每日学术速递6.9
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
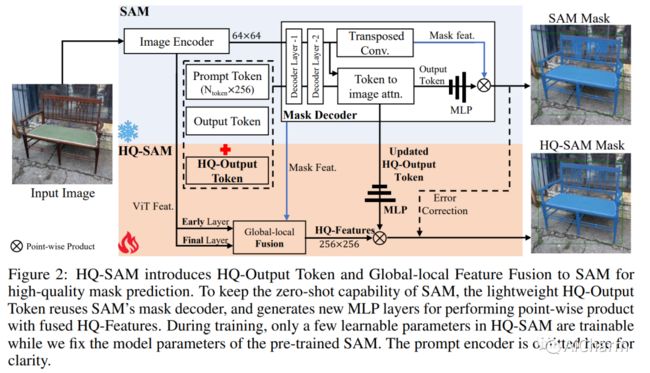
1.Segment Anything in High Quality

标题:以高质量分割任何内容
作者:Lei Ke, Mingqiao Ye, Martin Danelljan, Yifan Liu, Yu-Wing Tai, Chi-Keung Tang, Fisher Yu
文章链接:https://arxiv.org/abs/2306.01567
项目代码:https://github.com/SysCV/SAM-HQ




摘要:
最近的 Segment Anything Model (SAM) 代表了扩展分割模型的一大飞跃,允许强大的零样本功能和灵活的提示。尽管接受了 11 亿个掩码的训练,但 SAM 的掩码预测质量在许多情况下仍不尽如人意,尤其是在处理具有复杂结构的物体时。我们提出 HQ-SAM,使 SAM 具备准确分割任何对象的能力,同时保持 SAM 原有的提示设计、效率和零样本泛化能力。我们的精心设计重用并保留了 SAM 的预训练模型权重,同时只引入了最少的额外参数和计算。我们设计了一个可学习的高质量输出令牌,它被注入到 SAM 的掩码解码器中,并负责预测高质量掩码。我们不是仅将其应用于掩码解码器功能,而是首先将它们与早期和最终 ViT 功能融合以改进掩码细节。为了训练我们引入的可学习参数,我们从多个来源组成了一个 44K 细粒度掩码数据集。HQ-SAM 仅在引入的 44k 掩模 detaset 上进行训练,在 8 个 GPU 上仅需 4 小时。我们展示了 HQ-SAM 在跨不同下游任务的一组 9 个不同分割数据集中的功效,其中 7 个在零镜头传输协议中进行了评估。
Subjects: cs.CL
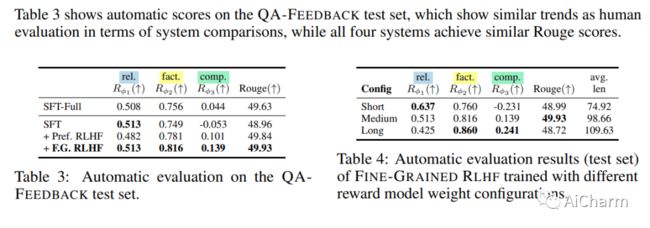
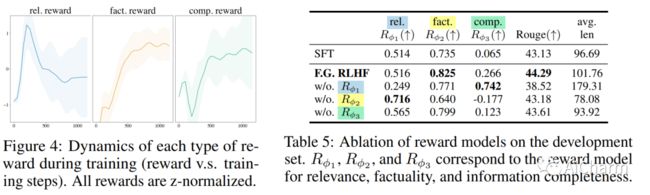
2.Fine-Grained Human Feedback Gives Better Rewards for Language Model Training

标题:细粒度的人类反馈为语言模型训练提供了更好的回报
作者:Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hannaneh Hajishirzi
文章链接:https://arxiv.org/abs/2306.01693
项目代码:https://finegrainedrlhf.github.io/



摘要:
语言模型 (LM) 通常表现出不良的文本生成行为,包括生成错误、有毒或不相关的输出。人类反馈强化学习 (RLHF)——人类对 LM 输出的偏好判断被转化为学习信号——最近在解决这些问题方面显示出希望。然而,这种整体反馈传达的长文本输出信息有限;它没有说明输出的哪些方面影响了用户偏好;例如,哪些部分包含什么类型的错误。在本文中,我们使用细粒度的人类反馈(例如,哪个句子是错误的,哪个子句子是不相关的)作为显式训练信号。我们介绍了细粒度 RLHF,这是一个框架,可以从两个方面细粒度的奖励函数中进行训练和学习:(1)密度,在生成每个片段(例如句子)后提供奖励;(2) 结合与不同反馈类型相关的多种奖励模型(例如,事实不正确、不相关和信息不完整)。我们对排毒和长篇问答进行了实验,以说明在自动和人工评估的支持下,使用此类奖励函数进行学习如何提高绩效。此外,我们表明可以使用细粒度奖励模型的不同组合来定制 LM 行为。我们在此 https URL 上发布所有数据、收集的人类反馈和代码。
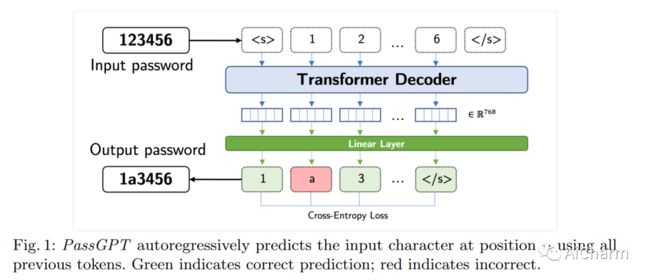
3.PassGPT: Password Modeling and (Guided) Generation with Large Language Models

标题:PassGPT:使用大型语言模型进行密码建模和(引导)生成
作者:Javier Rando, Fernando Perez-Cruz, Briland Hitaj
文章链接:https://arxiv.org/abs/2306.01545
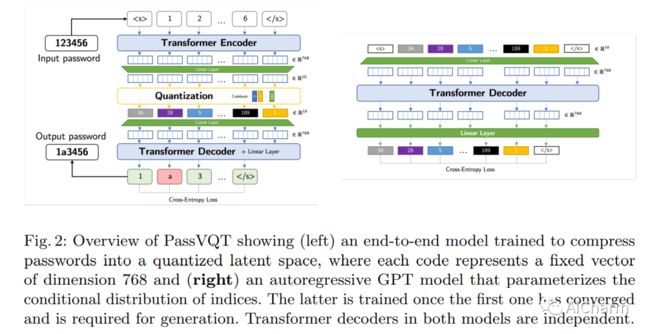
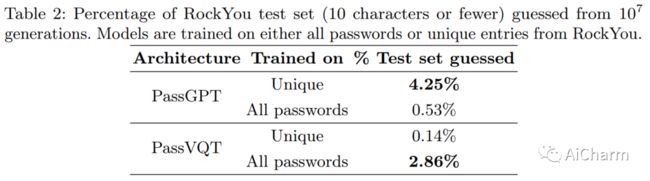

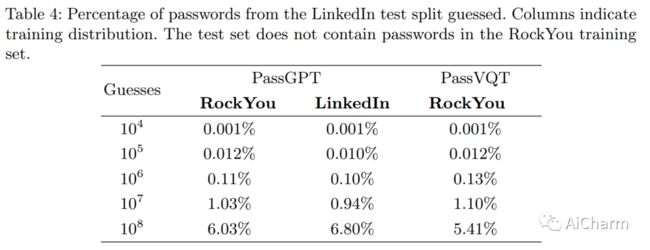
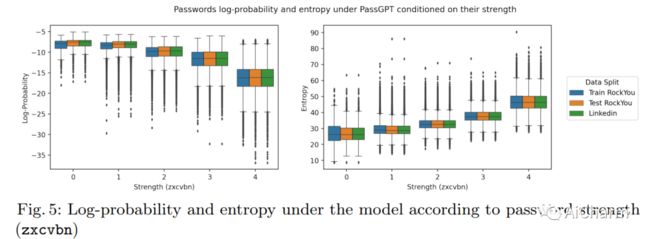

摘要:
大型语言模型 (LLM) 成功地从大量文本中对自然语言进行建模,而无需明确的监督。在本文中,我们研究了 LLM 在密码建模方面的功效。我们介绍了 PassGPT,这是一个受过密码泄漏培训的 LLM,用于生成密码。 PassGPT 通过猜测两倍于以前看不见的密码,优于基于生成对抗网络 (GAN) 的现有方法。此外,我们引入了引导密码生成的概念,我们利用 PassGPT 采样过程来生成匹配任意约束的密码,这是当前基于 GAN 的策略所缺乏的壮举。最后,我们对 PassGPT 定义的密码熵和概率分布进行了深入分析,并讨论了它们在增强现有密码强度估计器中的用途。
更多Ai资讯:公主号AiCharm