NeRF系列(4):Ha-NeRF: Hallucinated Neural Radiance Fields in the Wild论文解读
主页:
主页:Ha-NeRF: Hallucinated Neural Radiance Fields in the Wild https://rover-xingyu.github.io/Ha-NeRF/论文:https://openaccess.thecvf.com/content/CVPR2022/papers/Chen_Hallucinated_Neural_Radiance_Fields_in_the_Wild_CVPR_2022_paper.pdfhttps://openaccess.thecvf.com/content/CVPR2022/papers/Chen_Hallucinated_Neural_Radiance_Fields_in_the_Wild_CVPR_2022_paper.pdf
https://rover-xingyu.github.io/Ha-NeRF/论文:https://openaccess.thecvf.com/content/CVPR2022/papers/Chen_Hallucinated_Neural_Radiance_Fields_in_the_Wild_CVPR_2022_paper.pdfhttps://openaccess.thecvf.com/content/CVPR2022/papers/Chen_Hallucinated_Neural_Radiance_Fields_in_the_Wild_CVPR_2022_paper.pdf
code:https://github.com/rover-xingyu/Ha-NeRFhttps://github.com/rover-xingyu/Ha-NeRF
1 概要:
本文研究了重构的NeRF问题,即从一组旅游图像中恢复出不同时间的真实NeRF。
现有的解决方案采用具有可控外观嵌入的NeRF来在各种条件下渲染新视角,但无法渲染出具有未见外观的视图一致的图像。
为了解决这个问题,我们提出了一个端到端的框架,用于构建幻觉式的NeRF,被称为Ha-NeRF。具体而言,我们提出了一个外观重构模块,用于处理时间变化的外观并将其转移到新视角上。考虑到旅游图像中的复杂遮挡情况,我们引入了一个抗遮挡模块,用于准确地分解静态物体以获取清晰的可见性。

2 引言:
NeRF-W NeRF系列(2):NeRF in the wild : Neural Radiance Fields for Unconstrained Photo Collections论文解读与公式推导_LeapMay的博客-CSDN博客我们提出了一种基于学习的方法,利用非结构化的野外照片集合合成复杂场景的新视角。我们在神经辐射场(NeRF)的基础上进行了改进,以解决在真实世界的图像中存在的光照和遮挡等问题。我们将我们的方法命名为NeRF-W,并将其应用于互联网上著名地标的照片集合,展示了更接近真实照片的新视角渲染效果。https://blog.csdn.net/qq_35831906/article/details/131183038?spm=1001.2014.3001.5502该方法为每个输入图像优化外观嵌入以处理不同外观,并使用瞬态体积来分解静态组成部分及其遮挡物。与NeRF相比,NeRF-W在从具有不同外观和遮挡物的旅游图像中恢复真实世界方面迈出了一步。然而,NeRF-W通过优化训练样本的嵌入实现了可控的外观,这使得当给定一个新的图像时需要优化嵌入,并且无法从其他数据集中幻化外观。此外,NeRF-W尝试为每个输入图像优化一个瞬态体积,其中使用瞬态嵌入作为输入,由于瞬态遮挡物的随机性,这是高度不适定的。这导致场景的分解不准确,并进一步导致外观和遮挡物的纠缠,例如,导致瞬态体积记住了日落的光晕。
为了解决以上限制,Ha-NeRF的框架,从具有不同外观和遮挡物的无约束旅游图像中重构出逼真的辐射场,如图1所示。
对于外观重构,提出了基于CNN的外观编码器和一种视图一致的外观损失,以在不同视角中传递一致的光度外观。这种设计使得我们的方法能够转移未学习图像的外观。
对于抗遮挡,利用MLP学习一个基于图像的2D可见性掩码,并使用抗遮挡损失在训练过程中自动准确地分离静态组件。在几个地标上的实验证实了所提方法在外重构化和抗遮挡方面的卓越性能。
主要贡献:
- 提出了Ha-NeRF框架,用于从具有不同外观和遮挡物的图像组中恢复外观重构化辐射场。
- 开发了外观重构模块,将视图一致的外观转移到新视角中。
- 建立了一个基于图像的抗遮挡模块,用于感知射线的可见性。
3 相关工作:
4 方法:
我们可以根据在不同光度条件下拍摄的新视角修改整个三维场景的外观。具体而言,在野外拍摄的照片作为输入时,通过卷积神经网络编码的外观嵌入来重建一个与外观无关的NeRF。为了处理照片中的瞬态遮挡物,我提出了一个遮挡处理模块,可以自动分离静态场景。
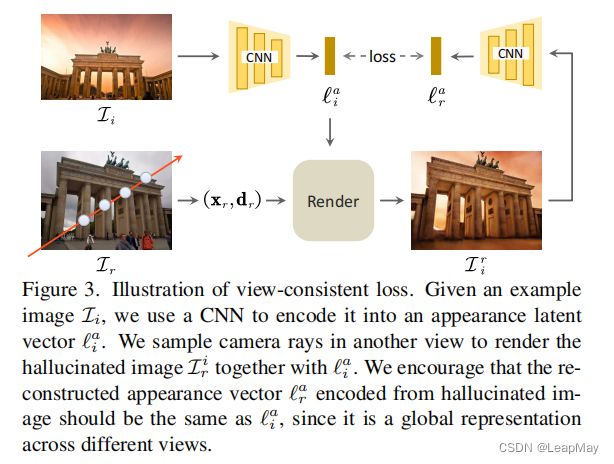
4.1. View-consistent Hallucination
为了根据具有不同外观的输入照片,从新的拍摄角度实现对3D场景的幻化,核心问题在于如何将场景几何与外观分离,并将新的外观传递到重建的场景中。NeRF-W [28] 尝试使用优化的外观嵌入来解释输入中依赖于图像的外观。然而,这种嵌入需要在训练过程中进行优化,使其在超出训练样本范围内从新的拍摄中重构场景时需要优化嵌入,并且无法从其他数据集中重构外观。
因此,我们提出使用基于卷积神经网络的编码器 Eφ 来学习解耦的外观表示,其中参数 φ 考虑了输入中的光照变化和光度后处理。Eφ 将每个图像 ![]() 编码为外观潜在向量
编码为外观潜在向量![]()
。
方程式1中的辐射度,这样就将外观潜在向量  扩展为外观相关的辐射度
扩展为外观相关的辐射度![]()
![]() 引入到发射颜色中。
引入到发射颜色中。

外观编码器 Eφ 的参数 φ 是与辐射场 Fθ 的参数 θ 一起学习的。这个外观编码器使得我们的方法具有使用超出训练集的图像外观的灵活性,
然而,从不成对的图像中解开外观与视角的问题本质上是不适定的,并且需要额外的约束。受最近的一些工作的启发[20, 23, 62],这些工作利用潜在回归损失来促进图像空间和潜在空间之间的可逆映射。我们提出了一个视图一致性损失 ![]() ,通过从外观编码器 Eφ 获取外观向量
,通过从外观编码器 Eφ 获取外观向量![]() 并尝试在不同视角下进行重构,从而实现外观和视角的解耦。这个损失的形式如下
并尝试在不同视角下进行重构,从而实现外观和视角的解耦。这个损失的形式如下

其中![]() 是根据随机生成的视角渲染的图像,外观是基于图像
是根据随机生成的视角渲染的图像,外观是基于图像![]() 进行条件设置的,如图3所示。
进行条件设置的,如图3所示。

在这里,我们假设重构的外观向量![]() (
(![]() )应该与原始的外观向量
)应该与原始的外观向量![]() 相同,因为外观向量是跨不同视角的全局表示。
相同,因为外观向量是跨不同视角的全局表示。
由于视图一致性损失的作用,我们可以在给定相同外观向量的情况下进行视图一致的外观渲染。
此外,借助视图一致性损失,我们可以防止将图像的几何内容编码到外观向量中,当将体积条件设置为相同向量时,它将将来自不同视角(也是内容)的渲染图像编码为相同的向量。
为了提高效率,在训练过程中,我们采样一组光线并将它们组合成图像![]() ,而不是渲染整个图像[46]。这基于一个假设,即在使用随机网格进行采样后,图像的全局外观向量将保持不变。
,而不是渲染整个图像[46]。这基于一个假设,即在使用随机网格进行采样后,图像的全局外观向量将保持不变。
4.2. Occlusion Handling
与NeRF-W中使用3D瞬态场来重建仅在单个图像中观察到的瞬态现象不同,我们使用基于图像的2D可见性图来消除瞬态现象。
这种简化使得我们的方法能够更准确地将静态场景与瞬态物体分割开来。为了建模这个图像,我们采用了一个隐式连续函数![]() ,它将2D像素位置p = (u, v)和图像相关的瞬态嵌入
,它将2D像素位置p = (u, v)和图像相关的瞬态嵌入![]() 映射为可见性概率
映射为可见性概率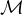
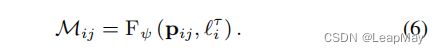
我们以无监督的方式训练可见性图,该图指示了起源于静态场景的光线的可见性,以解耦图像中的静态和瞬态现象。我们使用一个遮挡损失来实现这一目标![]() :
:
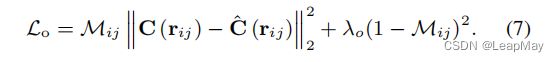
在这种情况下,损失函数![]() 包括两个项。
包括两个项。
第一个项是重建误差,考虑了渲染图像和真实颜色之间的像素可见性。可见性图M中的较大值增强了对像素的重要性,假设它属于静态现象。
第一个项通过第二个项进行平衡,第二个项是一个正则化项,乘以系数λo,用于鼓励模型不忽视静态现象。
第一个项的目标是最小化渲染图像和真实图像之间的差异,而第二个项的目标是鼓励模型减少忽略静态现象的情况。通过调整λo的值,可以控制两个项之间的平衡,以便在重建过程中更好地考虑静态现象。
具体而言,损失函数Lo可能计算渲染图像和真实图像之间的差异,并将其乘以可见性图M和不可见性的正则化项。最终目标是通过调整模型参数来最小化损失函数,以实现更准确的重建结果,并更好地处理静态现象。
4.3. Optimization
为了实现Ha-NeRF,我们结合上述约束条件,共同训练参数(θ, φ, ψ)和每个图像的瞬态嵌入,以优化完整的目标函数![]() :
:
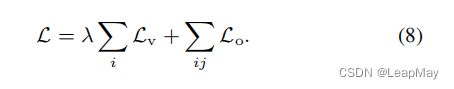

5. Experiments
我们遵循NeRF和NeRF-W的实现[41]方法。静态神经辐射场Fθ由8个具有256个通道的全连接层组成,接着是ReLU激活函数生成σ,并且有一个额外的具有128个通道的全连接层,使用Sigmoid激活函数输出与外观相关的RGB颜色c。
外观编码器Eφ由5个卷积层组成,接着是自适应平均池化和一个全连接层,得到具有48个维度的外观向量![]()
。
图像相关的2D可见性掩码 ![]() 由5个具有256个通道的全连接层和Sigmoid激活函数组成,生成在128个维度上与瞬态嵌入
由5个具有256个通道的全连接层和Sigmoid激活函数组成,生成在128个维度上与瞬态嵌入![]() 有关的可见性概率M。我们将λ设置为1×10^-3,λo设置为6×10^-3。
有关的可见性概率M。我们将λ设置为1×10^-3,λo设置为6×10^-3。
为了评估Ha-NeRF在实际场景中的性能,我们使用Phototourism数据集构建了三个数据集,分别称为"Brandenburg Gate"、"Sacre Coeur"和"Trevi Fountain",该数据集包含了文化地标的互联网照片集合。在训练过程中,我们将所有图像进行了2倍的降采样。
6. Conclusion
NeRF作为一种方法已经在各种应用中得到广泛应用,包括从旅游图像中恢复NeRF。虽然NeRF-W在训练数据上优化了外观嵌入,但很难在未学习的外观上一致地生成新视角。
为了解决这个具有挑战性的问题,我们提出了Ha-NeRF,它可以在变化的外观和复杂的遮挡情况下生成逼真的辐射场。具体来说,我们提出了一个外观幻化模块,用于处理时变外观并将其转移到新视角上。此外,采用了一个抗遮挡模块,学习了一种图像相关的2D可见性掩码,能够准确地分离静态对象。使用合成数据和旅游照片集的实验结果表明,我们的方法可以生成无遮挡的视角和外观的幻化。我们将公开提供代码和模型,以便研究社区进行可重现的研究。