【组会整理及心得】SR+SIC Network、CloFormer、DropKey
【JSTARS23】Super-Resolution-Aided Sea Ice Concentration Estimation From AMSR2 Images by Encoder–Decoder Networks With Atrous Convolution
Encoder-Decoder网络结构的Atrous卷积用于AMSR2图像的超分辨率辅助海冰浓度估计 - 知乎
【本文贡献】
- 提出了一种基于超分辨率和海冰联合估计网络的新框架,从原始的LR AMSR2无源微波图像中准确地进行精细的海冰估计
- 采用改进的超分辨率网络,即PMDRnet来减小冰水分水岭的模糊效应和空间分辨率差带来的海冰估计误差
- 采用具有编码器-解码器结构和空洞卷积的CNN网络作为 SIC 网络,在不同时期的不同地区显示出了良好的鲁棒性
【网络结构】
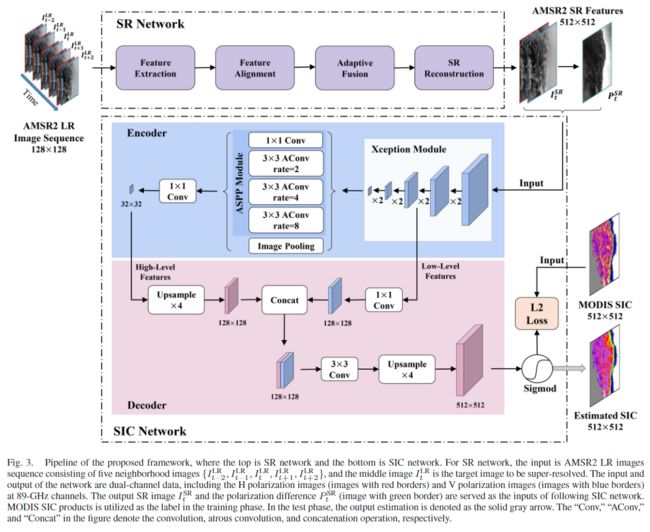
本文使用了两个网络,一个是用于图像超分的SR Network,另一个是用于海冰密集度估计的Encoder-Decoder结构的SIC Network。
SR Network部分是PMDRnet,出自论文《PMDRnet: A Progressive Multiscale Deformable Residual Network for Multi-Image Super-Resolution of AMSR2 Arctic Sea Ice Images》,和此处整理的论文应该是同组的工作。
PMDRnet由多个子网络组成,其中包括特征提取、多尺度可变形卷积对齐单元、特征融合网络和超分辨率重建网络等,具有强大的特征对齐能力和自适应融合能力。网络的输入是连续的五张双通道图片,可以看作类视频序列,其中目标图片是第三张图片,双通道指的是89 GHz通道的H偏振图像(红色边框的图像)和V偏振图像(蓝色边框的图像),输出两个图像,一个是极化差异图像,用于协助后面的SIC Network,另一个是超分重建后的图像,这两个图像都是双通道的。
SIC Network的Encoder部分使用的是经过修改的Xception和普通卷积与空洞卷积组成的ASPP模块,Xception用作特征提取的主干,ASPP模块使用多尺度卷积进行特征整合;Decoder部分主要是上采样、卷积和连接。
【心得体会】
海洋领域做深度学习的时候,需要更多注重海洋数据的处理,根据数据特点来设计网络。
【ARXIV2303】Rethinking Local Perception in Lightweight Vision Transformer
【ARXIV2303】Rethinking Local Perception in Lightweight Vision Transformer - 知乎
【本文贡献】
提出了CloFormer,其中引入了一个称为 AttnConv 的卷积算子,它采用注意力的风格,充分利用权值共享和上下文感知权重的优势,实现局部感知。在CloFormer中采用了一个双分支体系结构,其中一个分支使用AttnConv捕获高频信息,而另一个分支使用普通注意力和下采样捕获低频信息。
【网络结构】
CloFormer主要由一个卷积主干和四个stage组成,卷积主干用于获取tokens的表示,每个stage由一个Clo block和一个ConvFFN组成,用于提取分层特征。最后使用全局平均池化和全连接生成预测结果。
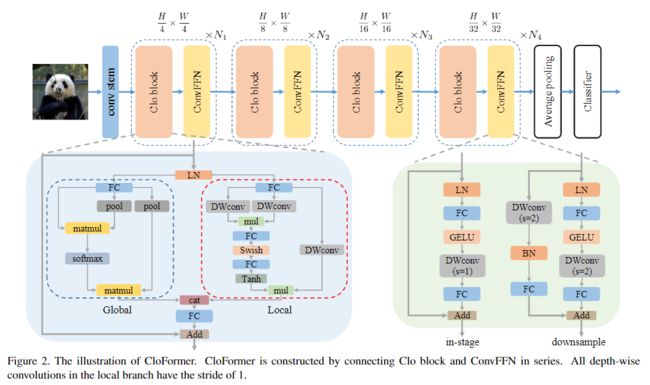
Clo block如上图蓝底部分所示,它使用了双分支结构,左边的分支是全局分支,先使用池化操作对k和v下采样,然后对qkv进行attention计算,提取出低频全局信息;右边的分支是局部分支,是一个AttnConv,它融合了共享权重和上下文感知权重,能更好地处理高频局部信息。
绿色底部分为ConvFFN,在GELU激活之后采用DW卷积,能够更好聚合局部信息。
将AttnConv与不同方法进行比较:
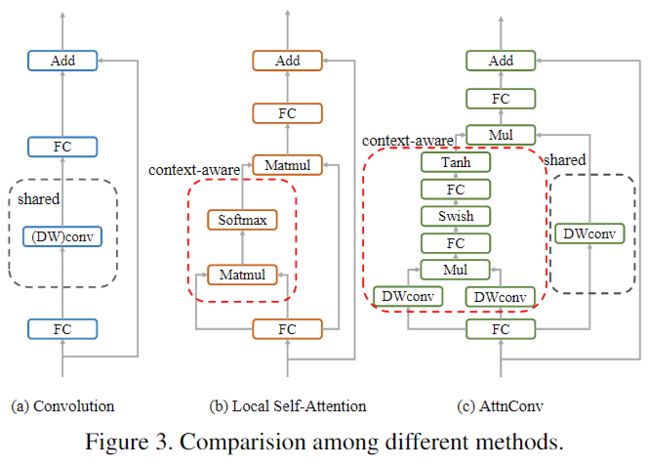
这三种方法都是残差结构,其中单纯的卷积能获取高频信息, 对于每个token,卷积算子使用卷积核中的权重对其相邻token执行加权求和,卷积核中的权重是全局共享的,对于不同的token仍然保持不变;相比之下,局部自注意力可以利用上下文感知权重来提取高频局部信息;与传统的卷积相比,AttnConv中使用的上下文感知权重使得模型能更好地适应输入内容,与局部自注意力相比,共享权重的引入使模型能更好地处理高频局部信息。此外,本文提出的生成上下文感知权重方法相比于局部自注意力引入了更强的非线性,从而提高了性能。
【心得体会】
本文的CloFormer整体可以看作为使用双分支结构的Transformer,一边是普通的提取全局信息的Transformer,另一边是AttnConv搭建的用于提取局部信息的Transformer,这种双分支结构感觉可以留意一下,花样挺多的(
【CVPR2023】DropKey for Vision Transformer
DropKey for Vision Transformer - 知乎
【本文贡献】
提出了3个问题:
- 自注意力层中要丢弃什么?
- 如何调度连续层中的丢弃率?
- 需不需要像CNN那样执行结构化dropout操作?
针对这3个问题,提出了DropKey方法,将Key视为Dropout单元,利用递减调度来降低丢弃率,对ViT进行了改进,并且该方法即插即用,只需两行代码即可实现。
【网络结构】
根据以上的三个问题,本文做出如下回答:
- 在计算注意力矩阵之前执行 Dropout 操作,把Key作为Dropout单元,得出一种新的dropout pre softmax方法,有助于缓解特定模式的过拟合问题,增强模型全局捕获重要信息的能力。
- 提出了一个 递减Dropout概率的计算方法,随着自注意力层的加深而减小Dropout概率。
- 尝试了基于patch的Dropout操作,发现其对于ViT来说并不是必需的。
通过对注意力机制的实现进行分析,本文发现,模型在优化的过程中,会对当前迭代下注意力占比更大的图像块在下次迭代时分配更大的注意力权值,这直接导致了过拟合的问题,因此本文试图通过随机drop部分key来缓解这一问题,通过自适应地调整注意力权重来获得更平滑的注意力向量,实现方法如图所示:

为了学习高维特征,ViT会叠加多个注意力层,其中浅层主要提取低维特征,深层主要提取高维复杂信息,因此本文将drop概率设置为由浅到深逐步减小,随着层数加深逐渐降低drop概率,避免丢失重要信息。
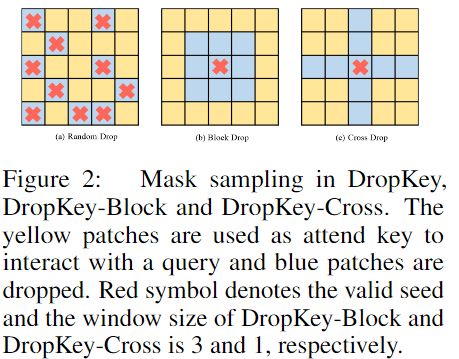
为探究DropKey对性能的影响,本文提出了两种结构化形式,分别为Block和Cross,最后发现这两种结构化方法不会带来性能提升。
除此之外,考虑到未对齐的期望会对模型带来一定的负面影响,本文提出了两种方法进行期望对齐,一个是用蒙特卡罗法估算c,执行多次随机下降,并在每次下降操作后计算注意力权重矩阵,将计算出的多重权重矩阵的平均值用作下一步的输入;另一个是在没有DropKey的情况下微调模型,作为DropKey训练后的额外阶段。实验证明第二种方法性能更好。
【心得体会】
没啥可说的,感觉很牛,顺便记录一个类似的工作:
《Reflash Dropout in Image Super-Resolution》仅需一行代码,实现真正的无痛涨点!单图像超分领域也需要Dropout一下