ls + awk 获取文件信息(json格式)
目前正在通过jsch实现一个通过web页面操作服务器文件的功能,如下图所示。
为了简化操作,直接通过ls和awk命令获取文件信息并转成json字符串,供前端展示。文件格式如下:
[
{
"typeAndPermission": "dr-xr-x---.",
"owner": "root",
"group": "root",
"size": "12288",
"lastAccessTime": "2021-06-14 05:01:08.692827320",
"name": "."
},
{
"typeAndPermission": "dr-xr-xr-x.",
"owner": "root",
"group": "root",
"size": "4096",
"lastAccessTime": "2021-06-12 02:44:48.665186744",
"name": ".."
},
{
"typeAndPermission": "-rw-------",
"owner": "root",
"group": "root",
"size": "5491",
"lastAccessTime": "2021-06-14 01:13:47.455249540",
"name": ".viminfo"
}
]
终版命令行
经过几版的修改,目前稳定使用的命令行:
ls -al --time-style=full ~ | \
awk 'BEGIN {print "["} NR>1 \
{ printf "{ \
\"typeAndPermission\": \""$1"\", \
\"owner\": \""$3"\",\"group\": \""$4"\", \
\"size\": \""$5"\",\"lastAccessTime\": \""$6" "$7"\",\
\"name\":"; print "\""substr($0, index($0,$7" "$8)+length($7" "$8)+1)"\"},"} \
END {print "]"}' | \
sed 'N;$s/},/}/;P;D';
第一版
开始自然而然根据ls -al --time-style=full的输出结果写了第一版的命令:
ls -al --time-style=full ~ | \
awk 'BEGIN {print "["} NR>1 \
{ print "{ \
\"typeAndPermission\": \""$1"\", \
\"owner\": \""$3"\",\"group\": \""$4"\", \
\"size\": \""$5"\",\"lastAccessTime\": \""$6" "$7"\",\
\"name\": \""$9"\"}, \
"} END {print "]"}' | \
sed 'N;$s/},/}/;P;D';
但是在使用的过程中发现,有一些文件名称会存在一些特殊字符,例如空格, 以上的命令无法获取完整的文件名称
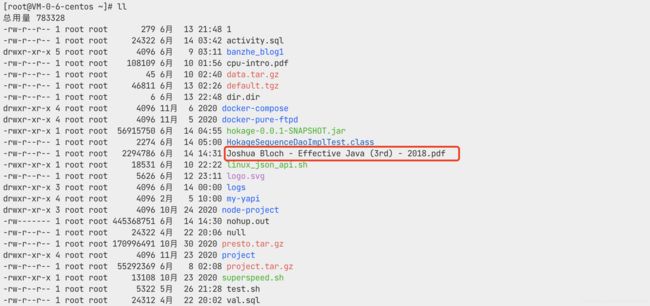
本来名称是Joshua Bloch - Effective Java (3rd) - 2018.pdf的文件,却只取出了Joshua,不满足使用要求,所以对命令行进行了改进。
[
{
"typeAndPermission": "dr-xr-x---.",
"owner": "root",
"group": "root",
"size": "12288",
"lastAccessTime": "2021-06-14 14:33:08.925973350",
"name": "."
},
{
"typeAndPermission": "dr-xr-xr-x.",
"owner": "root",
"group": "root",
"size": "4096",
"lastAccessTime": "2021-06-12 02:44:48.665186744",
"name": ".."
},
{
"typeAndPermission": "-rw-r--r--",
"owner": "root",
"group": "root",
"size": "2294786",
"lastAccessTime": "2021-06-14 14:31:34.760653561",
"name": "Joshua"
}
]
第二版
通过观察ls -al --time-style=full的输出结果发现,文件名称所处的列为$9-$NF, 如果文件名称不存在空格时,文件名称即$9列对应的值,如果文件名称中存在空格,文件名称则对应$9 $10 ... $NF的值,根据这个逻辑很容易完成命令行的改造:
ls -al --time-style=full ~ | \
awk 'BEGIN {print "["} NR>1 \
{ printf "{ \
\"typeAndPermission\": \""$1"\", \
\"owner\": \""$3"\",\"group\": \""$4"\", \
\"size\": \""$5"\",\"lastAccessTime\": \""$6" "$7"\",\
\"name\":"; name=$9;for(i=10;i<=NF;i++)name=name" "$i; print "\""name"\"}, "} \
END {print "]"}' | \
sed 'N;$s/},/}/;P;D';
此时对于存在空格的文件名称也可以提出出来了!
[
{
"typeAndPermission": "-rw-r--r--",
"owner": "root",
"group": "root",
"size": "2294786",
"lastAccessTime": "2021-06-14 14:31:34.760653561",
"name": "Joshua Bloch - Effective Java (3rd) - 2018.pdf"
}
]
但是,在使用过程又发现文件名中可能存在多个连续的空格,例如
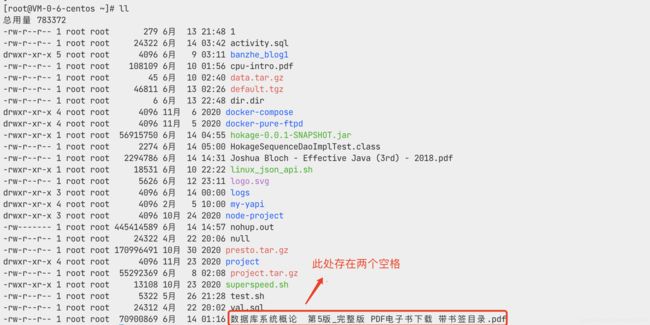
按照上面的命令行,得到的结果是:多个空格被删减为单个空格,在使用jsch对文件进行相关操作时,会抛出没有那个文件或目录异常,所以还需要对命令行进行改造。
第三版
经过一番搜索,发现可以使用awk命令的内建函数:awk '{print substr($0, index($0,$9))}'实现,主要原理就是找出文件名在整行内容中出现的位置索引,然后通过substr获取文件名。所以立马又对命令行进行了改造:
ls -al --time-style=full ~ | \
awk 'BEGIN {print "["} NR>1 \
{ printf "{ \
\"typeAndPermission\": \""$1"\", \
\"owner\": \""$3"\",\"group\": \""$4"\", \
\"size\": \""$5"\",\"lastAccessTime\": \""$6" "$7"\",\
\"name\":"; print "\""substr($0, index($0,$9))"\"},"} \
END {print "]"}' | \
sed 'N;$s/},/}/;P;D';
发现确实满足了提取包含多个空格的文件名
{
"typeAndPermission": "-rw-r--r--",
"owner": "root",
"group": "root",
"size": "70900869",
"lastAccessTime": "2021-06-14 01:16:31.794812285",
"name": "数据库系统概论 第5版_完整版 PDF电子书下载 带书签目录.pdf"
}
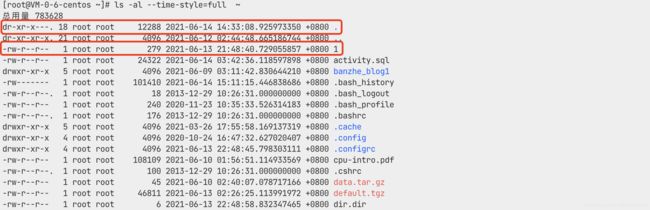
但是存在几个文件名称提取出现了错误:本来名称是.和1的文件名称,却抽取成了. 18 root root 12288 2021-06-14 14:33:08.925973350 +0800 ., 1 root root 279 2021-06-13 21:48:40.729055857 +0800 1
[
{
"typeAndPermission": "dr-xr-x---.",
"owner": "root",
"group": "root",
"size": "12288",
"lastAccessTime": "2021-06-14 14:33:08.925973350",
"name": ". 18 root root 12288 2021-06-14 14:33:08.925973350 +0800 ."
},
{
"typeAndPermission": "-rw-r--r--",
"owner": "root",
"group": "root",
"size": "279",
"lastAccessTime": "2021-06-13 21:48:40.729055857",
"name": "1 root root 279 2021-06-13 21:48:40.729055857 +0800 1"
}
]
第四版
通过观察ls的输出结果,可以发现,对于文件., $1中包含了$9的值,所以substr截取的时候,截取的值是$2~$9, 对于 文件1,$2与$9一样,所以substr截取了$2~$9的值。所以不能直接通过index($0,$9)获取,观察ls的结果,可以发现$7 $8是固定的,而且不会与前面的列重复,所以使用index($0, $7" "$8)作为索引即可:
ls -al --time-style=full ~ | \
awk 'BEGIN {print "["} NR>1 \
{ printf "{ \
\"typeAndPermission\": \""$1"\", \
\"owner\": \""$3"\",\"group\": \""$4"\", \
\"size\": \""$5"\",\"lastAccessTime\": \""$6" "$7"\",\
\"name\":"; print "\""substr($0, index($0,$7" "$8)+length($7" "$8)+1)"\"},"} \
END {print "]"}' | \
sed 'N;$s/},/}/;P;D';
目前此版本命令行还未发现特殊的用例,仍在使用中