云原生之深入解析如何在Kubernetes下快速构建企业级云原生日志系统
一、概述
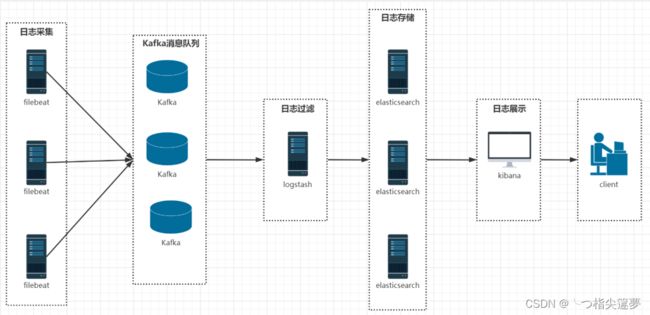
- ELK 是三个开源软件的缩写,分别表示 Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个 FileBeat,它是一个轻量级的日志收集处理工具 (Agent),Filebeat 占用资源少,适合于在各个服务器上搜集日志后传输给 Logstash,官方也推荐此工具。
- 大致流程图如下:

① Elasticsearch 存储
- Elasticsearch 是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。
② Filebeat 日志数据采集
- filebeat 是 Beats 中的一员,Beats 在是一个轻量级日志采集器,其实 Beats 家族有 6 个成员,早期的 ELK 架构中使用 Logstash 收集、解析日志,但是 Logstash 对内存、cpu、io 等资源消耗比较高。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。
- Filebeat 是用于转发和集中日志数据的轻量级传送工具,Filebeat 监视指定的日志文件或位置,收集日志事件。
- 目前 Beats 包含六种工具:
-
- Packetbeat:网络数据(收集网络流量数据);
-
- Metricbeat:指标(收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据);
-
- Filebeat:日志文件(收集文件数据);
-
- Winlogbeat:windows 事件日志(收集 Windows 事件日志数据);
-
- Auditbeat:审计数据(收集审计日志);
-
- Heartbeat:运行时间监控(收集系统运行时的数据)。
- 工作的流程图如下:

- 优点:Filebeat 只是一个二进制文件没有任何依赖。它占用资源极少。
- 缺点:Filebeat 的应用范围十分有限,因此在某些场景下会碰到问题,在 5.x 版本中,它还具有过滤的能力。
③ Kafka
- kafka 可以削峰,ELK 可以使用 redis 作为消息队列,但 redis 作为消息队列不是强项而且 redis 集群不如专业的消息发布系统 kafka。
④ Logstash 过滤
- Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为 c/s 架构,client 端安装在需要收集日志的主机上,server 端负责将收到的各节点日志进行过滤、修改等操作在一并发往 elasticsearch 上去。
- 优点:
-
- 可伸缩性,节拍应该在一组 Logstash 节点之间进行负载平衡,建议至少使用两个 Logstash 节点以实现高可用性,每个 Logstash 点只部署一个 Beats 输入是很常见的,但每个 Logstash 节点也可以部署多个 Beats 输入,以便为不同的数据源公开独立的端点;
-
- 弹性:Logstash 持久队列提供跨节点故障的保护,对于 Logstash 中的磁盘级弹性,确保磁盘冗余非常重要。对于内部部署,建议您配置 RAID,在云或容器化环境中运行时,建议使用具有反映数据 SLA 的复制策略的永久磁盘;
-
- 可过滤:对事件字段执行常规转换,可以重命名,删除,替换和修改事件中的字段;
- 缺点:Logstash 耗资源较大,运行占用 CPU 和内存高;另外没有消息队列缓存,存在数据丢失隐患。
⑤ Kibana 展示
- Kibana 也是一个开源和免费的工具,Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
- filebeat 和 logstash 的关系:因为 logstash 是 jvm 跑的,资源消耗比较大,所以后来作者又用 golang 写了一个功能较少但是资源消耗也小的轻量级的 logstash-forwarder。不过作者只是一个人,加入 http://elastic.co 公司以后,因为 es 公司本身还收购了另一个开源项目 packetbeat,而这个项目专门就是用 golang 的,有整个团队,所以 es 公司干脆把 logstash-forwarder 的开发工作也合并到同一个 golang 团队来搞,于是新的项目就叫 filebeat 了。
二、helm3 安装 ELK
- 整体流程图如下:
① 准备条件
- 添加 helm 仓库:
$ helm repo add elastic https://helm.elastic.co
② helm3 安装 elasticsearch
- 自定义 values:主要是设置 storage Class 持久化和资源限制,如果电脑资源有限,可以把资源调小:
# 集群名称
clusterName: "elasticsearch"
# ElasticSearch 6.8+ 默认安装了 x-pack 插件,部分功能免费,这里选禁用
esConfig:
elasticsearch.yml: |
network.host: 0.0.0.0
cluster.name: "elasticsearch"
xpack.security.enabled: false
resources:
requests:
memory: 1Gi
volumeClaimTemplate:
storageClassName: "bigdata-nfs-storage"
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 3Gi
service:
type: NodePort
port: 9000
nodePort: 31311
- 禁用 Kibana 安全提示(Elasticsearch built-in security features are not enabled)xpack.security.enabled: false。
- 开始安装 Elasitcsearch:
$ helm install es elastic/elasticsearch -f my-values.yaml --namespace bigdata

W1207 23:10:57.980283 21465 warnings.go:70] policy/v1beta1 PodDisruptionBudget is deprecated in v1.21+, unavailable in v1.25+; use policy/v1 PodDisruptionBudget
W1207 23:10:58.015416 21465 warnings.go:70] policy/v1beta1 PodDisruptionBudget is deprecated in v1.21+, unavailable in v1.25+; use policy/v1 PodDisruptionBudget
NAME: es
LAST DEPLOYED: Tue Dec 7 23:10:57 2021
NAMESPACE: bigdata
STATUS: deployed
REVISION: 1
NOTES:
1. Watch all cluster members come up.
$ kubectl get pods --namespace=bigdata -l app=elasticsearch-master -w2. Test cluster health using Helm test.
$ helm --namespace=bigdata test es
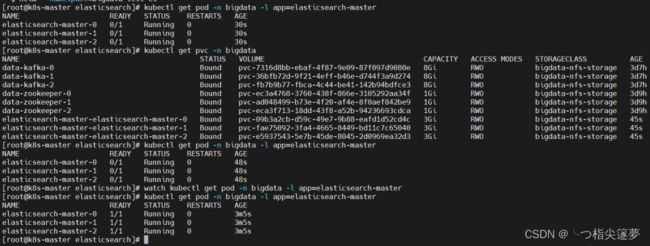
- 查看,需要所有 pod 都正常运行才正常,下载镜像有点慢,需要稍等一段时间再查看:
$ kubectl get pod -n bigdata -l app=elasticsearch-master
$ kubectl get pvc -n bigdata
$ watch kubectl get pod -n bigdata -l app=elasticsearch-master
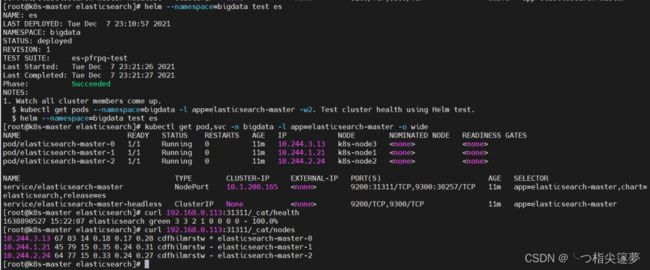
- 验证:
$ helm --namespace=bigdata test es
$ kubectl get pod,svc -n bigdata -l app=elasticsearch-master -o wide
$ curl 192.168.0.113:31311/_cat/health
$ curl 192.168.0.113:31311/_cat/nodes
- 清理:
$ helm uninstall es -n bigdata
$ kubectl delete pvc elasticsearch-master-elasticsearch-master-0 -n bigdata
$ kubectl delete pvc elasticsearch-master-elasticsearch-master-1 -n bigdata
$ kubectl delete pvc elasticsearch-master-elasticsearch-master-2 -n bigdata
③ helm3 安装 Kibana
- 自定义 values:
$ cat <<EOF> my-values.yaml
#此处修改了kibana的配置文件,默认位置/usr/share/kibana/kibana.yaml
kibanaConfig:
kibana.yml: |
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: [ "elasticsearch-master-headless.bigdata.svc.cluster.local:9200" ]
resources:
requests:
cpu: "1000m"
memory: "256Mi"
limits:
cpu: "1000m"
memory: "1Gi"
service:
#type: ClusterIP
type: NodePort
loadBalancerIP: ""
port: 5601
nodePort: "30026"
EOF
- 开始安装 Kibana:
$ helm install kibana elastic/kibana -f my-values.yaml --namespace bigdata

- 验证:
$ kubectl get pod,svc -n bigdata -l app=kibana
- 浏览器访问:http://192.168.0.113:30026/
- 清理:
$ helm uninstall kibana -n bigdata
④ helm3 安装 Filebeat
- filebeat 默认收集宿主机上 docker 的日志路径:/var/lib/docker/containers,如果修改了 docker 的安装路径要怎么收集呢?很简单,修改 chart 里的 DaemonSet 文件里边的 hostPath 参数:
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers #改为docker安装路径
- 当然也可以自定义 values 修改,这里推荐自定义 values 方式修改采集日志路径。
- 自定义 values:默认是将数据存储到 ES,这里做修改数据存储到 Kafka:
$ cat <<EOF> my-values.yaml
daemonset:
filebeatConfig:
filebeat.yml: |
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
output.elasticsearch:
enabled: false
host: '${NODE_NAME}'
hosts: '${ELASTICSEARCH_HOSTS:elasticsearch-master:9200}'
output.kafka:
enabled: true
hosts: ["kafka-headless.bigdata.svc.cluster.local:9092"]
topic: test
EOF
- 开始安装 Filefeat:
$ helm install filebeat elastic/filebeat -f my-values.yaml --namespace bigdata
$ kubectl get pods --namespace=bigdata -l app=filebeat-filebeat -w


- 验证:
# 先登录kafka客户端
$ kubectl exec --tty -i kafka-client --namespace bigdata -- bash
# 再消费数据
$ kafka-console-consumer.sh --bootstrap-server kafka.bigdata.svc.cluster.local:9092 --topic test
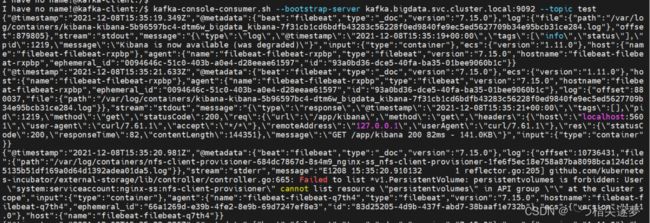
- 看到已经可以消费数据了,说明数据已经存储到 kafka。查看 kafka 数据积压情况:
$ kubectl exec --tty -i kafka-client --namespace bigdata -- bash
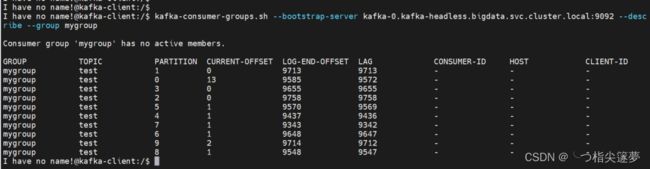
$ kafka-consumer-groups.sh --bootstrap-server kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 --describe --group mygroup
- 发现大量数据都是处于积压的状态:
- 接下来就是部署 logstash 去消费 kafka 数据,最后存储到 ES。
- 清理:
$ helm uninstall filebeat -n bigdata
⑤ helm3 安装 Logstash
- 自定义 values(把 ES 和 kafka 的地址换成自己环境):
$ cat <<EOF> my-values.yaml
logstashConfig:
logstash.yml: |
xpack.monitoring.enabled: false
logstashPipeline:
logstash.yml: |
input {
kafka {
bootstrap_servers => "kafka-headless.bigdata.svc.cluster.local:9092"
topics => ["test"]
group_id => "mygroup"
#如果使用元数据就不能使用下面的byte字节序列化,否则会报错
#key_deserializer_class => "org.apache.kafka.common.serialization.ByteArrayDeserializer"
#value_deserializer_class => "org.apache.kafka.common.serialization.ByteArrayDeserializer"
consumer_threads => 1
#默认为false,只有为true的时候才会获取到元数据
decorate_events => true
auto_offset_reset => "earliest"
}
}
filter {
mutate {
#从kafka的key中获取数据并按照逗号切割
split => ["[@metadata][kafka][key]", ","]
add_field => {
#将切割后的第一位数据放入自定义的“index”字段中
"index" => "%{[@metadata][kafka][key][0]}"
}
}
}
output {
elasticsearch {
pool_max => 1000
pool_max_per_route => 200
hosts => ["elasticsearch-master-headless.bigdata.svc.cluster.local:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
# 资源限制
resources:
requests:
cpu: "100m"
memory: "256Mi"
limits:
cpu: "1000m"
memory: "1Gi"
volumeClaimTemplate:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 3Gi
EOF
- output plugin 输出插件,将事件发送到特定目标:
stdout { codec => rubydebug } // 开启 debug 模式,可在控制台输出
- stdout :标准输出,将事件输出到屏幕上:
output{
stdout{
codec => "rubydebug"
}
}
- file:将事件写入文件:
output{
file {
path => "/data/logstash/%{host}/{application}
codec => line { format => "%{message}"} }
}
}
- kafka:将事件发送到 kafka:
output{
kafka{
bootstrap_servers => "localhost:9092"
topic_id => "test_topic" #必需的设置。生成消息的主题
}
}
- elasticseach:在 es 中存储日志:
output{
elasticsearch {
#user => elastic
#password => changeme
hosts => "localhost:9200"
index => "nginx-access-log-%{+YYYY.MM.dd}"
}
}
- 开始安装 Logstash:
$ helm install logstash elastic/logstash -f my-values.yaml --namespace bigdata

$ kubectl get pods --namespace=bigdata -l app=logstash-logstash
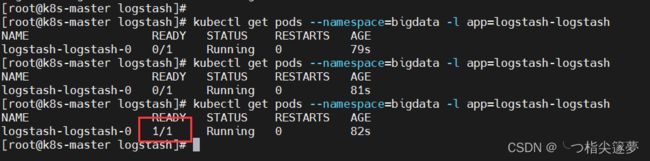
- 验证:
-
- 登录 kibana 查看索引是否创建:

-
- 查看 logs:
$ kubectl logs -f logstash-logstash-0 -n bigdata >logs
$ tail -100 logs

-
- 查看 kafka 消费情况:
$ kubectl exec --tty -i kafka-client --namespace bigdata -- bash
$ kafka-consumer-groups.sh --bootstrap-server kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 --describe --group mygroup

- 通过 kibana 查看索引数据(Kibana 版本:7.15.0) 创建索引模式:
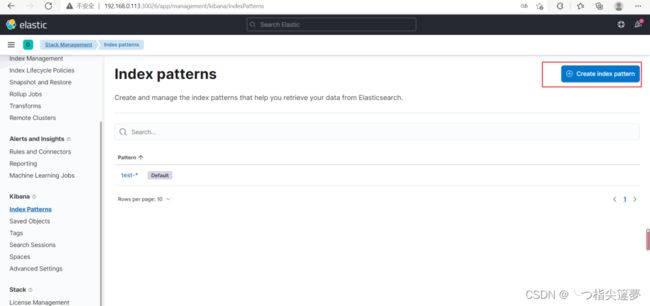
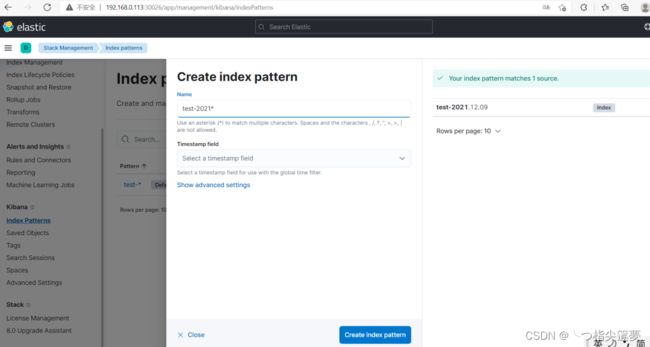

- 通过上面创建的索引模式查询数据(Discover):
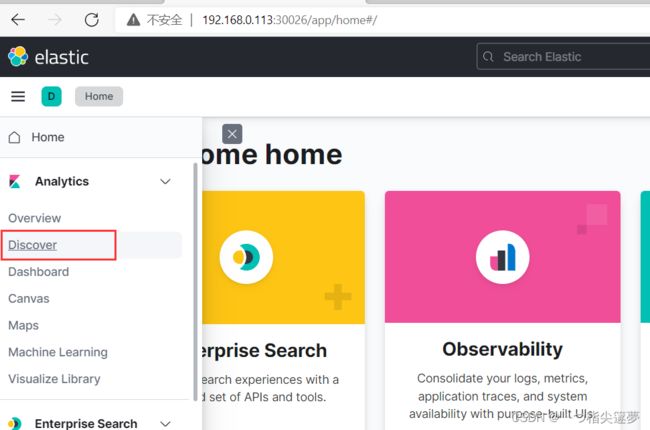
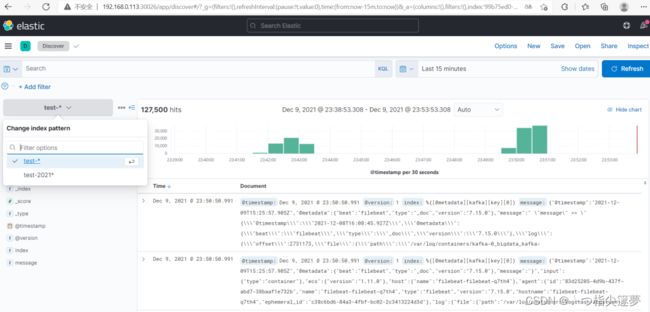
- 清理:
$ helm uninstall logstash -n bigdata
三、ELK 相关的备份组件和备份方式
- Elasticsearch 备份两种方式:
-
- 将数据导出成文本文件,比如通过 elasticdump、esm 等工具将存储在 Elasticsearch 中的数据导出到文件中,适用数据量小的场景;
-
- 备份 elasticsearch data 目录中文件的形式来做快照,借助 Elasticsearch 中 snapshot 接口实现的功能,适用大数据量的场景。
① Elasticsearch 的 snapshot 快照备份
- snapshot 快照备份的优缺点:
-
- 优点:通过 snapshot 拍摄快照,然后定义快照备份策略,能够实现快照自动化存储,可以定义各种策略来满足自己不同的备份;
-
- 缺点:还原不够灵活,拍摄快照进行备份很快,但是还原的时候没办法随意进行还原,类似虚拟机快照。
- 配置备份目录:
-
- 在 elasticsearch.yml 的配置文件中注明可以用作备份路径 path.repo ,如下所示:
path.repo: ["/mount/backups", "/mount/longterm_backups"]
-
- 配置好后,就可以使用 snapshot api 来创建一个 repository,如下创建一个名为 my_backup 的 repository:
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/mount/backups/my_backup"
}
}
- 开始通过 API 接口备份:
-
- 有了 repostiroy 后,就可以做备份,也叫快照,也就是记录当下数据的状态。如下所示创建一个名为 snapshot_1 的快照:
PUT /_snapshot/my_backup/snapshot_1?wait_for_completion=true
-
- wait_for_completion 为 true 是指该 api 在备份执行完毕后再返回结果,否则默认是异步执行的,这里为了立刻看到效果,所以设置了该参数,线上执行时不用设置该参数,让其在后台异步执行即可。
- 增量备份:当执行完毕后,可以发现 /mount/backups/my_backup 体积变大,这说明新数据备份进来了,要说明的一点是,当在同一个 repository 中做多次 snapshot 时,elasticsearch 会检查要备份的数据 segment 文件是否有变化,如果没有变化则不处理,否则只会把发生变化的 segment file 备份下来,这其实就实现了增量备份:
PUT /_snapshot/my_backup/snapshot_2?wait_for_completion=true
- 数据恢复:通过调用如下 api 即可快速实现恢复功能:
POST /_snapshot/my_backup/snapshot_1/_restore?wait_for_completion=true
{
"indices": "index_1",
"rename_replacement": "restored_index_1"
}
② elasticdump 备份迁移 es 数据
- 索引数据导出为文件(备份):
# 导出索引Mapping数据
$ elasticdump \
--input=http://es实例IP:9200/index_name/index_type \
--output=/data/my_index_mapping.json \ # 存放目录
--type=mapping
# 导出索引数据
$ elasticdump \
--input=http://es实例IP:9200/index_name/index_type \
--output=/data/my_index.json \
--type=data
- 索引数据文件导入至索引(恢复):
# Mapping 数据导入至索引
$ elasticdump \
--output=http://es实例IP:9200/index_name \
--input=/home/indexdata/roll_vote_mapping.json \ # 导入数据目录
--type=mapping
# ES文档数据导入至索引
$ elasticdump \
--output=http:///es实例IP:9200/index_name \
--input=/home/indexdata/roll_vote.json \
--type=data
- 可直接将备份数据导入另一个 es 集群:
$ elasticdump --input=http://127.0.0.1:9200/test_event --output=http://127.0.0.2:9200/test_event --type=data
- type 是 ES 数据导出导入类型,Elasticdump 工具支持以下数据类型:
| type 类型 | 说明 |
| mapping | ES 的索引映射结构数据 |
| data | ES 的数据 |
| settings | ES 的索引库默认配置 |
| analyzer | ES 的分词器 |
| template | ES 的模板结构数据 |
| alias | ES 的索引别名 |
③ esm 备份迁移 es 数据
- 备份 es 数据:
$ esm -s http://10.33.8.103:9201 -x "petition_data" -b 5 --count=5000 --sliced_scroll_size=10 --refresh -o=./es_backup.bin
- -w 表示线程数 -b 表示一次 bulk 请求数据大小,单位 MB 默认 5M -c 一次 scroll 请求数量 导入恢复 es 数据:
$ esm -d http://172.16.20.20:9201 -y "petition_data6" -c 5000 -b 5 --refresh -i=./dump.bin