科研作图-Accuracy,F1-score,Precision,Sensitive,混淆矩阵
1. 简介
在文章中评价实验结果的好坏比较重要的分类指标有Accuracy(准确率), F1-score(由Precision和Sensitive计算而成),Precision(精确度),Recall(召回率),混淆矩阵。我们首先来介绍不同指标的概念与计算方法,最后再使用库函数展现评价指标。
2. Accuracy,F1-score,Precision,Sensitive的计算
首先介绍四个不同的概念:TP、TN、FP、FN
TP(True Positive):预测为正的真实值也为正的样本。
TN(True Negative):预测值为负的真实值也为负的样本。
FP(False Positive):预测值为正的真实值为负的样本。
FN(False Negative):预测值为负的真实值为正的样本。
(1) Accuracy(准确率)
Accuracy = (TP + TN) / (TP + TN + FP + FN) 准确率为预测正确的占所有数量的比例。
(2)Precision(精确度也叫查准率)
Precision = TP / (TP + FP) 精确度反应的是预测正确的positive占所有预测为positive的比例。
(3)Recall(召回率也叫查全率)
Recall = TP / (TP+FN) 召回率反应了在所有正样本中检出为正样本的数量。灵敏度与召回率计算相同sensitive = TP / (TP+FN),表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。而我们也常常听过特异性(specificity)它与精确度的评价效果类似,但它表示的是所有负例中被分对的比例,specificity = TN / (TN + FP),衡量了分类器对负例的识别能力。
(4)F1-score
Precision和Recall指标并不能全面的反应结果的好坏,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。F-Measure是Precision和Recall加权调和平均:

当a为1时就是F1-score,即:
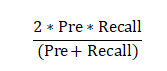
由于F1-score综合了Pre和Recall,因此更能评价结果的优劣。
3. 混淆矩阵
混淆能够直观的反应预测正确和错误的数量和比重。

4. 机器学习sklearn库中求Accuracy,F1-score,Precision,Sensitive和混淆矩阵的代码
from sklearn.metrics import classification_report
y_true = [0,1,2,3,1,2,3]
y_pred = [0,1,2,3,1,1,1]
# 一共0,1,2,3 四类,且保留三位小数
t = classification_report(y_true, y_pred,target_names=['0','1','2','3'], digits=3)
print(t)
输出结果如图所示,该图显示了不同类的评价指标:

混淆矩阵的代码如下:
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
y_true = [0,1,2,3,1,2,3,3]
y_pred = [0,1,2,3,1,1,1,2]
classes = ['0', '1', '2', '3']
confusion = confusion_matrix(y_true, y_pred)
plt.imshow(confusion, cmap=plt.cm.Blues) #此处可以修改为其他颜色
indices = range(len(confusion))
plt.xticks(indices, classes)
plt.yticks(indices, classes)
plt.colorbar()
plt.xlabel('y_pred')
plt.ylabel('y_true')
#显示数据
for first_index in range(len(confusion)):
for second_index in range(len(confusion[first_index])):
plt.text(first_index,second_index,confusion[second_index][first_index])
plt.savefig('1.png') #保存结果
plt.show()
结果如图所示:

5. 总结
今天我们介绍了常见的分类评价指标的计算以及怎样使用代码去生成相应的结果,下次我们接着讲解ROC曲线和AUC值,这个评价指标在文章中也是出现的频率较高的,那么如何才能使用代码生成自己的结果呢?答案下期揭晓。