优化性能测试分析:如何科学利用CPU异常曲线
性能测试为保证软件质量起到重要作用,对于交易量较大的应用系统,性能测试更是一个必不可少的环节。
测试人员通常通过监测响应时间、吞吐量、应用服务器和数据库服务器的CPU及内存来衡量系统的性能是否达标,那么,在性能测试过程中,面对一些异常的指标数据,我们应该如何层层剥茧,找到问题产生的原因?
如何聚焦、解决性能问题?笔者本次将总结移动端性能测试的经验,与大家分享如何应对CPU异常曲线。
如果你想学习性能测试,我这边给你推荐一套视频,这个视频可以说是B站播放全网第一的性能测试教程,同时在线人数到达1000人,并且还有笔记可以领取及各路大神技术交流:798478386
15天学会性能测试,通俗易懂详细教学,Jmeter性能测试实战(集群压测,全链路压测,性能调优,瓶颈分析)极速掌握,干就完事!_哔哩哔哩_bilibili15天学会性能测试,通俗易懂详细教学,Jmeter性能测试实战(集群压测,全链路压测,性能调优,瓶颈分析)极速掌握,干就完事!共计27条视频,包括:1.【性能测试】什么是性能测试以及性能测试的价值和目的、2.【性能测试】真实企业性能测试指标详解以及指标测算、3.【性能测试】真实企业中性能测试流程以及细节剖析等,UP主更多精彩视频,请关注UP账号。https://www.bilibili.com/video/BV1B14y1D7X9/?spm_id_from=333.337.search-card.all.click
一、性能测试发现的问题
本次是针对移动端应用进行性能测试,性能测试的交易分别为查询交易1、申请交易1、申请交易2、查询交易2和查询交易3。
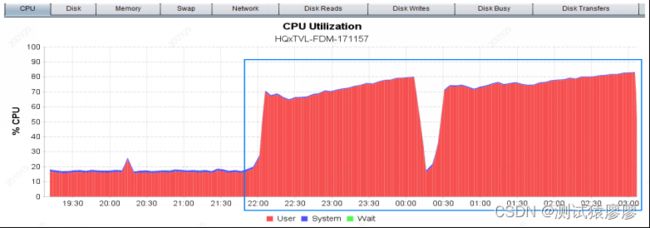
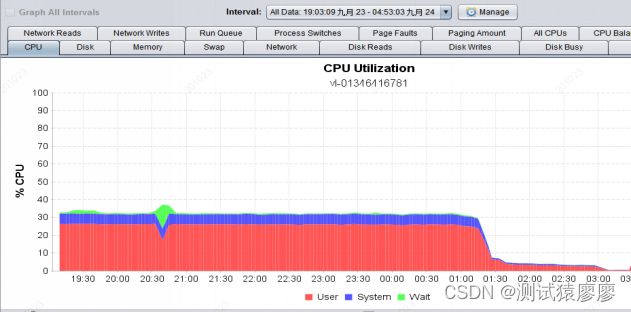
在对5支交易进行混合疲劳8小时测试过程中,发现应用服务器的CPU使用率曲线呈现规律性的异常现象:混合场景疲劳发压几小时后,CPU使用率陡增,直至发压结束,曲线如图1所示。
二、问题分析过程
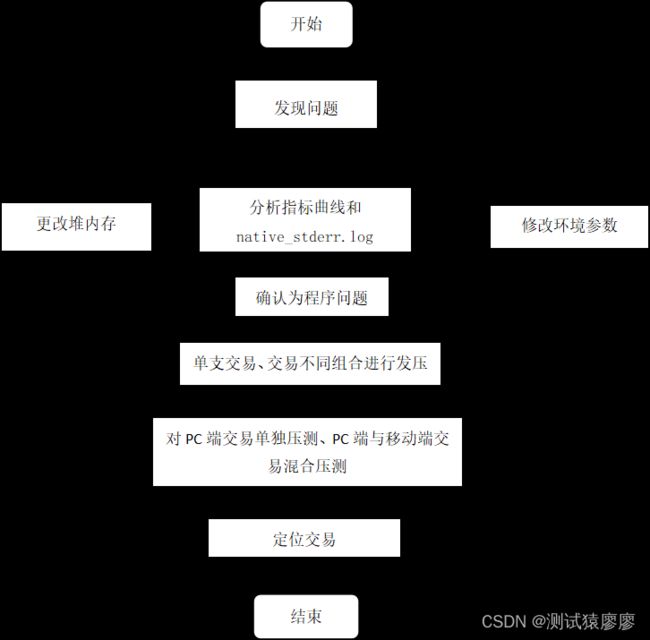
1.发现问题时,初步猜测是由于环境不稳导致了CPU陡增,再次进行混合8小时疲劳测试,发现测试结果和最初的结果一致,排除环境因素。
2. 查询XMeter的运行日志,发现有
Java.lang.OutOfMemoryError: Java heap space的报错信息,进而对Heapdump文件进行分析,并未发现导致该问题的代码块。随后修改堆内存配置,由原来的1.5G改为2.5G,再次混合疲劳压测8小时,压测结果如图3所示。

压测结果显示:应用服务器的CPU使用率曲线开始陡增的时间较之前变长,堆内存为1.5G时,CPU使用率在发压开始2-3小时左右陡增,直至发压结束;堆内存为2.5G时,CPU使用率在发压开始5-6小时左右陡增,直至发压结束。
3. 项目组进一步验证环境的参数配置,将服务器由2C/4G扩容至2C/8G,增加数据库连接池数目和WAS线程数,再次进行混合疲劳压测,测试结果显示CPU仍然出现陡增现象,排除环境参数配置因素。
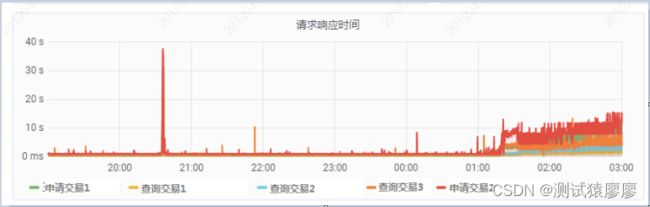
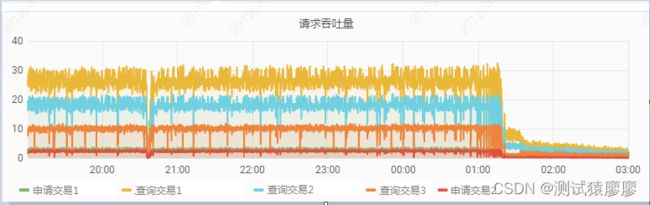
4. 测试人员对应用服务器CPU曲线、数据库服务器CPU曲线、TPS曲线和请求响应时间曲线进行综合分析,发现应用服务器CPU陡增的同时,数据库CPU和TPS曲线呈现下降趋势,平均响应时间曲线升高,因此初步将问题原因聚焦于应用服务器程序问题。
(1)请求响应时间
(2)请求吞吐量
(3)数据库服务器CPU曲线
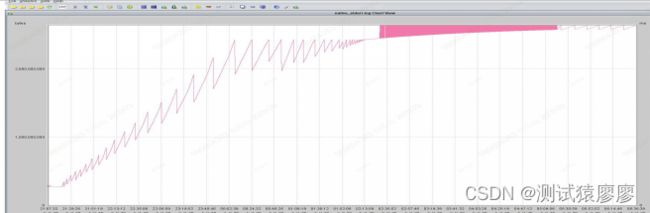
分析native_stderr.log,发现JVM堆内存使用量不断升高,堆内存回收异常,存在内存泄漏:
5. 在确认是程序问题之后,通过对不同的交易进行压测来定位导致问题的交易:
(1)移动端交易单独压测
由于陡增的时间节点是发压后3小时,分别对每支交易进行压测4小时,进而对不同的交易组合进行混合压测4小时,CPU陡增现象均未出现。
(2)PC端与移动端交易进行压测
① 由于5支交易中仅申请交易2是旧交易,因此对PC端的申请交易2单独进行疲劳压测8小时,发现JVM堆内存使用率曲线显示正常;
② 对PC端申请交易2,移动端:查询交易1、查询交易2、查询交易3这4支交易进行混合疲劳压测8小时,发现JVM堆内存使用率曲线显示正常;
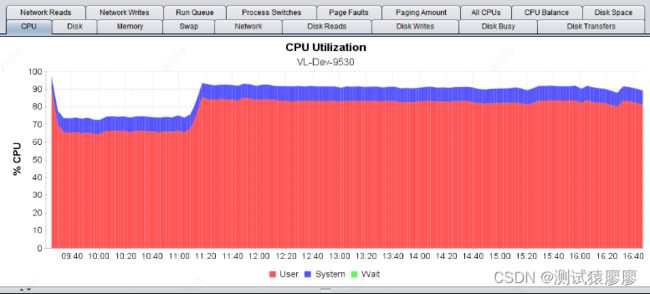
③ 对PC端申请交易2,移动端:查询交易1、查询交易2、查询交易3、申请交易1这5支交易混合疲劳压测8小时,问题复现,测试结果如图8所示。
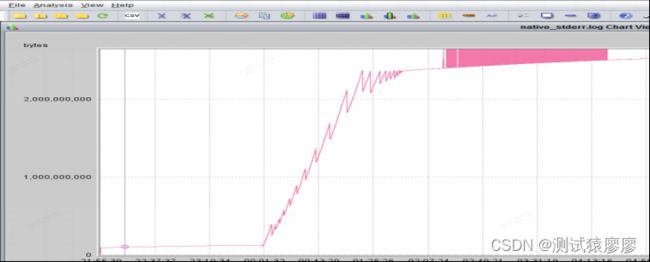
JVM堆内存使用量曲线如图9所示。
初步确认申请交易1导致该问题出现,随后对申请交易1单独进行疲劳压测8小时,问题复现,确认该交易存在问题,测试结果如图10所示。

JVM堆内存使用量曲线如图11所示。
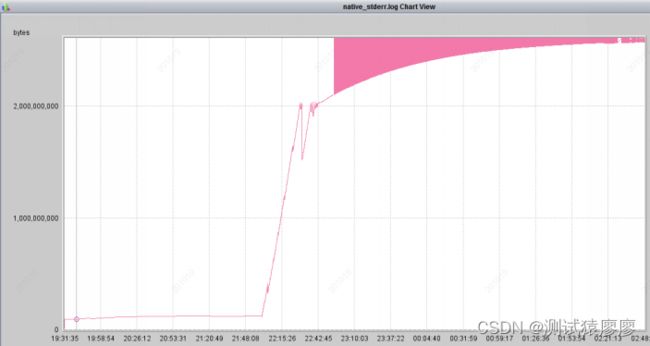
三、解决方案
项目组对申请交易1和申请交易2的代码进行单步调试,定位到出现内存问题的代码块,随后比对PC端和移动端交易代码,发现移动端交易代码未对申请单缓存数据进行清理,加入了清理缓存数据的方法后,再次对5支交易进行混合疲劳压测8小时,应用服务器的CPU曲线平稳,未出现陡增现象。
代码块采用了线程上下文方式对每笔申请单数据进行缓存,采用此种方法,需要用remove()方法对其进行清理,这样可以加速JVM的回收,否则,在高并发的情况下,会出现JVM堆内存使用量一直升高,堆内存回收异常的现象。
四、测试总结及反思
性能测试过程中,响应时间、吞吐量、CPU是衡量性能的关键指标,当响应时间、吞吐量符合通过准则时,并不意味着性能一定是正常的,还要关注CPU曲线是否正常。
1.及时查看相关的日志,如XMeter日志、Heapdump文件、java core文件和native_stderr.log文件,通过日志文件分析堆内存是否存在回收异常、内存泄漏或内存溢出等现象。
2. 问题复现的压测时间至少为8小时或8小时以上,本次性能测试中,问题复现的压测时间均为3-5小时,压测时间不足导致问题未能很好的复现。
3. 日志显示存在内存泄漏的现象后,要着重检查代码,而不应该持续的更改配置和参数。
4. 应及时对测试结果进行全面分析,包括应用服务器CPU曲线、数据库服务器CPU曲线、请求吞吐量和请求响应时间,这样更有助于快速定位问题来源。
5. 由于堆内存会在服务器重启之后进行清理,因此为了使每次测试都是从初始状态开始,测试之前应该重启服务器。