消息队列常见问题整理
前言
消息队列(Message Queue),从广义上讲是一种消息队列服务中间件,提供一套完整的信息生产、传递、消费的软件系统。
消息队列所涵盖的功能远不止于队列(Queue),其本质是两个进程传递信息的一种方法。两个进程可以分布在同一台机器上,亦可以分布在不同的机器上。
众所周知,进程通信可以通过 RPC(Remote Procedure Call,远程过程调用)进行,那么我们为什么要用消息队列这种软件服务来传递消息呢?
我们通过一个快递员送快递的栗子来描述下消息队列的作用。
消息队列
现实世界的例子
小明是一名快递员,通常给一个客户送快递分为三步:
- 第一步:把快递运到客户家门口;
- 第二步:敲门;
- 第三步:客户开门取走快递。
好了上边是送快递最简单的三步,让我们想想,这简单的三步会有什么问题?
(1)耦合
小明什么时候完成这一单,完全依赖于客户的响应速度。
如果客户还没起床,听见敲门声再穿衣服开门,可能消耗很多时间。如果客户没在家呢?那就要配送失败了,如何判断配送失败呢?小明需要判断等多久开门(超时时间),打电话判断是否在家(健康检查),最终郁闷的离开,下次再来一次(重试)。
小明直接与客户交互,对客户的状态强依赖,产生了耦合现象。
(2)同步影响性能
小明的配送速度受到客户的响应速度影响极大,有一两个需要长时间等待的快件,小明的配送效率(吞吐率)会受到很大影响。
(3)高峰期负载很高
每次到双11、618 购物节的时候,小明都很烦躁。快递太多,来的比送得快,这可如何是好。一旦有客户因为联系不上影响了配送效率,就会影响后面客户的配送,严重了还会收到投诉。
这个时候有个叫X巢的快递柜出现了,小明可以把快递放到柜子里,发条短信通知客户过来取快递。这样就不强依赖客户的响应,大大提高了配送效率。
这里的快递柜就相当于是编程世界的消息队列,让我们看看消息队列到底起到了什么作用。
消息队列解决什么问题
- 解耦:此时,小明只需要把快递放到柜子里,不需要关心客户是否在家,是否在睡觉。客户也不需要一直等待给小明开门,两个人解耦了。
- 异步:小明把快递放到柜子里发个信息就可以去送下一件,不需同步等待结果。这样每个快递的处理速度(响应时间)都变得极短,每天送的快递数量(吞吐量)也变多了。
- 削峰:这次又到了双十一,以前小明一天只能配送 100 个快递,现在有了快递柜,配送量(吞吐量和响应速度)增加了好几倍,甚至数十倍,大大提升了小明的工作效率。这下小明再也不担心接到投诉了。
总结
让我们简单总结一下消息队列的作用,首先需要肯定的是使用消息组件有很多好处,其中最核心的三个是:解耦、异步、削峰。
- 解耦:生产端和消费端不需要相互依赖;
- 异步:生产端不需要等待消费端响应,直接返回,提高了响应时间和吞吐量;
- 削峰:打平高峰期的流量,消费端可以以自己的速度处理,同时也无需在高峰期增加太多资源,提高资源利用率。
引入消息队列后让我们子系统间耦合性降低了,异步处理机制减少了系统的响应时间,同时能够有效的应对请求峰值问题,提升系统的稳定性。但同时引入消息队列也会带来一些问题。
下面我们以 RocketMQ 为例来分析引入 MQ 带来的问题以及解决方案。
MQ 常见问题分析
消息丢失
消息丢失可以说是 MQ 中普遍存在的问题,不管用哪种 MQ 都无法避免。
那么有哪些场景会出现消息丢失问题呢?
我们下面来看一下,整个消息从生产到消费的过程中,哪些地方可能会导致丢消息,以及应该如何避免消息丢失。
一条消息从生产到被消费,将会经历三个阶段:
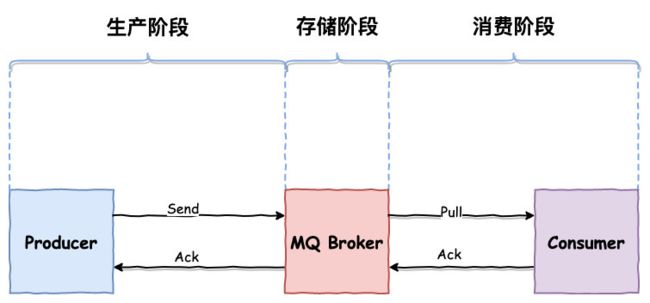
- 生产阶段,生产者新建消息,然后通过网络将消息投递给 MQ 服务器
- 存储阶段,消息将会存储在服务器磁盘中,如果是集群,消息会在这个阶段被复制到其他的副本上
- 消费阶段, 消费者将会从 MQ 服务器拉取消息
以上任一阶段都可能会丢失消息:
- 生产阶段:生产者发送消息时,由于网络原因,发送到 MQ 失败了。
- 存储阶段:MQ 服务器持久化时,服务器宕机、重启导致丢失消息。
- 消费阶段:消息消费者刚读取消息,已经 ack 确认了,但业务还没处理完,服务就被重启了。
消息丢失解决方案
生产阶段
RocketMQ 提供了 3 种发送消息方式,分别是:
- 同步发送:生产者向 MQ 发送消息,阻塞当前线程等待 MQ 服务器响应发送结果。
- 异步发送:生产者首先构建一个向服务器发送消息的任务,把该任务提交给线程池,等执行完该任务时,回调用户自定义的回调函数,执行处理结果。
- Oneway 发送:生产者发起消息发送请求后并不会等待服务器的响应结果,也不会调用回调函数,即不关心消息的最终发送结果。
Oneway 相对前两种发送方式来说是一种不可靠的消息发送方式,因此要保证消息发送的可靠性,我们只考虑同步和异步的发送方式。
(1)同步发送可靠性保证
采用同步阻塞式的发送,然后同步检查 MQ 服务器返回的状态来判断消息是否持久化成功。如果发送超时或者失败,则会自动重试,如果重试再失败,就会以返回值或者异常的方式告知用户。
我们在编写发送消息代码时,需要注意,正确处理返回值或者捕获异常,就可以保证这个阶段的消息不会丢失。
同步发送,代码如下:
public void send() throws Exception {
String message = "test producer";
Message sendMessage = new Message("topic1", "tag1", message.getBytes());
sendMessage.putUserProperty("name1","value1");
SendResult sendResult = null;
DefaultMQProducer producer = new DefaultMQProducer("testGroup");
producer.setNamesrvAddr("localhost:9876");
producer.setRetryTimesWhenSendFailed(3);
try {
sendResult = producer.send(sendMessage);
} catch (Exception e) {
e.printStackTrace();
}
if (sendResult != null) {
System.out.println(sendResult.getSendStatus());
}
}
Copy
同步发送会返回 4 个状态码:
SEND_OK:消息发送成功。
- 需要注意的是,消息发送到服务器后,还有两个操作:「消息刷盘」和「消息同步到 slave 节点」,默认这两个操作都是异步的,只有把这两个操作都改为同步,
SEND_OK这个状态才能真正表示发送成功。 FLUSH_DISK_TIMEOUT:消息发送成功但是消息刷盘超时。FLUSH_SLAVE_TIMEOUT:消息发送成功但是消息同步到 slave 节点时超时。SLAVE_NOT_AVAILABLE:消息发送成功但是 broker 的 slave 节点不可用。
根据返回的状态码,可以做消息重试,这里设置的重试次数是 3。
消息重试时,消费端一定要做好幂等处理。
既然是同步发送肯定就比较耗费一些时间,如果你的业务比较注重 RT 那就可以使用异步发送的方式。
(2)异步发送可靠性保证
异步发送时,则需要在回调方法里进行检查。这个地方是需要特别注意的,很多丢消息的原因就是,我们使用了异步发送,却没有在回调中检查发送结果。
具体的业务实现可以根据发送的结果信息来判断是否需要重试来保证消息的可靠性。
异步发送,代码如下:
public void sendAsync() throws Exception {
String message = "test producer";
Message sendMessage = new Message("topic1", "tag1", message.getBytes());
sendMessage.putUserProperty("name1","value1");
DefaultMQProducer producer = new DefaultMQProducer("testGroup");
producer.setNamesrvAddr("localhost:9876");
producer.setRetryTimesWhenSendFailed(3);
producer.send(sendMessage, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
}
@Override
public void onException(Throwable e) {
// TODO 可以在这里加入重试逻辑
}
});
}
Copy
异步发送,可以重写回调函数,回调函数捕获到 Exception 时表示发送失败,这时可以进行重试,这里设置的重试次数是 3。
存储阶段
默认的情况下,消息队列为了快速响应,在接受到生产者的请求,将消息保存在内存成功之后,就会立刻返回 ACK 响应给生产者。
RocketMQ 的刷盘方式分为「同步刷盘」和「异步刷盘」两种。
- 异步刷盘:消息写入 CommitLog 时,并不会直接写入磁盘,而是先写入 PageCache 缓存后返回成功,然后用后台线程异步把消息刷入磁盘。异步刷盘提高了消息吞吐量,但是可能会有消息丢失的情况,比如断点导致机器停机,PageCache 中没来得及刷盘的消息就会丢失。
同步刷盘:消息写入内存的 PageCache 后,立刻通知刷盘线程刷盘,然后等待刷盘完成,如果消息未在约定的时间内(默认 5 s)刷盘成功,就返回FLUSH_DISK_TIMEOUT,Producer 收到这个响应后,可以进行重试。同步刷盘策略保证了消息的可靠性,同时降低了吞吐量,增加了延迟。
- 要开启同步刷盘,需要增加下面配置:
flushDiskType=SYNC_FLUSH
RocketMQ 默认的是异步刷盘,就有可能导致消息还未刷到硬盘上就丢失了,可以通过设置为同步刷盘的方式来保证消息可靠性,这样即使 MQ 挂了,恢复的时候也可以从磁盘中去恢复消息。
如果是 Broker 是由多个节点组成的集群,需要将 Broker 集群配置成:至少将消息发送到 2 个以上的节点,再给客户端回复发送确认响应。 这样当某个 Broker 宕机时,其他的 Broker 可以替代宕机的 Broker,也不会发生消息丢失。
Broker 采用集群配置时,需要注意的一点是:消息发送到 master 节点后,slave 节点会从 master 拉取消息保持跟 master 的一致。这个过程默认是异步的,即 master 收到消息后,不等 slave 节点复制消息就直接给 Producer 返回成功。
这样会有一个问题,如果 slave 节点还没有完成消息复制,这时 master 宕机了,进行主备切换后就会有消息丢失。
为了避免这个问题,可以采用 slave 节点同步复制消息,即等 slave 节点复制消息成功后再给 Producer 返回发送成功。只需要增加下面的配置:brokerRole=SYNC_MASTER。
消费阶段
消费阶段采用和生产阶段类似的确认机制来保证消息的可靠传递,客户端从 Broker 拉取消息后,执行用户的消费业务逻辑:
- 如果 Consumer 消费成功,返回
CONSUME_SUCCESS,提交 offset 并从 Broker 拉取下一批消息 - 如果 Consumer 消费失败,下次拉消息的时候还会返回同一条消息,即进行消费重试。
消费重试
RocketMQ 认为消息消费失败需要重试的场景有三种:
- 返回 RECONSUME_LATER
- 返回 null
- 抛出异常
Broker 收到这个响应后,会把这条消息放入重试队列,Topic 名字为%RETRY% + consumerGroup。
注意:
Broker 默认最多重试 16 次,如果重试 16 次都失败,就把这条消息放入「死信队列」,Consumer 可以订阅死信队列进行消费。
重试只有在集群模式(MessageModel.CLUSTERING)下生效,在广播模式(MessageModel.BROADCASTING)下是不生效的。
Consumer 端一定要做好幂等处理。
其实重试 3 次都失败就可以说明代码有问题,这时 Consumer 可以把消息存入本地,给 Broker 返回 CONSUME_SUCCESS 来结束重试。
死信队列:未能成功消费的消息,消息队列并不会立刻将消息丢弃,而是将消息发送到死信队列,其名称是在原队列名称前加 %DLQ%,如果消息最终进入了死信队列,则可以通过 RocketMQ 提供的相关接口从死信队列获取到相应的消息,保证了消息消费的可靠性。
上面方案看似万无一失,每个阶段都能保证消息的不丢失,但在分布式系统中,故障不可避免,作为消息生产端,你并不能保证 MQ 是不是弄丢了你的消息,消费者是否消费了你的消息,所以,本着 Design for Failure 的设计原则,我们需要一种机制,来 Check 消息是否丢失了。
检测消息丢失的方法
总体方案解决思路为:在消息生产端,给每个发出的消息都指定一个全局唯一 ID,或者附加一个连续递增的版本号,然后在消费端做对应的版本校验。
可以利用拦截器机制。在生产端发送消息之前,通过拦截器将消息版本号注入消息中(版本号可以采用连续递增的 ID 生成,也可以通过分布式全局唯一 ID生成)。然后在消费端收到消息后,再通过拦截器检测版本号的连续性或消费状态,这样实现的好处是消息检测的代码不会侵入到业务代码中,可以通过单独的任务来定位丢失的消息,做进一步的排查。
如果同时存在多个消息生产端和消息消费端,通过版本号递增的方式就很难实现了,因为不能保证版本号的唯一性,此时只能通过全局唯一 ID 的方案来进行消息检测,具体的实现原理和版本号递增的方式一致。
重复消息
RocketMQ 为了保证消息的可靠性,选择 「至少传输成功一次」 的消息模型。
在消息领域有一个对消息投递的 QoS 定义,分为:
- 最多一次(At most once)
- 至少一次(At least once)
- 仅一次( Exactly once)
既然是至少一次,那避免不了消息重复,尤其是在分布式网络环境下。比如:网络原因闪断,ACK 返回失败等等故障,确认信息没有传送到消息队列,导致消息队列不知道该消息已经被消费了,再次将该消息分发给其他的消费者。
那么如何解决这个问题?
这个问题其实可以换一种说法,就是如何解决消费端幂等性问题(幂等性,就是一条命令,任意多次执行所产生的影响均与一次执行的影响相同),只要消费端具备了幂等性,那么重复消费消息的问题也就解决了。
那如何保证消息队列消费的幂等性? 我们还是得结合业务来思考,这里给几个思路:
- 利用数据库的唯一约束实现:比如收到数据时要写库,通过创建唯一索引的方式保证幂等。
- 为更新的数据设置前置条件:给数据变更设置一个前置条件,如果满足条件就更新数据,否则拒绝更新数据。 比如可以通过判断状态是否允许操作,不满足的拒绝更新。
如果上面提到的两种实现幂等方法都不能适用于你的场景,我们还有一种通用性最强,适用范围最广的实现幂等性方法。
更通用的解决方案
终极方法:「基于消息幂等表的非事务方案」,实现的思路特别简单:在执行业务代码之前,先检查一下是否处理过这个条消息。
具体的实现方法是:
首先,在数据库中建一张消息日志表,这个表有两个字段:「消息 ID」和「消息执行状态(消费中、已消费)」。
然后给消息 ID 来创建一个唯一约束,这样对于相同的消息 ID,表里至多只能存在一条记录。
在发送消息时,给每条消息指定一个全局唯一的 ID,消费时,先根据这个 ID 检查这条消息是否有被消费过,如果没有消费过,才执行业务代码,然后将消费状态置为已消费。

可以看到,此方案是无事务的,而是针对消息表本身做了状态的区分:消费中、消费完成。只有消费完成的消息才会被幂等处理掉。
而对于已有消费中的消息,后面重复的消息会触发延迟消费,这样主要是为了控制并发场景下,第二条消息在第一条消息没完成的过程中,去控制消息不丢(如果直接幂等,那么会丢失消息(同一个消息id的话),因为上一条消息如果没有消费完成的时候,第二条消息你已经告诉broker成功了,那么第一条消息这时候失败broker也不会重新投递了)。
我们分析下这种方案是否解决了幂等问题:
- 消息已经消费成功了,第二条消息将被直接幂等处理掉(消费成功)
- 并发场景下的消息,依旧能满足不会出现消息重复
- 支持上游业务生产者重发的业务重复的消息幂等问题
第一个问题明显解决了。
第二个问题也已经解决,主要是依靠插入消息表的这个动作做控制的,因为「消息 ID」的惟一的,后面的消息插入会由于主键冲突而失败,走向延迟消费的分支,然后后面延迟消费的时候就会变成上面第一个场景的问题。
关于第三个问题,只要我们设计去重的消息键让其支持业务的主键(例如订单号、请求流水号等),而不仅仅是 messageId 即可。所以也不是问题。
此方案是否有消息丢失的风险?
细心的读者可能会发现这里实际上是有逻辑漏洞的,问题出在上面聊到的三个问题中的第 2 个问题「并发场景」。
在并发场景下我们依赖于消息状态做并发控制,使得第二条重复的消息会不断延迟消费(重试)。
但如果这时候第一条消息也由于一些异常原因(例如机器重启了、外部异常导致消费失败)没有成功消费成功呢?
也就是说这时候延迟消费实际上每次下来看到的都是「消费中」的状态,最后消费就会被视为消费失败而被投递到死信队列中。
对于此,我们解决的方法是,插入的消息表必须要带一个最长消费过期时间,例如 10 分钟,意思是如果一个消息处于消费中超过 10 分钟,就需要从消息表中删除(需要程序自行实现)。
所以最后这个消息的流程会是这样的:

消息积压
如果出现积压,那一定是性能问题,想要解决消息从生产到消费上的性能问题,就首先要知道哪些环节可能出现消息积压,然后在考虑如何解决。
因为消息发送之后才会出现积压的问题,所以和消息生产端没有关系,又因为绝大部分的消息队列单节点都能达到每秒钟几万的处理能力,相对于业务逻辑来说,性能不会出现在中间件的消息存储上面。
毫无疑问,出问题的肯定是消息消费阶段。
如果是线上突发问题,要临时扩容,增加消费端的数量,与此同时,降级一些非核心的业务。通过扩容和降级承担流量。
其次,才是排查解决异常问题,如通过监控,日志等手段分析是否消费端的业务逻辑代码出现了问题,优化消费端的业务处理逻辑。
最后,如果是消费端的处理能力不足,可以通过水平扩容来提供消费端的并发处理能力。
在扩容消费者的是时候有一点需要注意,如果当前 Topic 的 Message Queue 的数量大于消费者数量,就可以对消费者进行扩容,增加消费者,来提高消费能力,尽快把积压的消息消费完。如果消费者的数量大于等于 Message Queue 的数量,增加消费者是没有用的。
顺序消费
我们知道,RocketMQ 在主题上是无序的。但是在有些场景下,使用 MQ 需要保证消息的顺序性,比如在电商系统中:下单、付款、发货、买家确认收货,消费端需要严格按照业务状态机的顺序处理,否则,就会出现业务问题。
我们发现,消息带上了状态,不再是一个个独立的个体,有了上下文依赖关系!
那么 MQ 是如何来保证消息顺序的?
我们通常发送消息的时候,消息发送默认是会采用轮询的方式发送到不同的 queue。
而消费端消费的时候,是会分配到多个 queue 的,多个 queue 是同时拉取提交消费。
但是同一条 queue 里面,RocketMQ 的确是能保证 FIFO 的。那么要做到顺序消息,应该怎么实现呢——把消息确保投递到同一条 queue。
对于 RocketMQ 来说,主要是通过 Producer 和 Consumer 来保证消息顺序的。
生产端
生产端提供了一个接口 MessageQueueSelector:
public interface MessageQueueSelector {
MessageQueue select(final List mqs, final Message msg, final Object arg);
}
Copy
接口内定义一个 select 方法,具体参数含义:
- mqs:该 Topic 下所有的队列分片
- msg:待发送的消息
- arg:发送消息时传递的参数
示例代码
模拟订单消息的发送,共有 3 个订单,每个订单都包含下单、付款、发货、买家确认收货四个流程,对应 4 条消息。同一个订单的消息要求严格按照顺序消费,不同订单的消息可以并发执行。
首先实现 MessageQueueSelector 接口,定制 MessageQueue 选择策略:
public class OrderMessageQueueSelector implements MessageQueueSelector {
@Override
public MessageQueue select(List mqs, Message msg, Object arg) {
//选择以参数arg为索引的MessageQueue
Integer id = (Integer) arg;
int index = id % mqs.size();
return mqs.get(index);
}
}
Copy
下面实现发送消息逻辑:
@Slf4j
@Service
public class OrderMessageProducer {
@Value("${spring.rocketmq.namesrvAddr}")
private String namesrvAddr;
private static final DefaultMQProducer producer = new DefaultMQProducer("OrderProducer");
private static final String[] ORDER_MESSAGES = {"下单", "付款", "发货", "买家确认收货"};
@PostConstruct
public void sendMessage() {
try {
//设置namesrv
producer.setNamesrvAddr(namesrvAddr);
//启动Producer
producer.start();
System.err.println("Order Message Producer Start...");
//创建3组消息,每组消息发往同一个Queue,保证消息的局部有序性
String tags = "Tags";
OrderMessageQueueSelector orderMessageQueueSelector = new OrderMessageQueueSelector();
//注:要实现顺序消费,必须同步发送消息
for (int i = 0; i < 3; i++) {
String orderId = "" + (i + 1);
for (int j = 0, size = ORDER_MESSAGES.length; j < size; j++) {
String message = "Order-" + orderId + "-" + ORDER_MESSAGES[j];
String keys = message;
byte[] messageBody = message.getBytes(RemotingHelper.DEFAULT_CHARSET);
Message mqMsg = new Message("TEST_TOPIC_NAME", tags, keys, messageBody);
producer.send(mqMsg, orderMessageQueueSelector, i);
}
}
} catch (Exception e) {
log.error("Message Producer: Send Message Error ", e);
}
}
}
Copy
使用 DefaultMQProducer 的 send() 方法,指定 MessageQueueSelector 和参数,Broker 将会将逻辑上需要保证顺序性的消息发往同一队列。
注意:上面的代码把 orderId 相同的消息都会发送到同一个 MessageQueue,这样同一个 orderId 的消息是有序的,这也叫做局部有序。对应的另一种是全局有序,这需要把所有的消息都发到同一个 MessageQueue。
注:想要实现顺序消费,发送方式必须为同步发送,异步发送无法保证消息的发送顺序!
这样同一批我们需要做到顺序消费订单肯定会投递到同一个队列,同一个队列肯定会投递到同一个消费实例,同一个消费实例肯定是顺序拉取并顺序提交线程池的,只要保证消费端顺序消费,则大功告成!
消费端
消费端想要实现顺序消费,只要设置监听器实现 MessageListenerOrderly 接口即可。
示例代码
首先自定义 MessageListenerOrderly 接口实现类,实现顺序消费:
public class OrderMessageListener implements MessageListenerOrderly {
@Override
public ConsumeOrderlyStatus consumeMessage(List msgs, ConsumeOrderlyContext context) {
if (CollectionUtils.isEmpty(msgs)){
return ConsumeOrderlyStatus.SUCCESS;
}
//设置自动提交
context.setAutoCommit(true);
msgs.stream()
.forEach(msg -> {
try {
String messageBody = new String(msg.getBody(), RemotingHelper.DEFAULT_CHARSET);
System.err.println("Handle Order Message: messageId: " + msg.getMsgId() + ",topic: " + msg.getTopic() + ",tags: "
+ msg.getTags() + ",keys: " + msg.getKeys() + ",messageBody: " + messageBody);
} catch (Exception e) {
throw new RuntimeException(e);
}
});
return ConsumeOrderlyStatus.SUCCESS;
}
}
Copy
下面就是消费逻辑:
@Service
public class OrderMessageConsumer {
@Value("${spring.rocketmq.namesrvAddr}")
private String namesrvAddr;
private final DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("DefaultConsumer");
@PostConstruct
public void start() {
try {
//设置namesrv地址
consumer.setNamesrvAddr(namesrvAddr);
//从消息队列头部开始消费
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
//集群消费模式
consumer.setMessageModel(MessageModel.CLUSTERING);
//订阅主题
consumer.subscribe("TEST_TOPIC_NAME", "*");
//注册消息监听器,这里因为要实现顺序消费,所以必须注册MessageListenerOrderly
consumer.registerMessageListener(new OrderMessageListener());
//启动消费端
consumer.start();
System.err.println("Order Message Consumer Start...");
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
Copy
要保证消息的顺序性,就需要保证同一个 MessageQueue 只能被同一个 Consumer 消费。简单来说就是通过对 MessageQueueLock 进行加锁,这样就保证只有一个线程在处理当前 MessageQueue。感兴趣的同学可以深入研究下。
总结
在项目中引入 MQ 解决了我们系统之间的耦合度过高的问题、提高系统的灵活性和峰值处理能力。但同时也带来了一些问题:消息丢失、重复消息和消息积压。
消息丢失可分三个阶段进行分析:
- 生产阶段:采用同步发送,通过正确处理返回值或者捕获异常,保证消息可靠性;采用异步发送则需要在回调方法里进行检查。
- 存储阶段:存储端的可靠性依靠持久化策略、备份(主从复制)保证。
- 消费阶段:消费失败可以依靠重试策略保证可靠性。
对于重复消息,我们最后也给出一个终极方案:「基于消息幂等表的非事务方案」。不依赖事务而实现消息的去重,那么方案就能推广到更复杂的场景例如:RPC、跨库等。
而消息积压,绝大部分问题出现在消费端,我们可以通过水平扩容增加 Consumer 的实例数量来解决,需要注意的是,增加并发需要同步扩容分区数量,否则是起不到效果的。
最后介绍了顺序消费,RocketMQ 采用了局部顺序一致性的机制,实现了单个队列中的消息严格有序。