AI技术在跨学科融合创新方面扮演着日益重要的角色,特别是在Al for Science领域,AI技术的发展为跨学科、跨领域的融合创新带来了巨大的机会。AI已成为一个关键的研究工具,改变了基础科学的研究范式。依托AI技术开发的科学计算工具,如DeepXDE、SciML等,正在解决传统科学计算过于复杂且难以理解的问题。未来将会有更多功能强大的科学计算工具出现,从而推动AI技术成为重要的科研辅助工具,在数学、物理、化学、生物、地理等基础科学以及材料、电子、医疗、制药等应用领域发挥独特价值[1]。
 .png")
.png")
图1 AI for Science跨领域应用
飞桨PaddlePaddle目前是国内市场综合份额第一的深度学习平台,且一直在为科学研究者提供优秀的AI技术支持。在AI for Science方面,飞桨已经发布了针对流体、结构、电磁等学科的工具组件——赛桨PaddleScience V1.0 Beta。同时,为了更好地支持AI for Science在科研领域的深入探索,飞桨也在同步拓展和支持一系列业内主流科学计算工具。本期我们将重点介绍飞桨全量支持的深度学习科学计算工具DeepXDE,从全量算例及模型支持、高性能的训推环境以及典型工程实践等方面进行说明。
科学计算工具-DeepXDE
DeepXDE是一款开源且高度模块化的科学计算工具,以深度学习为核心,提供多种数据、物理机理及数理融合的模型,如PINN、DeepONet、MFNN等,同时支持多种类型微分方程,如常微分方程、偏微分方程的定义及求解,可有效解决复杂科学计算问题。
基于所提供的深度学习求解模型,DeepXDE具备以下典型的功能特点:
- 高度模块化:DeepXDE提供多种支持调用、组合的模块,如计算域、边界条件、微分方程、神经网络、训练及预测等,方便用户组合构建物理系统;
- 多类微分方程:支持自定义常微分方程、偏微分方程、积分微分方程等来描述具体问题;
- 可扩展性:支持用户结合自身需求添加自定义的数值算法、模型或其他功能;
- 可视化:提供一系列丰富的可视化工具,可以帮助用户直观地理解计算结果。
在科学计算领域,DeepXDE的强大功能与高精度求解能力,使其成为国内外知名的科学计算工具之一。截止目前,DeepXDE的下载量已超过40万次,并被全球70多所知名大学、科研机构和企业采用,比如MIT、Stanford、美国西北太平洋国家实验室、通用汽车等。在实际应用中,DeepXDE正在帮助用户快速解决复杂的科学计算问题,为各领域科学研究的进展作出了重要贡献。
 .png")
.png")
图2 DeepXDE方法与Backends
飞桨全量支持DeepXDE
全量支持DeepXDE方法与算例
飞桨完全支持DeepXDE工具中提供的PINN、DeepONet等方法,并对工具中提供的各类算例进行了全面的精度对齐。采用PINN方法运行的42个算例涵盖多种方程和初值/边界条件,飞桨支撑情况如下表所示,相比PyTorch目前支持的算例(31个)多了11个。

表1 飞桨支持DeepXDE中全部微分方程算例
飞桨科学计算支持能力
在支持科学计算方面,飞桨从神经网络、高阶微分、动转静技术等进行了全面改进,不仅能够全面支持DeepXDE提供的算例,也能够支持用户自定义的科学计算问题分析。
完备的训练网络
飞桨目前提供可覆盖PINN方法以及数据驱动方法的常用网络,如全连接网络、多尺度傅里叶特征网络及DeepONet、DeepONetCartesianProd等网络。
完整的微分方程体系
飞桨目前可支持多种类型微分方程的定义,如常微分方程、偏微分方程、积分微分方程、分数阶偏微分方程等。
动态图模式及“一键动转静”方案
飞桨支持用户基于动态图编码,同时支持一键动转静,可以使用户使用简单的转换语句同时享有动态图和静态图优势。
完善的科学计算常用高阶算子
为了实现科学计算问题中控制方程的高阶表达,飞桨框架完善了如下算子及功能:
- 提供部分算子的三阶计算,如全连接网络算子(matmul、add),激活函数(tanh, sin, cos等);
- 提供标量与tensor的加减乘除幂运算;
- 常用算子如assign、concat、cumsum、expand_v2、reverse、squeeze、unsqueeze、scale、tile、transpose、sign、sum、mean、flip、cast、slice等无限阶计算。
多优化器选择
飞桨提供如ADAM、L-BFGS等优化器,可覆盖广泛的科学计算应用,且针对DeepXDE中提供的科学计算算例,飞桨提供的L-BFGS 优化器可以达到更高精度的收敛效果。
此外,飞桨对DeepXDE部分算例已经实现了分布式并行,扩展数据集大小后可获得更高的性能提升。
飞桨性能优势
基于DeepXDE所提供算例的默认配置,在表2所示的测试环境中对其中20个算例进行了端到端的性能测试,结果如图3所示。左图表示飞桨(蓝色)与PyTorch(橙色)的算例对齐情况,其中横坐标为工具中的不同算例,纵坐标为算例达到收敛目标所需的训练时间,右图则直观的表示飞桨相比于PyTorch在不同算例对齐过程中的加速情况。可以看出,在所测试的75%个算例中,飞桨的性能均领先PyTorch,最高提速达25%,这说明飞桨可以作为DeepXDE全量算例的Backend,支持开发者进行科学计算分析。

表2 默认测试环境
 .png")
.png")
 .png")
.png")
图3 飞桨支持DeepXDE全量算例性能评估
飞桨DeepXDE开发验证学习文档
针对DeepXDE中提供的算例及相关模型,飞桨完成了大量精度对齐、验证工作,积累并形成了丰富的开发和验证经验,可以为用户提供应用指导,帮助用户正确使用DeepXDE工具进行新算例的开发和验证。
用户可以访问DeepXDE官方代码仓库体验飞桨对DeepXDE中全量算例及模型的支持,在完成DeepXDE的安装后,用户仅需设置DDE_BACKEND环境变量,即可执行相应的算例代码($ DDE_BACKEND=paddle; python pde.py)。
- DeepXDE官方代码仓库网址
https://github.com/lululxvi/d...
另外,在飞桨AI Studio-人工智能学习与实训社区提供的NoteBook环境下,用户仅需定义环境变量DDE_BACKEND=paddle,即可实现代码块的独立测试、执行。
围绕飞桨+DeepXDE算例的开发验证过程,主要包含如下算例验证标准、算例验证流程、模型对齐问题排查流程等工作:
算例验证标准
结合科学计算的正问题与逆问题,可以从单框架测试、多框架测试等途径进行网络参数、目标解、Loss的计算比对,且验证的优先级为:网络参数>目标解>Loss。
算例验证流程
算例验证流程主要分为算例实现和验证两个阶段。下图给出了PINN方法的完整训练过程,其中蓝色部分为每个阶段需要对齐的数据,黄色部分为算例实现的逻辑。对于算例的验证,主要从飞桨框架自测、多框架对比验证进行分阶段实现。  .png")
.png")
图4 DeepXDE支持的PINN方法原理
模型对齐问题排查流程
围绕算例及模型对齐过程中出现的问题,我们也形成了一些可供用户参考的经验,如可以对比其他框架,进行前向和反向的逐步对齐验证,并逐次打印对齐流程中的中间结果。此外,也需要进行如“随机种子”、“数据类型”、“初始化参数”、“控制合理误差”等设置,从而降低对齐难度。
此部分内容会在下一期的AI for Science专题“飞桨DeepXDE算例及模型精度对齐学习”中进行详细展开说明,期待广大用户阅读、指正。
案例实践
问题定义
随着通过缩小电路线宽提高集成度的“微细化”速度放缓,三维(3D)堆叠技术将承担半导体持续提高性能的作用。在芯片国产自主的背景下,3D堆叠技术也成为缓解国外技术制裁的重要方式。热挑战是3D堆叠技术的主要障碍之一,复杂的架构和高度集成的器件增加了芯片功耗和热密度。基于AI的传热模型不仅可以评估3D堆叠芯片的散热性能,而且为芯片散热结构设计的自动优化提供了广泛的潜力。本节主要介绍采用飞桨+DeepXDE进行芯片散热分析的相关案例实践,如图5所示。  .png")
.png")
*图5 3D堆叠芯片
JL Ayala,A Sridhar, Through silicon via-based grid for thermal control in 3D chips *
针对图5-(a)所示的简化3D芯片结构,其散热过程可由如下热自然对流控制方程来描述:
- 质量守恒
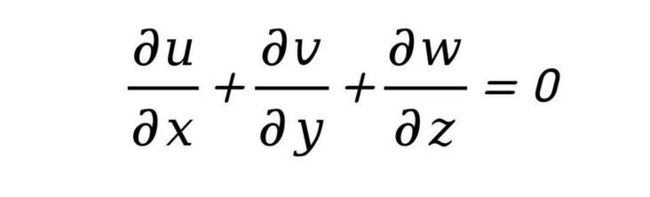
- 动量守恒
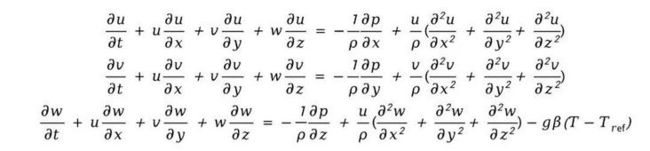
- 能量守恒
 式中,、、分别为、、方向的速度分量(m⋅${s}^{-1}$),为压力(),为温度(℃),为时间(s);为动力粘度(⋅),为密度(⋅${m}^{-3}$),${}_{p}$为比热容(⋅${}^{-1}$⋅${m }^{-3}$),为导热系数(⋅${m}^{-1}$⋅${℃}^{-1}$),为重力加速度(通常取9.8m⋅${s}^{-1}$),为热膨胀系数(1⋅${℃}^{-1}$),${T}_{ref}$为参考温度(℃);为体积热源项(⋅${m}^{-3}$),与芯片的热功耗有关。
式中,、、分别为、、方向的速度分量(m⋅${s}^{-1}$),为压力(),为温度(℃),为时间(s);为动力粘度(⋅),为密度(⋅${m}^{-3}$),${}_{p}$为比热容(⋅${}^{-1}$⋅${m }^{-3}$),为导热系数(⋅${m}^{-1}$⋅${℃}^{-1}$),为重力加速度(通常取9.8m⋅${s}^{-1}$),为热膨胀系数(1⋅${℃}^{-1}$),${T}_{ref}$为参考温度(℃);为体积热源项(⋅${m}^{-3}$),与芯片的热功耗有关。
针对实际芯片散热问题,通常假定温度为常温、周围空气静止,只要给定特定的边界条件就可以采用AI模型进行求解。其中,速度场通常采用无滑移边界条件,而温度场的边界条件则可描述如下:
- Dirichlet条件
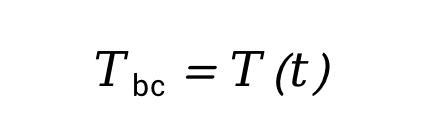
- Neumann条件
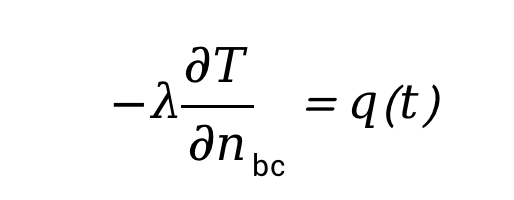
- Robin条件
案例建设及分析
基于DeepXDE的PINN方法,构建相应的芯片散热案例,如图6所示。其原理简要介绍如下,首先,针对待求解的时间(t)和实际的空间(x, y, z),采用合适的采样方法获得模型训练所需的时空离散点,这些点数据将作为AI网络模型的输入,并输出相应的流场和温度信息(u, v, w, p, T);然后,计算约束方程所需的流场和温度结果的时空导数,并获得对应于约束方程和初边值条件的Loss。

图6 芯片散热分析原理及主要构建步骤
针对5层芯片结构的散热案例,构建相应热自然对流控制方程的无量纲化形式,以提高模型训练的稳定性和精度。结合给定的计算域,采用NVIDIA V100-16G单卡训练约4小时,预测的无量纲时间为1s时的结果如图7所示。3D整体和2D中间截面的温度分布均表明,芯片内部的温度远高于周围空气的温度。这说明单纯靠空气热自然对流来将存在明显的热限制,从材料和散热结构等方面提升散热性能非常必要,此部分工作成果会在之后的专题中向大家呈现。

图7 3D芯片散热案例预测结果
总结
飞桨PaddlePaddle目前已经全面支持科学计算工具DeepXDE,对DeepXDE中提供的模型、算例等进行了多框架精度对齐以及性能调优。目前飞桨提供了完备的科学计算算子以及相关的网络模型、优化器、分布式并行等能力,可为广大用户使用飞桨+DeepXDE解决科学问题提供更多的可能。下一期我们会对飞桨+DeepXDE算例及模型精度对齐的详细实现过程进行经验介绍,敬请期待。
引用
[1] 百度研究院2023科技趋势发布:AI向实而生,智能技术构筑科技变革主线
https://baijiahao.baidu.com/s...[2] DeepXDE介绍文档
https://deepxde.readthedocs.i...[3] 飞桨动态图转静态图实现流程
https://www.paddlepaddle.org....[4] 飞桨L-BFGS优化器定义
https://www.paddlepaddle.org....拓展阅读
[1] 【PaddlePaddle Hackathon 第四期】—飞桨科学计算 PaddleScience
https://github.com/PaddlePadd...
[2] 飞桨AI for Science流体力学公开课第一期
https://aistudio.baidu.com/ai...
[3] AI+Science系列(三):赛桨PaddleScience底层核心框架技术创新详解
[4] 飞桨科学计算实训示例
https://aistudio.baidu.com/ai...相关地址
[1] 飞桨AI for Science共创计划
https://www.paddlepaddle.org....
[2] 飞桨PPISG-Science小组https://www.paddlepaddle.org....