seaborn学习笔记二
哈喽哈大噶好!今天我们接着上次学习seaborn。
分面网格分类图
分面网格(FacetGrid)可以绘制多个子图,在分面网格中绘制分类图使用catplot函数,“图级函数”,而barplot、boxplot、violinplot等函数是分面网格x和y轴上进行绘制,是“轴级函数”
参数
row , col 分别表示在x,y轴上绘制数据
col_wrap 在x轴绘制子图的最大个数
kind 绘制子图类型,主要有bar strip swarm box violin或boxen,其中strip是默认值
sns.catplot(x='day', y='tip', hue='sex', col='time', kind="violin", data=tips, split=True)#split参数是小提琴图分类显示一半

(行按size分)加col_wrap参数可以定义列有多少列,这里我就不举栗子啦
sns.catplot(x='day', y='tip', hue='sex', col='size', kind="bar", data=tips)

分面网格关联图
在分面网格中绘制关联图使用relplot函数,默认画散点图,其他参数没有给的话只画一个图,一个大类
这里引用汽车数据集为例,先导入数据
mpg_df = sns.load_dataset('mpg')
mpg_df.head()
(小汽车每加仑在城市公路行驶的英里数)
- mpg:每加仑行驶英里数
- cylinders:汽缸数量
- displacement:排量
- horsepower:马力
- weight:重量
- acceleration:加速度
- model year:生成年份
- origin:原产地
- car name:本地

g = sns.relplot(x='displacement',y='mpg',col='cylinders',row='origin',data=mpg_df)#分裂,分行
#同一类型下的不同类别 col_wrap控制一列放几个,kind画什么类型的图,像点图,线图(line)等这里以点图为例

直方图、密度图、毛坦图
dist图
seaborn中的distplot函数可以绘制bist图,事实上统计学不存在dist图,seaborn中dist图是单变量的直方图和密度图的结合体。
distplot参数
seaborn.distplot(a, bins=None, hist=True, kde=True)
a参数是单变量数据,可以是数组、列表、series
bins参数是直方图中柱体的个数
hist参数是否绘制直方图
kde参数是否绘制密度图
kde密度曲线,如果不想要密度曲线就将它(kde)设置为false,该函数默认绘制的是直方图,并且带有kde核密度估计函数
sns.distplot(tip['total_bill'])

密度(KDE)图
核密度估计图,用来估计数据发布,如果单纯的只想要密度图可以使用函数kdeplot,该函数可以绘制:单变量和双变量图(等值线表示)。
其中参数shade指曲线下阴影,bw参数(bandwidth)指定kde拟合的精度,类似于直方图中的bins的效果,bw越小,曲线越精细。
sns.kdeplot(tips['total_bill'], shade=True)
sns.kdeplot(tips['total_bill'], bw=0.5, label='bw:0.5')
plt.legend()

双变量kde图,悄咪咪说一句有阴影很美哦
n = 1024
x = np.random.normal(0,1,n)
y = np.random.normal(0,1,n)
sns.kdeplot(x,y)

连接图
将单变量发布图与双变量图绘制到一个图表中,可以使用jointplot函数,主要参数有kind(绘制类型,scatter散点默认 、reg线性回归、 kde密度图、 hex六角形 )
连接图,kind默认散点图,rug,kde密度曲线图hex,如下图所示上边和右边是直方图,炫技的首选
n = 1024
x = np.random.normal(0,1,n)
y = np.random.normal(0,1,n)
g = sns.jointplot(x, y, kind="hex")

热力图
热力图是以矩阵形式表示数据的一种方式,数据值在图中表示为颜色,函数heatmap,其中颜色越深数值越小,颜色越浅数值越大,cmap参数是用来选择颜色(即colormap的意思)annot参数可以把数值标上去(不过可能看的有点乱,当数值少的时候还是挺不错的)vmin和vmax参数图例中最大值和最小值的显示值。

线性回归图
线性回归图通过大量数据找到模型拟合的线性回归线,使用函数regplot,值得注意的是两个参数必须是连续型变量
回归图:线性回归图regplot和分面网格FacetGrid线性回归图lmplot
df = sns.load_dataset('tips')
sns.regplot(x='total_bill',y='tip',data=df)

分面网格线性回归图
还是数据集“tips”,哈哈想不到吧,一直是它。
sns.lmplot(x='total_bill',y='tip',hue='sex',data=df)

分面网格绘图
通过facetgrid类绘图然后通过seaborn.FacetGrid.map方法将一个绘图函数作用于一个网格,并绘制子图,看下面的栗子
#绘制单变量分面网格
g = sns.FacetGrid(mpg_df,col='origin')#实例化把数据放进去
g.map(sns.distplot,'mpg')

分类散点图——strip图与swarm图
分类图有两种散点图:strip(带状)图和swarm(蜂群状)图
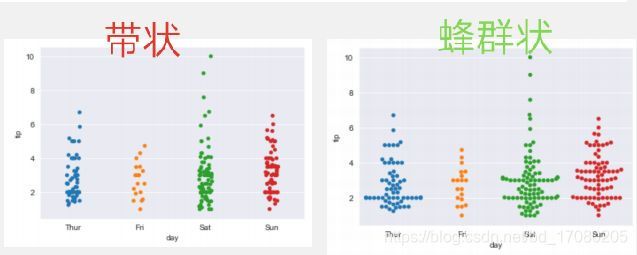
strip
其实如果想变成横着的可以把x,y互换,比如这样y=‘day’,x=‘tip’,
sns.stripplot(x='day', y='tip', data=tips, hue='sex')
比较有趣的是,在seaborn中有些图是可以叠加的,就比如说你可以把箱线图和散点图结合在一起,但是他们也可能不太适合加(看看下面的,嘿嘿嘿)

sns.swarmplot(x='day',y='tip',data=tips,color='r')
 (噫鹅~)
(噫鹅~)
散点图
关联散点图函数是seaborn.scatterplot,主要参数函数前面一样的x,y,hue分类变量,不分类谈论不写,size后面写类别型变量,用大小区分不同的类别,style点的类型,data。
来,让你们看看传说中的各种参数各种作妖
sns.scatterplot(x='total_bill', y='tip', hue='sex', style='time', size='size', data=tips)

小白还是要提醒大家一句,做图把自己最想表达的结论显示得一目了然才是最好的,不要太花里胡哨哦
线图
主要参数同散点图,函数是seaborn.lineplot
先举一个简单的栗子,像下面这样没有指明x,y的时候,index按编码,对应的a、b、c列连成线。
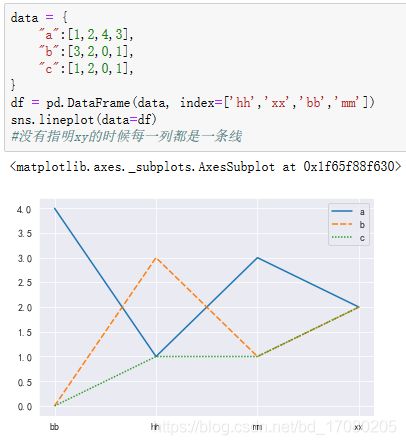
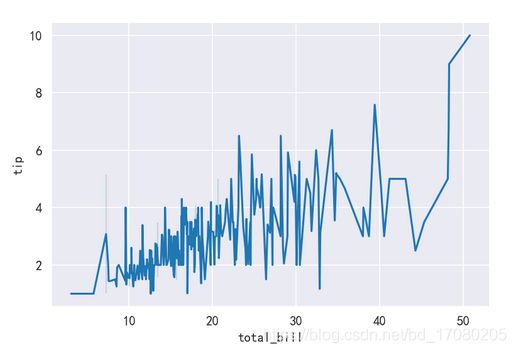
再来一个栗子,以数据集中的“tips”数据
tips = sns.load_dataset('tips')
plt.figure(dpi=150)
sns.lineplot(x='total_bill',y='tip',data=tips)
 如果按性别分类使用hue参数
如果按性别分类使用hue参数
sns.lineplot(x='total_bill',y='tip',hue='sex',data=tips)
