MySQL常用操作(一)
创建表
create table user(
id int unsigned primary key not null auto_increment,
name varchar(50) unique not null,
age tinyint not null,
sex enum('M', 'W') not null
)engine=INNODB default charset=utf8;
# 查看创建表语句
show create table user
两种插入方式比较
# 方式1
insert into user(name, age, sex) values('zhangsan', 21, 'M');
insert into user(name, age, sex) values('lisi', 22, 'M');
insert into user(name, age, sex) values('xiaohong', 21, 'W');
insert into user(name, age, sex) values('wangwu', 22, 'M');
insert into user(name, age, sex) values('zhaoliu', 23, 'M');
# 方式2
insert into user(name, age, sex) values('zhangsan', 21, 'M'),('lisi', 22, 'M'),('xiaohong', 21, 'W'),('wangwu', 22, 'M'),('zhaoliu', 23, 'M');
方式1五次insert就要5次的TCP握手和挥手,而方式2只要一次TCP握手和挥手
例子:union合并查询
SELECT expression1, expression2, ... expression_n
FROM tables[WHERE conditions]
UNION [ALL | DISTINCT] # 注意:union默认去重,不用修饰distinct,all表示显示所有重复值
SELECT expression1, expression2, ... expression_n
FROM tables[WHERE conditions];
如:
select name,age,sex from user where age >= 22 union all select name,age,sex from user where sex='M';
注:or 也可用到索引
limit分页查询
从第1行开始(第0行是起始行),查找出3行数据:
select * from user limit 1, 3;
explain可以查看SQL语句的执行计划:
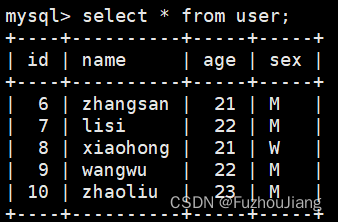
首先表内容为:
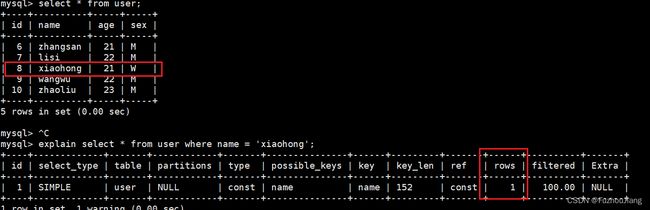
查看执行计划:
explain select * from user where age = 20;

可以看出来age这一列没有建立索引,需要逐行查找。
而对于name列有建立索引,虽然记录不在第一行但是只需要查找一次:
例子:使用存储过程往表中插入大量记录
这个例子可以用于进行一些测试工作中提前需要有大量记录的表
# 将结束符设置为 $
delimiter $
create Procedure add_t_user(IN n INT)
BEGIN
DECLARE i INT;
SET i=0;
WHILE ilimit能够优化查询效率
limit在没有索引的时候查找到指定的记录就停止,如果不加limit就要全表扫描。
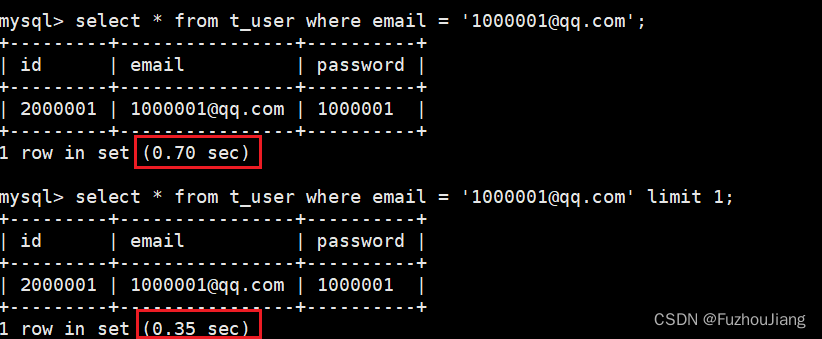
例子:
设每页行数pagenum=20, pageno为页号,显示某一页的数据:
select * from user limit (pageno-1)*pagenum, pageno * pagenum
但是这个select效率太低,偏移量( (pageno-1)*pagenum )大的时候需要花时间,可以通过使用:
select * from user where id>上一页最后一条数据的id值 limit 20;
这条语句能够利用id索引省去偏移的时间开销。
order by排序
发现order by查询的Extra列是 Using filesort 说明使用到了归并排序(外排序)可以性能优化,如加索引或者修改查询列