这篇文章是学习Kaldi的第二篇。对应SUSTech CS310课程的Lab6和Lab7。
第一篇里探索了如何对toy language(仅包含两个单音素单词)进行语言模型的建模。至于训练和解码的部分,时间条件和理解能力暂时不允许去整理。
本篇文章的主要目标是理解复杂的中文多音素语言模型和使用AiShell语料集来真实的训练出一个可用的中文语音识别模型。完整的AiShell例子包含GMM-HMM和神经网络。Lab6先展示了GMM-HMM后的结果。Lab7则补充了神经网络。
AiShell描述和下载
AiShell 是 ??公司开源的中文普通话语料集。400个来自不同方言区的人参与录制, 录制的条件是在室内使用高保真的麦克风,音频降采样到16000Hz。
//中文文字脚本95%的准确度
//170小时的语料。划分为85%的训练集,10%的开发集(作用?),5%的测试集。在上课的时候我被录制语料的成本吓到了,2000小时的语料大约需要100万人民币的费用。
AiShell语料集可以免费由于学术目的。
语料集下载
Kaldi中包含Aishell的示例脚本。在kaldi/egs/aishell/s5中。下文所有的文件都在该目录之下。
下载语料集的脚本包含在run.sh中。
先安装好语言模型的工具才能运行run.sh
run ./install_kaldi_lm.sh && source ../env.sh
上一篇文章没有说每一个项目下的s5文件夹中有什么,在网上找到了别人写的一个总结:kaldi 源码分析(三) - run.pl 分析
cmd.sh # 并行执行命令,通常分 run.pl, queue.pl 两种
config # 参数定制化配置文件, mfcc, decode, cmvn 等配置文件
local # 工程定制化内容
path.sh # 环境变量相关脚本
run.sh # 整体流程控制脚本,主入口脚本
steps # 存放单一步骤执行的脚本
utils # 存放解析文件,预处理等相
关工具的脚本
最重要的入口脚本是run.sh。包含所有脚本。如果要在本地运行,需要修改这个脚本。把其中的queue.pl改成run.pl。
export train_cmd="run.pl"
export decode_cmd=run.pl
export mkgraph_cmd="run.pl"
先做Lab6,注释掉神经网络训练部分。为了对比加不加神经网络对最后的识别准确率有多大的影响。
# nnet3
#local/nnet3/run_tdnn.sh
# chain
#local/chain/run_tdnn.sh
运行run.sh脚本,一步到位
在上一篇文章中,主要讲了kaldi的工作流程,复杂一点的项目除了要考虑多音素的对齐以外?基本流程是差不多的。先运行整体流程脚本run.sh看一下效果。然后再具体深入进脚本中看有哪些关键步骤。
你是否遇到过连接远程服务器跑训练,然后网络掉线杀掉了正在跑的进程?我遇到过,后来主要使用nohup来避免这个问题。课件里推荐使用screen来避免远程登陆进程被杀掉后,训练进程也停止的问题。screen的原理不是本篇文章关心的重点。
加上screen后运行run.sh:
screen -S run
run ./run.sh
就能看到脚本在一个新的页面输出内容了。
如果要结束进程ctrl a + d//我其实不喜欢这个命令,因为很经常使用ctrl+a来编辑命令,两个快捷键冲突。
查看结果
中文语音识别的准确度通常使用CER(Char Error Rate)来表示。因为中文中字是最小语义单位,而英文中词是基本语义单位。
和上一篇文章差不多的命令。脚本的运行结果保存在了exp目录下。
for x in exp/*/decode_test; do [ -d $x ] && grep WER $x/cer_* | utils/best_wer.sh; done 2>/dev/null
训练出来的结果如下:
可以cat RESULTS,和官方跑出来的结果做一下对比。
需要注意的是,和上篇文章的实验不一样的是,输出的结果是多行的,因为执行了多次的实验,上面的脚本输出的是每次实验最好的结果。
我自己跑出来的最好结果是tri5a的cer_14_0.5而RESULTS中的GMM-HMM模型中最好的结果是tri5a的cer_13_0.5。两者CER都是12.12。每次实验本身都有一定的随机性。结果有一些误差是没问题的。为了确认模型有被正确的训练,查看自己结果的
tri5a/decode_test/cer_13_0.5的CER是12.18,恰好不是最优解而已。这里的13和14是lmwt(语言模型权重)。具体的可以看上一篇文章。
细节
使用命令cat run.sh | grep "#"将run.sh脚本中的环节注释提取打印出来。其中倒数2,4行是我们在一开始注释掉的。可以看到基本可以分为准备、训练和获取结果三个部分。
准备
-
下载语料集
需要注意的是aishell语料集有大概20GB的大小。意味着需要很长的时间才能下载下来。我是直接用服务器里提前下好的语料集。
aishell目录概览
local/download_and_untar.sh $data $data_url data_aishell || exit 1;
这里的 a || b是一个逻辑符号,代表着如果a执行失败则执行b。这里要放一个小插曲。去年面试阿里云的实习项目时,面试官开头就问了如何知道上一条linux命令是否成功执行。我当时不知道,现在要知道了。就是看变量$?的值,如果为0代表成功执行。这里的exit 1终止当前进程并且将$?设置为1。表示不成功执行。
$data 是aishell在本机的位置,既可以新建一个空目录来下载,也可以指定到已经下好的路径,aishell 分为resource_aishell和data_aishell两部分来下载,脚本会通过检查每一个部分下是否有.complete文件来判断当前部分是否下载完全。如果没有才会到指定网址下载。
- Lexicon Preparation
local/aishell_prepare_dict.sh $data/resource_aishell || exit 1;
这个脚本的功能主要是将resource_aishell下的lexicon.txt复制到data/local/dict中。并且提取出nonsilence_phones.txt、optional_silence.txt、silence_phones.txt和extra_questions.txt。用到了很多awk和perl的脚本。没看懂。(要是看懂了,第一次assignment就不会搞砸了)
那就要求自己看懂把。
每行代表一组相同的base phone,包含各种不同的重音或者声调。
- Data preparation
local/aishell_data_prep.sh $data/data_aishell/wav $data/data_aishell/transcript || exit 1;
$data/data_aishell/wav目录下放着的是音频文件。其中有两级目录speaker/filename.wav。
$data/data_aishell/transcript目录下放着的是aishell_transcript_v0.8.txt文字翻录。
这个shell脚本的功能是将$data/data_aishell/wav下的 train,test,dev分别建立索引。并且建立Kaldi能够理解的语料格式。具体有些什么可以参考上一篇文章和下面这一段脚本。
# Transcriptions preparation
for dir in $train_dir $dev_dir $test_dir; do
echo Preparing $dir transcriptions
# 将当前集合目录下的wav的文件名提取出来作为utt_id
sed -e 's/\.wav//' $dir/wav.flist | awk -F '/' '{print $NF}' > $dir/utt.list
# 根据目录结构建立utt2spk的关系
sed -e 's/\.wav//' $dir/wav.flist | awk -F '/' '{i=NF-1;printf("%s %s\n",$NF,$i)}' > $dir/utt2spk_all
# 按列合并utt.list和wav.flist,达到对音频文件的映射。
paste -d' ' $dir/utt.list $dir/wav.flist > $dir/wav.scp_all
utils/filter_scp.pl -f 1 $dir/utt.list $aishell_text > $dir/transcripts.txt
awk '{print $1}' $dir/transcripts.txt > $dir/utt.list
utils/filter_scp.pl -f 1 $dir/utt.list $dir/utt2spk_all | sort -u > $dir/utt2spk
utils/filter_scp.pl -f 1 $dir/utt.list $dir/wav.scp_all | sort -u > $dir/wav.scp
sort -u $dir/transcripts.txt > $dir/text
utils/utt2spk_to_spk2utt.pl $dir/utt2spk > $dir/spk2utt
done
4. Phone sets, questions, L compilation
utils/prepare_lang.sh --position-dependent-phones false data/local/dict \
"" data/local/lang data/lang || exit 1;
上面shell脚本的目的是创建L.fst,音素模型,其中fst是Finite State Transducers(有限状态转换器)的缩写。找到这篇Kaldi学习笔记 -- 构建字典FST脚本 -- prepare_lang.sh 关键内容解析详细的说明了这个脚本的工作。而关于prepare_lang的一点理解给脚本进行了一些翻译和注释。
Kaldi中FST(Finite State Transducer)含义及其可视化
L.fst: 音素词典(Phonetic Dictionary or Lexicon)模型,phone symbols作为输入,word symbols作为输出,如图Figure 1所示。
Figure 1 L.fst结构
L_disambig.fst是为了消除模棱两可(disambiguation)而引入的模型,表述为 the lexicon with disambiguation symbols。分歧的情况如:一个词是另一个词的前缀,cat 和 cats在同一个词典中,则需要"k ae t #1"; 有同音的词,red: "r eh d #1", read: "r eh d #2"。
我一直疑惑lexiconp.txt是怎么生成的,查了好久。结果竟然只是一段在词和音素之间插入1.0的代码:
if [[ ! -f $srcdir/lexiconp.txt ]]; then
echo "**Creating $srcdir/lexiconp.txt from $srcdir/lexicon.txt"
perl -ape 's/(\S+\s+)(.+)/${1}1.0\t$2/;' < $srcdir/lexicon.txt > $srcdir/lexiconp.txt || exit 1;
fi
那么L.fst是怎么得到的呢?
通过
make_lexicon_fst.py(现有的博客都说是.pl结尾,可能kaldi重构了)。还有一个消歧义的过程。具体的就看不懂了。解码图创建示例(测试阶段)里有较为详细的文档讲解。
5. LM training
local/aishell_train_lms.sh || exit 1;
这个shell脚本读取data/local/train/text,data/local/dict/lexicon.txt
得到text的计数文件word.counts并以word.counts为基础添加lexicon.txt中的字(除了SIL)出现的次数到unigram.counts中。我就没深入看下去了,期间用到的脚本文件有:get_word_map.pl、train_lm.sh --arpa --lmtype 3gram-mincount $dir || exit 1;这个步骤的结果保存在data/local/lm/3gram-mincount/lm_unpruned.gz中。
6. G compilation, check LG composition
utils/format_lm.sh data/lang data/local/lm/3gram-mincount/lm_unpruned.gz \
data/local/dict/lexicon.txt data/lang_test || exit 1;
这个步骤是编译G.fst并将LG串联起来。
Kaldi中FST(Finite State Transducer)含义及其可视化
G.fst: 语言模型,大部分是FSA(finite state acceptor, i.e. 每个arc的输入输出是相同的),如图Figure 2所示。
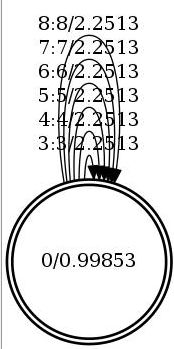 Figure 2 G.fst结构(由指令词识别1-gram语法产生,disambiguation symbol #0 未加入)
Figure 2 G.fst结构(由指令词识别1-gram语法产生,disambiguation symbol #0 未加入)
kaldi 训练 aishell 解析
utils/format_lm.sh:上述的语言工具基于第三方工具,为ARPA-format,脚本的作业是将其转换为fst,方便与之前的字典fst(L.fst)结合,发挥fst的优势。脚本最后会检测G.fst中是否存在没有单词的空回环,如果存在会报错,因为这会导致后续HLG determinization的出现错误。
脚本utils/format_lm.sh解决把ARPA格式的语言模型转换成OpenFST格式类型。脚本用法如下:
Usage: utils/format_lm.sh
E.g.: utils/format_lm.sh data/lang data/local/lm/foo.kn.gz data/local/dict/lexicon.txt data/lang_test
Convert ARPA-format language models to FSTs.
这个脚本的一些关键命令如下:
gunzip -c out_dir/words.txt - $out_dir/G.fst
Kaldi程序arpa2fst将ARPA格式的语言模型转换成一个加权有限状态转移机(实际上是接收机)。
流程很复杂,未来可能再把L.fst,LM training,G.fst, LG composition另起一篇。(就是说现在时间条件不允许深入)
训练
训练的环节开始我就读不懂了。主要是逻辑和概念不懂。也不浪费时间了。简单的去了解一下输入输出和功能。
1. MFCC 特征生成
这个环节和yesno项目的没有不同。主要就是获得train,test, dev三个集合的归一化的梅尔倒谱系数。最后修复排序错误,并会移除那些被指明需要特征数据或标注,但是却找不到被需要的数据的那些发音(utterances)。
2. 训练单音素模型
steps/train_mono.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/mono || exit 1;
参考kaldi-GMM-HMM pipeline,上面的shell脚本主要是对齐音素和每一帧音频的。Kaldi 入门train_mono.sh详解、kaldi学习笔记 -- 训练单音素(monophone)模型脚本 -- steps/train_mono.sh都有讲一些。
对流程讲得最好的是:
mkgraph 需要 lang_test 下的 L.fst G.fst phones.txt, words.txt , phones/silence.csl , phones/http://disambig.int
以及 exp/tri 下的 tree, final.mdl
在训练的job并行训练过程中,训练数据的各个子集合是分散到不同的处理器去进行训练,然后每轮迭代后会进行合并。
下面就讲一下训练的过程:
1.首先是初始化GMM,使用的脚本是/kaldi-trunk/src/gmmbin/gmm-init-mono,输出是0.mdl和tree文件;
2.compile training graphs,使用的脚本是/kaldi-trunk/source/bin/compile-training-graphs,输入是tree,0.mdl和L.fst,输出是fits.JOB.gz,其是在训练过程中构建graph的过程;
3.接下来是一个对齐的操作,kaldi-trunk/source/bin/align-equal-compiled;
4.然后是基于GMM的声学模型进行最大似然估计得过程,脚本为/kaldi-trunk/src/gmmbin/gmm-est;
5.然后进行迭代循环中进行操作,如果本步骤到了对齐的步骤,则调用脚本kaldi-kaldi/src/gmmbin/gmm-align-compiled;
6.重新估计GMM,累计状态,用脚本/kaldi-trunk/src/gmmbin/gmm-acc-states-ali;调用新生成的参数(高斯数)重新估计GMM,调用脚本/kaldi-trunk/src/gmmbin/gmm-est;
7.对分散在不同处理器上的结果进行合并,生成.mdl结果,调用脚本gmm-acc-sum;
8.增加高斯数,如果没有超过设定的迭代次数,则跳转到步骤5重新进行训练
最后生成的.mdl即为声学模型文件
在离线识别阶段,即可以调用utils/mkgraph.sh;来对刚刚生成的声学文件进行构图
之后解码,得到离线测试的识别率。
3. (Monophone decoding) 单音素解码
utils/mkgraph.sh data/lang_test exp/mono exp/mono/graph || exit 1;
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/mono/graph data/dev exp/mono/decode_dev
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/mono/graph data/test exp/mono/decode_test
mkgraph.sh将L_disambig.fst 和 G.fst 复合生成LG.fst。中间经历了我看不懂的处理。最终生成用于解码的 HCLG.fst。
看不懂的部分
后面就已经看不懂了。
# Get alignments from monophone system.
steps/align_si.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/mono exp/mono_ali || exit 1;
# train tri1 [first triphone pass]
steps/train_deltas.sh --cmd "$train_cmd" \
2500 20000 data/train data/lang exp/mono_ali exp/tri1 || exit 1;
# decode tri1
utils/mkgraph.sh data/lang_test exp/tri1 exp/tri1/graph || exit 1;
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/tri1/graph data/dev exp/tri1/decode_dev
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/tri1/graph data/test exp/tri1/decode_test
# align tri1
steps/align_si.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri1 exp/tri1_ali || exit 1;
# train tri2 [delta+delta-deltas]
steps/train_deltas.sh --cmd "$train_cmd" \
2500 20000 data/train data/lang exp/tri1_ali exp/tri2 || exit 1;
# decode tri2
utils/mkgraph.sh data/lang_test exp/tri2 exp/tri2/graph
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/tri2/graph data/dev exp/tri2/decode_dev
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/tri2/graph data/test exp/tri2/decode_test
# train and decode tri2b [LDA+MLLT]
steps/align_si.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri2 exp/tri2_ali || exit 1;
# Train tri3a, which is LDA+MLLT,
steps/train_lda_mllt.sh --cmd "$train_cmd" \
2500 20000 data/train data/lang exp/tri2_ali exp/tri3a || exit 1;
utils/mkgraph.sh data/lang_test exp/tri3a exp/tri3a/graph || exit 1;
steps/decode.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri3a/graph data/dev exp/tri3a/decode_dev
steps/decode.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri3a/graph data/test exp/tri3a/decode_test
# From now, we start building a more serious system (with SAT), and we'll
# do the alignment with fMLLR.
steps/align_fmllr.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri3a exp/tri3a_ali || exit 1;
steps/train_sat.sh --cmd "$train_cmd" \
2500 20000 data/train data/lang exp/tri3a_ali exp/tri4a || exit 1;
utils/mkgraph.sh data/lang_test exp/tri4a exp/tri4a/graph
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri4a/graph data/dev exp/tri4a/decode_dev
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri4a/graph data/test exp/tri4a/decode_test
steps/align_fmllr.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri4a exp/tri4a_ali
# Building a larger SAT system.
steps/train_sat.sh --cmd "$train_cmd" \
3500 100000 data/train data/lang exp/tri4a_ali exp/tri5a || exit 1;
utils/mkgraph.sh data/lang_test exp/tri5a exp/tri5a/graph || exit 1;
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri5a/graph data/dev exp/tri5a/decode_dev || exit 1;
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri5a/graph data/test exp/tri5a/decode_test || exit 1;
steps/align_fmllr.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri5a exp/tri5a_ali || exit 1;
# nnet3
local/nnet3/run_tdnn.sh
# chain
local/chain/run_tdnn.sh
获取结果
# getting results (see RESULTS file)
for x in exp/*/decode_test; do [ -d $x ] && grep WER $x/cer_* | utils/best_wer.sh; done 2>/dev/null
for x in exp/*/*/decode_test; do [ -d $x ] && grep WER $x/cer_* | utils/best_wer.sh; done 2>/dev/null
exit 0;
和上一篇文章一样的步骤。
Kaldi入门:yesno项目