NeRF系列(3): Semantic-aware Occlusion Filtering Neural Radiance Fields in the Wild 论文解读
论文 https://arxiv.org/pdf/2303.03966.pdf https://arxiv.org/pdf/2303.03966.pdf
https://arxiv.org/pdf/2303.03966.pdf
1. 摘要
在真实环境中的语义感知遮挡滤波神经辐射场》
我们提出了一个学习框架,用于从少量的非约束性旅游照片中重建神经场景表示。由于每个图像都包含瞬时遮挡物,对静态和瞬时成分进行分解是构建辐射场所必需的,而现有方法需要大量的训练数据。我们引入了SF-NeRF,旨在仅凭少量给定的图像解耦这两个成分,该方法利用语义信息而无需任何监督。所提出的方法包含一个遮挡滤波模块,用于预测每个像素的瞬时颜色及其不透明度,使得NeRF模型仅学习静态场景表示。这个滤波模块通过可训练的图像编码器获得的像素级语义特征来指导学习瞬时现象,该编码器可以跨多个场景进行训练,以学习瞬时对象的先验知识。此外,我们提出了两种技术来防止滤波模块产生模糊的分解和噪声结果。我们证明了我们的方法在Phototourism数据集的少样本设置下优于现有的新视角合成方法。
2 引言和主要贡献
近年来,由于神经渲染技术的快速发展,从2D图像合成新视角引起了越来越多的关注。特别是神经辐射场(NeRF)通过多层感知机(MLP)隐式地编码了三维场景的体积密度和颜色,在新视角合成方面表现出色。随着NeRF的成功,出现了一些后续工作,扩展了神经场的训练和渲染速度[2-7],处理动态场景[8-16],以及利用少量图像学习场景表示[17-27]等等。然而,大多数这些方法都是在受控环境中进行验证的,其中所有图像中的场景辐射都不发生变化,场景中的所有内容都是静态的。然而,在现实世界的图像中(例如,文化地标的互联网照片),它们不符合这种假设:照片的照明会随着拍摄时间和天气的不同而变化,移动的对象,如云、人或车辆,可能会出现。
许多研究致力于处理光度变化和瞬时对象。先前的研究主要通过使用每个图像的外观嵌入来解决不一致的外观,并对其进行优化[28-30]。至于我们将重点关注的瞬时现象,NeRF-W[28]和HA-NeRF[31]利用了额外的瞬时模块,将瞬时成分从场景中分离出来。另一方面,Block-NeRF[29]和Mega-NeRF[30]使用分割模型来屏蔽通常被认为是可移动对象的类别的对象。然而,前者需要大量的图像,因为模型不仅必须消除遮挡物,还必须学习场景的复杂几何形状和外观,而后者受限于预定义的类别,可能会错过异常对象,如阴影。
为了解决这些局限性,我们提出了一个名为SF-NeRF的新颖框架,它利用了两个附加模块:一个学习瞬时遮挡物先验的图像编码器和一个称为FilterNet的遮挡过滤模块。FilterNet通过在编码器给出的图像特征的条件下,预测每个图像的瞬时成分:颜色和不透明度,从而分解静态和瞬时现象。与上述先前方法不同,我们的方法不受预定义类别的限制,可以通用于从场景中解离瞬时对象的特征,实现少样本学习。此外,我们对瞬时不透明度应用了重新参数化技术,将其建模为二进制Concrete随机变量,以完全分离瞬时对象与场景。我们还添加了一个正则化项,以对瞬时不透明度施加平滑约束。
我们在Phototourism数据集[32]上评估了我们的方法,该数据集包含在文化地标拍摄的互联网照片,并在少样本设置下进行训练,每个地标使用30张图像。我们的实验证明,SF-NeRF能够学习瞬时遮挡物的先验知识,并能够仅使用少量训练图像对场景进行分解。主要贡献如下:
1 我们提出了一个新颖的框架(SF-NeRF),通过利用图像的语义特征以无监督的方式学习场景的静态和瞬时成分的分解。
2• 我们在FilterNet的训练过程中引入了重新参数化技术,以避免场景分解产生模糊的结果。
3• 我们引入了一个正则化项,以确保瞬时不透明度场的平滑性。
4• 在少样本设置下,所提出的方法在Phototourism数据集上表现优于现有的新视角合成方法。
3 相关工作
4 方法
为了从仅有几张真实环境中的照片中学习NeRF表示,我们提出了一种名为“Semantic-aware Occlusion Filtering Neural Radiance Fields (SF-NeRF)”的方法。
为了一致地分解静态和瞬态组件,我们引入了一个名为FilterNet的新的遮挡处理模块,它利用图像的语义信息来预测瞬态组件,这些信息是通过一个无监督预训练编码器提取的。然后,使用一种重新参数化技巧来避免模糊的分解。在训练过程中,我们使用先验知识来防止FilterNet产生噪声结果。我们的整体流程如图1所示。

图1. 总体架构。我们的框架通过过滤图像中的瞬态遮挡物将场景分解为静态和瞬态组件。给定3D位置x、方向d和学习的外观嵌入,静态NeRF模型Fθ生成静态颜色和密度,用于渲染静态图像。对于每个图像,FilterNet Tψ将像素位置p映射到其瞬态不透明度α(τ)、瞬态颜色C(τ)和不确定性值β,条件是基于图像相关的瞬态嵌入和从图像编码器Eφ提取的像素级特征f(p)。最终预测的像素颜色ˆC通过alpha混合渲染的静态颜色C和瞬态颜色C(τ)计算得出。
4.1 前情概要
我们采用一种条件NeRF结构,其中发射的辐射度量取决于图像特定的潜在嵌入。此外,我们使用集成位置编码(IPE),它将空间区域的特征化作为整体,而不是单个点,使得单个多层感知机(MLP)可以学习多尺度的场景表示。


为了从具有不同照明条件的照片中合成视角,先前的方法[28, 28–30]主要使用了外观嵌入 ,这使得NeRF能够灵活调整每个图像的场景发射辐射。方程(1)中的辐射c和方程(2)中的渲染颜色C(r)被图像相关的ci和Ci(r)取代,如下所示:
在NeRF-W [28, 70]的框架下,我们采用外观嵌入,并针对每个输入图像进行优化

Mip-NeRF.
与NeRF不同,mip-NeRF [3]不是为每个像素投射单个光线,而是投射一个锥体,随着图像分辨率的变化,锥体的半径也会改变。mip-NeRF将位置编码方案从对无穷小点进行编码改变为在光线的每个部分内进行积分(综合位置编码)。
这使得mip-NeRF能够学习多尺度表示,并将NeRF的粗略和细节MLP结合成一个单一的MLP。在本文中,我们采用mip-NeRF的结构,以充分利用其模型容量减半和尺度鲁棒性的优势,因为野外拍摄的照片拍摄距离和分辨率各不相同。

4.2 语义感知场景分解
为了实现一致的场景分解,我们使用了一个额外的MLP模块,称为FilterNet,通过利用图像的语义特征来建模瞬时成分。FilterNet Tψ被设计用于处理瞬时现象,通过学习图像相关的2D映射:瞬时RGBA和不确定性映射。瞬时RGBA图像与NeRF生成的渲染(静态)图像进行Alpha混合,以重建原始图像,如图1所示。
我们估计每个像素观察到的颜色的不确定性,使模型能够通过忽略不可靠的像素来调整重建损失。这个想法借鉴自NeRF-W [28],但不同之处在于我们直接估计一个2D的不确定性映射,而NeRF-W则根据沿射线的3D位置的不确定性渲染值。 具体而言,我们将FilterNet Tψ建模为一个隐式的连续函数,它将瞬时嵌入、像素位置和对应的编码特征 映射到瞬时颜色,不透明度和不确定性值,如下所示:

描述了一种基于短暂值和静态值的组合来预测图像像素颜色的方法。位置编码函数γp被应用于每个像素坐标,通过预先训练的编码器E从输入图像中提取特征映射fi,其输入输出分别为R H×W×3和R H×W×F,并可以在其他真实世界数据集上进行预训练。我们将对应于光线r的像素的短暂颜色、不透明度和不确定度值分别表示为C(iτ)(pr)、αi(τ)(pr)和βi(pr)。最终预测的像素颜色ˆCi(r)是通过使用alpha混合将短暂颜色C(iτ)(pr)和静态颜色Ci(r)组合而成的。

对于图像Ii中的每条光线r,我们使用损失函数L(t_i)以无监督的方式训练FilterNet,从场景中分离出瞬态成分。

其中,¯C是真实颜色。第一项和第二项可以被视为¯Ci(r)的负对数似然,假设其遵循具有均值ˆCi(r)和方差βi(pr)^2的各向同性正态分布[28]。第三项防止FilterNet描述静态现象。
4.3. 瞬时不透明度重参数化
我们经验性地发现,如果仅通过将MLP的输出传递到sigmoid激活函数中训练FilterNet来预测瞬态不透明度值,则会产生模糊的伪影,即不接近于零或一的值。这种不明确的分解会导致静态场景中出现模糊的伪影。
为了使瞬态图像完全不透明或为空,我们将αi(τ)建模为二进制Concrete随机变量[71],它是Bernoulli随机变量的连续松弛,并预测其概率。二进制Concrete分布是Concrete分布的一种特殊情况,也称为Gumbel-Softmax分布[72],通常用于近似离散随机变量。我们从具有位置参数˜αi∈(0, ∞)的二进制Concrete分布中采样αi(τ),而不是直接预测不透明度值,如下所示:

其中,t∈(0, ∞)是一个超参数。这种采样方案鼓励我们的模型预测集中在区间[0,1]的边界上的不透明度值,同时允许反向传播。在评估过程中,我们将U固定为0.5。
4.4. 瞬态不透明度平滑先验
FilterNet的输入包括编码像素(PE特征)γp(p),![]() ,其中包含高频信息。这自然导致高频输出,适合预测像素的颜色,但可能会导致瞬态不透明度的嘈杂预测。因此,我们在瞬态不透明度场上添加平滑损失,如下所示
,其中包含高频信息。这自然导致高频输出,适合预测像素的颜色,但可能会导致瞬态不透明度的嘈杂预测。因此,我们在瞬态不透明度场上添加平滑损失,如下所示


4.5 优化
通过最小化总损失函数,联合优化模型参数(θ, φ, ψ),每个图像的外观嵌入![]()
和瞬态嵌入
 :
:
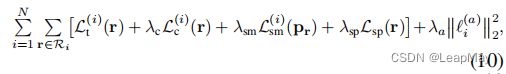
其中λc,λsm,λsp和λa是超参数,![]() 是由粗略样本
是由粗略样本![]() 合成的渲染图像的重建损失,Lsp是一个名为稀疏性损失的正则化项:
合成的渲染图像的重建损失,Lsp是一个名为稀疏性损失的正则化项:

![]() 粗略样本是由分层采样产生的。
粗略样本是由分层采样产生的。
稀疏性损失Lsp鼓励静态场景在未观察区域具有零密度。由于瞬态物体隐藏了静态场景,因此静态模型无法学习这些区域的场景表示。当提供足够的训练图像时,这种障碍是可以忽略的,因为其他图像提供了观察缺失区域的机会。然而,在少样本情况下,这不能保证,允许模型在未观察区域自由生成任意几何形状。因此,我们使用这种稀疏性先验,也称为Cauchy损失[5,73],以鼓励NeRF的不透明度场的稀疏性。
5. Experiments
整体的定量结果如表1所示,其中SF-NeRF在少样本设置中大多优于基线。虽然SF-NeRF总体上改善了性能,但差距并不明显。

如果我们看一下Phototourism数据集的测试集,这是可以解释的。如图5所示,大多数测试图像仅包含可见部分,即在训练期间未被瞬态遮挡物隐藏的部分。因此,评估这些图像可能无法反映分解静态和瞬态组件的能力。尽管定性结果显示SF-NeRF比基线有明显的改进。

图2显示了我们的模型和基线在一些数据集示例上的定性结果。使用NeRF渲染通常会导致全局颜色偏移和幽灵伪影。这些是我们在第1节中解释的NeRF假设的直接后果,即场景在所有图像中保持不变,并且场景中的每个内容都是静态的。虽然NeRF-AM、HA-NeRF和NeRF-W能够通过使用外观嵌入来建模不同的光度效应,但它们也会受到伪影的影响。具体而言,这三个基线在“泰姬陵”和“勃兰登堡门”(特别是在NeRF-AM上)中显示出幽灵伪影,在“特维尔喷泉”中显示出模糊伪影。可以看到,大多数伪影都放置在瞬态遮挡物经常隐藏的区域,这表明它们缺乏分解静态和瞬态组件的能力。这一观察结果得到了图3的支持,其中NeRF-AM、HA-NeRF和NeRF-W经常无法移除一些瞬态对象。相反,SF-NeRF始终将瞬态元素与静态场景分离开来,证明了语义引导滤波模块的有效性。

6 局限和未来工作
SF-NeRF仅关注在解决从现实世界的照片中进行少量训练的新颖视角合成任务时,如何有效去除瞬态现象。为了进一步改进,有必要探索在少量训练数据下,如何很好地学习静态场景的几何形状和多样化外观的方法。
此外,每个图像的相机参数是通过结构光测量技术获得的,这些参数并不完全准确。由于SF-NeRF仅使用少量图像进行训练,对相机校准误差非常敏感,这导致重建结果模糊。因此,同时进行相机姿态的细化调整可能是一种解决方案。
7 结论
论文提出了一种新的学习框架,名为“语义感知遮挡过滤神经辐射场(SF-NeRF)”,用于从少量现实世界的照片中学习神经表示。
SF-NeRF专注于分解瞬态和静态现象,并利用一个名为FilterNet的额外MLP模块预测每个图像的短暂组成部分。FilterNet利用经过无监督预训练的图像编码器提供的语义信息,这是实现少样本学习的关键。此外,我们采用了重新参数化技术来防止模糊的分解,并对瞬态不透明度施加平滑先验。我们的实验证明,在少样本设置下,SF-NeRF整体上优于Phototourism数据集上的最先进的新颖视角合成方法。