MyCat总结
目录
什么是mycat
核心概念
逻辑库
逻辑表
分片节点
数据库主机
用户
mycat原理
目录结构
配置文件
读写分离
搭建读写分离
搭建主从复制:
搭建读写分离:
分片技术
垂直拆分
实现分库:
水平拆分
实现分库:
ER表
全局表
分片规则(分片算法)
取模
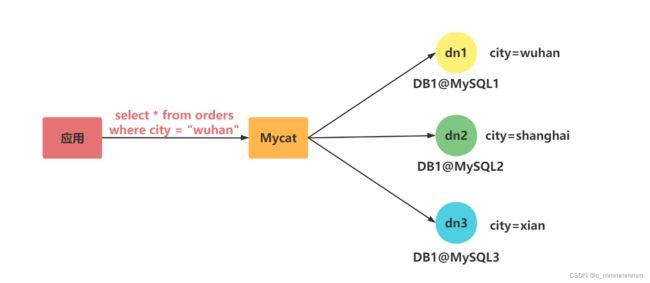
分片枚举
范围分片
时间天分片
全局序列
高可用
高可用概述
HAProxy实现高可用
keepalived实现高可用
权限
User标签
privileges标签
安全设置
SQL拦截白名单
SQL拦截黑名单
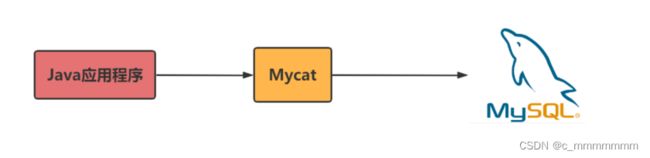
什么是mycat
mycat是数据库的中间件,mycat的作用就是实现了数据库的高可用以及负载均衡
核心概念
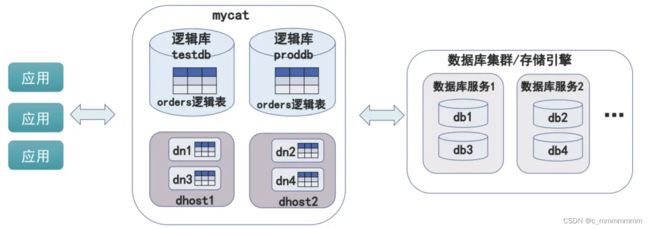
逻辑库
业务开发人员通常在实际应用中不需要知道中间件的存在,只需要关注数据库,所以数据库中间件可以被一个或多个数据库集群构成的逻辑库
注意:
逻辑库,与MySQL中的Database(数据库)对应,⼀个逻辑库中定义了所包括的Table。
逻辑表
既然有逻辑库,就会有逻辑表。在分布式数据库中,对于应用来说,读写数据的表就是逻辑表。逻辑表可以分布在一个或多个分片库中,也可以不分片
注意:
Table:表,即物理数据库中存储的某⼀张表,与传统数据库不同,这⾥的表格需要声明其所存储的逻辑数据节点DataNode。
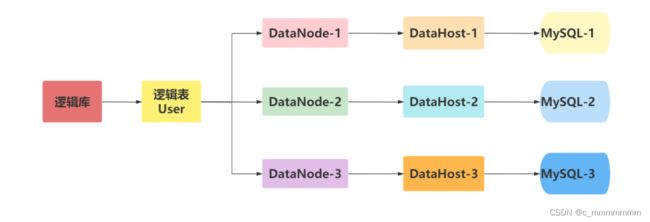
分片节点
将数据切分后,每个分片节点不一定会独占一台机器,同一台机器上可以有多个分片数据库,这样一个或多个分片节点所在的机器就是节点主机,为了规避节点主机并发数量的限制,尽量将读写压力大的分片节点均匀地放在不同的节点主机上
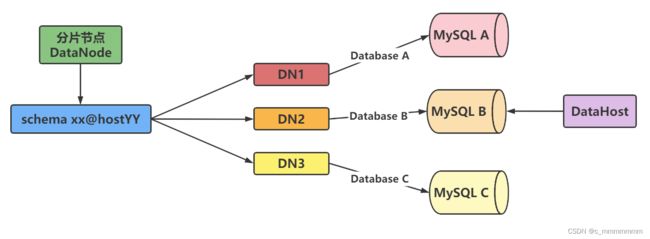
数据库主机
数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
用户
MyCat的用户(类似于MySQL的用户,支持多用户)

mycat原理
Mycat 的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL 语句。
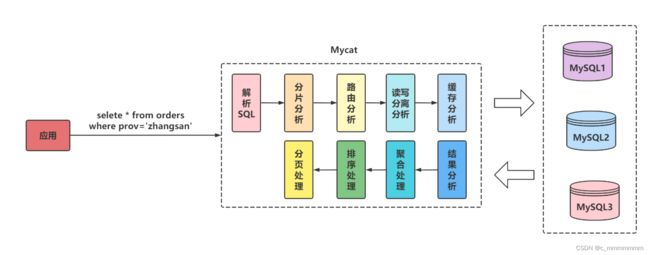
流程:
首先对 SQL 语句做了一些特定的分析:如分片分析、路由分析、读写分离 分析、缓存分析等,然后将此 SQL 发 往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
流程示例
- 解析SQL语句涉及的表。
- 查看表的定义,如果表存在分片规则,则获取SQL语句的分片字段。
- 将SQL语句发送到相应的分片去执行。
- 最后处理所有分片返回的数据并返回给客户端。
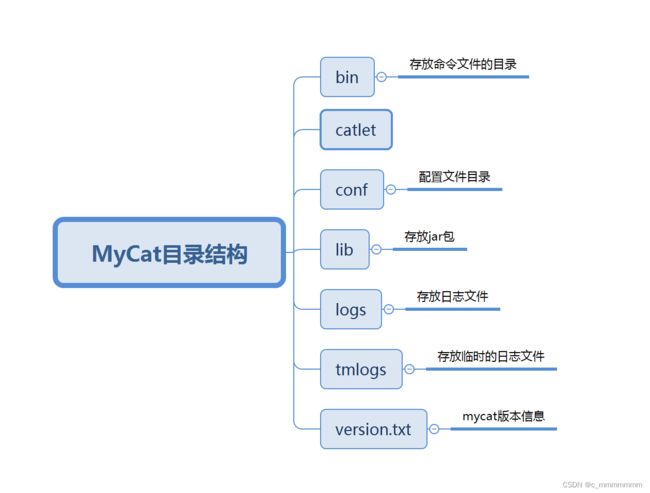
目录结构
配置文件
三个核心配置文件
(只需要记住这三个就可以使用mycat大部分操作)
- schema.xml:定义逻辑库,表、切(分)片节点等内容
- rule.xml:定义切(分)片规则
- server.xml:定义用户以及系统相关变量,如端口等
读写分离
读写分离基本的原理是让主数据库处理事务性增删改操作,而从数据库处理查询操作
为什么使用读写分离
从集中到分布,最基本的一个需求不是数据存储的瓶颈,而是在于 计算的瓶颈,即 SQL 查询的瓶颈,我们知道,正常情况下,Insert SQL 就是几十个毫秒的时间内写入完成,而系 统中的大多数 Select SQL 则要几秒到几分钟才能有结果,很多复杂的 SQL,其消耗服务器 CPU 的能力超强,不亚于死循环的威力。
读写分离方案
MyCat的读写分离是建立在MySQL主从复制基础之上实现的,所以必须先搭建MySQL的主从复制。数据库读写分离对于⼤型系统或者访问量很⾼的互联网应用来说,是必不可少的⼀个重要功能。
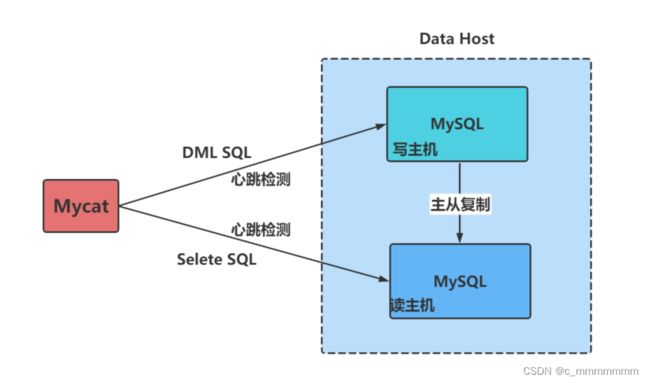
注意:
Mycat实现的读写分离和自动切换机制,需要MySQL的主从复制机制配合。
搭建读写分离
首先搭建读写分离之前,我们需要搭建数据库的主从复制,你想想如果主从两个数据库的数据都不同,读写分离还有什么作用呢?
主从复制的作用就是让主从数据库的数据保持一致,从数据库从主数据库中的log-bin文件中复制执行的sql语句到自己的relay log文件中,从数据库开启一个线程定时检查relay log文件,如果发现有更新立即把更新的内容在本地的数据库上执行,log-bin文件是主数据库的二进制日志文件
搭建主从复制:
首先在两台虚拟机中安装数据库,安装数据库的过程我这里就不描述了,
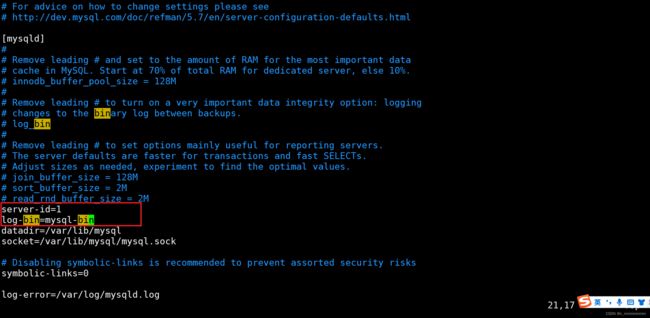
1、主数据库操作/etc/my.cnf,添加如下配置
修改配置文件:vim /etc/my.cnf
#主服务器唯一ID
server-id=1
#启用二进制日志
log-bin=mysql-bin
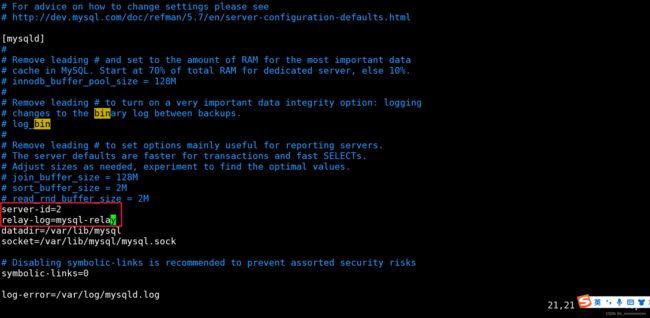
2、 修改从数据库添加如下配置
修改配置文件:vim /etc/my.cnf
#从服务器唯一ID
server-id=2
#启用中继日志
relay-log=mysql-relay
3、重启两台服务器的mysql
service mysqld restart
4、在主服务器上建立帐户并授权slave
mysql>GRANT REPLICATION SLAVE ON *.* to 'slave'@'%' identified by '123456';
注意:
一般不用root帐号,“%”表示所有客户端都可能连,只要帐号,密码正确,此处可用具体客户端IP代替,如192.168.145.226,加强安全。
5、查询Master的状态
mysql>show master status;
+------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------+-----------+--------------+--------------+
| mysql-bin.000004 | 308 | |
+-----------+----------+--------------+------------------+
1 row in set (0.00 sec)
配置从服务器Slave
mysql>change master to master_host='192.168.66.101',master_user='slave',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=430;
这里的加粗字体根据实际情况来写,不是固定的,这四个的意思分别是:主数据库的ip地址,主数据库连接的用户名和密码,主数据库的log_file名字,主数据库log的偏移量
注意:
注意不要断开,308数字前后无单引号。
启动从服务器复制功能
mysql>start slave;
检查从服务器复制功能状态
show slave status \G;
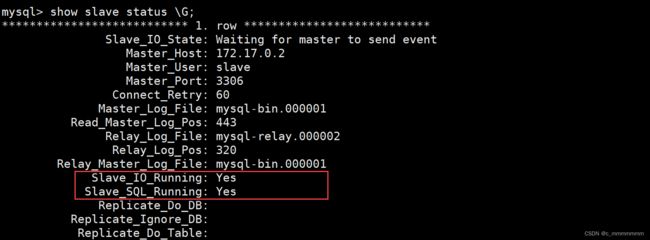
注意:
Slave_IO及Slave_SQL进程必须正常运行,即YES状态,否则都是错误的状态(如:其中一个NO均属错误)。
主从服务器测试
主服务器Mysql,建立数据库,并在这个库中建表插入一条数据
mysql>create database hi_db;
Query OK,1 row affected (0.00sec)
mysql>use hi_db;
Database changed
mysql>create table hi_tb(id int(3),name char(10));
Query OK,0 rows affected (0.00sec)
mysql>insert into hi_tb values(001,'baizhan');
Query OK,1 row affected (0.00sec)
从服务器Mysql查询
mysql>show databases;
mysql>use hi_db
mysql>select * from hi_tb;
搭建读写分离:
1、首先下载mycat,在opt目录下wget该文件
wget http://dl.mycat.org.cn/1.6.7.6/20201104174609/Mycat-server-1.6.7.6-test-20201104174609-linux.tar.gz
2、tar -zxvf Mycat-server-1.6.7.6-test-20201104174609-linux.tar.gz -C /usr/local
3、进入/usr/local/mycat/conf目录中操作schema.xml文件,schema.xml文件初始是有内容的,我们可以删改一些内容,然后再进行修改,写的配置和读的配置都不是固定的,大家根据自己的数据库地址修改
writeHost和readHost分别定义了读在哪个数据库,写在哪个数据库,writeHost一定要在主数据库,因为我们通过主从复制实现了数据的一致性,但是只能从数据库复制主数据库,所以写的操作一定要在主数据库上实现
?xml version="1.0"?>
2、创建数据库db_test在主数据库
create databases db_test;
3、进入bin目录,启动mycat
./mycat start
4、测试写操作
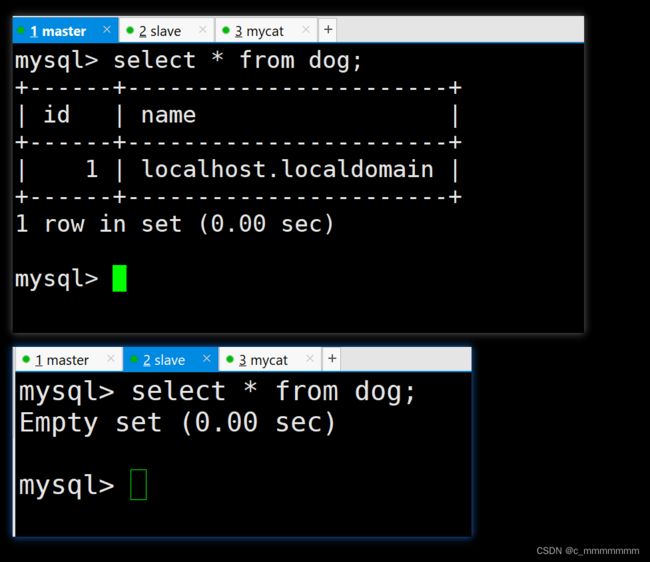
首先登录mysql -uroot -p123456 -h192.168.138.104 -P8066,这里是登录mycat
5、在主数据库创建表dog,字段为id和name
create table dog(id int(11),name varchar(40));
6、在mycat中执行写操作,首先我们需要停止主从复制,因为如果需要测试哪台数据库执行了写的操作的话,就需要停止主从复制,如果我们没有停止主从复制,那么我们执行完写的操作之后,会通过主从复制的方式将写的内容复制到从数据库
进入从数据库,执行stop slave;
7、在mycat中执行写的操作
insert into dog values(1,@@hostname);
注意:
@@代表系统变量。
在mycat查询
select * from dog;
分片技术
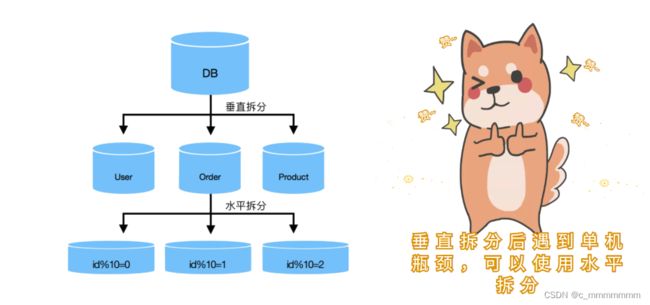
垂直拆分
前沿
目前很多互联网系统都存在单表数据量过大的问题,这就降低了查询速度,影响了客户体验。为了提高查询速度,我们可以优化sql语句,优化表结构和索引,不过对那些百万级千万级的数据库表,即便是优化过后,查询速度还是满足不了要求。
垂直分割
垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。表的记录并不多,但是字段却很长,表占用空间很大,检索表的时候需要执行大量的IO,严重降低了性能。这时需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。

拆分原则:
- 把不常用的字段单独放在一张表
- 把text,blob等大字段拆分出来放在附表中
- 经常组合查询的列放在一张表中
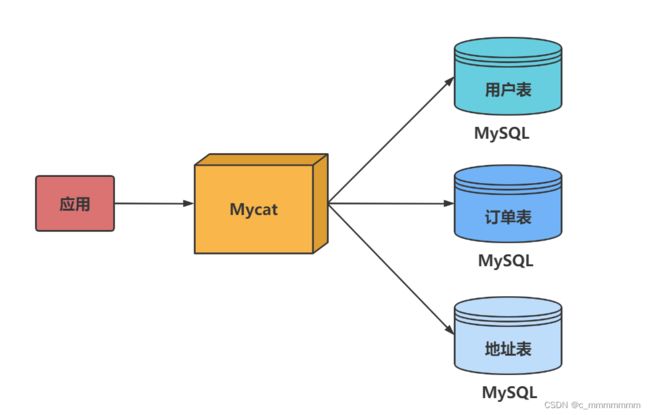
举个例子

拆分思路:
如果我们只想查询id为8的学生的分数:select 分数 from 答题表 where id = 8;虽然知识查询分数,但是题目和回答这两个大字段也是要被扫描的,很消耗性能。但是我们只关心分数,并不想查询题目和回答。这就可以使用垂直分割。
实现分库:
1、修改schema.xml配置文件
select user()
select user()
2、新增两个空白库
分库操作不是在原来的老数据库上进行操作,需要准备两台机器分别安装新的数据库
#在数据节点 dn1、dn2 上分别创建数据库 orders
CREATE DATABASE orders;
3、启动Mycat
./mycat start
4、Mycat进行分库
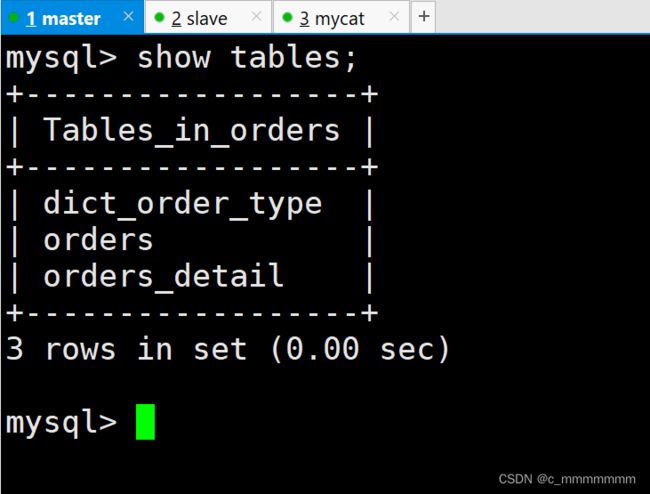
#创建表
mysql> use TESTDB;
# 使用 mycat 创建四个表
create table customer(
id int auto_increment,
name varchar(200),
primary key(id)
);
create table orders(
id int auto_increment,
order_type int,
customer_id int,
amount decimal(10,2),
primary key(id)
);
create table orders_detail(
id int auto_increment,
order_id int,
detail varchar(200),
primary key(id)
);
create table dict_order_type(
id int auto_increment,
order_type varchar(200),
primary key(id)
);5、主从数据库查询表
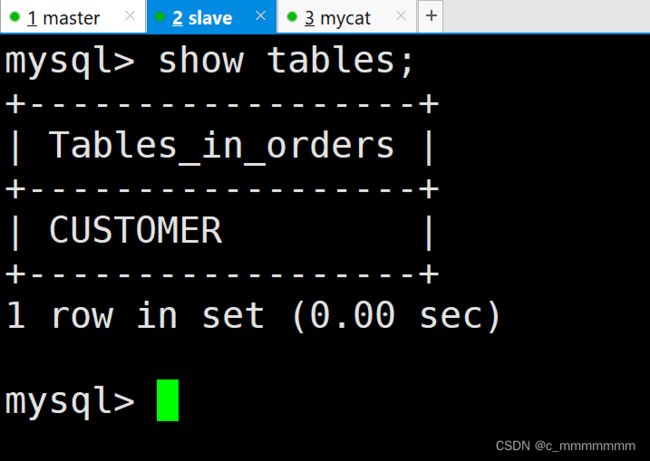
水平拆分
前言
上面谈到垂直切分只是把表按模块划分到不同数据库,但没有解决单表大数据量的问题。
水平拆分
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。
理解:
我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中。
实现分库:
1、 选择要拆分的表
MySQL 单表存储数据条数是有瓶颈的,单表达到 1000 万条数据就达到了瓶颈,会影响查询效率,需要进行水平拆分(分表)进行优化。
2、分表字段
以 orders 表为例,可以根据不同自字段进行分表
| 编号 |
分表字段 |
效果 |
| 1 |
id |
查询订单注重时效,历史订单被查询的次数少,如此分片会造成一个节点访问多,一个访问少,不平均。 |
| 2 |
customer_id |
根据客户 id 去分,两个节点访问平均 |
3、 修改配置文件 schema.xml
为 orders 表设置数据节点为 dn1、dn2,并指定分片规则为 mod_rule(自定义的名字)
4、在配置文件rule.xml中添加自定义的分片规则并指定分片规则的算法

分片规则:
在 rule 配置文件里新增分片规则 mod_rule,并指定规则适用字段为 customer_id, 还有选择分片算法 mod-long(对字段求模运算),customer_id 对两个节点求模,根据结果分片.配置算法 mod-long 参数 count 为 2,两个节点。
customer_id
mod-long
2
5、 在数据节点dn2上建orders表
create table orders(
id int auto_increment,
order_type int,
customer_id int,
amount decimal(10,2),
primary key(id)
);
6、 重启Mycat,让配置生效
mycat restart
7、 访问Mycat实现分片
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);查询主数据库和从数据库
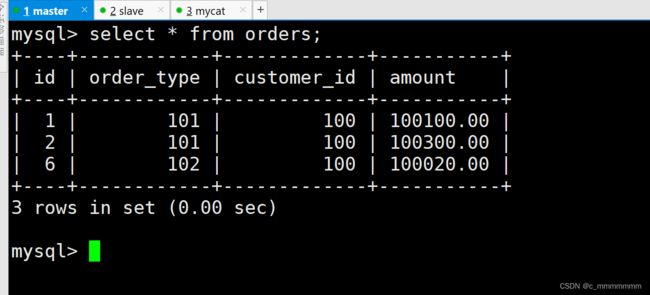
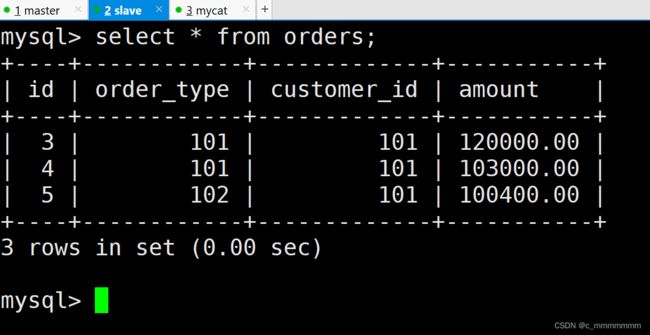
ER表
分片 join
遇到问题:
orders表分片了,那和他相关的orders_detail 表未分片, join联查的时候, master1正常查询出结果, master2上由于没有 orders_detail 表,则报错, 最后聚合结果肯定也是错误的。
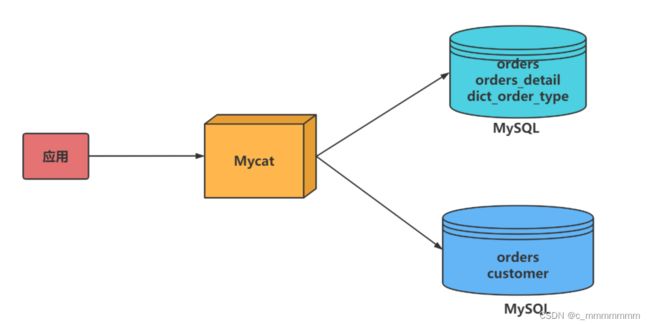
ER 表
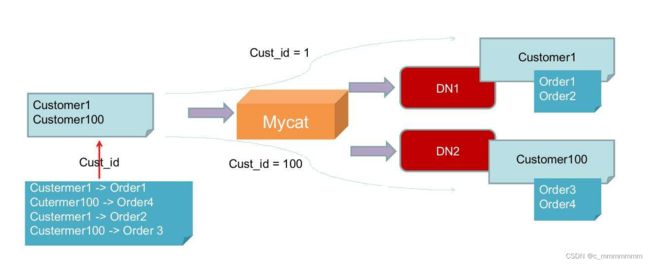
将子表的存储位置依赖于主表,并且物理上紧邻存放因此彻底解决了JION的效率和性能问题,根据这一思路,提出了基于E-R关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上。
修改配置文件schema.xml(在表的下面添加子表,以后只要有orders表的数据库就一定会有orders_detail表)
参数:
- childTable:子表
从数据库上没有订单详情表创建一下
create table orders_detail(
id int auto_increment,
order_id int,
detail varchar(200),
primary key(id)
);重启Mycat服务
mycat restart
Mycat服务添加数据
insert into orders_detail(detail, order_id) values('detail1',1);
insert into orders_detail(detail, order_id) values('detail1',2);
insert into orders_detail(detail, order_id) values('detail1',3);
insert into orders_detail(detail, order_id) values('detail1',4);
insert into orders_detail(detail, order_id) values('detail1',5);
测试数据
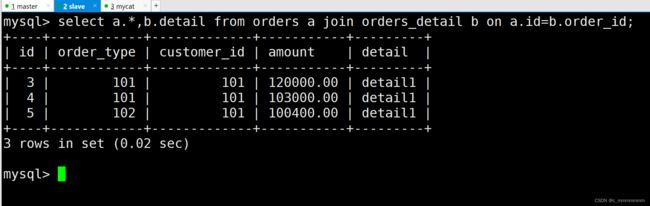
select a.*,b.detail from orders a join orders_detail b on a.id=b.order_id;
主数据库:
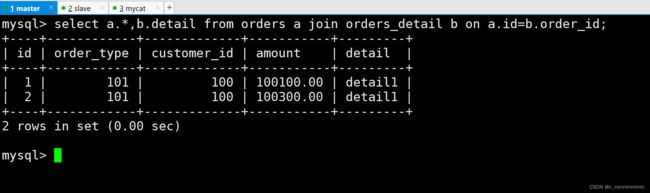
从数据库:
全局表
全局表描述
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,考虑到字典表具有以下几个特性:
- 变动不频繁
- 数据量总体变化不大
- 数据规模不大,很少有超过数十万条记录。
全局表特征
- 全局表的插入更新操作会实时在所有节点上执行,保持各个分片的数据一致。
- 全局表的查询操作,只从一个节点获取。
- 全局表可以和任何一个表进行 JOIN 操作。
注意:
将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据JOIN 的难题。通过全局表+基于E-R 关系的分片策略,Mycat 可以满足 80%以上的企业应用开发。
配置全局表
在dn2创建 dict_order_type 表
#订单类型字典表
create table dict_order_type(
id int auto_increment,
order_type varchar(200),
primary key(id)
);重启Mycat
mycat restart
Mycat上添加数据
insert into dict_order_type(id,order_type)values(101,'type1');
insert into dict_order_type(id,order_type)values(102,'type2');测试数据
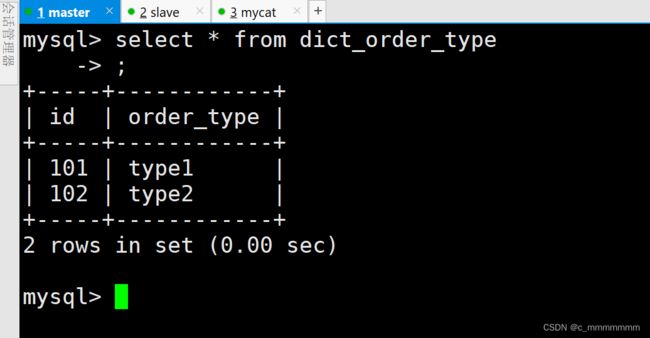
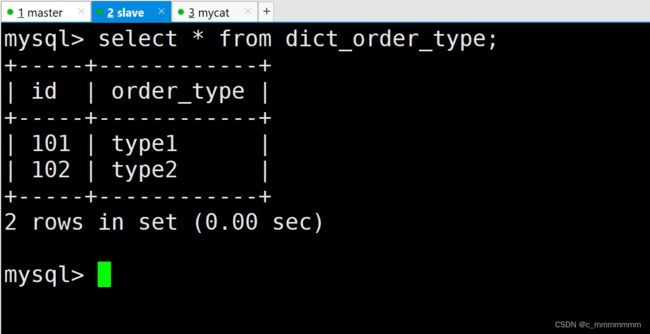
select * from dict_order_type;
主数据库:
从数据库:
分片规则(分片算法)
取模
实现方式
取模分片就是根据数据表的某一个字段,通常是某一个整数型的字段,对其进行十进制的求模运算,将运算结果作为Mycat的路由结果。
注意:
- 优点:这种策略可以很好的分散数据库写的压力。
- 缺点:出现了范围查询,就需要MyCAT去合并结果,当数据量偏高的时候,这种跨库查询+合并结果消耗的时间有可能会增加很多,尤其是还出现了order by的时候。
tableRule 标签
这个标签定义表规则。
user_id
mod-long
参数:
- name :属性指定唯一的名字,用于标识不同的表规则。 内嵌的 rule 标签则指定对物理表中的哪一列进行拆分和使用什么路由算法。
- columns :根据哪个字段进行取模
- algorithm:使用 function 标签中的 name 属性。连接表规则和具体路由算法。当然,多个表规则可以连接到 同一个路由算法上。
function标签
定义具体路由算法
2
注意:
- name 指定算法的名字。
- class 制定路由算法具体的类名字。
- property 为具体算法需要用到的一些属性。
- count:表示需要取模的最大值,将数据分成该配置的切片。
分片枚举
实现原理
有些业务需要按照省份或区县来做保存,这类业务使用本条规则。
根据某个字段的值在文件中匹配数字,数字则代表某一个分片节点
实现过程
在这里,需定义三个值,规则均是在rule.xml中定义。
• tableRule
• function
• mapFile
创建示例表
#订单归属区域信息表
CREATE TABLE orders_ware_info(
`id` INT AUTO_INCREMENT comment '编号',
`order_id` INT comment '订单编号',
`address` VARCHAR(200) comment '地址',
`areacode` VARCHAR(20) comment '区域编号',
PRIMARY KEY(id)
);修改schema.xml配置文件
定义tableRule
areacode
hash-int
注意:
其中,sharding-by-intfile-test是规则名,会在schema.xml中用到。columns指的是对省份进行分片。algorithm是算法名,该算法必须在function中定义。
定义funtion
partition-hash-int.txt
1
0
注意:
• mapFile:指的是配置文件名
• type:默认值为0,0表示Integer,非零表示String。因为我接下来的测试是基于省份分片,所以需type指定为1。
• defaultNode 默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点 默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点。
修改partition-hash-int.txt配置文件
(该文件的作用就是将根据对应字段的值匹配,如果是110则前往第零个分片节点,如果是120则前往第一个分片节点)
110=0
120=1
注意:
其中,110会被分发到第一个节点中,120分发被第二个节点中。
重启Mycat
mycat restart
插入数据
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (1,1,'beijing','110');
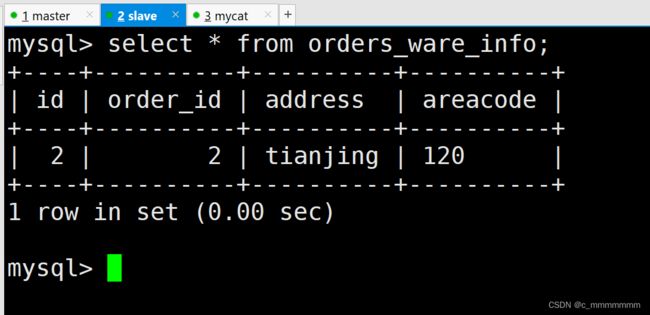
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (2,2,'tianjing','120');
主数据库:
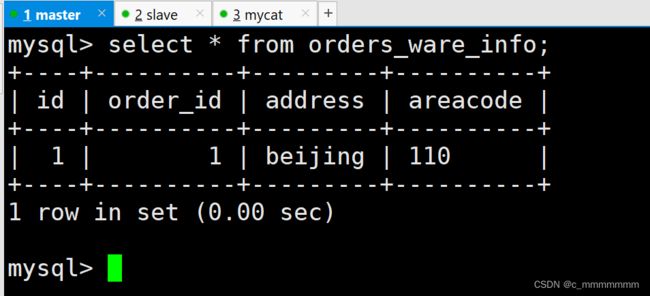
从数据库:
范围分片
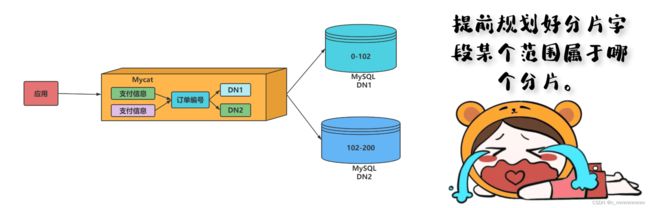
实现原理
此分片适用于,提前规划好分片字段某个范围属于哪个分片。
根据某个字段的值的范围去决定该表是使用哪个分片节点
举个例子
比如将id在0-500W的数据分片在第一个节点上面,将id在500W-1000W的数据分片在第二个节点上,依次类推下去。
优缺点:
实现过程
1、创建示例表
#支付信息表
CREATE TABLE payment_info
(
`id` INT AUTO_INCREMENT comment '编号',
`order_id` INT comment '订单编号',
`payment_status` INT comment '支付状态',
PRIMARY KEY(id)
);2、修改schema.xml配置文件
3、定义tableRule
order_id
rang-long
注意:
其中,auto_sharding_long是规则名,会在schema.xml中用到。columns指的是对订单id进行分片。algorithm是算法名,该算法必须在function中定义。
4、定义function
autopartition-long.txt
0
注意:
5、修改autopartition-long.txt配置文件
0-102=0
103-200=1
6、重启Mycat
mycat restart
7、插入数据
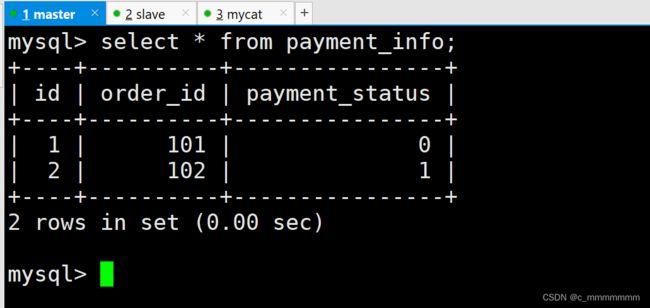
INSERT INTO payment_info (id,order_id,payment_status) VALUES (1,101,0);
INSERT INTO payment_info (id,order_id,payment_status) VALUES (2,102,1);
INSERT INTO payment_info (id,order_id ,payment_status) VALUES (3,103,0);
INSERT INTO payment_info (id,order_id,payment_status) VALUES (4,104,1);- mapFile:指的是配置文件名
- type:默认值为0,0表示Integer,非零表示String。因为我接下来的测试是基于省份分片,所以需type指定为1。
- defaultNode 默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点 默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点。
- 优点:适用于想明确知道某个分片字段的某个范围具体在哪一个节点;
- 缺点:如果短时间内有大量的批量插入操作,那么某个分片节点可能一下子会承受比较大的数据库压力,而别的分片节点此时可能处于闲置状态,无法利用其它节点进行分担压力(热点数据问题);
主数据库:
从数据库:
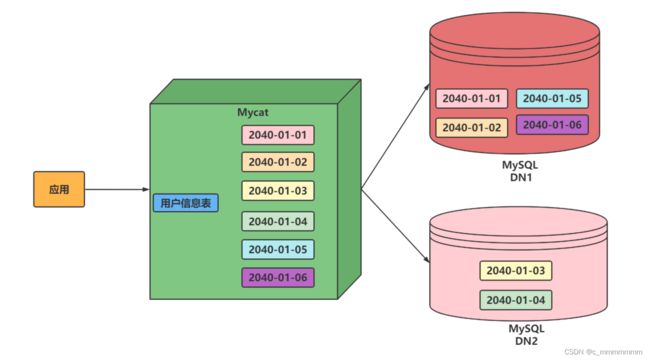
时间天分片
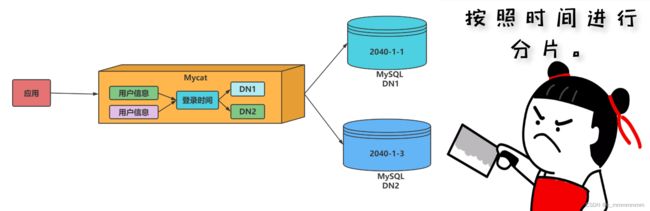
实现原理
此规则为按天分片,设定时间格式、范围。
实现过程
创建示例表
#用户信息表
create table login_info(
id int auto_increment comment '编号',
user_id int comment '用户编号',
login_date date comment '登录时间',
primary key(id)
);修改schema.xml配置文件
修改rule.xml配置文件
login_date
shardingByDate
定义function
yyyy-MM-dd
2040-01-01
2040-01-04
2
参数:
- columns:分片字段,algorithm:分片函数
- dateFormat :日期格式
- sBeginDate :开始日期
- sEndDate:结束日期,则代表数据达到了这个日期的分片后循环从开始分片插入
- sPartionDay :分区天数,即默认从开始日期算起,分隔 2 天一个分区
重启Mycat
mycat restart
插入数据
insert into login_info(id,user_id,login_date) values(1,101,'2040-01-01');
insert into login_info(id,user_id,login_date) values(2,102,'2040-01-02');
insert into login_info(id,user_id,login_date) values(3,103,'2040-01-03');
insert into login_info(id,user_id,login_date) values(4,104,'2040-01-04');
insert into login_info(id,user_id,login_date) values(5,105,'2040-01-05');
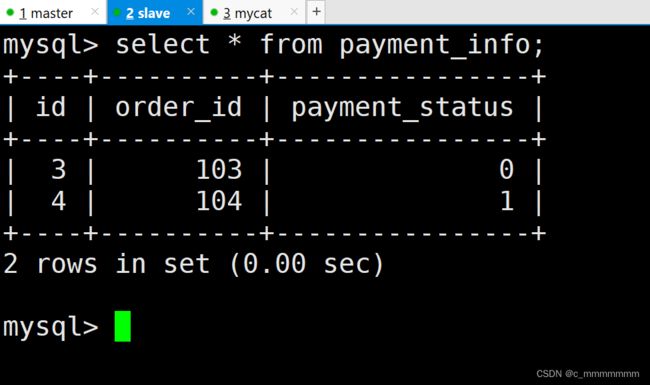
insert into login_info(id,user_id,login_date) values(6,106,'2040-01-06');主数据库:
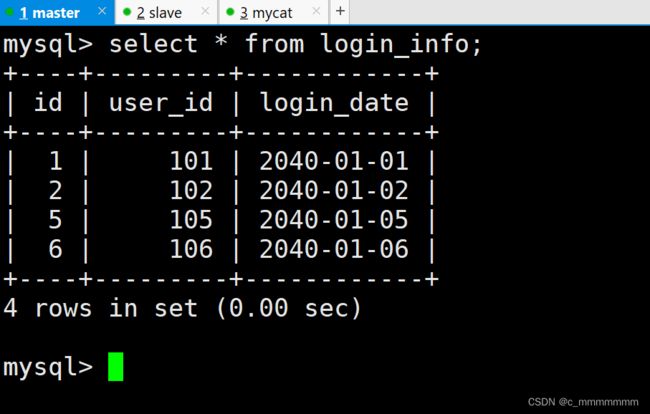 从数据库:
从数据库:
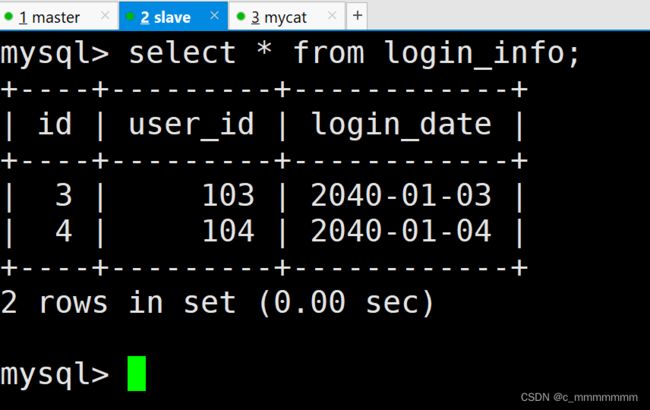
全局序列
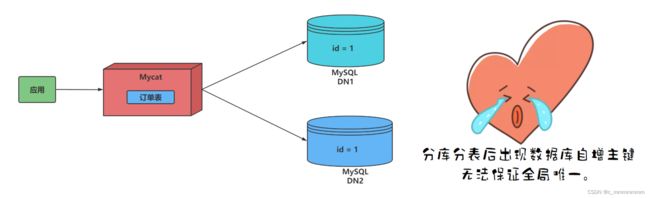
在实现分库分表的情况下,数据库自增主键已无法保证全局唯一。
解决方案
1、本地文件
此方式Mycat将sequence配置到文件中,当使用到 sequence中的配置后,Mycat会更下classpath中的 sequence_conf.properties 文件中sequence当前的值。
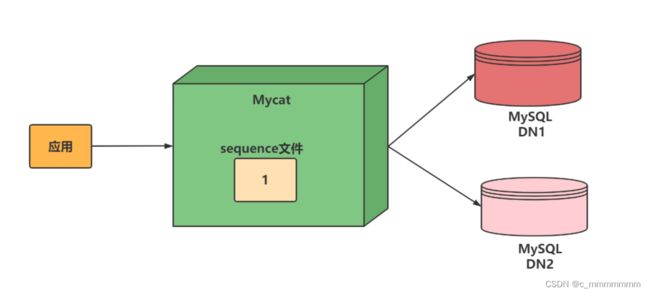
注意:
- 优点:本地加载,读取速度较快
- 缺点:抗风险能力差,Mycat 所在主机宕机后,无法读取本地文件。
2、本地时间戳方式
全局序列ID=64位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加) 换算成十进制为18位数的long类型,每毫秒可以并发12位二进制的累加。
优缺点:
- 优点:配置简单
- 缺点:18位ID过长
3、数据库方式
利用数据库一个表来进行计数累加。但是并不是每次生成序列都读写数据库,这样效率太低。Mycat 会预加载一部分号段到 Mycat 的内存中,这样大部分读写序列都是在内存中完成的。如果内存中的号段用完了 Mycat 会再向数据库要一次。
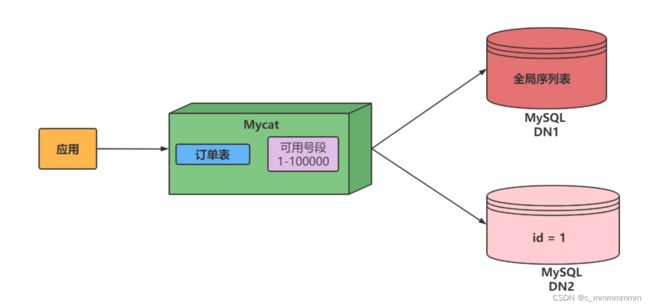
原理:
在数据库中建立一张表,存放 sequence 名称(name),sequence 当前值(current_value),步长(increment int 类型每次读取多少个 sequence,假设为 K)等信息;
数据库解决全局序列
修改Mycat配置文件server.xml
#全局序列类型:0-本地文件,1-数据库方式,2-时间戳方式。此处应该修改成1。
1 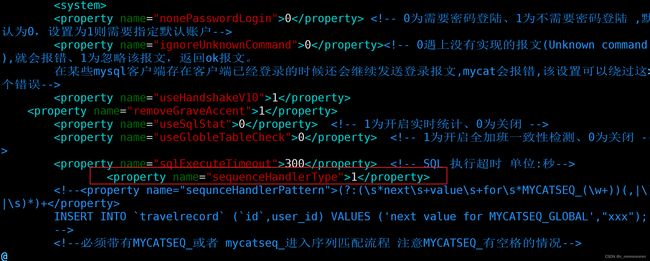
修改Mycat配置文件schema.xml
修改Mycat 配置文件 sequence_db_conf.properties
最下面添加MYCAT=dn2,告诉mycat:dn2放了全局序列表
GLOBAL=dn1
COMPANY=dn1
CUSTOMER=dn1
ORDERS=dn1
MYCAT=dn2
在dn2节点的orders数据库中添加 MYCAT_SEQUENCE表
DROP TABLE IF EXISTS MYCAT_SEQUENCE;
CREATE TABLE MYCAT_SEQUENCE (name VARCHAR(50) NOT NULL,current_value INT NOT NULL,increment INT NOT NULL DEFAULT 100, PRIMARY KEY(name)) ENGINE=InnoDB;
MYCAT_SEQUENCE 表插入sequence初始记录
INSERT INTO MYCAT_SEQUENCE(name,current_value,increment) VALUES ('mycat', -99, 100);
注意:
代表插入了一个名为mycat的sequence,当前值为-99,步长为100。
创建全局序列所需存储过程
#获取当前sequence的值
DELIMITER $$
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR)) INTO retval FROM
MYCAT_SEQUENCE WHERE NAME = seq_name;
RETURN retval;
END $$
DELIMITER ;#设置sequence值
DELIMITER $$
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNS
VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = VALUE
WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER ;#获取下一个sequence值
DELIMITER $$
CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER ;
重启Mycat
mycat restart
向dn1,dn2添加test表
#登录 Mycat,插入数据
create table test(id int,name varchar(10));
在Mycat中向test表中添加测试数据
(加粗字体代表调用函数)
insert into test(id,name) values(' 1670825118995189760',(select database()));
查询数据验证
SELECT * FROM test order by id asc;高可用
高可用概述
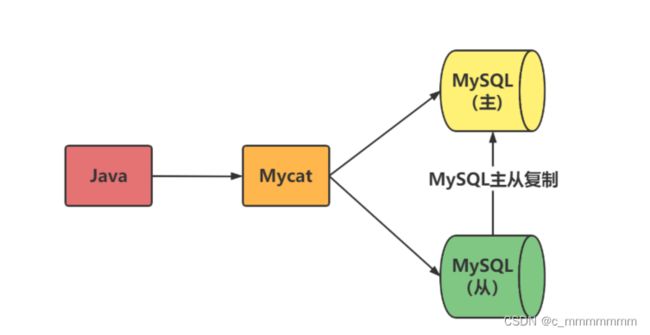
MyCat实现读写分离架构
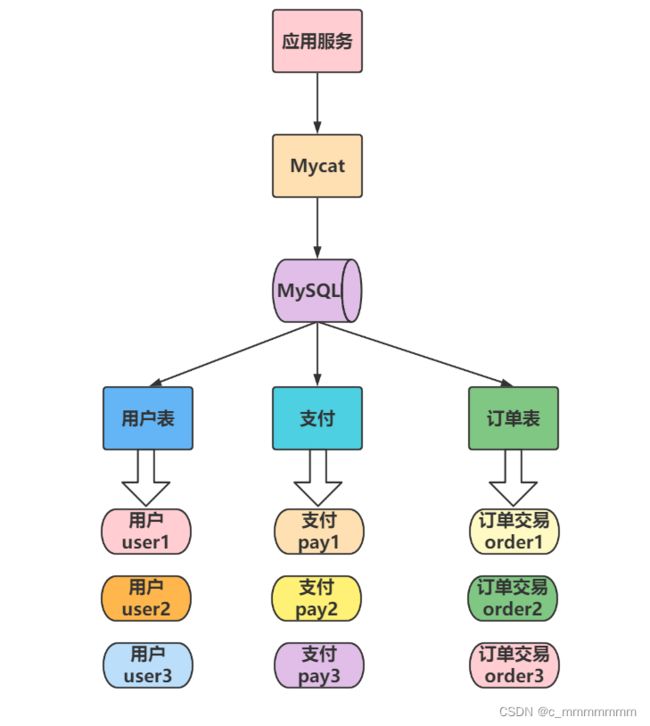
通过MyCat来实现MySQL的读写分离, 从而完成MySQL集群的负载均衡 , 如下面的结构图:
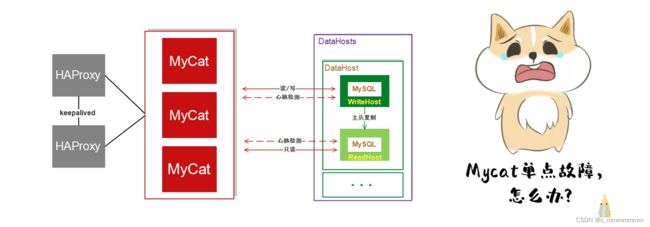
问题:
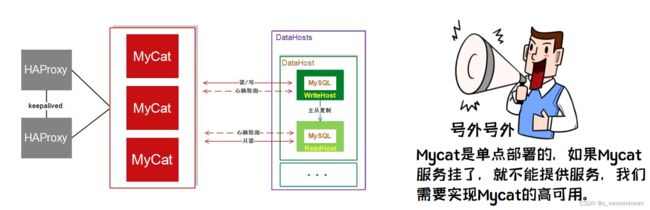
但是以上架构存在问题 , 由于MyCat中间件是单节点的服务, 前端客户端所有的压力过来都直接请求这一台MyCat , 存在单点故障。所以这个时候, 我们就需要考虑MyCat的集群 ;
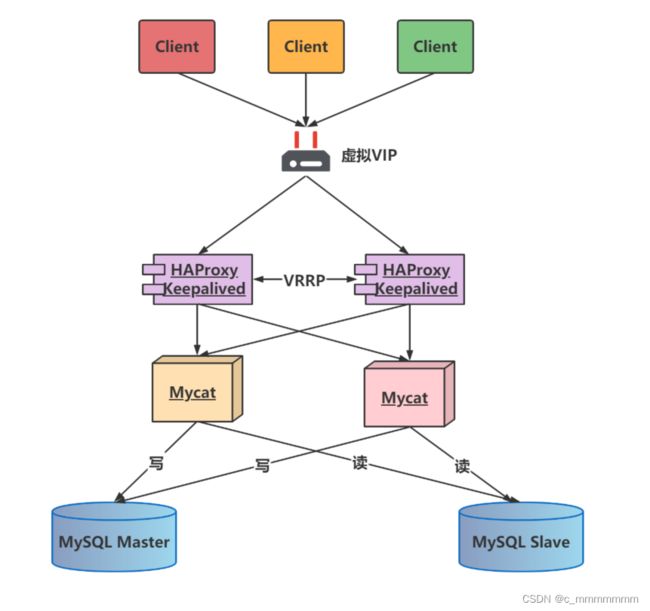
MyCat集群架构
通过MyCat来实现后端MySQL的负载均衡 , 通过HAProxy再实现MyCat集群的负载均衡。
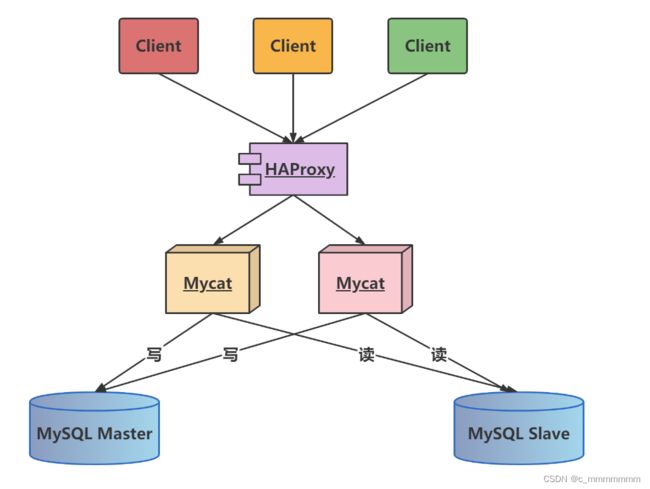
介绍:
HAProxy负责将请求分发到MyCat上,起到负载均衡的作用,同时 HAProxy也能检测到MyCat是否存活,HAProxy只会将请求转发到存活的 MyCat 上。如果一台MyCat服务器宕机,HAPorxy 转发请求时不会转发到宕机的MyCat 上,所以 MyCat 依然可用。
HAProxy介绍
HAProxy是一个开源的、高性能的基于TCP(第四层)和HTTP(第七层)应用的负载均衡软件。 使用HAProxy可以快速、可靠地实现基于TCP与HTTP应用的负载均衡解决方案。
问题:
因为所以的客户端请求都是先到达HAProxy, 由HAProxy再将 请求再向下分发, 如果HAProxy宕机的话, 就会造成整个MyCat集群不能正常运行, 依然存在单点故障。
MyCat的高可用集群
图解说明:
keepalived介绍
Keepalived是一种基于VRRP协议来实现的高可用方案,可以利用其来避免单点故障。 通常有两台甚至多台服务器运行Keepalived,一台为主服务器(Master), 其他为备份服务器, 但是对外表现为一个虚拟IP(VIP), 主服务器会发送特定的消息给备份服务器, 当备份服务器接收不到这个消息时, 即认为主服务器宕机, 备份服务器就会接管虚拟IP, 继续提供服务, 从而保证了整个集群的高可用。
- HAProxy实现了MyCat多节点的集群高可用和负载均衡,而HAProxy自身的高可用则可以通过Keepalived来实现。因此,HAProxy主机上要同时安装 HAProxy和Keepalived,Keepalived负责为该服务器抢占vip(虚拟 ip),抢占到vip后,对该主机的访问可以通过原来的ip访问,也可以直接通过vip访问。
- HAProxy负责将对vip的请求分发到MyCat集群节点上,起到负载均衡的作用。同时HAProxy也能检测到MyCat是否存活,HAProxy只会将请求转发到存活的MyCat 上。
- 如果Keepalived+HAProxy高可用集群中的一台服务器宕机,集群中另外一台服务器上的 Keepalived会立刻抢占vip 并接管服务,此时抢占了 vip 的HAProxy节点可以继续提供服务。
- 如果一台MyCat服务器宕机,HAPorxy 转发请求时不会转发到宕机的 MyCat 上,所以 MyCat 依然可用。
HAProxy实现高可用
安装配置HAProxy
查看列表
yum list | grep haproxy
yum安装
yum -y install haproxy
修改配置文件
$ vim /etc/haproxy/haproxy.cfg
启动HAProxy
$ haproxy -f /etc/haproxy/haproxy.cfg
HAProxy配置文件
HAProxy配置文件主要由全局设定和代理设定两部分组成,包含5个域:global、default、frontend、backend、listen。
global
# 全局配置,定义haproxy进程的工作特性和全局配置
global
log 127.0.0.1 local2
chroot /var/lib/haproxy #chroot运行的路径
pidfile /var/run/haproxy.pid #haproxy pid的存放位置
maxconn 65536 #最大连接数
nbproc 10
ulimit-n 200000
user haproxy #haproxy的运行用户
group haproxy #haproxy的运行用户的所属组
daemon #守护进程的方式在后台工作
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
注意:
全局配置,通常是一些进程级别的配置,与操作系统相关。
default
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http #默认使用的七层协议,也可以是tcp四层协议,如果配置为health,则表示健康检查,返回ok
log global
option tcplog #详细记录tcp日志
option redispatch
option dontlognull #不记录健康检查的日志信息
option forwardfor
retries 3 #重试次数为3次,失败3次以后则表示服务不可用
timeout http-request 5s #http请求超时时间,客户端建立连接5s但不请求数据的时候,关闭客户端连接
timeout queue 10s #等待最大时间,表示等待最大时长为10s
timeout connect 10s #连接超时时间,表示客户端请求转发至服务器所等待的时长为10s
timeout client 30m #客户端超时时间,表示客户端非活跃状态的时间为30min
timeout server 30m #服务器超时时间,表示客户端与服务器建立连接后,等待服务器的超时时间为30min
timeout http-keep-alive 10s #持久连接超时时间,表示保持连接的超时时长为10s
timeout check 10s #心跳检测超时时间,表示健康状态监测时的超时时间为10s
参数:
默认参数配置,主要是涉及的公共配置,在defaults中一次性添加。frontend、backend、listen未配置时,都可以默认defaults中的参数配置。若配置了,会覆盖。
frontend & backend
frontend test
bind *:8082
default_backend test
option httplog
acl user-core path_beg /test/v1/user/
use_backend user-core_server if user-core
# test
backend test
mode http
balance roundrobin
server node1 10.xxx.xxx.1:7000 check port 7000 inter 5000 rise 5 fall 5
server node2 10.xxx.xxx.2:7000 check port 7000 inter 5000 rise 5 fall 5
# user-core_server
backend user-core_server
mode http
balance roundrobin
server node1 10.xxx.xxx.1:7001 check port 7001 inter 5000 rise 5 fall 5
server node2 10.xxx.xxx.2:7001 check port 7001 inter 5000 rise 5 fall 5 backup
frontend haproxy_statis_front
bind *:8081
mode http
default_backend statis_haproxy
backend statis_haproxy
mode http
balance roundrobin
stats uri /haproxy/stats
stats auth haproxy:zkK_HH@zz
stats refresh 30s
stats show-node
stats show-legends
stats hide-version
参数:
frontend可以看作是前端接收请求的部分,内部指定后端; backend可以看作是后端服务接收请求的部分;
listen
listen admin_stats
bind *:8080 #监听端口
mode http
option httplog
log global
#统计接口启用开关
stats enable
maxconn 10
#页面刷新时长
stats refresh 30s
#haproxy ui访问后缀
stats uri /haproxy?stats
#认证时的realm,作为提示用的
stats realm haproxy
#认证用户名和密码
stats auth admin:admin
#隐藏HAProxy版本号
stats hide-version
#管理界面只有认证通过后才能在ui上进行管理
stats admin if TRUE
参数:
listen是`frontend和backend的组合,haproxy的监控ui可以通过这个进行配置。
向配置文件中插入以下配置信息,并保存
global
log 127.0.0.1 local0
#log 127.0.0.1 local1 notice
#log loghost local0 info
maxconn 4096
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
#uid 99
#gid 99
daemon
#debug
#quiet
defaults
log global
mode tcp
option abortonclose
option redispatch
retries 3
maxconn 2000
timeout connect 5000
timeout client 50000
timeout server 50000
listen proxy_status
bind :48066
mode tcp
balance roundrobin
server mycat_1 192.168.66.101:8066 check inter 10s
server mycat_2 192.168.66.102:8066 check inter 10s
frontend admin_stats
bind :7777
mode http
stats enable
option httplog
maxconn 10
stats refresh 30s
stats uri /admin
stats auth admin:123123
stats hide-version
stats admin if TRUE
启动验证
/usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/haproxy.conf
查看HAProxy进程
ps -ef|grep haproxy
打开浏览器访问
http://192.168.140.125:7777/admin#在弹出框输入用户名:admin密码:123123
验证负载均衡,通过HAProxy访问Mycat
mysql -uroot -p123456 -h 192.168.66.101 -P 48066
keepalived实现高可用
高可用架构
查看列表
yum list | grep keepalived
yum安装
yum install -y keepalived
查看yum安装的配置文件
rpm -ql keepalived
修改主节点配置文件
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
## keepalived 自带的邮件提醒需要开启 sendmail 服务。建议用独立的监控或第三方 SMTP
router_id baizhan ## 标识本节点的字条串,通常为 hostname
}
## keepalived 会定时执行脚本并对脚本执行的结果进行分析,动态调整 vrrp_instance 的优先级。
## 如果脚本执行结果为 0,并且 weight 配置的值大于 0,则优先级相应的增加。
## 如果脚本执行结果非 0,并且 weight 配置的值小于 0,则优先级相应的减少。
## 其他情况,维持原本配置的优先级,即配置文件中 priority 对应的值。
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh" ## 检测 haproxy 状态的脚本路径
interval 2 ## 检测时间间隔
weight 2 ## 如果条件成立,权重+2
}
## 定义虚拟路由, VI_1 为虚拟路由的标示符,自己定义名称
vrrp_instance VI_1 {
state MASTER ## 默认主设备(priority 值大的)和备用设备(priority 值小的)都设置为 BACKUP,
## 由 priority 来控制同时启动情况下的默认主备,否则先启动的为主设备
interface ens33 ## 绑定虚拟 IP 的网络接口,与本机 IP 地址所在的网络接口相同,我的是 eth3
virtual_router_id 35 ## 虚拟路由的 ID 号,两个节点设置必须一样,可选 IP 最后一段使用,
## 相同的 VRID 为一个组,他将决定多播的 MAC 地址
priority 120 ## 节点优先级,值范围 0-254, MASTER 要比 BACKUP 高
nopreempt ## 主设备(priority 值大的)配置一定要加上 nopreempt,否则非抢占也不起作用
advert_int 1 ## 组播信息发送间隔,两个节点设置必须一样,默认 1s
## 设置验证信息,两个节点必须一致
authentication {
auth_type PASS
auth_pass 1111 ## 真实生产,按需求对应该过来
}
## 将 track_script 块加入 instance 配置块
track_script {
chk_haproxy ## 检查 HAProxy 服务是否存活
}
## 虚拟 IP 池, 两个节点设置必须一样
virtual_ipaddress {
192.168.66.200
}
}
修改备用节点配置文件
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
## keepalived 自带的邮件提醒需要开启 sendmail 服务。建议用独立的监控或第三方 SMTP
router_id baizhan ## 标识本节点的字条串,通常为 hostname
}
## keepalived 会定时执行脚本并对脚本执行的结果进行分析,动态调整 vrrp_instance 的优先级。
## 如果脚本执行结果为 0,并且 weight 配置的值大于 0,则优先级相应的增加。
## 如果脚本执行结果非 0,并且 weight 配置的值小于 0,则优先级相应的减少。
## 其他情况,维持原本配置的优先级,即配置文件中 priority 对应的值。
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh" ## 检测 haproxy 状态的脚本路径
interval 2 ## 检测时间间隔
weight 2 ## 如果条件成立,权重+2
}
## 定义虚拟路由, VI_1 为虚拟路由的标示符,自己定义名称
vrrp_instance VI_1 {
state MASTER ## 默认主设备(priority 值大的)和备用设备(priority 值小的)都设置为 BACKUP,
## 由 priority 来控制同时启动情况下的默认主备,否则先启动的为主设备
interface ens33 ## 绑定虚拟 IP 的网络接口,与本机 IP 地址所在的网络接口相同,我的是 eth3
virtual_router_id 35 ## 虚拟路由的 ID 号,两个节点设置必须一样,可选 IP 最后一段使用,
## 相同的 VRID 为一个组,他将决定多播的 MAC 地址
priority 120 ## 节点优先级,值范围 0-254, MASTER 要比 BACKUP 高
nopreempt ## 主设备(priority 值大的)配置一定要加上 nopreempt,否则非抢占也不起作用
advert_int 1 ## 组播信息发送间隔,两个节点设置必须一样,默认 1s
## 设置验证信息,两个节点必须一致
authentication {
auth_type PASS
auth_pass 1111 ## 真实生产,按需求对应该过来
}
## 将 track_script 块加入 instance 配置块
track_script {
chk_haproxy ## 检查 HAProxy 服务是否存活
}
## 虚拟 IP 池, 两个节点设置必须一样
virtual_ipaddress {
192.168.66.200
}
}
编写 Haproxy 状态检测脚本
我们编写的脚本为/etc/keepalived/haproxy_check.sh (已在 keepalived.conf 中配置) 脚本要求:如果 haproxy 停止运行,尝试启动,如果无法启动则杀死本机的 keepalived 进程,keepalied将虚拟 ip 绑定到 BACKUP 机器上。 内容如下:
mkdir -p /usr/local/keepalived/log
vi /etc/keepalived/haproxy_check.sh#!/bin/bash
START_HAPROXY="/usr/sbin/haproxy start"
STOP_HAPROXY="/usr/sbin/haproxy stop"
LOG_FILE="/usr/local/keepalived/log/haproxy-check.log"
HAPS=`ps -C haproxy --no-header |wc -l`
date "+%Y-%m-%d %H:%M:%S" >> $LOG_FILE
echo "check haproxy status" >> $LOG_FILE
if [ $HAPS -eq 0 ];then
echo $START_HAPROXY >> $LOG_FILE
$START_HAPROXY >> $LOG_FILE 2>&1
sleep 3
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
echo "start haproxy failed, killall keepalived" >> $LOG_FILE
killall keepalived
fi
fi
权限
User标签
目前 Mycat 对于中间件的连接控制并没有做太复杂的控制,目前只做了中间件逻辑库级别的读写权限控制。是通过 server.xml 的 user 标签进行配置。
#server.xml配置文件user部分
123456
TESTDB
user
TESTDB
true
参数:
• name:应用连接中间件逻辑库的用户名
• password:该用户对应的密码
• TESTDB:应用当前连接的逻辑库中所对应的逻辑表。schemas 中可以配置一个或多个
• readOnly:应用连接中间件逻辑库所具有的权限。true 为只读,false 为读写都有,默认为 false
测试案例
使用user用户,权限为只读(readOnly:true),验证是否可以查询出数据,验证是否可以写入数据。
1、用user用户登录,运行命令如下:
mysql -uuser -puser -h 192.168.140.128 -P8066
2、切换到TESTDB数据库,查询orders表数据,如下:
use TESTDB
select * from orders;
3、执行插入数据sql
insert into orders(id,order_type,customer_id,amount) values(7,101,101,10000);
4、可看到运行结果,插入失败,只有只读权限
mysql> insert into orders(id,order_type,customer_id,amount) values(7,101,101,10000);
ERROR 1495 (HY000): User readonly
privileges标签
在 user 标签下的 privileges 标签可以对逻辑库(schema)、表(table)进行精细化的 DML 权限控制。
#server.xml配置文件privileges部分
#配置orders表没有增删改查权限
123456
TESTDB
配置说明
| DML权限 |
新增 |
更新 |
查询 |
删除 |
| 0000 |
禁止 |
禁止 |
禁止 |
禁止 |
| 0010 |
禁止 |
禁止 |
可以 |
禁止 |
| 1000 |
可以 |
禁止 |
禁止 |
禁止 |
| 1111 |
可以 |
可以 |
可以 |
可以 |
测试案例
使用mycat用户,privileges配置orders表权限为禁止增删改查(dml="0000") 验证是否可以查询出数据,验证是否可以写入数据。
1、重启mycat,用mycat用户登录,运行命令如下:
mysql -umycat -p123456 -h 192.168.66.101 -P8066
2、切换到TESTDB数据库,查询orders表数据,如下:
use TESTDB
select * from orders;
3、禁止该用户查询数据
mysql> use TESTDBDatabase changed
mysql> select* from orders;
ERROR 3012(HY000): The statement DML privilege check is not passed,reject for user 'mycat'
4、执行插入数据sql,如下
insert into orders(id,order_type,customer_id,amount) values(8,101,101,10000);
5、可看到运行结果,禁止该用户插入数据
mysql> insert into orders(id,order_type,customer_id,amount) values(8,101,101,10000)ERROR 3012 (HY000): The statement DMLprivilege check is not passed,reject for use
安全设置
SQL拦截白名单
firewall标签用来定义防火墙;firewall下whitehost标签用来定义IP白名单 ,blacklist 用来定义SQL 黑名单。
白名单
可以通过设置白名单,实现某主机某用户可以访问 Mycat,而其他主机用户禁止访问。
#设置白名单
#server.xml配置文件firewall标签
#配置只有192.168.66.101主机可以通过mycat用户访问
SQL拦截黑名单
可以通过设置黑名单,实现Mycat对具体SQL操作的拦截,如增删改查等操作的拦截。
#设置黑名单
#server.xml配置文件firewall标签
#配置禁止mycat用户进行删除操作
false
黑名单 SQL 拦截功能列表
| 配置项 |
默认值 |
功能 |
| selectAllow |
true |
是否允许执行select语句 |
| selectColumnAllow |
true |
是否允许执行select *操作 |
| selectIntoAllow |
true |
是否允许select语句中包含into子句 |
| deleteAllow |
true |
是否允许执行delete语句 |
| updateAllow |
true |
是否允许执行update语句 |
| insertAllow |
true |
是否允许执行insert语句 |
| replaceAllow |
true |
是否允许执行replace语句 |
| createTableAllow |
true |
是否允许创建表 |
| setAllow |
true |
是否允许使用set语法 |
| truncateAllow |
true |
是否允许执行truncate语句 |
| alterTableAllow |
true |
是否允许执行alter table语句 |
| dropTableAllow |
true |
是否允许修改表 |
| commitAllow |
true |
是否允许执行commit操作 |
| rollbackAllow |
true |
是否允许执行rollback操作 |
| useAllow |
true |
是否允许执行use语句 |
| describeAllow |
true |
是否允许执行describe操作 |
| showAllow |
true |
是否允许执行show语句 |