深信服技术认证之使用spark进行数据分析示例之拆分字段
背景:给定一数据集,结构如下:

数据说明:
| 字段 |
字段说明 |
| positionName |
职位名称 |
| salary |
薪水 |
| workYear |
工作年限 |
| city |
城市 |
| companyShortName |
公司简称 |
| companySize |
公司规模 |
| district |
所在区 |
| financeStage |
融资阶段 |
| industryField |
所在领域 |
| thirdType |
职位类型 |
| resumeProcessDay |
简历日处理 |
| resumeProcessRate |
简历处理率 |
任务:使用spark对给定的数据进行数据分析
要求:拆分字段salary -> min_salary,max_salry,并且取薪资的整数
说明:
如果salary字段是否包含类似'10k-20k*15薪'的值 如果存在 则把 *15这样的类似数据给去掉,保留10K-20K; 则拆分为 min_salary,max_salry 分别是 10,20,
如果salary字段 类似10-20K 则拆分为 min_salary,max_salry 分别是 10,20,
如果 salay字段为空值或者 面议,则拆分为 min_salary,max_salry 分别是 -1,-1,
拆分后字段 表结构为
| 字段 |
| positionName |
| salary |
| min_salary |
| max_salry |
| workYear |
| city |
| companyShortName |
| companySize |
| district |
| financeStage |
| industryField |
| thirdType |
| resumeProcessDay |
| resumeProcessRate |
分析思路:
根据逗号分隔为多列字段。
1、文件丢进去


2、上传到hdfs
[admin@Master ~]$ hadoop fs -mkdir /user/admin/spark

[admin@Master ~]$ hadoop fs -put zhaopin.txt /user/admin/spark
[admin@Master ~]$ hadoop fs -ls -R /user/admin/spark
![]()
3、进入shell交互
[admin@Master ~]$ spark-shell
scala>
import spark.implicits._
val Df1 = spark.read.textFile("/user/admin/spark/zhaopin.txt");
Df1.show
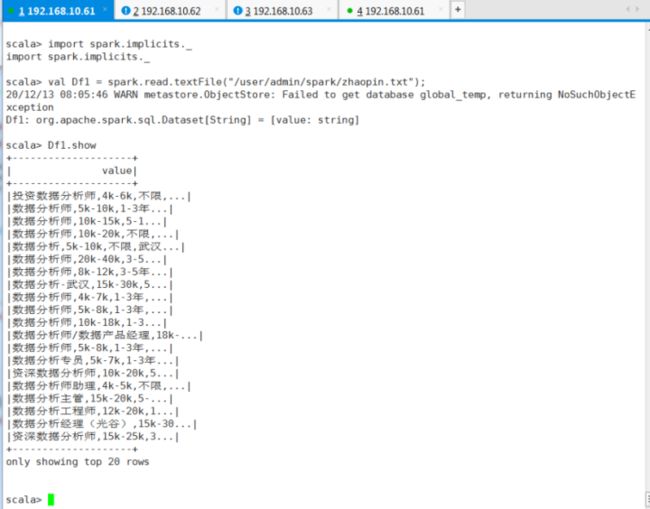
# 本部操作创建一个名为Df1的RDD.首先要确保zhaopin.txt在HDFS文件系统相应的路径中。
Df1.show
/**
* withColumn的第二个参数要传入已有列的Column对象,否则会报错;
* column的表达式只能引用此数据集提供的属性。 添加引用其他数据集的列是错误的
*/
val Df2 = Df1.withColumn("splitcol",split(Df1.col("value"), ",")).select(
col("splitcol").getItem(0).as("positionName"),
col("splitcol").getItem(1).as("salary"),
col("splitcol").getItem(2).as("workYear"),
col("splitcol").getItem(3).as("city"),
col("splitcol").getItem(4).as("companyShortName"),
col("splitcol").getItem(5).as("companySize"),
col("splitcol").getItem(6).as("district"),
col("splitcol").getItem(7).as("financeStage"),
col("splitcol").getItem(8).as("industryField"),
col("splitcol").getItem(9).as("thirdType"),
col("splitcol").getItem(10).as("resumeProcessDay"),
col("splitcol").getItem(11).as("resumeProcessRate")
).drop("splitcol");

Df2.show

Df2.write.csv("/user/admin/spark/output02");

如果双字符拆分,以逗号和短横线:
val Df3 = Df1.withColumn("splitcol",split(Df1.col("value"), ",|-")).select(
col("splitcol").getItem(0).as("positionName"),
col("splitcol").getItem(1).as("min_salary"),
col("splitcol").getItem(2).as("max_salry"),
col("splitcol").getItem(3).as("workYear"),
col("splitcol").getItem(4).as("city"),
col("splitcol").getItem(5).as("companyShortName"),
col("splitcol").getItem(6).as("companySize"),
col("splitcol").getItem(7).as("district"),
col("splitcol").getItem(8).as("financeStage"),
col("splitcol").getItem(9).as("industryField"),
col("splitcol").getItem(10).as("thirdType"),
col("splitcol").getItem(11).as("resumeProcessDay"),
col("splitcol").getItem(12).as("resumeProcessRate")
).drop("splitcol");
# 这个思路是有问题的,因为把年限也给分拆开了,表结构对应错位了。除非把年限也拆分为两个表结构字段。

Df3.show

val Df4 = Df3.withColumn("max_salry",regexp_replace(col("max_salry"), "\\*15", ""));
Df4.show

Df4.write.csv("/user/admin/spark/output04");

#RDD的saveASTextFile如果文件存在则无法追加写入,数据只能覆盖,对于有数据追加需求的人很不友好。而且saveASTextFile只能导出一列的数据,多列无效。所以不能用saveASTextFile方法。

val Df5 = Df4.withColumn("min_salary",regexp_replace(col("min_salary"), "k", ""));
Df5.show
val Df6 = Df5.withColumn("max_salry",regexp_replace(col("max_salry"), "k", ""));
Df6.show

如果只保留最低工资和最高工资两列:
Df2.show

val Df8 = Df2.withColumn("splitcol",split(col("salary"), "-")).select(
col("splitcol").getItem(0).as("min_salary"),
col("splitcol").getItem(1).as("max_salry")
).drop("splitcol");
Df8.show

Df8.write.csv("/user/admin/spark/output08") ;
Df6.show
import org.apache.spark.sql._
Df6.repartition(2).write.mode(SaveMode.Overwrite).text("/user/admin/spark/output02");
#报错,因为文本输出只支持一列数据,我们有13列,故报错。只能以csv格式导出。
注意:DataSrt[Row]格式的数据无法写入到text文件中,因为text文件不含表头信息,它只能保存一列的数据,多列的数据保存时会报错。
Df6.write.parquet("/user/admin/spark/output08") ;
# parquent是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录。Parquet是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与Parquet配合的组件有:
* 查询引擎: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
* 计算框架: MapReduce, Spark, Cascading, Crunch, Scalding, Kite
* 数据模型: Avro, Thrift, Protocol Buffers, POJOs
Spark已经为我们提供了parquet样例数据,就保存在“/usr/local/spark/examples/src/main/resources/”这个目录下,有个users.parquet文件,这个文件格式比较特殊,如果你用vim编辑器打开,或者用cat命令查看文件内容,肉眼是一堆乱七八糟的东西,是无法理解的。只有被加载到程序中以后,Spark会对这种格式进行解析,然后我们才能理解其中的数据。
parquet既保存数据又保存schema信息(列的名称、类型、列的偏移量(它的文件中没有换行,相同列的数据存在一起,而不是一个记录的数据存在一起))
问题:如果 salay字段为空值或者 面议,则拆分为 min_salary,max_salry 分别是 -1,-1,
import org.apache.spark.sql._
我们把原始数据改几个null进去。重新命名zhaopin01.txt上传。
[admin@Master ~]$ hadoop fs -put zhaopin01.txt /user/admin/spark
[admin@Master ~]$ hadoop fs -ls -R /user/admin/spark
import spark.implicits._
val Df11 = spark.read.textFile("/user/admin/spark/zhaopin01.txt");
Df11.show
val Df12 = Df11.na.fill(value="-1--1",Array[String]("value"));
#这种空值替换思路是错误的,因为只有一列,而null仅仅为列中的某字符串。
Df12.show
先拆分,以逗号分12列,再替换salary表结构字段下的空值为-1--1,然后再拆分salary,再去除不要的字符串*15和k。
val Df9 = Df11.withColumn("splitcol",split(Df11.col("value"), ",")).select(
col("splitcol").getItem(0).as("positionName"),
col("splitcol").getItem(1).as("salary"),
col("splitcol").getItem(2).as("workYear"),
col("splitcol").getItem(3).as("city"),
col("splitcol").getItem(4).as("companyShortName"),
col("splitcol").getItem(5).as("companySize"),
col("splitcol").getItem(6).as("district"),
col("splitcol").getItem(7).as("financeStage"),
col("splitcol").getItem(8).as("industryField"),
col("splitcol").getItem(9).as("thirdType"),
col("splitcol").getItem(10).as("resumeProcessDay"),
col("splitcol").getItem(11).as("resumeProcessRate")
).drop("splitcol");
Df9.show

val Df10 = Df9.na.fill(value="-1--1",Array[String]("salary"));
val Df10 = Df9.na.fill("-1--1",Seq("salary")).show
如果两列批量替换则:
val Df10 = Df9.na.fill("-1--1",Seq("salary","workYear")).show
#填充失败,暂时未找到原因。
Df10.show()
我们使用方法二:利用map进行填充,试试:
import java.util
var map = new util.HashMap[String, Any]()
map.put("salary","-1--1")
map.put("workYear","无")
println(map)
var Df20 = Df9.na.fill(map)
Df20.show()
#还是填充失败。
我们换个思路,先以“-”拆分,然后再对分开的两列进行一列一列的替换。或者清洗完再替换。
import org.apache.spark.sql._
val Df22 = Df20.withColumn("splitcol",split(col("salary"), "-")).select(
'positionName,
col("splitcol").getItem(0).as("min_salary"),
col("splitcol").getItem(1).as("max_salry"),
'workYear,
'city,
'companyShortName,
'companySize,
'district,
'financeStage,
'industryField,
'thirdType,
'resumeProcessDay,
'resumeProcessRate
).drop("splitcol");
Df22.show
然后,再清洗,去掉多余的字符串。
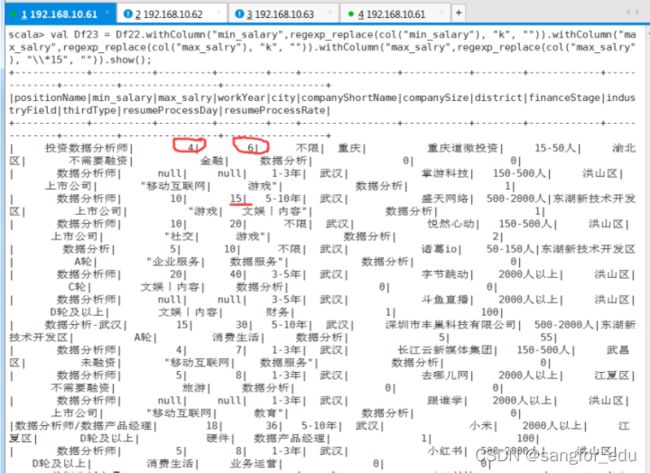
val Df23 = Df22.withColumn("min_salary",regexp_replace(col("min_salary"), "k", "")).withColumn("max_salry",regexp_replace(col("max_salry"), "k", "")).withColumn("max_salry",regexp_replace(col("max_salry"), "\\*15", ""));
Df23.show
val Df24 = Df23.na.fill(value="-1",Array[String]("min_salary"));
val Df25 = Df24.na.fill(value="-1",Array[String]("max_salry"));
或val Df24 = D23.na.fill("-1",Seq("min_salary"));
Df25.show

#可以看出max_salry修改成功,但是min_salary失败,应该是表格中的null不能手动写成null,手动应该写成空着就好。大家可以试一下。
通过以上示例,我们简单的学习了spark拆分字段方法。
文章作者傅先全:深信服云计算认证专家,产业教育中心资深讲师,曾任职于国内知名企业、某知名教育集团,分别担任云平台资深架构师、IT课程总监及名师团金牌讲师、四川某大学特聘企业讲师。十余年云计算、大数据行业从业经验,在企业信息化建设、企业项目管理、云平台架构设计等方面有较强的实战经验;对IT技术、云计算技术、大数据技术相关课程具备丰富的课程交付经验。