DistSQL 深度解析:打造动态化的分布式数据库
一、背景
自 ShardingSphere 5.0.0 版本发布以来,DistSQL 为 ShardingSphere 生态带来了强大的动态管理能力,通过 DistSQL,用户可以:
- 在线创建逻辑库;
- 动态配置规则(包括分片、数据加密、读写分离、数据库发现、影子库、全局规则等);
- 实时调整存储资源;
- 即时切换事务类型;
- 随时开关 SQL 日志;
- 预览 SQL 路由结果;
- …
同时,随着使用场景的深入,越来越多的 DistSQL 特性被发掘出来,众多宝藏语法也受到了用户的喜爱。
二、内容提要
本文将以数据分片为例,深度解析 Sharding 相关 DistSQL 的应用场景和使用技巧。同时,通过实践案例将一系列 DistSQL 语句进行串联,为读者展现一套完整实用的 DistSQL 分片管理方案。
本文案例中将用到以下 DistSQL:

三、实战演练
3.1 场景需求
- 创建两张分片表
t_order和t_order_item; - 两张表均以
user_id字段分库,以order_id字段分表; - 分片数量为 2 库 x 3 表;
如图:

3.2 环境准备
- 准备可供访问的 MySQL 数据库实例,创建两个新库
demo_ds_0、demo_ds_1;
以 MySQL 为例,也可使用 PostgreSQL 或 openGauss 数据库。
2.部署 Apache ShardingSphere-Proxy 5.1.2 和 Apache ZooKeeper,其中 ZooKeeper 将作为治理中心,存储 ShardingSphere 元数据信息;
3.配置 Proxy conf 目录下的 server.yaml,内容如下;
mode:
type: Cluster
repository:
type: ZooKeeper
props:
namespace: governance_ds
server-lists: localhost:2181 # ZooKeeper 地址
retryIntervalMilliseconds: 500
timeToLiveSeconds: 60
maxRetries: 3
operationTimeoutMilliseconds: 500
overwrite: false
rules:
- !AUTHORITY
users:
- root@%:root
- 启动 ShardingSphere-Proxy,并使用客户端连接到 Proxy,例如
mysql -h 127.0.0.1 -P 3307 -u root -p
3.3 添加存储资源
- 创建逻辑数据库
CREATE DATABASE sharding_db;USE sharding_db;
- 添加存储资源,对应之前准备的 MySQL 数据库
ADD RESOURCE ds_0 (
HOST=127.0.0.1,
PORT=3306,
DB=demo_ds_0,
USER=root,
PASSWORD=123456
), ds_1(
HOST=127.0.0.1,
PORT=3306,
DB=demo_ds_1,
USER=root,
PASSWORD=123456
);
- 查看存储资源
mysql> SHOW DATABASE RESOURCES\\G;
*************************** 1. row ***************************
name: ds_1
type: MySQL
host: 127.0.0.1
port: 3306
db: demo_ds_1
-- 省略部分属性
*************************** 2. row ***************************
name: ds_0
type: MySQL
host: 127.0.0.1
port: 3306
db: demo_ds_0
-- 省略部分属性
查询语句加了 \G 是为了让输出格式更易读,非必需。
3.4 创建分片规则
ShardingSphere 分片规则支持“常规分片”和“自动分片”两种配置方式,它们的分片效果是等价的,区别在于“自动分片”的配置定义更加简洁,而“常规分片”配置方式更加灵活自主。
还不了解“自动分片”的同学可以参考:
《DistSQL:像数据库一样使用 Apache ShardingSphere》
《分片利器 AutoTable:为用户带来「管家式」分片配置体验》
接下来,我们将采用“常规分片”的方式,使用 INLINE 表达式算法实现需求描述的分片场景。
3.4.1 主键生成器
- 创建主键生成器
CREATE SHARDING KEY GENERATOR snowflake\_key\_generator \(
TYPE(NAME=SNOWFLAKE)
);
- 查询主键生成器
mysql> SHOW SHARDING KEY GENERATORS;
+-------------------------+-----------+-------+
| name | type | props |
+-------------------------+-----------+-------+
| snowflake_key_generator | snowflake | {} |
+-------------------------+-----------+-------+
1 row in set (0.01 sec)
3.4.2 分片算法
- 创建一个分库算法,由
t_order和t_order_item共用
-- 分库时按 user_id 对 2 取模
CREATE SHARDING ALGORITHM database_inline (
TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="ds_${user_id % 2}"))
);
- 为
t_order和t_order_item创建不同的分表算法
-- 分表时按 order_id 对 3 取模
CREATE SHARDING ALGORITHM t_order_inline (
TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="t_order_${order_id % 3}"))
);
CREATE SHARDING ALGORITHM t_order_item_inline (
TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="t_order_item_${order_id % 3}"))
);
- 查询分片算法
mysql> SHOW SHARDING ALGORITHMS;
+---------------------+--------+---------------------------------------------------+
| name | type | props |
+---------------------+--------+---------------------------------------------------+
| database_inline | inline | algorithm-expression=ds_${user_id % 2} |
| t_order_inline | inline | algorithm-expression=t_order_${order_id % 3} |
| t_order_item_inline | inline | algorithm-expression=t_order_item_${order_id % 3} |
+---------------------+--------+---------------------------------------------------+
3 rows in set (0.00 sec)
3.4.3 默认分片策略
分片策略由分片键和分片算法组成,其概念可参考《分片策略》
分片策略包含分库策略(databaseStrategy)和分表策略(tableStrategy)。
由于t_order和 t_order_item 的分库字段和分库算法相同,我们创建一个默认策略,未配置分库策略的分片表都使用它:
- 创建默认分库策略
CREATE DEFAULT SHARDING DATABASE STRATEGY (
TYPE=STANDARD,SHARDING_COLUMN=user_id,SHARDING_ALGORITHM=database_inline
);
- 查询默认策略
mysql> SHOW DEFAULT SHARDING STRATEGY\G;
*************************** 1. row ***************************
name: TABLE
type: NONE
sharding_column:
sharding_algorithm_name:
sharding_algorithm_type:
sharding_algorithm_props:
*************************** 2. row ***************************
name: DATABASE
type: STANDARD
sharding_column: user_id
sharding_algorithm_name: database_inline
sharding_algorithm_type: inline
sharding_algorithm_props: {algorithm-expression=ds_${user_id % 2}}
2 rows in set (0.00 sec)
未配置默认分表策略,因此 TABLE 类型的默认策略是 NONE。
3.4.4 分片规则
主键生成器和分片算法都已就绪,现在开始创建分片规则:
- t_order
CREATE SHARDING TABLE RULE t_order (
DATANODES("ds_${0..1}.t_order_${0..2}"),
TABLE_STRATEGY(TYPE=STANDARD,SHARDING_COLUMN=order_id,SHARDING_ALGORITHM=t_order_inline),
KEY_GENERATE_STRATEGY(COLUMN=order_id,KEY_GENERATOR=snowflake_key_generator)
);
-
DATANODES 指定了分片表的数据节点;
-
TABLE_STRATEGY 指定了分表策略,其中 SHARDING_ALGORITHM 使用了已创建好的分片算法 t_order_inline;
-
KEY_GENERATE_STRATEGY 指定该表的主键生成策略,若不需要主键生成,可省略该配置。
- t_order_item
CREATE SHARDING TABLE RULE t_order_item (
DATANODES("ds_${0..1}.t_order_item_${0..2}"),
TABLE_STRATEGY(TYPE=STANDARD,SHARDING_COLUMN=order_id,SHARDING_ALGORITHM=t_order_item_inline),
KEY_GENERATE_STRATEGY(COLUMN=order_item_id,KEY_GENERATOR=snowflake_key_generator)
);
- 查询分片规则
mysql> SHOW SHARDING TABLE RULES\G;
*************************** 1. row ***************************
table: t_order
actual_data_nodes: ds_${0..1}.t_order_${0..2}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_${order_id % 3}
key_generate_column: order_id
key_generator_type: snowflake
key_generator_props:
*************************** 2. row ***************************
table: t_order_item
actual_data_nodes: ds_${0..1}.t_order_item_${0..2}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_item_${order_id % 3}
key_generate_column: order_item_id
key_generator_type: snowflake
key_generator_props:
2 rows in set (0.00 sec)
至此,t_order 和t_order_item的分片规则已配置完成。什么?有点复杂?
好吧,其实也可以忽略单独创建主键生成器、分片算法、默认策略的步骤,一步完成分片规则,让我们来加点糖。
3.5 语法糖
现在,需求中要增加一张分片表 t_order_detail,我们可以这样一步完成分片规则的创建:
CREATE SHARDING TABLE RULE t_order_detail (
DATANODES("ds_${0..1}.t_order_detail_${0..1}"),
DATABASE_STRATEGY(TYPE=STANDARD,SHARDING_COLUMN=user_id,SHARDING_ALGORITHM(TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="ds_${user_id % 2}")))),
TABLE_STRATEGY(TYPE=STANDARD,SHARDING_COLUMN=order_id,SHARDING_ALGORITHM(TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="t_order_detail_${order_id % 3}")))),
KEY_GENERATE_STRATEGY(COLUMN=detail_id,TYPE(NAME=snowflake))
);
说明:
上述语句中指定了分库策略、分表策略、主键生成策略,但都没有引用已经存在的算法,因此 DistSQL 引擎会自动用输入的表达式创建相应的算法,供 t_order_detail 分片规则使用。
此时我们再来查看主键生成器、分片算法和分片规则,结果如下:
- 主键生成器
mysql> SHOW SHARDING KEY GENERATORS;
+--------------------------+-----------+-------+
| name | type | props |
+--------------------------+-----------+-------+
| snowflake_key_generator | snowflake | {} |
| t_order_detail_snowflake | snowflake | {} |
+--------------------------+-----------+-------+
2 rows in set (0.00 sec)
- 分片算法
mysql> SHOW SHARDING ALGORITHMS;
+--------------------------------+--------+-----------------------------------------------------+
| name | type | props |
+--------------------------------+--------+-----------------------------------------------------+
| database_inline | inline | algorithm-expression=ds_${user_id % 2} |
| t_order_inline | inline | algorithm-expression=t_order_${order_id % 3} |
| t_order_item_inline | inline | algorithm-expression=t_order_item_${order_id % 3} |
| t_order_detail_database_inline | inline | algorithm-expression=ds_${user_id % 2} |
| t_order_detail_table_inline | inline | algorithm-expression=t_order_detail_${order_id % 3} |
+--------------------------------+--------+-----------------------------------------------------+
5 rows in set (0.00 sec)
- 分片规则
mysql> SHOW SHARDING TABLE RULES\G;
*************************** 1. row ***************************
table: t_order
actual_data_nodes: ds_${0..1}.t_order_${0..2}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_${order_id % 3}
key_generate_column: order_id
key_generator_type: snowflake
key_generator_props:
*************************** 2. row ***************************
table: t_order_item
actual_data_nodes: ds_${0..1}.t_order_item_${0..2}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_item_${order_id % 3}
key_generate_column: order_item_id
key_generator_type: snowflake
key_generator_props:
*************************** 3. row ***************************
table: t_order_detail
actual_data_nodes: ds_${0..1}.t_order_detail_${0..1}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_detail_${order_id % 3}
key_generate_column: detail_id
key_generator_type: snowflake
key_generator_props:
3 rows in set (0.01 sec)
*说明:
CREATE SHARDING TABLE RULE 语句中,DATABASE_STRATEGY、TABLE_STRATEGY 和 KEY_GENERATE_STRATEGY 均可以引用已有算法,达到复用的目的,也可以通过语法糖快速定义,差异是会创建额外的算法对象。用户可根据场景灵活搭配使用。
3.6 配置验证
规则创建完毕后,我们可以通过如下方式进行验证:
3.6.1 检查节点分布
DistSQL 提供 SHOW SHARDING TABLE NODES 的语法用于查看节点分布,帮助用户快速总览分片表的分布情况。使用方式如下:

从分片表的节点分布观察,与需求描述的分布一致。
3.6.2 SQL 预览
SQL 预览,也是验证配置的一种快捷的方式,语法是 PREVIEW sql:
- 无分片键查询,全路由

2. 指定 user_id 查询,单库路由

3.指定 user_id 和 order_id,单表路由

单表路由扫描的分片表最少,效率最高。
3.7 辅助查询 DistSQL
在系统维护过程中,可能会出现不再使用的算法或存储资源需要释放,或是想要释放的资源被引用了无法删除,以下 DistSQL 可以为我们提供帮助:
3.7.1 查询未使用的资源
- 语法:SHOW UNUSED RESOURCES
- 示例:
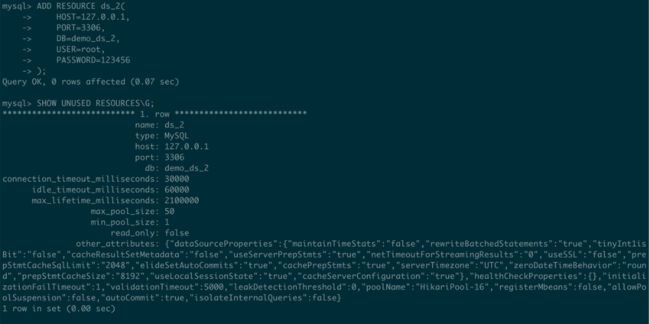
3.7.2 查询未使用的主键生成器
- 语法:SHOW UNUSED SHARDING KEY GENERATORS
- 示例:

3.7.3 查询未使用的分片算法
1.语法:SHOW UNUSED SHARDING ALGORITHMS
2. 示例:

3.7.4 查询使用目标存储资源的规则
- 语法:SHOW RULES USED RESOURCE
- 示例:

使用了该资源的所有规则都会查询出来,不限于Sharding Rule。
3.7.5 查询使用目标主键生成器的分片规则
- 语法:SHOW SHARDING TABLE RULES USED KEY GENERATOR
- 示例:

3.7.6 查询使用目标算法的分片规则
- 语法:SHOW SHARDING TABLE RULES USED ALGORITHM
- 示例:

4、结语
本篇以常用的数据分片场景为例,介绍了 DistSQL 的使用流程和应用技巧。同时,DistSQL 提供了灵活的语法糖以帮助减少操作步骤,用户可灵活选择使用。
在分片场景下,除了 INLINE 算法,DistSQL 也能完美支持其他的标准分片、复合分片、Hint 分片、自定义类分片算法,更多的应用案例将在后续的文章中为大家解读,敬请期待。
以上就是本次分享的全部内容,如果读者对 Apache ShardingSphere 有任何疑问或建议,欢迎在 GitHub issue 列表提出,或可前往中文社区交流讨论。
GitHub issue:https://github.com/apache/shardingsphere/issues
贡献指南:https://shardingsphere.apache.org/community/cn/contribute/
中文社区:https://community.sphere-ex.com/
5、参考文献
- 概念 DistSQL:https://shardingsphere.apache.org/document/current/cn/concepts/distsql/
- 概念 分布式主键:https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/key-generator/
- 概念 分片策略:https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/sharding/
- 概念 行表达式:https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/inline-expression/
- 内置分片算法:https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/builtin-algorithm/sharding/
- 用户手册:DistSQLhttps://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-proxy/distsql/syntax/
作者
江龙滔,SphereEx 中间件研发工程师,Apache ShardingSphere Committer。
主要负责 DistSQL 及安全相关特性的创新与研发。
欢迎点击链接,了解更多内容:
Apache ShardingSphere 官网:https://shardingsphere.apache.org/
Apache ShardingSphere GitHub 地址:https://github.com/apache/shardingsphere
SphereEx 官网:https://www.sphere-ex.com
欢迎添加社区经理微信(ss_assistant_1)加入交流群,与众多 ShardingSphere 爱好者一同交流。