机器学习——KNN算法(手动代码,含泪)
徒手实现代码的过程,真是含泪和心酸,浪费了生命中的三天,以及工作中的划水一小时
终于滤清思路后,自己实现了KNN
都说KNN是最基础,最简单的分类器
放屁!骗纸!!!它的想法是简单的,但实现的过程何其复杂!!!
问题何其之多!!是我实现感知机、逻辑回归分类、线性回归、朴素贝叶斯中,最难实现的分类算法!!!!
给多少时间都无法将这个槽吐尽,甚至算法都没完全弄好,但只剩收尾工作了
1. KNN 分类思想
首先,KNN思想很简单,找到离目标对象最近的K个对象,以K个对象中数量最多的那个类型为预测结果。
就好像:要对一个有喉结、短头发、平胸的对象进行性别的分类,那么特征最相近的K个人,如果男性居多,则将该对象分类为男性。如果女性居多,则分类为女性。
KNN搜索特征最相近的精髓,在于建立KD树——二叉树
2. KNN 分类流程
2.1 构建KD树
构建KD树的原因是,我们不能逐一去计算某个对象与所有对象的特征距离。
那就对所有对象的特征,进行KD树的分组,分组规则别人说的非常清晰明了,我看了之后有种恍然大悟、拍手叫好的激动
kd树的搜索过程到底是怎么进行的? - 月来客栈的文章 - 知乎
但是当我自己去实现时,遇到重重的困难
先来实现 KD树:应用二叉树的原理
# 构建一个二叉树节点
class Node_1():
def __init__(self,X_value):
self.left = None
self.right = None
self.value = []
self.X = X_value # {"特证名":"x","划分标准":"aaaaaa"}
# 根据节点,构建一个二叉树
class Tree():
def __init__(self):
self.root = None
def get_value_1(self,X_arg,node_arg=None):
node = node_arg
if self.root == None:
node = Node_1(X_arg)
self.root = node
# 获取所有特征各自对应的方差
vars = [X_arg[i].var() for i in X_arg.columns[0:2]]
# 如果这些方差中,最大的那个方差为0或是无法计算,则说明数据已经分的很清楚了
"""重点:停止迭代的条件:所有特征的方差均为0 或无法计算"""
if max(vars) == 0 or math.isnan(max(vars)):
return
"""以方差最大的那个特征,作为分组的维度,根据该特征的中位数进行分组:
pandas中的median中位数,与统计学稍微不同
统计学中偶数个数据的中位数,是中间两个数据的均值
pandas中偶数个数据的中位数,是中间两个数据的其中一个
因此,用pandas的median计算中位数,还需要考虑一个非常坑的问题:如果最后只剩两个数据,中位数到底是偏大的那个,还是偏小的那个,这决定了我们分组到底能不能分清楚!!!"""
X_name = X_arg.columns[vars.index(max(vars))]
med = X_arg[X_name].median()
if med == X_arg[X_name].max():
"""要根据中位数,分为左组、右组:涉及到pandas的分组条件筛选【抄网上】"""
left = X_arg.groupby(X_name).apply(lambda x: x.loc[x.loc[x[X_name] < med].index]).reset_index(drop=True)
right = X_arg.groupby(X_name).apply(lambda x: x.loc[x.loc[x[X_name] >= med].index]).reset_index(drop=True)
else:
left = X_arg.groupby(X_name).apply(lambda x: x.loc[x.loc[x[X_name] <= med].index]).reset_index(drop=True)
right = X_arg.groupby(X_name).apply(lambda x: x.loc[x.loc[x[X_name] > med].index]).reset_index(drop=True)
"""如果左右组有一个为空,说明这个节点已经分完了"""
if left.empty or right.empty:
return
# print(f"当前节点以【{X_name}】为分组特征,中位数为{med},【{X_name}】方差为{X_arg[X_name].std()}")
# print(X_arg)
node.value=[X_name,med]
# print(f"【————————左子树(left)————————】")
# print(left)
node_left = Node_1(left)
node.left = node_left
self.get_value_1(left, node_left)
# print(f"【————————右子树(right)————————】")
# print(right)
node_right = Node_1(right)
node.right = node_right
self.get_value_1(right, node_right)
分的过程,很漂亮,我看了很多次。。。肉眼数它是怎么分的!!!瞎了
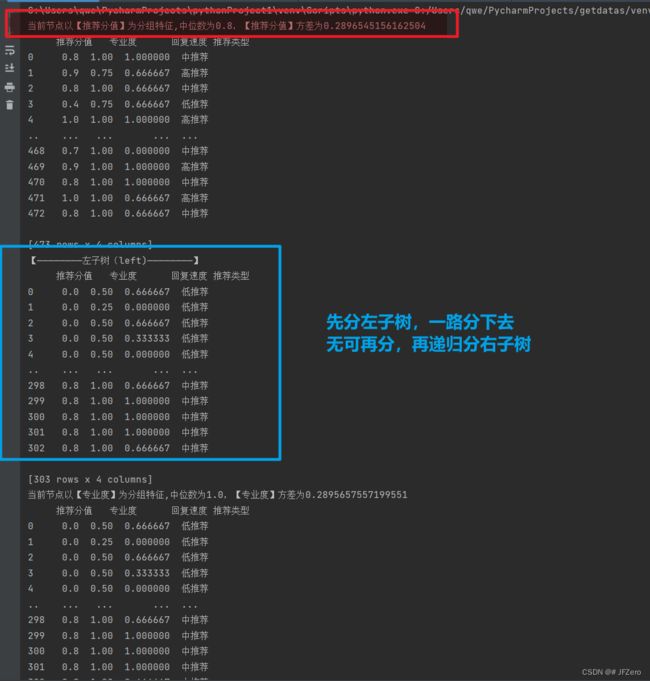
最终分组后的数据,都分在叶子节点上【全挂在树梢,中间节点不挂】
2.2 搜索最近邻&K近邻
搜索最近邻和K近邻也并不容易,用到了递归
我现在对递归,真的是轻车熟路!!!!
痛苦,总是让人印象深刻
最近邻,主要还是用到了欧式距离的计算
class Find_KD_Tree:
def __init__(self):
self.k = 10
self.K_list = []
self.min_point = []
# self.X = X_arg
def find_K(self,node_arg, X_arg):
# global k, K_list, min_point
columns_1 = len(node_arg.X.columns)
if not node_arg.value:
k_distance = ((node_arg.X.loc[0][0:columns_1 - 1] - X_arg[0:columns_1 - 1]) ** 2).sum()
if (not self.min_point) or (k_distance < self.min_point[0]): # 当没有最小值,或比最小值更小时
self.min_point = [k_distance, node_arg]
if len(self.K_list) < self.k:
row, columns = node_arg.X.shape
for i in range(row):
# print(f"添加的距离为{k_distance},添加的数据为")
# print(node_arg.X.loc[i])
if len(self.K_list) <= self.k:
self.K_list.append([k_distance, node_arg.X.loc[i]])
self.K_list = sorted(self.K_list, key=lambda cus: cus[0], reverse=False)
elif k_distance < self.K_list[-1][0]:
# print(f"出现了替代值{k_distance},当前列表最末为{[i[0] for i in self.K_list]}")
self.K_list.pop()
self.K_list.append([k_distance, node_arg.X.loc[i]])
self.K_list = sorted(self.K_list, key=lambda cus: cus[0], reverse=False)
else:
break
# print(K_list)
# K_list.sort()
elif k_distance < self.K_list[-1][0]:
row, columns = node_arg.X.shape
for i in range(row):
# print(f"添加的距离为{k_distance},添加的数据为")
# print(node_arg.X.loc[i])
# print(f"出现了替代值{k_distance},当前列表最末为{[i[0] for i in K_list]}")
self.K_list.pop()
self.K_list.append([k_distance, node_arg.X.loc[i]])
self.K_list = sorted(self.K_list, key=lambda cus: cus[0], reverse=False)
if k_distance > self.K_list[-1][0]:
break
# print(K_list)
# K_list.sort()
else:
# 计算叶子与当前数据的欧式距离:叶子上都是一样的数据,选择其中一个数据与当前数据进行计算即可。
X_name = node_arg.value[0]
X_value = node_arg.value[1]
node_distance = (X_arg[X_name] - X_value) ** 2
# print("cecece测试",node_distance)
# 选择方向-回溯搜索K近邻
if X_arg[X_name] <= X_value:
# print(f'当前节点按{X_name}来分,且往左节点搜索')
self.find_K(node_arg.left, X_arg)
# print(f'当前节点距维度的距离为{node_distance},最近邻距离min为{self.min_point[0]}')
if node_distance <= self.min_point[0]:
# print(f'当前节点按{X_name}来分,且可往右right右节点,有可能搜索到近邻k')
self.find_K(node_arg.right, X_arg)
else:
# print(f'当前节点按{X_name}来分,且往右节点搜索')
self.find_K(node_arg.right, X_arg)
# print(f'当前节点距维度的距离为{node_distance},最近邻距离min为{self.min_point[0]}')
if node_distance <= self.min_point[0]:
# print(f'当前节点按{X_name}来分,且可往右left左节点,有可能搜索到近邻k')
self.find_K(node_arg.left, X_arg)
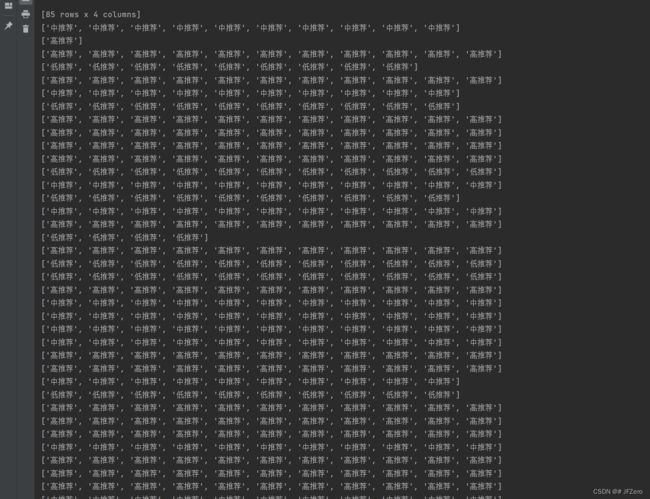
最终将每一条数据的K近邻,存储在一个二维列表中,输出结果如下
有些K近邻的列表,不足k个(我设为10个)元素,主要还是因为回溯到上一个维度时,维度距离超过了全局最小距离,因此就不再搜索另一边的树了。
搜索最近邻和K近邻的过程,比较简单:(主要是要细讲逻辑,太复杂了。。。放弃细讲。。。)
2.3 预测分类
最终,只需要将上述每个对象的K近邻,通过统计,得出它们各自类型最多的那个分类,即为预测分类的结果。
相比于前边徒手建立二叉树,和徒手进行K近邻、最近邻的回溯搜索来说,这一步真是太过easy,我都已经不稀罕浪费脑细胞来详写了!!!
待回头,收拾旧心情,再来写
3. KNN - 手动代码(缺2.3)
""" 难点:构思要如何建立KD树,如何回溯找出最近邻和K近邻"""
import math
import time
import pandas as pd
# 获取所需数据:'推荐分值', '专业度','回复速度','用户群活跃天数'
datas = pd.read_excel('./datas1.xlsx')
important_features = ['推荐类型','推荐分值', '专业度','回复速度']
datas_1 = datas[important_features]
# 明确实值Y为'推荐分值',X分别为'专业度','回复速度','用户群活跃天数'
Y = datas_1['推荐类型']
X = datas_1.drop('推荐类型',axis=1)
# X 归一化处理
data = (X-X.min())/(X.max()-X.min())
data["推荐类型"] = Y
# print(data)
"""
构建KNN二叉树
# 构造二叉树的节点、构造二叉树的内容
① 二叉树的节点是node:包含 4 个属性 - 值value、左left、右left、数据组
② 二叉树的内容是三个节点:根节点、左节点、右节点
# 迭代创建二叉树的三个关键:
① 停止迭代的条件:特征方差为0或Nan(无法计算方差)
② 如何分组迭代:选择方差最大的特征,按该特征的中位数,对数据进行分组,再对组调用构造二叉树的方法
"""
# 构建一个二叉树节点
class Node_1():
def __init__(self,X_value):
self.left = None
self.right = None
self.value = []
self.X = X_value # {"特证名":"x","划分标准":"aaaaaa"}
# 根据节点,构建一个二叉树
class Tree():
def __init__(self):
self.root = None
def get_value_1(self,X_arg,node_arg=None):
node = node_arg
if self.root == None:
node = Node_1(X_arg)
self.root = node
vars = [X_arg[i].var() for i in X_arg.columns[0:2]]
if max(vars) == 0 or math.isnan(max(vars)):
return
X_name = X_arg.columns[vars.index(max(vars))]
med = X_arg[X_name].median()
if med == X_arg[X_name].max():
"""要根据中位数,分为左组、右组:涉及到pandas的分组条件筛选"""
left = X_arg.groupby(X_name).apply(lambda x: x.loc[x.loc[x[X_name] < med].index]).reset_index(drop=True)
right = X_arg.groupby(X_name).apply(lambda x: x.loc[x.loc[x[X_name] >= med].index]).reset_index(drop=True)
else:
left = X_arg.groupby(X_name).apply(lambda x: x.loc[x.loc[x[X_name] <= med].index]).reset_index(drop=True)
right = X_arg.groupby(X_name).apply(lambda x: x.loc[x.loc[x[X_name] > med].index]).reset_index(drop=True)
if left.empty or right.empty:
return
print(f"当前节点以【{X_name}】为分组特征,中位数为{med},【{X_name}】方差为{X_arg[X_name].std()}")
print(X_arg)
node.value=[X_name,med]
print(f"【————————左子树(left)————————】")
print(left)
node_left = Node_1(left)
node.left = node_left
self.get_value_1(left, node_left)
#
print(f"【————————右子树(right)————————】")
print(right)
node_right = Node_1(right)
node.right = node_right
self.get_value_1(right, node_right)
def pre_print(self,root):
if root is None:
return
# if not root.left and not root.right:
# print(f"现在root的节点按【{root.X}】来分")
# print(f"print:{root.X}")
self.pre_print(root.left)
self.pre_print(root.right)
class Find_KD_Tree:
def __init__(self):
self.k = 10
self.K_list = []
self.min_point = []
# self.X = X_arg
def find_K(self,node_arg, X_arg):
# global k, K_list, min_point
columns_1 = len(node_arg.X.columns)
if not node_arg.value:
k_distance = ((node_arg.X.loc[0][0:columns_1 - 1] - X_arg[0:columns_1 - 1]) ** 2).sum()
if (not self.min_point) or (k_distance < self.min_point[0]): # 当没有最小值,或比最小值更小时
self.min_point = [k_distance, node_arg]
if len(self.K_list) < self.k:
row, columns = node_arg.X.shape
for i in range(row):
# print(f"添加的距离为{k_distance},添加的数据为")
# print(node_arg.X.loc[i])
if len(self.K_list) <= self.k:
self.K_list.append([k_distance, node_arg.X.loc[i]])
self.K_list = sorted(self.K_list, key=lambda cus: cus[0], reverse=False)
elif k_distance < self.K_list[-1][0]:
# print(f"出现了替代值{k_distance},当前列表最末为{[i[0] for i in self.K_list]}")
self.K_list.pop()
self.K_list.append([k_distance, node_arg.X.loc[i]])
self.K_list = sorted(self.K_list, key=lambda cus: cus[0], reverse=False)
else:
break
# print(K_list)
# K_list.sort()
elif k_distance < self.K_list[-1][0]:
row, columns = node_arg.X.shape
for i in range(row):
# print(f"添加的距离为{k_distance},添加的数据为")
# print(node_arg.X.loc[i])
# print(f"出现了替代值{k_distance},当前列表最末为{[i[0] for i in K_list]}")
self.K_list.pop()
self.K_list.append([k_distance, node_arg.X.loc[i]])
self.K_list = sorted(self.K_list, key=lambda cus: cus[0], reverse=False)
if k_distance > self.K_list[-1][0]:
break
# print(K_list)
# K_list.sort()
else:
# 计算叶子与当前数据的欧式距离:叶子上都是一样的数据,选择其中一个数据与当前数据进行计算即可。
X_name = node_arg.value[0]
X_value = node_arg.value[1]
node_distance = (X_arg[X_name] - X_value) ** 2
# print("cecece测试",node_distance)
# 选择方向-回溯搜索K近邻
if X_arg[X_name] <= X_value:
# print(f'当前节点按{X_name}来分,且往左节点搜索')
self.find_K(node_arg.left, X_arg)
# print(f'当前节点距维度的距离为{node_distance},最近邻距离min为{self.min_point[0]}')
if node_distance <= self.min_point[0]:
# print(f'当前节点按{X_name}来分,且可往右right右节点,有可能搜索到近邻k')
self.find_K(node_arg.right, X_arg)
else:
# print(f'当前节点按{X_name}来分,且往右节点搜索')
self.find_K(node_arg.right, X_arg)
# print(f'当前节点距维度的距离为{node_distance},最近邻距离min为{self.min_point[0]}')
if node_distance <= self.min_point[0]:
# print(f'当前节点按{X_name}来分,且可往右left左节点,有可能搜索到近邻k')
self.find_K(node_arg.left, X_arg)
def predict(self):
all_predict.append([i[1][-1] for i in self.K_list])
# print(f"{[i[1][-1] for i in self.K_list]}")
a = Tree()
a.get_value_1(data)
all_predict = []
# print("____++++++++__________")
# a.pre_print(a.root)
# k = 5
def func(datas_arg):
# print(datas_arg)
ob = Find_KD_Tree()
ob.find_K(a.root,datas_arg)
# print("++++++++++++++++++++++++++++")
ob.predict()
data.apply(func,axis = 1)
for i in all_predict:
print(i)
附:KNN - sklearn代码(too easy)
from sklearn import neighbors
import time
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report
# 获取所需数据:'推荐分值', '专业度','回复速度','用户群活跃天数'
datas = pd.read_excel('./datas1.xlsx')
important_features = ['推荐类型','推荐分值', '专业度','回复速度','用户群活跃天数']
datas_1 = datas[important_features]
# 明确实值Y为'推荐分值',X分别为'专业度','回复速度','用户群活跃天数'
Y = datas_1['推荐类型']
X = datas_1.drop('推荐类型',axis=1)
start_time = time.time()
# 1. 建立模型
classifier = neighbors.KNeighborsClassifier(10)
classifier.fit(X,Y)
# 2. 学习模型
classifier.fit(X,Y)
Y_predict = classifier.predict(X)
result_P = classifier.predict_proba(X)
end_time = time.time()
# 3. 衡量模型
accurency = classifier.score(X,Y)
PRF = classification_report(Y,Y_predict)
# 输出模型最优状态下的参数及衡量模型的指标
print(f"KNN 耗时{end_time-start_time}秒")
print("KNN的分类【准备率】为:",accurency)
print("KNN的精确率、召回率、F1分数为:")
print(PRF)
print('【模型分类,实际分类】的对比如下:')
for index,value in enumerate(zip(Y_predict,Y)):
print(value)
print(result_P[index])
# print(result_P)