离线分析fsimage文件进行数据深度分析
以离线分析FsImage文件进行数据深度分析
整个方案的基本架构:
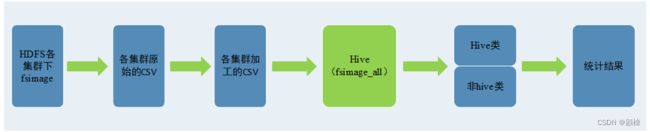
FsImage文件时HDFS存放在NameNode中的镜像文件,里面包括了整个HDFS集群的目录和文件信息,(类似于一个索引目录+部分数据的文件),而且HDFS提供了命令可以将FsImage文件转成CSV文件,可以用它在Hive上进行分析。目前fsiamge一般都是几十g的级别。
FsImage字段一览
| 字段名 | 中文 |
|---|---|
| Path | 目录路径 |
| Replication | 备份数 其实就是所有的存储份数 |
| ModificationTime | 最后修改时间 创建 |
| AccessTime | 对于文件来说是最后访问时间,对于文件夹来说就是创建时间 |
| PreferredBlockSize | 首选块大小 byte |
| BlocksCount | 块 数eeeeeeeeee |
| FileSize | 文件大小 byte |
| NSQUOTA | 名称配额 限制指定目录下允许的文件和目录的数量。 |
| DSQUOTA | 空间配额 限制该目录下允许的字节数 |
| Permission | 权限 |
| UserName | 用户 |
| GroupName | 用户组 |
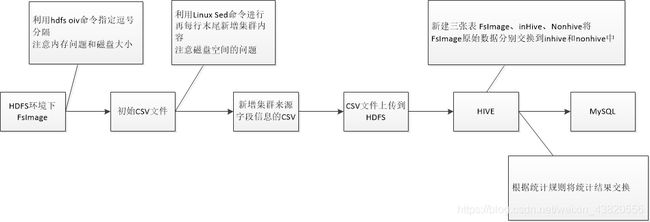
hdfs get命令
hdfs dfs -get /user/bigdata/fsimage_0000000010470664202 /opt/fsimage_001
hdfs vio命令:
hdfs oiv -i /opt/fsimage_001 -o /opt/fsimage_001.csv -p Delimited -delimiter ","
Linux sed命令: 在每行数据末尾后面新增,HDFS
sed -i s/$/,HDFS/g fsimage_001.csv
hdfs put命令
hdfs dfs -put /opt/fsimage_001.csv /user/hdfsser/hdfs_fsimage/fsimage_001.csv
Hive中的相关表
1. FsImage表 存放来自FsImage的初始数据
| 字段名 | 类型 | 备注 |
|---|---|---|
| Path | string | 目录路径 |
| Replication | string | 备份数 |
| ModificationTime | string | 最后修改时间 |
| AccessTime | string | string |
| PreferredBlockSize | string | 首选块大小 byte |
| BlocksCount | string | 块 数 |
| FileSize | string | 文件大小 byte |
| NSQUOTA | string | 名称配额 限制指定目录下允许的文件和目录的数量。 |
| DSQUOTA | string | 空间配额 限制该目录下允许的字节数 |
| Permission | string | 权限 |
| UserName | string | 用户 |
| GroupName | string | 用户组 |
| clustersource | string | 数据集群来源 |
2. inhive 存放Hive产生的文件
| 字段名 | 类型 | 备注 |
|---|---|---|
| Path | string | 完成目录路径 |
| dbname | string | Hive库名 |
| tablename | string | Hive表名 |
| FileSize | string | 文件大小 byte |
| UserName | string | 用户 |
| clustersource | string | 数据集群来源 |
3. nonhive 存放非Hive的文件
| 字段名 | 类型 | 备注 |
|---|---|---|
| Path | string | 目录路径 不包含文件名 |
| filename | string | 文件名 |
| FileSize | string | 文件大小 byte |
| UserName | string | 用户 |
| clustersource | string | 数据集群来源 |
Hive数据交换语句中涉及到的函数
字符串长度函数:length
语法: length(string A)
返回值: int
说明:返回字符串A的长度
字符串反转函数:reverse
语法: reverse(string A)
返回值: string
说明:返回字符串A的反转结果
字符串截取函数:substr,substring
语法: substr(string A, int start),substring(string A, int start)
返回值: string
说明:返回字符串A从start位置到结尾的字符串
字符串截取函数:substr,substring
语法: substr(string A, int start, int len),substring(string A, intstart, int len)
返回值: string
说明:返回字符串A从start位置开始,长度为len的字符串
分割字符串函数: split
语法: split(string str, string pat)
返回值: array
说明:按照pat字符串分割str,会返回分割后的字符串数组
向下取整函数
语法:floor(double d)
返回值:bigint
说明:返回<=d的最大bigint值;
向下取整函数
语法:ceil(double d)
返回值:bigint
说明:返回>=d的最小bigint 值;
部分SQL语句示例
-
启动Hive,直接使用hive命令
$ hive; -
进入对应的数据库 use hdfsser;
hive> use hdfsser; -
查询出插入inhive表的语句
INSERT INTO TABLE inhive
SELECT path,
split(path,'\\/')[5],
split(path,'\\/')[6],
FileSize,
UserName,
clustersource
FROM fsimage
WHERE split(path,'\\/')[3]= 'hive' and split(path,'\\/')[4] = 'warehouse';
- 查询出插入nonhive表的语句
INSERT INTO TABLE nonhive
SELECT CASE
WHEN filesize='0' THEN path
ELSE substr(path, 0, length(path)-1-length(reverse(split(reverse(path),'\\/')[0])))
END,
CASE
WHEN filesize='0' THEN NULL
ELSE reverse(split(reverse(path),'\\/')[0])
END ,
FileSize,
UserName,
clustersource
FROM fsimage
WHERE size(split(path,'\\/'))<=3
OR split(path,'\\/')[3] <> 'hive';
小文件分析
小文件的定义
- 判断小文件的规则:
1、文件大小<1MB;(最好支持配置或者sql脚本传参)
2、目录下文件数量>10000(最好支持配置或者sql脚本传参) - 需要治理哪些用户的小文件规则:
1、hive小文件数大于100W的用户;|
2、hive小文件占比超过30%的用户。(hive小文件/hive文件总数)
未定问题
- 文件目录第三级目录为hive,第四级目录不为warehouse的数据存放位置。
- [目录下文件>10000]目录指的是几级目录,目录的规则需要根据治理目标再确认。
其他分析
在文件大小的不同区间进行分析,单位大小MB
(0-1),[1,10),[10,128),[128-512),[512,+∞)
各个区间下的文件数量,目录数量
- 特征1 文件的数量远大于目录数量
- 特征2 某个目录下文件数量过多
- 特征3 目录的组成有明显的序列,日志log/logs 日期yyyy-MM-dd 临时tmp temp checkpoint等等的
两大考量点 一个是文件数量一个是文件或目录类型
- 文件数量指的是 单个目录下小文件的数量,可以定义一个阀值,目录小文件下超过阀值的就肯定需要治理,阀值可以是1000,1W,10W
- 文件或目录类型指的是 一些目录或者文件是特定任务或者临时产生使用的。比如日志文件(log,logs)、临时文件或者目录(tmp,temp,temp_transfer),Flink,Spark任务(checkpoint),长年未访问的文件(这个指文件)