作者:段忠杰(终劫)、刘冰雁(伍拾)、汪诚愚(熊兮)、黄俊(临在)
背景
以Stable Diffusion模型为代表,AI生成内容(AI Generated Content,AIGC)的模型和应用呈现出井喷式的增长趋势。在先前的工作中,阿里云机器学习PAI团队开源了PAI-Diffusion系列模型(看这里),包括一系列通用场景和特定场景的文图生成模型,例如古诗配图、二次元动漫、魔幻现实等。这些模型的Pipeline除了包括标准的Diffusion Model,还集成了PAI团队先前提出的中文CLIP跨模态对齐模型(看这里)使得模型可以生成符合中文文本描述的、各种场景下的高清大图。此外,由于Diffusion模型推理速度比较慢,而且需要耗费较多的硬件资源,我们结合由PAI自主研发的编译优化工具 PAI-Blade,支持对PAI-Diffusion模型的端到端的导出和推理加速,在A10机器下做到了1s内的中文大图生成(看这里)。在本次的工作中,我们对之前的PAI-Diffusion中文模型进行大幅升级,主要的功能扩展包括:
- 图像生成质量的大幅提升、风格多样化:通过大量对模型预训练数据的处理和过滤,以及训练过程的优化,PAI-Diffusion中文模型生成的图像无论在质量上,还是在风格上都大幅超越先前版本;
- 丰富的精细化模型微调功能:除了对模型的标准微调,PAI-Diffusion中文模型支持开源社区的各种微调功能,包括LoRA、Textual Inversion、DreamBooth、ControlNet等,支持各类图像生成和编辑的功能;
- 简单易用的场景化定制方案:除了训练各种通用场景下的中文模型,我们也在垂类场景下做了很多尝试和探索,通过场景化的定制,可以在各种产品中使用这些模型,包括Diffuser API、WebUI等。
在下文中,我们详细介绍PAI-Diffusion中文模型的新功能和新特性。
艺术画廊
在详细介绍PAI-Diffusion中文模型及其功能前,我们首先带大家参观我们的艺术画廊,下面的所有图片都采用PAI-Diffusion中文模型真实生成。
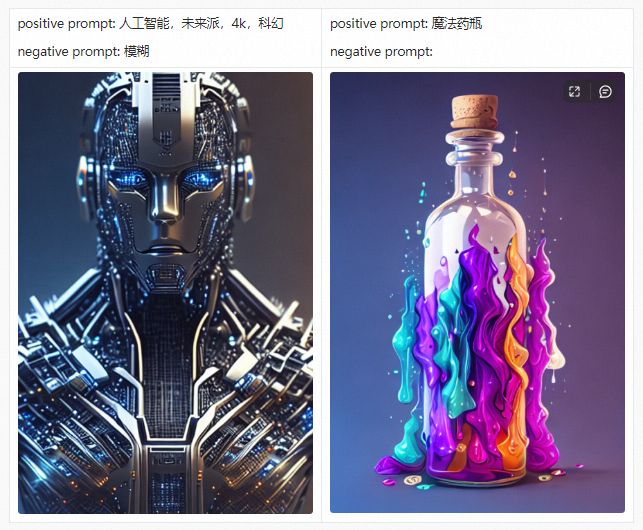

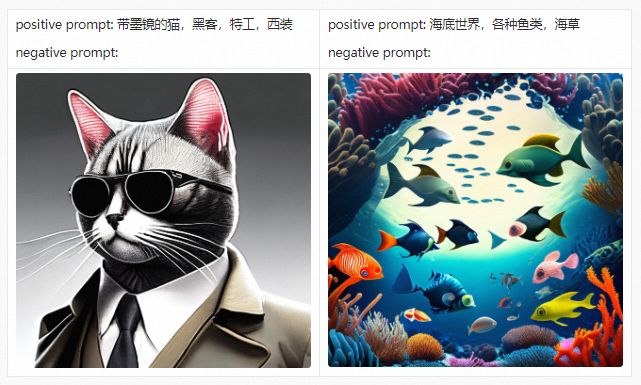
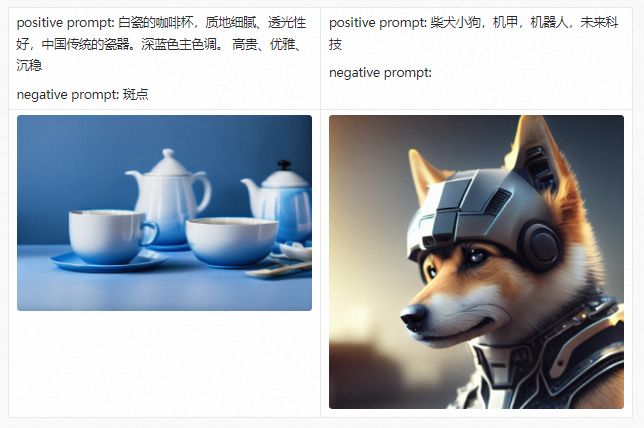
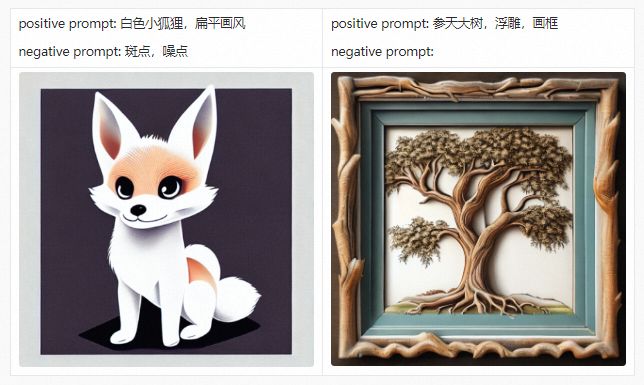

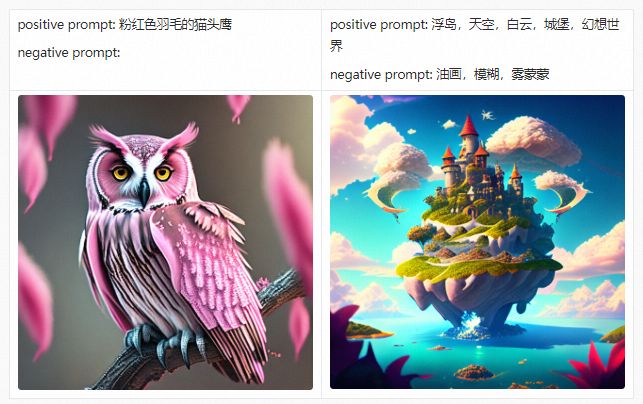
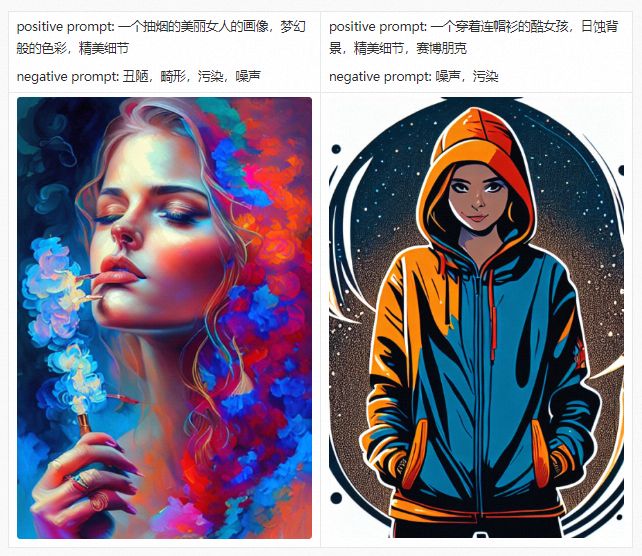

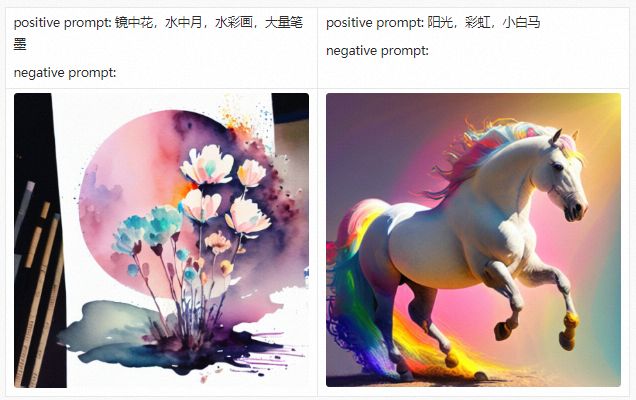
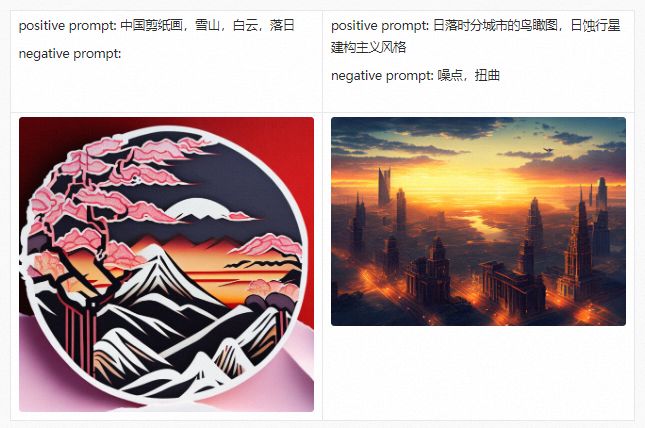






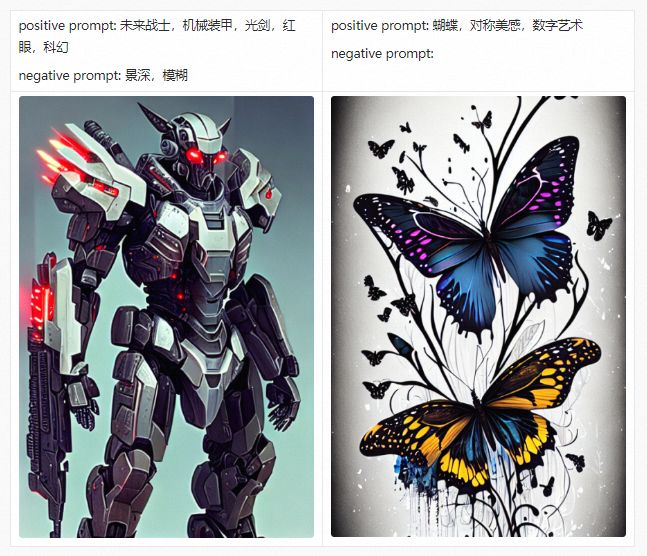
PAI-Diffusion ModelZoo
我们利用海量中文图文对数据,训练了多个Diffusion中文模型,参数量均在10亿左右。本次我们开源了如下两个模型。概述如下所示:
| 模型名 | 使用场景 |
|---|---|
| pai-diffusion-artist-large-zh | 中文文图生成艺术模型,默认支持生成图像分辨率为512*512 |
| pai-diffusion-artist-xlarge-zh | 中文文图生成艺术模型(更大分辨率),默认支持生成图像分辨率为768*768 |
为了提升模型输出图像的质量,在最大限度内避免出现不合规或低质量内容,我们搜集海量开源的图文对数据集,包括大规模中文跨模态预训练数据集WuKong、大规模多语言多模态数据集LAION-5B等。我们针对图像和文本进行了多种清洗方式,筛选掉违规和低质量数据。具体的数据处理方式包括NSFW(Not Safe From Work)数据过滤、水印数据去除,以及使用CLIP分数和美观值分数评分,选出最合适的预训练数据子集进行训练。与英文开源社区的Diffusion模型不同,我们的CLIP Text Encoder采用EasyNLP自研的中文CLIP模型(https://github.com/alibaba/EasyNLP),并且在Diffusion训练过程中冻结其参数,使得模型对中文语义的建模更加精确。值得注意的是,上表的图像分辨率指训练过程中的图像分辨率,在模型推理阶段可以设置不同的分辨率。
PAI-Diffusion模型特性
为了更加便于广大用户使用PAI-Diffusion模型,我们从如下几个方面详细介绍PAI-Diffusion模型的特性。
丰富多样的模型微调方法
PAI-Diffusion模型和社区Stable Diffusion等模型的参数量一般在十亿左右。这些模型的全量参数微调往往需要消耗大量计算资源。除了标准的模型微调,PAI-Diffusion模型支持多种轻量化微调算法,支持用户在计算量尽可能少的情况下,实现模型的特定领域、特定场景的微调。以下,我们也给出两个轻量化微调的示例。
使用LoRA进行模型轻量化微调
PAI-Diffusion模型可以使用LoRA(Low-Rank Adaptation)算法进行轻量化微调,大幅降低计算量。调用开源脚本train_text_to_image_lora.py,我们同样可以实现PAI-Diffusion中文模型的轻量化微调。训练命令示例如下:
export MODEL_NAME="model_name"
export TRAIN_DIR="path_to_your_dataset"
export OUTPUT_DIR="path_to_save_model"
accelerate launch train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-04 \
--max_grad_norm=1 \
--lr_scheduler="cosine" --lr_warmup_steps=0 \
--output_dir=$OUTPUT_DIR其中,MODEL_NAME是用于微调的PAI-Diffusion模型名称或路径,TRAIN_DIR是训练集的本地路径,OUTPUT_DIR为模型保存的本地路径(只包含LoRA微调参数部分)。当模型LoRA轻量化微调完毕之后可以使用如下示例代码进行文图生成:
from diffusers import StableDiffusionPipeline
model_id = "model_name"
lora_path = "model_path/checkpoint-xxx/pytorch_model.bin"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
pipe.unet.load_attn_procs(torch.load(lora_path))
pipe.to("cuda")
image = pipe("input text").images[0]
image.save("result.png")其中,model_path即为微调后的模型保存的本地路径(只包含LoRA微调参数部分),即前一步骤的OUTPUT_DIR;model_id为原始的没有经过LoRA微调的模型。
使用Textual Inversion进行模型定制化轻量微调
由于PAI-Diffusion模型一般用于生成各种通用场景下的图像,Textual Inversion是一种定制化轻量微调技术,使模型生成原来模型没有学会的、新的概念相关图像。PAI-Diffusion模型可以使用Textual Inversion算法进行轻量化微调。同样地,我们可以运行脚本textual_inversion.py,训练命令示例如下:
export MODEL_NAME="model_name"
export TRAIN_DIR="path_to_your_dataset"
export OUTPUT_DIR="path_to_save_model"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--learnable_property="object" \
--placeholder_token="<小奶猫>" --initializer_token="猫" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=100 \
--learning_rate=5.0e-04 --scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--output_dir=$OUTPUT_DIR其中,MODEL_NAME是用于微调的PAI-Diffusion模型名称,TRAIN_DIR是前述训练集的本地路径,OUTPUT_DIR为模型保存的本地路径。其中placeholder_token是与新的概念相关的文本,initializer_token是与新的概念密切相关的字(用于初始化新的概念对应的参数),这里我们以小奶猫为例。当模型轻量化微调完毕之后可以使用如下示例代码进行文图生成:
from diffusers import StableDiffusionPipeline
model_path = "path_to_save_model"
pipe = StableDiffusionPipeline.from_pretrained(model_path).to("cuda")
image = pipe("input text").images[0]
image.save("result.png")其中,model_path即为微调后的模型保存的本地路径,即前一步骤的OUTPUT_DIR。注意在使用微调后的模型生成包含新的概念的图像时,文本中新的概念用步骤二中的placeholder_token表示,例如:

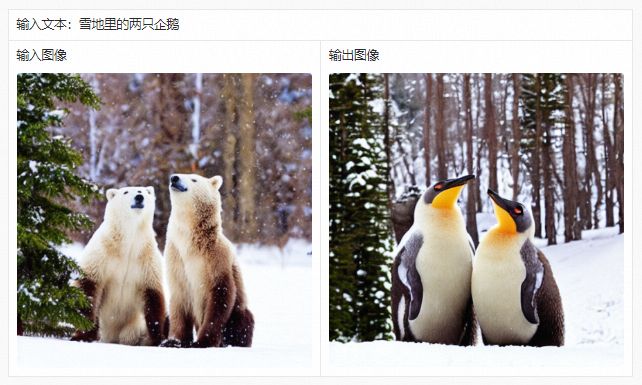
AIGC系列模型的潜在风险在于容易生成不可控的、带有违法信息的内容,影响了这些模型在下游业务场景中的应用。PAI-Diffusion中文模型支持多种可控的图像编辑功能,允许用户对生成的图像内容作出限制,从而使得结果更加可用。PAI-Diffusion中文模型对StableDiffusionImg2ImgPipeline做到完全兼容,这一文本引导的图像编辑Pipeline允许模型在给定输入文本和图像的基础上,生成相关的图像,示例脚本如下:
from diffusers import StableDiffusionImg2ImgPipeline
pipe = StableDiffusionImg2ImgPipeline.from_pretrained("model_name").to("cuda")
image = pipe(prompt="input text", image=init_image, strength=0.75, guidance_scale=7.5).images[0]
image.save("result.png")以下给出一个输入输出的示例:
场景定制化的功能支持
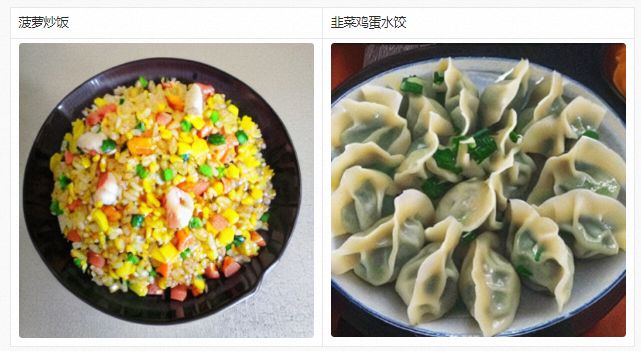
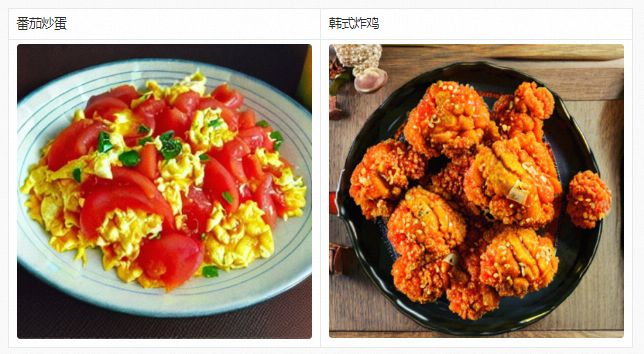
除了用于生成艺术大图,通过对PAI-Diffusion中文模型进行继续预训练,我们也可以得到高度场景化的中文模型。以下是PAI-Diffusion中文模型在美食数据上继续预训练后生成的结果,可以看出只要拥有高质量的业务数据,可以产出针对不同业务场景的Diffusion模型。这些模型可以进一步与LoRA、ControlNet等技术进行无缝结合,做到与业务更契合、更可控的图像编辑与生成。
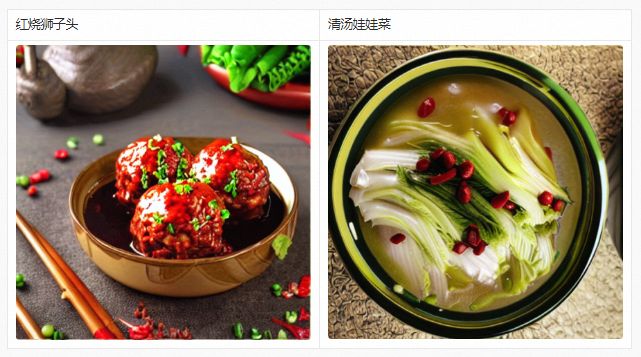
模型的使用和下载
在开源社区使用PAI-Diffusion中文模型
为了方便开源社区使用这些模型,我们将这两个模型接入了两个知名的开源模型分享社区HuggingFace和ModelScope。以HuggingFace为例,我们可以使用如下代码进行模型推理:
from diffusers import StableDiffusionPipeline
model_id = "alibaba-pai/pai-diffusion-artist-large-zh"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
pipe = pipe.to("cuda")
prompt = "雾蒙蒙的日出在湖面上"
image = pipe(prompt).images[0]
image.save("result.png")在ModelScope的使用接口示例如下:
from modelscope.pipelines import pipeline
import cv2
p = pipeline('text-to-image-synthesis', 'PAI/pai-diffusion-artist-large-zh', model_revision='v1.0.0')
result = p({'text': '雾蒙蒙的日出在湖面上'})
image = result["output_imgs"][0]
cv2.imwrite("image.png", image)此外,我们也在EasyNLP算法框架中开设了Diffusion算法专区(链接),提供各种PAI-Diffusio模型的使用脚本和教程。
在PAI-DSW使用PAI-Diffusion中文模型
PAI-DSW(Data Science Workshop)是阿里云机器学习平台PAI开发的云上IDE,面向不同水平的开发者,提供了交互式的编程环境(文档)。在DSW Gallery中,提供了各种Notebook示例,方便用户轻松上手DSW,搭建各种机器学习应用。我们也在DSW Gallery中上架了使用PAI-Diffusion中文模型的Sample Notebook,欢迎大家体验!
免费领取:阿里云机器学习平台PAI为开发者提供免费试用额度,包含DSW、DLC、EAS多款产品。https://free.aliyun.com/?pipCode=learn
未来展望
在这一期的工作中,我们对PAI-Diffusion中文模型的效果和功能进行了大幅扩展,使得图像生成质量的大幅提升、风格多样化。同时,我们支持包括LoRA、Textual Inversion等多种精细化模型微调和编辑功能。此外,我们也展示了多种场景化定制方案,方便用户在特定场景下训练和使用自己的Diffusion中文模型。在未来,我们计划进一步扩展各种场景的模型功能。
阿里灵杰回顾
- 阿里灵杰:阿里云机器学习PAI开源中文NLP算法框架EasyNLP,助力NLP大模型落地
- 阿里灵杰:预训练知识度量比赛夺冠!阿里云PAI发布知识预训练工具
- 阿里灵杰:EasyNLP带你玩转CLIP图文检索
- 阿里灵杰:EasyNLP中文文图生成模型带你秒变艺术家
- 阿里灵杰:EasyNLP集成K-BERT算法,借助知识图谱实现更优Finetune
- 阿里灵杰:中文稀疏GPT大模型落地 — 通往低成本&高性能多任务通用自然语言理解的关键里程碑
- 阿里灵杰:EasyNLP玩转文本摘要(新闻标题)生成
- 阿里灵杰:跨模态学习能力再升级,EasyNLP电商文图检索效果刷新SOTA
- 阿里灵杰:EasyNLP带你实现中英文机器阅读理解
- 阿里灵杰:EasyNLP发布融合语言学和事实知识的中文预训练模型CKBERT
- 阿里灵杰:当大火的文图生成模型遇见知识图谱,AI画像趋近于真实世界
- 阿里灵杰:PAI-Diffusion模型来了!阿里云机器学习团队带您徜徉中文艺术海洋
- 阿里灵杰:阿里云PAI-Diffusion功能再升级,全链路支持模型调优,平均推理速度提升75%以上