嵌入式(轻量级)车道线语义分割模型搭建
1.语义分割介绍
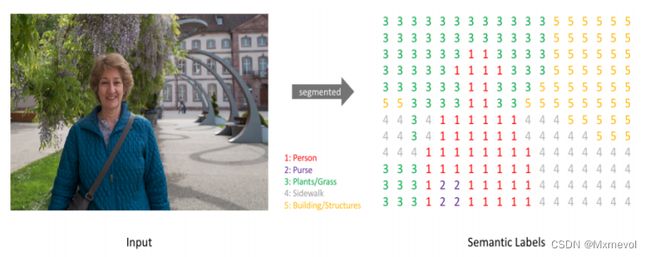
语义分割主要包括语义分割(Semantic Segmentation)和实例分割(Instance Segmentantion)。语义分割是对图像中的每个像素都划分出对应的类别,即实现像素级别的分类。实例分割不但要分类像素,还需要在具体的类别基础上区别开不同的个体。语义分割的输入是一张原始的RGB图像或者简单单通道图像,但是输出不再是简单的分类类别或者目标定位,而是带有各个像素类别标签的与输入同分辨率的分割图像。简单的来说,我们的输入输出都是图像,而且是同样大小的图像。
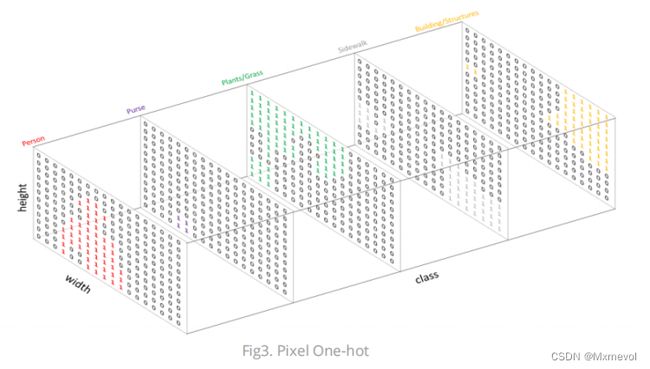
类似于图像处理分类标签数据,对预测分类目标采用像素上的one-hot编码,即为每个分类类别创建一个输出的通道。
下图是将分割图像添加到原始图像中的叠加效果。这里需要明确一下mask的概念,在图像处理中我们将其称为掩码,如Mask-R C-nn中的Mask,Mask可以理解为我们将预测结果叠加戴单个通道时得到的该分类所在区域。

所以语义分割的任务就是输入图像经过深度学习算法处理得到带有语义标签的同样尺寸的输出图像。
2.U-Net介绍
本次网络搭建的就是经典的U型语义分割网络Unet的魔改,使得其能够更加是使用在嵌入式设备能够进行实时检测,如Jetson nano中。语义分割网络的核心构件就是编码器和解码器。
语义分割详细介绍文章
3.本模型介绍
本模型是基于一片论文复现修改实现了,用pytorch框架实现,上代码
# -*- coding:utf-8 _*-
from collections import OrderedDict
import torch.nn as nn
class UNet(nn.Module):
def __init__(self, in_channels=3, out_channels=2, init_features=8):
super(UNet, self).__init__()
features = init_features
# 编码
self.encoder1 = UNet._block3(in_channels, features, name="enc1")
self.encoder2 = UNet._block3(features, features * 2, name="enc2")
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.encoder3 = UNet._block3(features * 2, features * 2, name="enc3")
self.dop3 = nn.Dropout(0.2)
self.encoder4 = UNet._block3(features * 2, features * 4, name="enc4")
self.dop4 = nn.Dropout(0.2)
self.encoder5 = UNet._block3(features * 4, features * 4, name="enc5")
self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2)
self.dop5 = nn.Dropout(0.2)
self.encoder6 = UNet._block3(features * 4, features * 8, name="enc6")
self.dop6 = nn.Dropout(0.2)
self.encoder7 = UNet._block3(features * 8, features * 8, name="enc7")
self.dop7 = nn.Dropout(0.2)
self.pool7 = nn.MaxPool2d(kernel_size=2, stride=2)
# 解码
self.decoder10 = UNet._Tblock2(features * 8, features * 8, name="dec10")
self.decoder9 = UNet._Tblock3(features * 8, features * 8, name="dec9")
self.tdop9 = nn.Dropout(0.2)
self.decoder8 = UNet._Tblock3(features * 8, features * 8, name="dec8")
self.tdop8 = nn.Dropout(0.2)
self.decoder7 = UNet._Tblock2(features * 8, features * 8, name="dec7")
self.decoder6 = UNet._Tblock3(features * 8, features * 4, name="dec6")
self.tdop6 = nn.Dropout(0.2)
self.decoder5 = UNet._Tblock3(features * 4, features * 4, name="dec5")
self.tdop5 = nn.Dropout(0.2)
self.decoder4 = UNet._Tblock3(features * 4, features * 2, name="dec4")
self.tdop4 = nn.Dropout(0.2)
self.decoder3 = UNet._Tblock2(features * 2, features * 2, name="dec3")
self.decoder2 = UNet._block3(features * 2, features, name="dec2")
self.decoder1 = UNet._block3(features, out_channels, name="dec1")
def forward(self, x):
enc1 = self.encoder1(x)
enc2 = self.encoder2(enc1)
enc3 = self.dop3(self.encoder3(self.pool2(enc2)))
enc4 = self.dop4(self.encoder4(enc3))
enc5 = self.dop5(self.encoder5(enc4))
enc6 = self.dop6(self.encoder6(self.pool5(enc5)))
enc7 = self.dop7(self.encoder7(enc6))
enc = self.pool7(enc7)
dec9 = self.tdop9(self.decoder10(enc))
dec8 = self.tdop8(self.decoder9(dec9))
dec7 = self.decoder8(dec8)
dec6 = self.tdop6(self.decoder7(dec7))
dec5 = self.tdop5(self.decoder6(dec6))
dec4 = self.tdop4(self.decoder5(dec5))
dec3 = self.decoder4(dec4)
dec2 = self.decoder3(dec3)
dec1 = self.decoder2(dec2)
out = self.decoder1(dec1)
return out
@staticmethod
def _block3(in_channels, features, name):
return nn.Sequential(
OrderedDict( # 用字典的形式进行网络定义,字典key即为网络每一层的名称
[
(
name + "conv3",
nn.Conv2d(
in_channels=in_channels,
out_channels=features,
kernel_size=3,
padding=1,
bias=False,
),
),
(name + "relu1", nn.ReLU(inplace=True)),
]
)
)
@staticmethod
def _Tblock3(in_channels, features, name):
return nn.Sequential(
OrderedDict( # 用字典的形式进行网络定义,字典key即为网络每一层的名称
[
(
name + "Tconv3",
nn.ConvTranspose2d(
in_channels=in_channels,
out_channels=features,
kernel_size=3,
padding=1,
bias=False,
),
),
(name + "relu1", nn.ReLU(inplace=True)),
(name + "norm2", nn.BatchNorm2d(num_features=features)),
]
)
)
@staticmethod
def _Tblock2(in_channels, features, name):
return nn.Sequential(
OrderedDict( # 用字典的形式进行网络定义,字典key即为网络每一层的名称
[
(name + "up",
nn.Upsample(
scale_factor=2,
mode='bilinear',
align_corners=True)
),
(
name + "Tconv2",
nn.ConvTranspose2d(
in_channels=in_channels,
out_channels=features,
kernel_size=2,
padding=1,
bias=False,
)
),
(name + "norm2", nn.BatchNorm2d(num_features=features)),
]
)
)
本模型是为了实现车道线检测而搭建,最终得到的模型精度达到94%,模型大小为853kb,最终在Jetson Nano的FPS达到25帧左右,已经基本满足实时的要求。
杜中强,唐林波,韩煜祺.面向嵌入式平台的车道线检测方法[J/OL].红外与
激光工程. https://kns.cnki.net/kcms/detail/12.1261.tn.20211207.1052.004.html