弄了SSE指令集,必然会在不同的场合不同的人群中了解到还有更为高级的AVX指令集的存在,早些年也确实有偶尔写点AVX的函数,但是一直没有深入的去了解,今年十一期间也没到那里去玩,一个人在家里抽空就折腾下这个东西,也慢慢的开始了解了这个东西,下面是基于目前的认知对这个东西进行下一个简单的小结,有些东西也许是不正确或者不全面的,但应该无伤大雅。
第一、用AVX指令集必须做好合适的IDE配置。
如果你们有看过我之前的一些文章,应该可以看到我在部分博文中有多次提高过“使用AVX对该算法似乎没有什么速度和效率方面的提升”,那么现在我这里要稍微纠正一下:即如果一个算法可以用AVX有效的写出来,那么其效率肯定是不会比同样思路的SSE代码效率低,核心是需要更改一些配置,核心的是下面的配置:
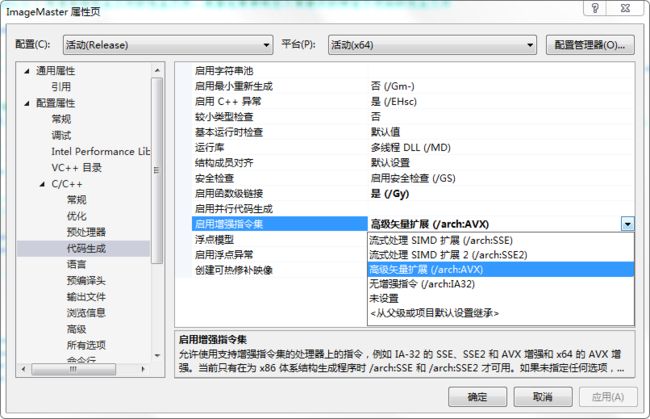
即如果你自己使用AVX的Intrinsic编码, 那么在C/C++ ->代码生成的启用增强指令集里一定要选择 高级矢量扩展(/arch:AVX)选项,或者高级版本的VS可以选择高级矢量扩展(/arch:AVX2)。
如果您没有选择上面的这些选项,比如选择了流式处理SIMD扩展(SSE),那么很有可能,你使用的AVX算法会得到效率很低的版本,我想一个核心的原因是你如果勾选了SSE,那么你在算法里的部分代码会被编译器优化为SSE代码,这样就可能存在AVX和SSE代码共存的情况,但是几乎可以肯定的是,AVX <-> SSE转换延迟是由于将传统SSE与没有vzeroupper的256位AVX指令混合使用引起的。而如果选择" / arch:AVX",则编译器可能很好照顾你自己写的SSE代码,他会在适当的地方加上类似于vzeroupper这样的代码。
第二:AVX代码很难完全脱离SSE单独使用。
AVX无法像SSE一样,独立的使用其体系内的函数完成一个独立的功能,我们去看AVX的指令系统,其很多参数或者返回值都有__m128,__m128i,__m128d这些SSE数据类型的影子,因此AVX必然和SSE共存,比如大量的数据类型转换函数,提取函数等等。
第三:AVX并不是简单的SSE的扩展,很多函数的使用方式完全不同了。
原本以为一些和SSE形态基本一样的函数只是把128位扩展到256位,那么原来的SSE代码只要改下循环步长就可以了,但是实际上很多函数已经不是这样了。
其中数据计算类、类型转换类、数据加载保存类、数值比较类、大部分移位类基本上是直接的扩展,这些比较典型的比如 加减陈处、最大、最小、平均值、8位转为16位,16位转为32位、数据大小比较等等。
但是shuffle类函数、unpack拆包类、pack打包类就完蛋了,他们都是以一个128位为一个平面进行的,就相当于他们就是对2个SSE进行同样的操作。这样的操作初步看起来对于SSE代码转AVX是个灾难,因为其实我们知道特别是shuffle,是SSE的精华,这样的话,如果用到了shuffle类的函数,所有的代码都要从算法层次上更改。同样的打包函数也是有类似的情况。
特别是_mm_shuffle_epi8这个函数,他其实可以代替其他所有的shuffle,因为他是以字节为单位的。同样_mm256_shuffle_epi8则是以高低2个128位lanes独立操作,相互之间的shuffle互不相干,这样导致高低位之间无法直接交流。
另外,还有一个比较特别的移位函数,也是以128位一个平面进行操作的,他们就是_mm256_srli_si256、_mm256_slli_si256 ,这也导致一些以字节为单位的移位算法,无法直接使用了。
第四、没有AVX2的AVX对图像处理来说简直是个灾难。
上面说了AVX和SSE的这些不同,这些不同给图像处理带来了很大的困惑,因为图像的数据基本都是以字节为单位的,而且很多计算都是以整形为基础的,在AVX中,强调的主要是高性能计算,提供的函数基本上都是针对浮点数的,很少有整形的函数。也缺少一些数据的相互转换。所以AVX2给我们带来了希望,增加了丰富和完整的数据类型转换函数、以及各种整形的比较、数值计算、移位等功能,可以说,AVX2对于AVX就有点类似于SSE4.2对于SSE,有了他,对于图像来说,就有了灵魂了。
另外,AVX2还增加了一些的permute方面的函数,这个为我们打通AVX中2个独立128位lanes提供了有力的工具和手段。比如说如果我们需要把2个__m256i中的整形数据(8个int32)保存到16个字节中,这肯定是需要使用打包功能的,但是AVX的打包不是按照SSE的方式进行的打包,这个时候我们就可以用_mm256_permutevar8x32_epi32来协调处理。
inline void _mm256_store2si256_16char(unsigned char *Dest, __m256i Result_L, __m256i Result_H)
{
// short A0 A1 A2 A3 B0 B1 B2 B3 A4 A5 A6 A7 B4 B5 B6 B7
__m256i Result = _mm256_packs_epi32(Result_L, Result_H);
// byte A0 A1 A2 A3 B0 B1 B2 B3 0 0 0 0 0 0 0 0 A4 A5 A6 A7 B4 B5 B6 B7 0 0 0 0 0 0 0 0
Result = _mm256_packus_epi16(Result, _mm256_setzero_si256());
// A0 A1 A2 A3 B0 B1 B2 B3 A4 A5 A6 A7 B4 B5 B6 B7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
_mm_storeu_si128((__m128i *)Dest, _mm256_castsi256_si128(_mm256_permutevar8x32_epi32(Result, _mm256_setr_epi32(0, 4, 1, 5, 2, 3, 6, 7))));
}
可以这样认为,_mm256_permutevar8x32_epi32就是类似于SSE环境下的256位的32位shuffle,即真正的_mm256_shuffle_epi32。
AVX2里还增加了一各比较特别的功能,gather系列指令,这个系列的指令可以从不同的位置收集数据到寄存器中,这个是在SSE中缺失的。这个功能可以实现更为快速的数据查表功能,我们后续应该会有一个单独的文章讲这个算子。
第五、AVX相较于SSE的提速可能没有你想象的高
表面上看,AVX一次性可以处理256位数据,SSE只能处理128位,带宽是提高了一倍,但是从实际的测试表现来看,同样的算法,使用AVX的提速比相对于SSE来说绝对是不可能达到1倍的,能有40%的提速就已经很不错了,这也导致我们从SSE转型为AVX时能得到的喜悦绝对没有从C++转型到SSE时那么充足。很多算法只有5%的提速,这当然于算法本身的结构有关,如果是以读取内存为主的程序,提速比会很低,以数值计算、比较等等为主的程序就要稍微高一些,我目前写的一些AVX程序和SSE比较,提速比大概5%到35%之间。
另外一点,在不同的CPU上(都支持AVX及AVX2),同一个算法的提速比例也是不同,我甚至遇到过AVX还比SSE慢一点的CPU(都是64位程序),这个目前我不知道是为什么。
第六、AVX和SSE的选择问题
这个没有绝对的,只是谈点自己的看法。
在PC上,一个算法如果需要使用SIMD优化,除了考虑硬件的因素外(现在市面上能看到的硬件不支持AVX或者AVX2的还是有很多在使用的,特备是AVX2,我他妈的去年买的一个机器,CPU居然还只支持AVX,也是醉了),还要考虑算法本身的粒度,SSE真的很自由,特别是shuffle,说实在的,我倒现在还没想到,如何用AVX2实现 32个字节的自由shuffle, AVX的那个_mm256_shuffle_epi8就是个太监啊。 所以你的算法里需要借用大量这样的shuffle,还是考虑用SSE吧, 如果以32位整形数据或者浮点计算为主,AVX肯定在效率上还是要更为高效。
在学习曲线上,如果你没有AVX的基础,直接从C开始使用AVX,你会发现你要做很多弯路,因为正如前面所述,使用AVX脱离不了SSE,最好先了解一点SSE的知识。
如果有SSE的基础,去转学AVX,则轻松很多,只需要把AVX2里的那个permute、broadcast等等理解透了,你也就基本掌握了真谛。
其他:
十一期间,我大概把我原有的基于SSE算法里抽取20个左右,转换为AVX的版本,另外,还提供了普通的C语言版本的算法,并提供了速度比较,注意,其实这里的C语言算法,并不是真正的C算法了,他只能说是编译器自动向量化后的算法,也就是比较编译器自己的向量化和我们手工向量化的速度差异了。因为在同一个DEMO里,为了照顾AVX的代码,只能选择/arch:AVX选项。

本文可执行Demo下载地址: https://files.cnblogs.com/files/Imageshop/SSE_Optimization_Demo.rar,菜单中蓝色字体显示的部分为已经使用AVX加速的算法,如果您的硬件中不支持AVX,可能这个DEMO你无法运行。