最新版Ambari2.75安装及HDP3.1.5集群搭建
最近打算使用ambari搭建集群,却突然发现Cloudera相关软件包括HDP、CDH都收费了,都需要有效的订阅,并且只能通过付费墙进行访问(官宣地址:关于Cloudera软件的访问获取)。还好笔者千辛万苦在内外网找了两天才搞到最新版ambari2.7.5和HDP3.1.5的二进制安装包。以下详细介绍ambari的安装,及使用ambari搭建HDP集群的详细步骤,以及遇到的各种问题;文中有提供ambari2.7.5和HDP3.1.5的二进制安装包的百度网盘下载地址。
Ambari2.7.5和HDP3.1.5二进制安装包下载地址:ambari2.7.5百度网盘下载地址.txt_ambari2.7.5-Hadoop工具类资源-CSDN下载
前言
这次集群安装使用5台机器,分别是hadoop01、hadoop02、hadoop03、hadoop04、hadoop05。其中,hadoop01为ambari server所在节点,也是mysql所在节点,也是下文提到的镜像服务器。
1、环境准备
1.1安装必备软件
yum -y install gcc gcc-c++ kernel-devel libtirpc-devel
yum -y install rpm-build
yum -y install net-tools
yum -y install openssl openssl-devel patch
yum -y install wget
yum install -y bash-completion
yum install -y unzip zip
1.2安装ssh
yum install -y openssh-clients
yum install -y openssh-server
#启动
/usr/sbin/sshd -D &
1.3内存需要
| Number of hosts |
Memory Available |
Disk Space |
| 1 |
1024 MB |
10 GB |
| 10 |
1024 MB |
20 GB |
| 50 |
2048 MB |
50 GB |
| 100 |
4096 MB |
100 GB |
| 300 |
4096 MB |
100 GB |
| 500 |
8096 MB |
200 GB |
| 1000 |
12288 MB |
200 GB |
| 2000 |
16384 MB |
500 GB |
可以使用以下命令查看:
free -m
1.4最大打开文件限制
检查当前最大打开文件限制
ulimit -Sn
ulimit -Hn
如果小于10000,则需设置
ulimit -n 10000
1.5配置全限定域名FQDN
(1)配置集群每台服务器的hosts
vim /etc/hosts
#这两个不能删
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#第一列:IP,第二列:域名,第三列:主机名
192.168.100.151 hadoop01.com hadoop01
192.168.100.152 hadoop02.com hadoop02
192.168.100.153 hadoop03.com hadoop03
192.168.100.154 hadoop04.com hadoop04
192.168.100.155 hadoop05.com hadoop05
(2)设置每台服务器的hostname
hostname `hostname -f` #使用这个命令可以使用xshell等终端工具批量设置
1.6免密登录
(1)ambari server所在主机要和其它主机通信并安装ambari agent,所以需配置server到其它服务器的免密登录
ssh-keygen -t rsa #(四个回车)
#执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
cd ~/.ssh
(2)将server所在服务器的公钥拷贝到其它服务器
ssh-copy-id hadoop02
ssh-copy-id hadoop03
ssh-copy-id hadoop04
ssh-copy-id hadoop05
(3)分别ssh登录其它服务器
配置完ssh免密登录后,第一次需要输入密码,之后就可免密登录了
ssh hadoop02
ssh hadoop03
ssh hadoop04
ssh hadoop05
1.7各主机安装同步时钟
yum install -y ntp
systemctl enable ntpd
1.8各主机关闭防火墙
systemctl disable firewalld
service firewalld stop
1.9各主机关闭seLiinux和packageKit和umask值
(1)修改selinux值
vim /etc/selinux/config
#修改如下选项
SELINUX=disabled
(2)修改packageKit值(这个packageKit默认未启用;如果未启用可以不用处理)
vim /etc/yum/pluginconf.d/refresh-packagekit.conf
#修改如下选项
enabled=0
(3)umask修改
umask可以设置新文件和新文件夹的默认权限,Linux发行版将022设置为默认umask值。Umask值022授予新文件或文件夹755的读、写、执行权限。Umask值027授予新文件或文件夹750的读、写、执行权限。
Ambari、HDP和HDF支持umask值022(0022是功能等效的),027(0027是功能等效的)。必须在所有主机上设置这些值。
umask #查看当前umask值
umask 0022 #设置当前登录会话的umask
echo umask 0022 >> /etc/profile #永久更改所有交互式用户的umask
1.10各主机安装JDK并配置环境变量
(1)下载JDK:Java Downloads | Oracle
#上传到服务器
rz -be jdk-8u291-linux-x64.tar.gz
#解压
tar -zxvf jdk-8u291-linux-x64.tar.gz -C /usr/local
(2)配置环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_281
export PATH=.:$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
(3)使之生效
source /etc/profile
2.MySQL数据库安装
由于ambari和hive等组件都需要元数据存储到数据库中,故需要一个mysql数据库
(1) 下载并安装MySQL官方的 Yum Repository
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
(2)安装
yum -y install mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql-community-server
(3)MySQL启动
#首先启动MySQL
systemctl start mysqld.service
#查看状态
systemctl status mysqld.service
(4)设置密码
#初次登陆需要root用户的密码,通过如下命令可以在日志文件中找出密码:
grep "password" /var/log/mysqld.log
#设置密码验证策略(默认是1,即MEDIUM,所以刚开始设置的密码必须符合长度,且必须含有数字,小写或大写字母,特殊字符。)
set global validate_password_policy=0;
#修改密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'zstax2021';
#但此时还有一个问题,就是因为安装了Yum Repository,以后每次yum操作都会自动更新,需要把这个卸载掉:
yum -y remove mysql57-community-release-el7-10.noarch
(5)确认mysql-connector-java.jar
在ambari server所在机器执行如下命令,看是否存在
ls /usr/share/java/mysql-connector-java.jar
如果没有,则安装MySQL connector .jar file
yum install -y mysql-connector-java*
3.安装本地库(在ambari server主机上)
ambari各版本支持的HDP版本:Cloudera Support Matrix
如果您的企业集群有有限的出站Internet访问权限,则应该考虑使用本地存储库,这使您能够从更多的治理和更好的安装性能中获益。就算有网络也也建议使用本地库,要不然会很慢很久;更重要的是现在有付费墙的原因,不能免费下载了。
在设置本地存储库之前,必须满足某些要求:
-
选择运行受支持操作系统的现有服务器(群集中的服务器或群集可以访问的服务器);
-
启用了从群集中的所有主机到镜像服务器的网络访问;
-
确保镜像服务器安装了包管理器(如yum);
-
安装yum工具包
yum install yum-utils createrepo
3.1创建http服务器
-
在镜像服务器上,使用Apache社区网站提供的说明安装HTTP服务器(例如Apachehttpd)。
-
激活服务器
-
确保任何防火墙设置都允许从群集节点到镜像服务器的入站HTTP访问。
3.2创建 HTTP 服务
yum -y install httpd
/sbin/chkconfig httpd on
/sbin/service httpd start
在浏览器里访问安装 HTTP 服务的主机,查看是否成功。如: http://192.168.100.151:80
3.3上传安装包
Ambari2.7.5和HDP3.1.5二进制安装包下载地址:ambari2.7.5百度网盘下载地址.txt_ambari2.7.5-Hadoop工具类资源-CSDN下载
由于安装包过大(9G),使用rz命令只能上传4G以下的文件,这里使用pscp上传。
pscp使用方法:
a、下载putty软件,并可以在目录中,找到pscp.exe文件
b、pscp和scp功能相同,但pscp同时支持windows下使用,解决了windows系统向linux服务器传输文件,
而且它只有一个文件,即pscp.exe,建议将该文件放到C:\WINDOWS\system32下面, 这样就可以在任何地方调用该文件命令
pscp -P 22 .\HDP-3.1.5.0-centos7-rpm.tar.gz [email protected]:/softs/hdp-3.15
pscp -P 22 .\HDP-UTILS-1.1.0.22-centos7.tar.gz [email protected]:/softs/hdp-3.15
pscp -P 22 .\HDP-GPL-3.1.5.0-centos7-gpl.tar.gz [email protected]:/softs/hdp-3.15
pscp -P 22 .\ambari-2.7.5.0-centos7.tar.gz [email protected]:/softs/hdp-3.15
3.4解压安装
在镜像服务器上,为web服务器创建一个目录
mkdir -p /var/www/html/
# 解压:
cd /softs/hdp-3.15/
tar -zxvf ambari-2.7.5.0-centos7.tar.gz -C /var/www/html/
tar -zxvf HDP-3.1.5.0-centos7-rpm.tar.gz -C /var/www/html/
tar -zxvf HDP-GPL-3.1.5.0-centos7-gpl.tar.gz -C /var/www/html/
tar -zxvf HDP-UTILS-1.1.0.22-centos7.tar.gz -C /var/www/html/
3.5安装yum插件
在所有节点执行以下命令:
yum install yum-plugin-priorities -y
vim /etc/yum/pluginconf.d/priorities.conf
3.6配置本地yum源
(1)拷贝repo文件
cd /var/www/html
cp ambari/centos7/2.7.5.0-72/ambari.repo /etc/yum.repos.d/
cp HDP/centos7/3.1.5.0-152/ssl_hdp.repo /etc/yum.repos.d/hdp.repo
cp HDP-GPL/centos7/3.1.5.0-152/hdp.gpl.repo /etc/yum.repos.d/
(2)修改ambari的yum源配置
vim /etc/yum.repos.d/ambari.repo
#VERSION_NUMBER=2.7.5.0-72
[ambari-2.7.5.0]
#json.url = http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json
name=ambari Version - ambari-2.7.5.0
baseurl=http://hadoop01/ambari/centos7/2.7.5.0-72/
gpgcheck=1
gpgkey=http://hadoop01/ambari/centos7/2.7.5.0-72/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
(3)修改hdp的yum源配置
vim /etc/yum.repos.d/hdp.repo
#VERSION_NUMBER=3.1.5.0-152
[HDP-3.1.5.0]
name=HDP Version - HDP-3.1.5.0
baseurl=http://hadoop01/HDP/centos7/3.1.5.0-152/
gpgcheck=1
gpgkey=http://hadoop01/HDP/centos7/3.1.5.0-152/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
[HDP-UTILS-1.1.0.22]
name=HDP-UTILS Version - HDP-UTILS-1.1.0.22
baseurl=http://hadoop01/HDP-UTILS/centos7/1.1.0.22/
gpgcheck=1
gpgkey=http://hadoop01/HDP-UTILS/centos7/1.1.0.22/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
(4)修改hdp.gpl的yum源配置
vim /etc/yum.repos.d/hdp.gpl.repo
#VERSION_NUMBER=3.1.5.0-152
[HDP-GPL-3.1.5.0]
name=HDP-GPL Version - HDP-GPL-3.1.5.0
baseurl=http://hadoop01/HDP-GPL/centos7/3.1.5.0-152/
gpgcheck=1
gpgkey=http://hadoop01/HDP-GPL/centos7/3.1.5.0-152/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
4.安装ambari(在ambari server主机上)
4.1安装ambari
yum -y install ambari-server
4.2新建ambari数据库
create database ambari default character set='utf8';
CREATE USER 'ambari'@'localhost' IDENTIFIED BY 'zstax2021';
CREATE USER 'ambari'@'hadoop01' IDENTIFIED BY 'zstax2021';
CREATE USER 'ambari'@'%' IDENTIFIED BY 'zstax2021';
GRANT ALL PRIVILEGES ON ambari.* TO 'ambari'@'localhost' IDENTIFIED BY 'zstax2021' with grant option;
GRANT ALL PRIVILEGES ON ambari.* TO 'ambari'@'hadoop01' IDENTIFIED BY 'zstax2021' with grant option;
GRANT ALL PRIVILEGES ON ambari.* TO 'ambari'@'%' IDENTIFIED BY 'zstax2021' with grant option;
FLUSH PRIVILEGES;
#如果添加错误,删除的话用如下命令
drop user 'ambari'@'localhost';
#可用如下命令查看hive用户的权限信息
SELECT * FROM mysql.`user` WHERE `User`='ambari'
4.3导入元数据
use ambari;
source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
4.4安装
[root@hadoop01 ~]# ambari-server setup
Using python /usr/bin/python
Setup ambari-server
Checking SELinux...
SELinux status is 'enabled'
SELinux mode is 'permissive'
WARNING: SELinux is set to 'permissive' mode and temporarily disabled.
OK to continue [y/n] (y)? y
Customize user account for ambari-server daemon [y/n] (n)? y
Enter user account for ambari-server daemon (root):ambari
Adjusting ambari-server permissions and ownership...
Checking firewall status...
Checking JDK...
[1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8
[2] Custom JDK
==============================================================================
Enter choice (1): 2
WARNING: JDK must be installed on all hosts and JAVA_HOME must be valid on all hosts.
WARNING: JCE Policy files are required for configuring Kerberos security. If you plan to use Kerberos,please make sure JCE Unlimited Strength Jurisdiction Policy Files are valid on all hosts.
Path to JAVA_HOME: /usr/local/jdk1.8.0_281
Validating JDK on Ambari Server...done.
Check JDK version for Ambari Server...
JDK version found: 8
Minimum JDK version is 8 for Ambari. Skipping to setup different JDK for Ambari Server.
Checking GPL software agreement...
GPL License for LZO: https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
Enable Ambari Server to download and install GPL Licensed LZO packages [y/n] (n)? y
Completing setup...
Configuring database...
Enter advanced database configuration [y/n] (n)? y
Configuring database...
==============================================================================
Choose one of the following options:
[1] - PostgreSQL (Embedded)
[2] - Oracle
[3] - MySQL / MariaDB
[4] - PostgreSQL
[5] - Microsoft SQL Server (Tech Preview)
[6] - SQL Anywhere
[7] - BDB
==============================================================================
Enter choice (1): 3
Hostname (localhost):
Port (3306):
Database name (ambari):
Username (ambari):
Enter Database Password (bigdata):
Re-enter password:
Configuring ambari database...
Should ambari use existing default jdbc /usr/share/java/mysql-connector-java.jar [y/n] (y)? y
Configuring remote database connection properties...
WARNING: Before starting Ambari Server, you must run the following DDL directly from the database shell to create the schema: /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
Proceed with configuring remote database connection properties [y/n] (y)? y
Extracting system views...
ambari-admin-2.7.5.0.72.jar
....
Ambari repo file contains latest json url http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json, updating stacks repoinfos with it...
Adjusting ambari-server permissions and ownership...
Ambari Server 'setup' completed successfully.
(1) 如果没有设置 SELinux=disable,会有一个警告信息,按回车,接受默认值(y)。
(2)设置运行 ambari server 的用户,默认会使用 root。可以键入 y,回车后输入一个其它的用户,注:这里建议新建一个用户,否则后面启动ambari的时候会报:REASON: Unable to detect a system user for Ambari Server.
(3)选择 JDK。为了使用统一的 JDK,这里选择自定义的 JDK。然后会要求输入 JAVA_HOME 的路径
(4)GPL License , 这一步必须选择 y.
(5)配置元数据库的连接信息
(6)输入数据库驱动的 jar 包的路径,前面已经安装过
(7)进行远程数据库连接信息配置。选择 y
4.5启动ambari
#启动
ambari-server start
#查看状态
#ambari-server status
#停止
ambari-server stop
注:在初次启动时,如果报错可查看具体日志信息:
more /var/log/ambari-server/ambari-server.log
启动成功后,访问:http://hadoop01:8080(我已经将集群服务器加入到Windows的hosts,所以可使用主机名访问),默认用户名/密码是 : admin/admin
5.使用ambari搭建集群
5.1为集群起名字
登录成功后,点击 “LAUNCH INSTALL WIZARD”,开始创建一个集群,并为集群取一个名字

5.2选择版本和安装库

之前配置的Apache服务器此时派上用场了
http://hadoop01/HDP/centos7/3.1.5.0-152/
http://hadoop01/HDP-GPL/centos7/3.1.5.0-152/
http://hadoop01/HDP-UTILS/centos7/1.1.0.22/
5.3安装选项

(1)这一步的“Target Hosts”为每台主机的域名,在之前配置/etc/hosts的步骤里提到过。
(2)SSH Private Key 里选择的文件是ambari主机那台机器的 id_rsa 这个文件
5.4选择服务
根据需要,选择服务。如果某些服务依赖其它服务,而没有选择依赖的服务的话,点击“Next”时,会做相应的提示。
5.5分配主服务
“Assign Masters” ambari 会自动分配各种服务到不同的机器上,也可手动进行调整。

5.6分配从服务和客户端
在这一步,建议datanode和nodemanager设置三个以上,其它的可酌情修改。
5.7认证

设置各组件的认证密码,建议都设置为一样的,方便管理和记忆。
5.8配置hive数据库

注意:配置hive的元数据库时链接上强烈建议加上utf8字符限制,如:
jdbc:mysql://hadoop01.com/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8
在这一步要先建立hive数据库和账号
create database hive default character set='utf8';
use hive;
CREATE USER 'hive'@'localhost' IDENTIFIED BY 'zstax2021';
GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'localhost' IDENTIFIED BY 'zstax2021' with grant option;
CREATE USER 'hive'@'%' IDENTIFIED BY 'zstax2021';
GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'%' IDENTIFIED BY 'zstax2021' with grant option;
FLUSH PRIVILEGES;
然后需要执行以下语句,否则会报红框里的警告,并且 “TEST CONNECTION”会失败。
ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java.jar
5.9kafka配置

(1)点击“listeners”最右侧的加号,在弹出的框里填写kafka配置组的名称,然后点击 “OK”.
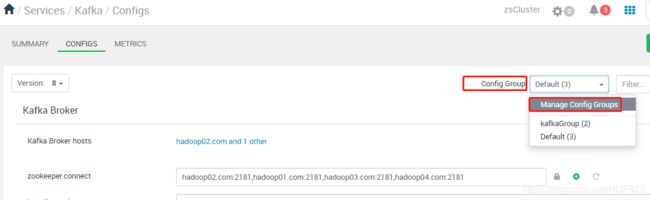
(2)在右上角的“config Group”中点击“Manage Config Groups”,在弹出的框中选中刚刚新增的配置组名称,再点击右下角的加号,选择之前我们在5.5中安装的kafka broker的主机,并点击“SAVE”即可。

测试kafka命令:
#创建主题:
bin/kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 2 --partitions 3 --topic test
#查看所有主题列表:
bin/kafka-topics.sh --list --zookeeper hadoop01:2181
#模拟生产者:
bin/kafka-console-producer.sh --broker-list hadoop02:6667,hadoop03:6667 --topic test
#模拟消费者:
bin/kafka-console-consumer.sh --from-beginning --topic test --bootstrap-server hadoop02:6667,hadoop03:6667
#查看主题详细信息:
bin/kafka-topics.sh --describe --zookeeper hadoop01:2181 --topic test
5.10配置HA
ambari默认安装好的集群是没有开启HA,要开启HA需要做以下两步:
1)HDFS-> actions->enable namenode HA
2)YARN-> actions->enable resourcemanager HA
根据提示一步步操作即可。
至此,集群搭建完毕,实属不易!!!
问题总结
1、Timeline Service V2.0 Reader 启动不了?
解决办法:Yarn->Configs->advanced->Advanced yarn-hbase-env -> is_hbase_system_service_launch和use_external_hbase勾选
2、Invalid smartsense ID unspecified. Please configure a vaid SmartSense ID to proceed
解决方案: HORTONWORKS的一款增值服务产品,需要付费订阅后方可获得并使用.因此可关闭/卸载/删除
3、 启动spark-shell报错:Required executor memory (1024+384 MB) is above the max threshold (510 MB) of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'.
解决方案:修改yarn下yarn-site.xml文件对应yarn.scheduler.maximum-allocation-mb和yarn.nodemanager.resource.memory-mb的值为2G。可在ambari界面上搜索修改,但貌似改了不生效,必要时可修改服务器上的配置文件,ambari所有组件安装目录为: /usr/hdp/ ;日志文件一般在:/var/log/
4、如果要安装spark2的 SPARK2 THRIFT SERVER,yarn的node manager至少要两台以上,否则spark的thriftServer启动不了
5、启动spark-shell报错:
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).. does not exist or is not a directory
这个问题快把我整疯了,搞了两天,查不出任何原因,最后发现必须在spark2-client目录下启动./bin/spark-shell才行,直接在命令行下调用全局的spark-shell命令就会报这个错误,真的是坑啊!