MapReduce(分布式计算框架)
什么是MapReduce
MapReduce是分布式计算框架,它将大型数据操作作业分解为可以跨服务器集群并行执行的单个任务,适用于大规模数据处理场景,每个job包含Map和Reduce两部分
MapReduce的设计思想
分而治之:简化并行计算的编程模型
构建抽象模型:Map和Reduce
隐藏系统层细节:开发人员专注于业务逻辑实现
MapReduce特点
优点:
- 易于编程
- 可扩展性
- 高容错性
- 高吞吐量
缺点:
- 难以实时计算
- 不适合流式计算
- 不适合DAG(有向图)计算
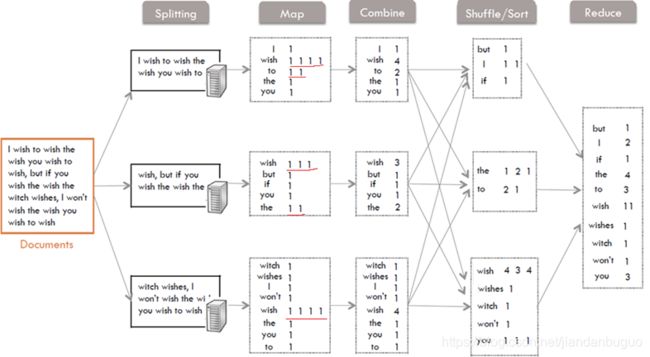
MapReduce实现WordCount
Mapper
public class WCMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arrys = line.split(" ");
for (String s : arrys) {
context.write(new Text(s),new IntWritable(1));
}
}
}
Reduce
public class WCReduce extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int total=0;
for (IntWritable value : values) {
total+=value.get();
}
context.write(key,new IntWritable(total));
}
}
Driver
public class WCDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1、建立连接
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,"wc");
// 2、指定mapper和reduce及jar位置
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReduce.class);
job.setJarByClass(WCDriver.class);
// 3、mapper输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 4、reduce输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 5、文件输入输出路径
String[] path={"file:///f:/data/interview.txt","file:///f:/data/wcResult"};
FileInputFormat.setInputPaths(job,new Path(path[0]));
FileOutputFormat.setOutputPath(job, new Path(path[1]));
boolean result =job.waitForCompletion(true);
System.out.println(result?"成功":"失败");
System.exit(result?0:1);
}
}
MapReduce编程总结
- MapReduce框架处理的数据格式是
- Mapper端
Map端接受
Map端处理逻辑写在Mapper类中的map()方法 - Reducer端
Reduce端搜集多个Mapper端输出的
Reducer的业务逻辑写在reduce()方法中
每组相同的k的
MapReduce框架原理
MapReduce执行流程
- split阶段:计算分片,
该阶段是从数据分片出发,把数据输入到处理程序中,是整个过程的开始 - map阶段:调用map()方法对数据进行处理
当数据输入进来以后,我们进行的是 map 阶段的处理。例如对一行的单词进行分割,然后每个单词进行计数为 1 进行输出 - shuffle阶段:主要负责将map端生成的数据传递给reduce端
shuffle 阶段是整个 MapReduce 的核心,介于 Map 阶段跟 Reduce 阶段之间 - reduce阶段:对shuffle阶段传来的数据进行最后的整理合并
数据经过 Map 阶段处理,数据再经过 Shuffle 阶段,最后到 Reduce ,相同的 key 值的数据会到同一个 Reduce 任务中进行最后的汇总 - Output 阶段
这个阶段的事情就是将 Reduce 阶段计算好的结果,存储到某个地方去,这是整个过程的结束
MapReduce框架中核心类

InputFormat接口

常用实现类为:
- FileInputFormat
- TextInputFormat
- DBInputFormat
流程:
1、找到输入数据存储的目录
2、开始遍历目录下的每一个文件
3、遍历第一个文件
4、获取文件的大小
5、计算切片的大小,默认情况下,切片大小会等于块的大小
6、开始切片(假设260M的文件,0128M,128256M,256~260M,判断剩下的部分是否大于块的1.1倍,如果不大于1.1,就直接划分为一个切片)
切片(split):MapReduce中的一个逻辑概念,一个切片就是一个Mapper任务
切块(block):HDFS上的物理切割,是一个物理概念,通常情况下,切块的个数等于切片的个数
block和split的区别:
①block是数据的物理表示
②split是块中数据的逻辑表示
③split划分是在记录的边界处
④split的数量应不大于block的数量(一般相等)
Combiner类
①Combiner相当于本地化的Reduce操作
②在shuffle之前进行本地聚合
③用于性能优化,可选项
④输入和输出类型一致
⑤Reduce可以被用作Conbiner的条件
⑥符合交换律和结合律
⑦实现Conbiner类需要继承Rreduce类,
⑧Driver类中设置job.setConbinerClass()
Partitioner类
①用于在Map端对key进行分区
②默认使用的是HashPartitioner ,取key的哈希值,使用key的哈希值对reduce任务数求模,决定每调记录应该送到那个reducer处理
③自定义Partitioner,需要继承抽象类Partitioner,重写getPartition方法
④Driver类中设置job.setPartitioerClass()
⑤当设置的分区数与partitioner类不匹配时
- 分区数为1:生成1个文件
- 大于1且小于设置的分区数:报错
- 大于设置的分区数:会有空白文件
OutputFormat接口
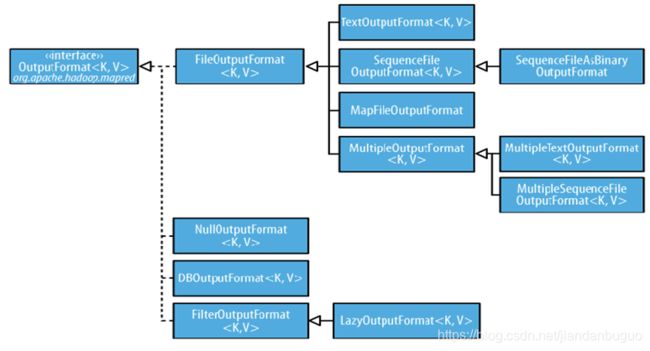
常用实现类
①FileOutputFormat
②TextOutputFormat
③SequenceFileOutputFormat
④MapFileOutputFormat
执行流程图

- Input Split 数据阶段
Input Split 即输入分片,数据在进行 Map 计算之前,MapReduce 会根据输入文件进行切分,因为我们需要分布式的进行计算嘛,那么我得计算出来我的数据要切成多少片,然后才好去对每片数据分配任务去处理。
每个输入分片会对应一个 Map 任务,输入分片存储的并非数据本身,而是一个分片长度和一个记录数据的位置数据,它往往是和 HDFS 的 block(块) 进行关联的。
假如我们设定每个 HDFS 的块大小是为默认的 128M,如果我们现在有3个文件,大小分别是 10M,129M,200M,那么MapReduce 对把 10M 的文件分为一个分片,129M 的数据文件分为2个分片,200M 的文件也是分为两个分片。那么此时我们就有 5 个分片,就需要5个 Map 任务去处理,而且数据还是不均匀的。
如果有非常多的小文件,那么就会产生大量的 Map 任务,处理效率是非常低下的。这个阶段使用的是 InputFormat 组件,它是一个接口 ,默认使用的是 TextInputFormat 去处理,他会调用 readRecord() 去读取数据。
小文件处理是MapReduce 计算优化的一个非常重要的一个点。可以通过如下方法:
①最好的办法:在数据处理系统的最前端(预处理、采集),就将小文件先进行合并了,再传到 HDFS 中去。
②补救措施:如果已经存在大量的小文件在HDFS中了,可以使用另一种 InputFormat 组件CombineFileInputFormat 去解决,它的切片方式跟 TextInputFormat 不同,它会将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个 Map 任务去处理了。
- Map阶段
将 Map 阶段的输出作为 Reduce 阶段的输入的过程就是 Shuffle 。 这也是整个 MapReduce 中最重要的一个环节。
一般MapReduce 处理的都是海量数据,Map 输出的数据不可能把所有的数据都放在内存中,当我们在map 函数中调用 context.write() 方法的时候,就会调用 OutputCollector 组件把数据写入到处于内存中的一个叫环形缓冲区的东西。
环形缓冲区默认大小是 100M ,但是只写80%,同时map还会为输出操作启动一个守护线程,当到数据达到80%的时候,守护线程开始清理数据,把数据写到磁盘上,这个过程叫 spill 。
数据在写入环形缓冲区的时候,数据会默认根据key 进行排序,每个分区的数据是有顺序的,默认是 HashPartitioner。当然了,我们也可以去自定义这个分区器。
每次执行清理都产生一个文件,当 map 执行完成以后,还会有一个合并文件文件的过程,其实他这里跟 Map 阶段的输入分片(Input split)比较相似,一个 Partitioner 对应一个 Reduce 作业,如果只有一个 reduce 操作,那么 Partitioner 就只有一个,如果有多个 reduce 操作,那么 Partitioner 就有多个。Partitioner 的数量是根据 key 的值和 Reduce 的数量来决定的。可以通过 job.setNumReduceTasks() 来设置。
这里还有一个可选的组件 Combiner ,溢出数据的时候如果调用 Combiner 组件,它的逻辑跟 reduce 一样,相同的key 先把 value 进行相加,前提是合并并不会改变业务,这样就不糊一下传输很多相同的key 的数据,从而提升效率。
举个例子,在溢出数据的时候,默认不使用 Combiner,数据是长这样子:
- Reduce 阶段
在执行 Reduce 之前,Reduce 任务会去把自己负责分区的数据拉取到本地,还会进行一次归并排序并进行合并。
Reduce 阶段中的 reduce 方法,也是我们自己实现的逻辑,跟Map 阶段的 map 方法一样,只是在执行 reduce 函数的时候,values 为 同一组 key 的value 迭代器。在 wordCount 的例子中,我们迭代这些数据进行叠加。最后调用 context.write 函数,把单词和总数进行输出。
- Output 阶段
在 reduce 函数中调用 context.write 函数时,会调用 OutPutFomart 组件,默认实现是 TextOutPutFormat ,把数据输出到目标存储中,一般是 HDFS。
面试题:
MapReduce执行流程
MapReduce Shuffle过程
MapTask个数如何调整