Java中ExecutorService线程池的使用(Runnable和Callable多线程实现)
场景
线程的创建和释放,需要占用不小的内存和资源。如果每次需要使用线程时,都new 一个Thread的话,难免会造成资源的浪费,
而且可以无限制创建,之间相互竞争,会导致过多占用系统资源导致系统瘫痪。
不利于扩展,比如如定时执行、定期执行、线程中断,所以很有必要了解下ExecutorService的使用。
ExecutorService是Java提供的线程池,也就是说,每次我们需要使用线程的时候,可以通过ExecutorService获得线程。
它可以有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞,
同时提供定时执行、定期执行、单线程、并发数控制等功能,也不用使用TimerTask了。
线程池的目的是降低系统的开销,因为在高并发的场景下频繁的创建和销毁线程会降低程序的性能,有了线程池,线程就可以
实现复用,这样就可以减少线程的创建和销毁。
API文档
ExecutorService (Java Platform SE 8 )

注:
博客:
霸道流氓气质的博客_CSDN博客-C#,架构之路,SpringBoot领域博主
关注公众号
霸道的程序猿
获取编程相关电子书、教程推送与免费下载。
实现
1、ExecutorService的创建方式
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) 参数说明
corePoolSize : 核心线程数,一旦创建将不会再释放。如果创建的线程数还没有达到指定的核心线程数量,将会继续创建新的核心线程,直到达到最大核心线程数后,核心线程数将不在增加;如果没有空闲的核心线程,同时又未达到最大线程数,则将继续创建非核心线程;如果核心线程数等于最大线程数,则当核心线程都处于激活状态时,任务将被挂起,等待空闲线程来执行。
maximumPoolSize : 最大线程数,允许创建的最大线程数量。如果最大线程数等于核心线程数,则无法创建非核心线程;如果非核心线程处于空闲时,超过设置的空闲时间,则将被回收,释放占用的资源。
keepAliveTime : 也就是当线程空闲时,所允许保存的最大时间,超过这个时间,线程将被释放销毁,但只针对于非核心线程。
unit : 时间单位,TimeUnit.SECONDS等。
workQueue : 任务队列,存储暂时无法执行的任务,等待空闲线程来执行任务。
threadFactory : 线程工程,用于创建线程。
handler : 当线程边界和队列容量已经达到最大时,用于处理阻塞时的程序
线程池有多种类型,一般常用的是固定线程数线程池newFixedThreadPool,创建方式:
ExecutorService executorService = Executors.newFixedThreadPool(5);
这里配置线程数为5。具体数量根据自己的业务需求配置。
2、线程池的使用步骤
在上面创建线程池之后,需要新建任务执行类并实现Runable接口和重写run方法
class PrintTask implements Runnable{
@Override
public void run() {
String threadName = Thread.currentThread().getName();
System.out.println("线程名:"+threadName+" 开始时间:"+ DateUtils.getTime());
System.out.println("系统需要业务操作3秒");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程名:"+threadName+" 结束时间:"+ DateUtils.getTime());
}
}这里模拟一个任务需要3秒的处理时间。
然后需要调用executorService的submit方法提交任务
ExecutorService executorService = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
executorService.submit(new PrintTask());
}完整示例代码
package com.ruoyi.demo.Executor;
import com.ruoyi.common.utils.DateUtils;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ExecutorDemo {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
executorService.submit(new PrintTask());
}
}
}
class PrintTask implements Runnable{
@Override
public void run() {
String threadName = Thread.currentThread().getName();
System.out.println("线程名:"+threadName+" 开始时间:"+ DateUtils.getTime());
System.out.println("系统需要业务操作3秒");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程名:"+threadName+" 结束时间:"+ DateUtils.getTime());
}
}3、效果演示
上面循环10次,每次模拟处理业务设定为3秒,设置线程数为5个,所以会需要两组3秒执行完毕。
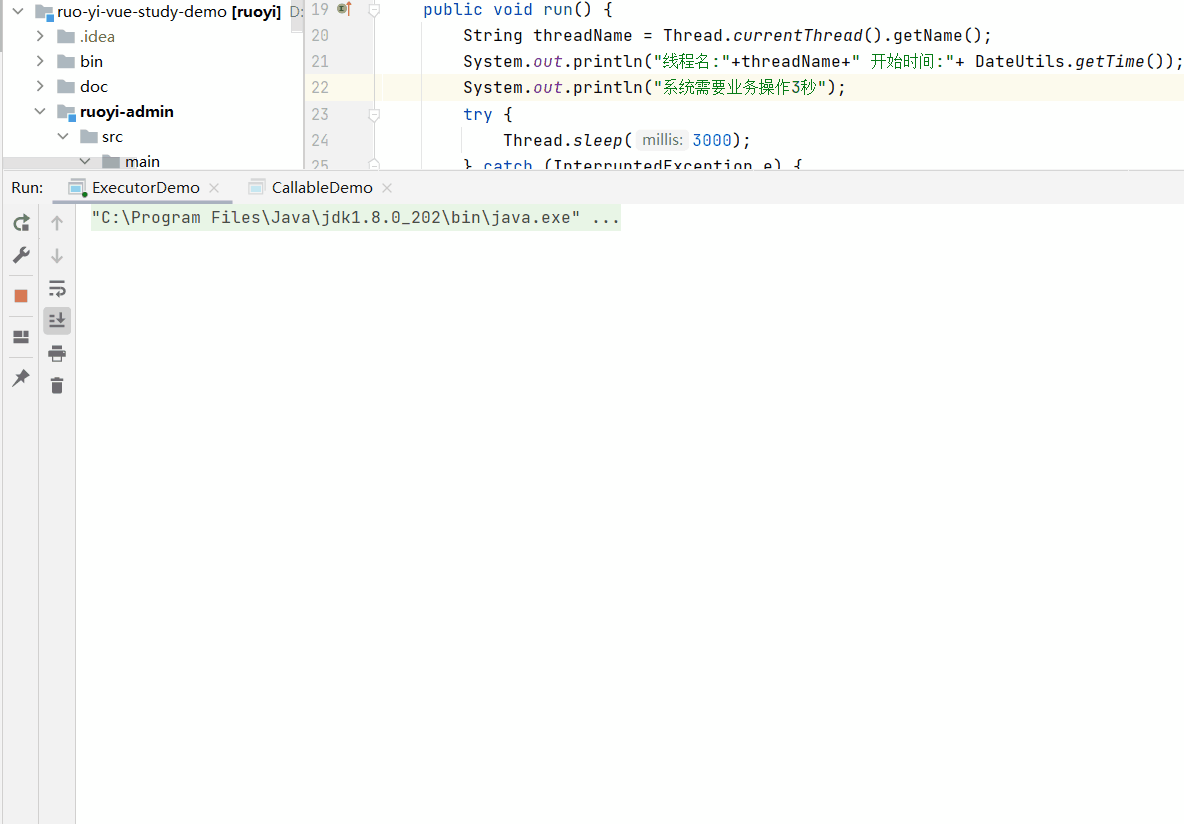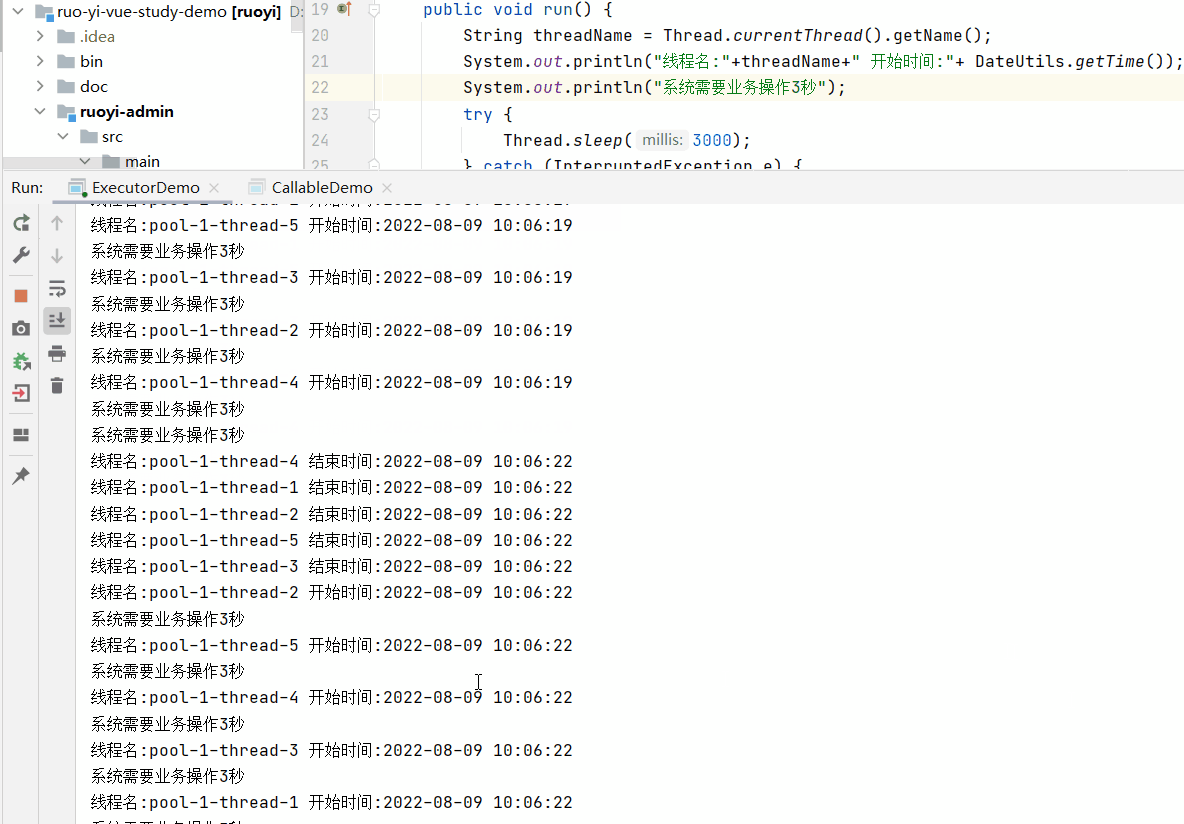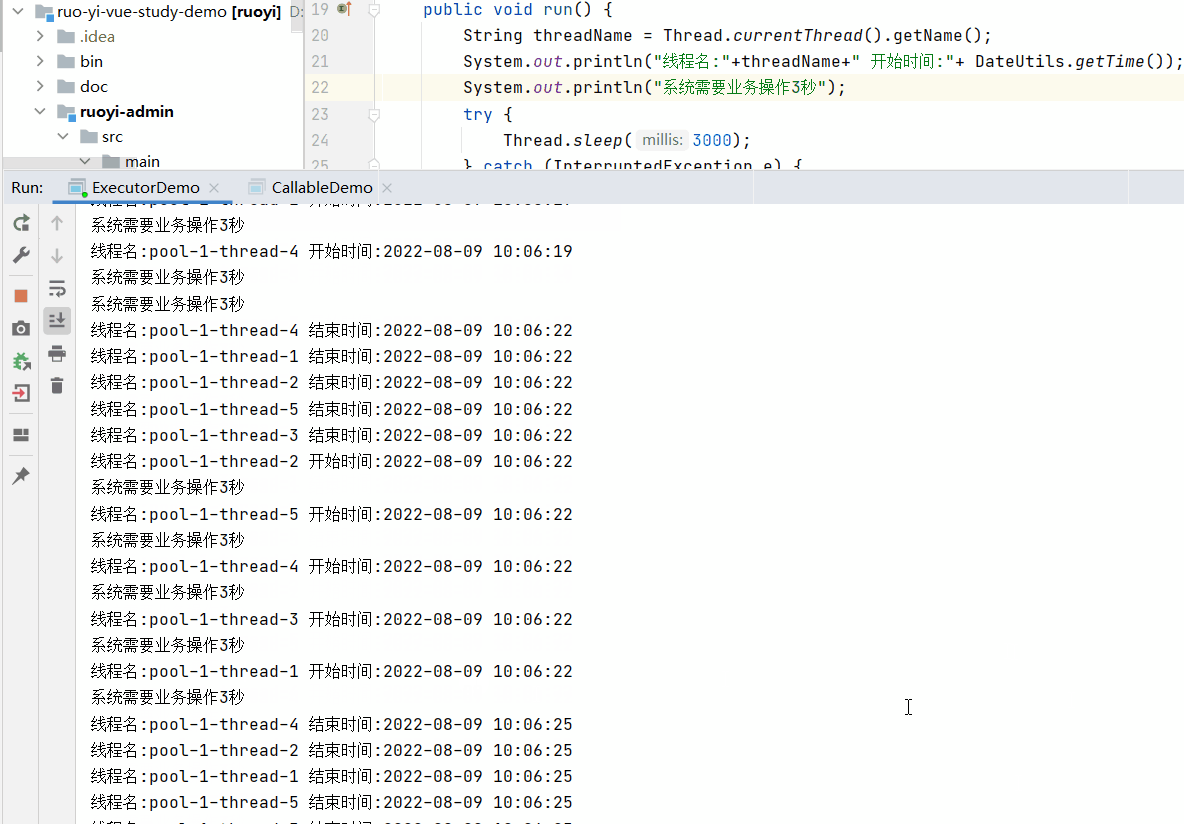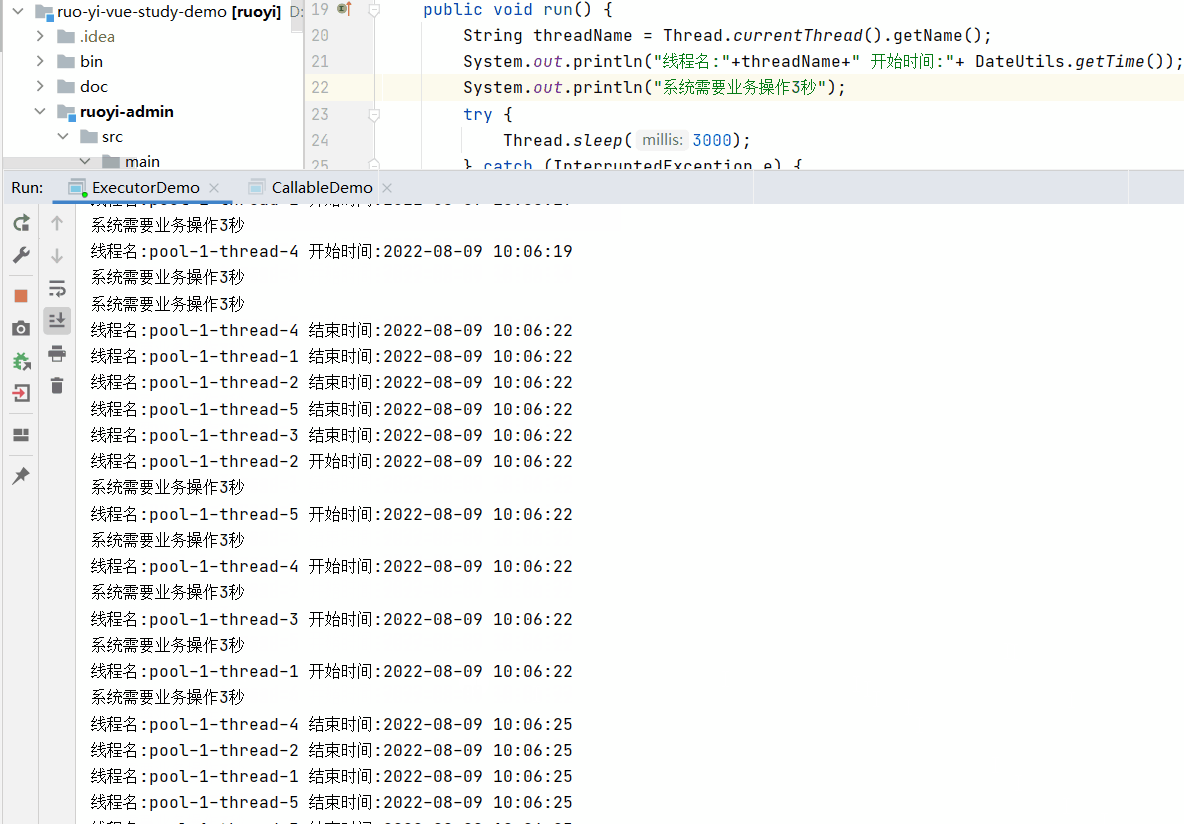
如果将循环改为5次,线程数还是5个,则只需要一组3秒即可完成

4、线程池的关闭
线程池的关闭通过调用shutdown方法
executorService.shutdown();但是实际场景下一般不进行关闭,关闭之后就无法再进行使用。
但是上面演示效果中如果不关闭线程池,则main方法一直运行中,因为main线程会等到所有的业务线程执行完毕之后才会销毁。
但是调用了关闭之后,main方法才会执行完毕。
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(5);
for (int i = 0; i < 5; i++) {
executorService.submit(new PrintTask());
}
executorService.shutdown();
}
5、如果需要每个任务执行之后需要返回一个结果,可以实现Callable接口并重写call方法
这种应用场景比如批量进行图片上传时,开启多个线程分别进行上传,然后将每个线程上传之后的图片路径返回,批量存储。
class CustomTask implements Callable {
@Override
public String call() throws Exception {
String threadName = Thread.currentThread().getName();
System.out.println("线程名:" + threadName + " 开始时间:" + DateUtils.getTime());
System.out.println("系统需要业务操作1秒");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "threadName = "+threadName +" 结束时间:"+DateUtils.getTime();
}
} 其中Callable
怎么获取返回值。
submit会返回Future<>对象,将每个线程的返回的对象存储到list中,等循环结束之后调用list
的每个Future的get方法。
ExecutorService executorService = Executors.newFixedThreadPool(5);
ArrayList> resultList = new ArrayList<>();
for (int i = 0; i < 5; i++) {
Future submit = executorService.submit(new CustomTask());
resultList.add(submit);
}
resultList.forEach(result -> {
try {
System.out.println(result.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
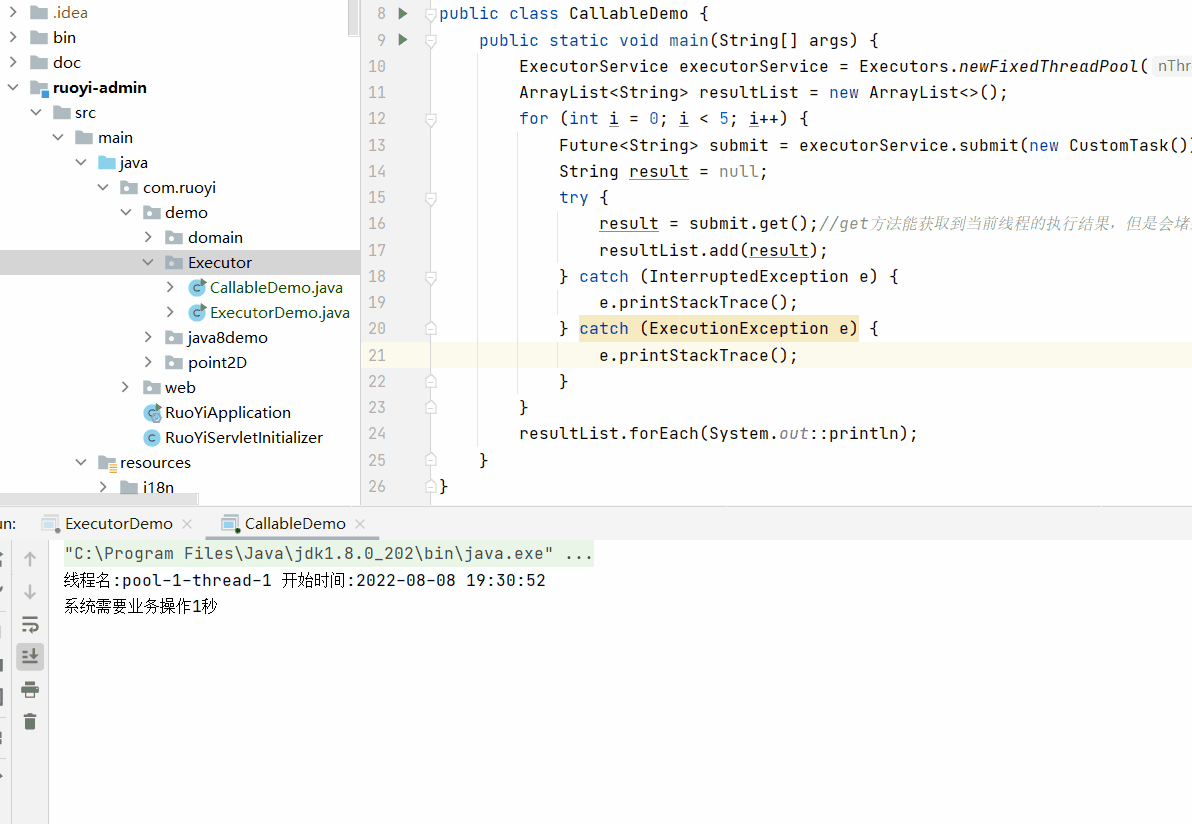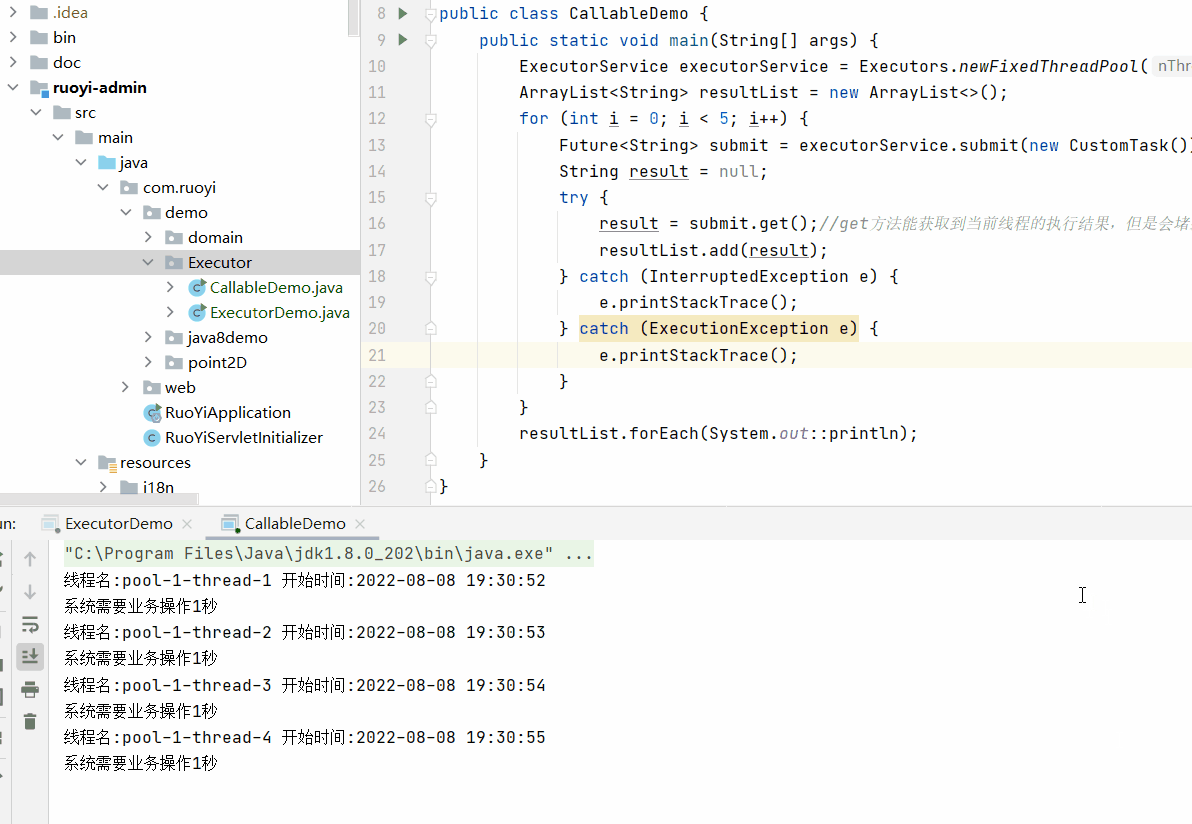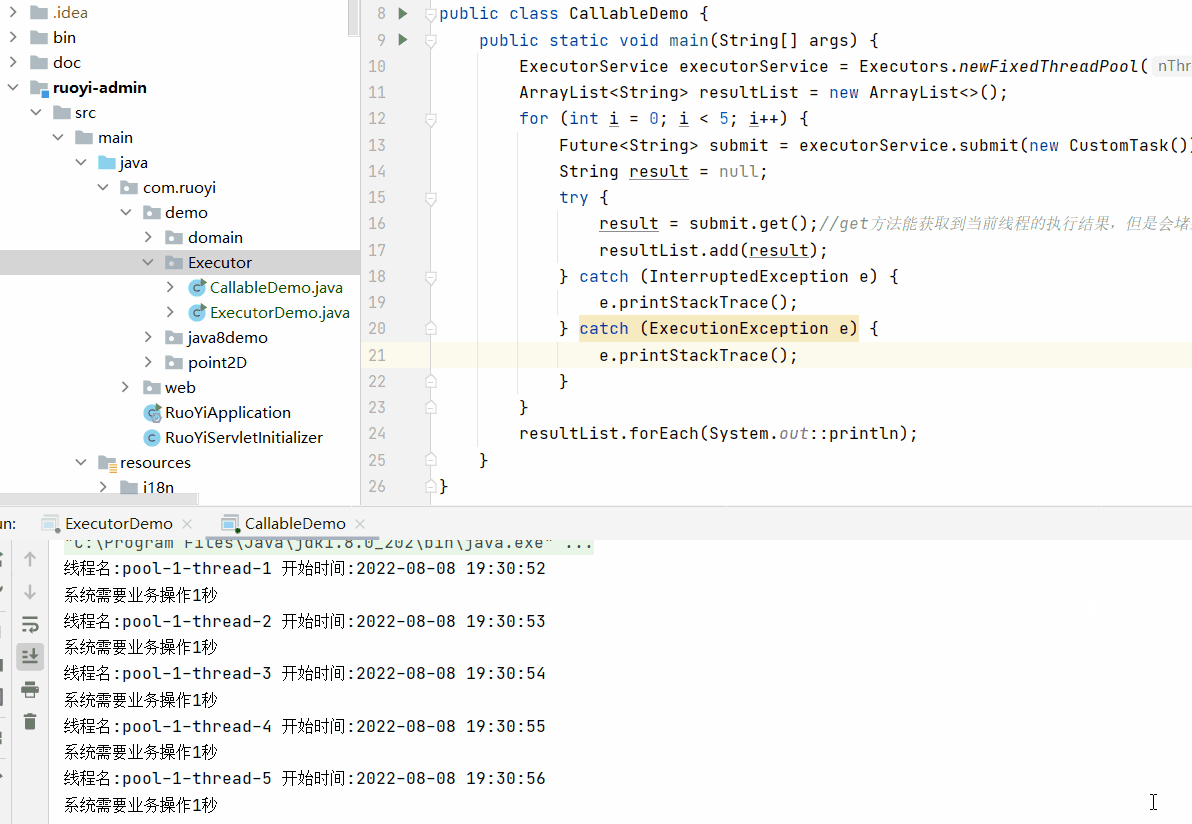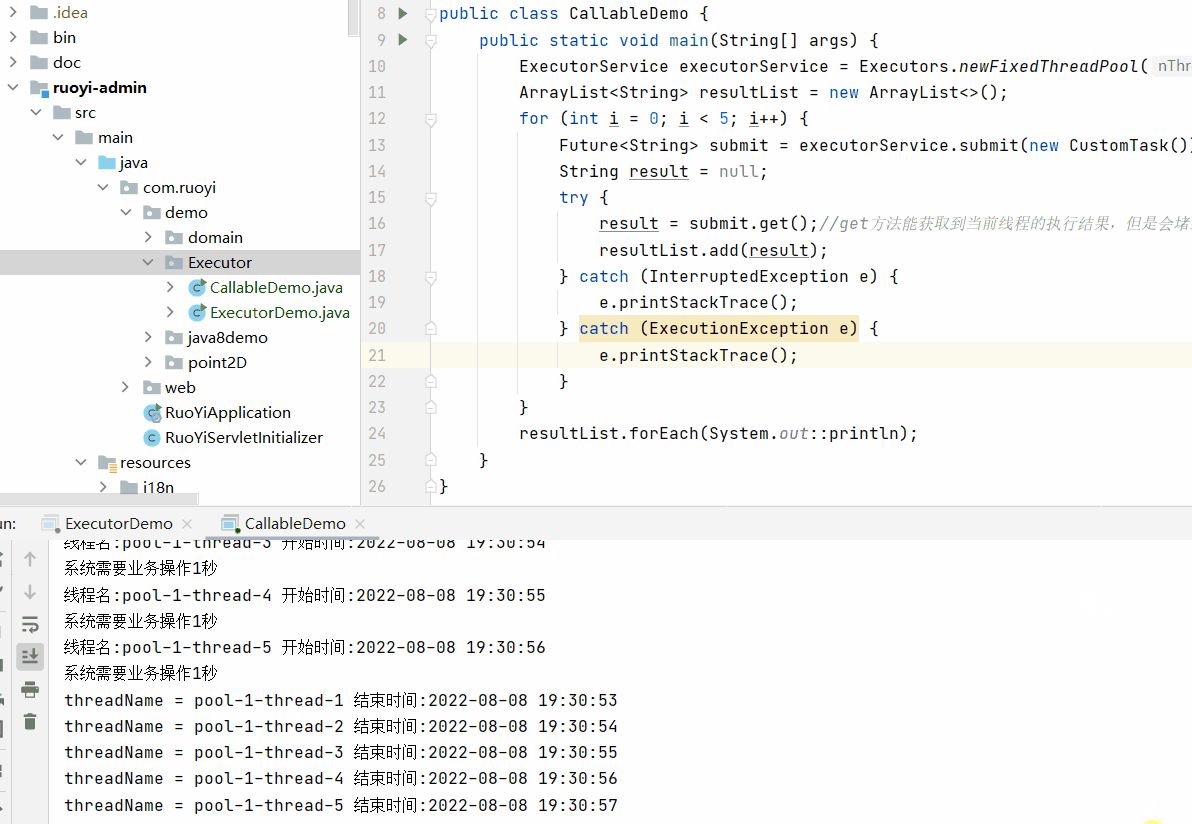
}); 这里为什么强调需要在循环结束之后再调用每个Future的get方法。
因为get方法会堵塞当前线程,所以如果再循环内调用get方法,那么每次循环会等到返回结果之后再继续进行,
那就达不到多线程的效果。
上面的执行效果为

但是如果在循环中调用get方法,以下为错误示例代码
// ArrayList resultList = new ArrayList<>();
// for (int i = 0; i < 5; i++) {
// Future submit = executorService.submit(new CustomTask());
// String result = null;
// try {
// result = submit.get();//get方法能获取到当前线程的执行结果,但是会堵塞当前线程
// resultList.add(result);
// } catch (InterruptedException e) {
// e.printStackTrace();
// } catch (ExecutionException e) {
// e.printStackTrace();
// }
// } 则会导致线程堵塞