Prometheus+Grafana监控系统
一、简介
1、Prometheus简介
官网:https://prometheus.io
项目代码:https://github.com/prometheus
- Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016年加入云原生云计算基金会(CNCF),成为继Kubernetes之后的第二个托管项目。
2、Prometheus组件与架构
- Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
- ClientLibrary:客户端库
- Push Gateway:短期存储指标数据。主要用于临时性的任务
- Exporters:采集已有的第三方服务监控指标并暴露metrics
- Alertmanager:告警
- Web UI:简单的Web控制台

3、监控实现
exporter列表:https://prometheus.io/docs/instrumenting/exporters

4、Grafana 简介
-
Grafana 官方是这么介绍 Grafana 的:grafana是用于可视化大型测量数据的开源程序,他提供了强大和优雅的方式去创建、共享、浏览数据。dashboard中显示了你不同metric数据源中的数据。
-
Grafana 官方还对 Grafana 的适用场景以及基本特征作了介绍:
- grafana最常用于因特网基础设施和应用分析,但在其他领域也有机会用到,比如:工业传感器、家庭自动化、过程控制等等。
- grafana有热插拔控制面板和可扩展的数据源,目前已经支持Graphite、InfluxDB、OpenTSDB、Elasticsearch。
二、实验环境
selinux iptables off
| 主机名 | IP | 系统版本 |
|---|---|---|
| jenkins | 10.10.10.10 | rhel7.5 |
| tomcat | 10.10.10.11 | rhel7.5 |
三、部署Prometheus
安装文档:https://prometheus.io/docs/prometheus/latest/installation/
1、创建prometheus.yml
[root@jenkins ~]# mkdir Prometheus
[root@jenkins ~]# mkdir Prometheus/data
[root@jenkins ~]# cat Prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
2、安装
(1)docker启动
docker run -d \
--name=prometheus \
-v /root/Prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /root/Prometheus/data:/prometheus \
-p 9090:9090 \
prom/prometheus
(2)报错
[root@jenkins ~]# docker logs -f 3e0e4270bd92
ts=2023-05-21T05:26:40.392Z caller=main.go:531 level=info msg="No time or size retention was set so using the default time retention" duration=15d
ts=2023-05-21T05:26:40.392Z caller=main.go:575 level=info msg="Starting Prometheus Server" mode=server version="(version=2.44.0, branch=HEAD, revi sion=1ac5131f698ebc60f13fe2727f89b115a41f6558)"
ts=2023-05-21T05:26:40.392Z caller=main.go:580 level=info build_context="(go=go1.20.4, platform=linux/amd64, user=root@739e8181c5db, date=20230514 -06:18:11, tags=netgo,builtinassets,stringlabels)"
ts=2023-05-21T05:26:40.392Z caller=main.go:581 level=info host_details="(Linux 3.10.0-862.el7.x86_64 #1 SMP Wed Mar 21 18:14:51 EDT 2018 x86_64 3e 0e4270bd92 (none))"
ts=2023-05-21T05:26:40.392Z caller=main.go:582 level=info fd_limits="(soft=65536, hard=65536)"
ts=2023-05-21T05:26:40.392Z caller=main.go:583 level=info vm_limits="(soft=unlimited, hard=unlimited)"
ts=2023-05-21T05:26:40.393Z caller=query_logger.go:91 level=error component=activeQueryTracker msg="Error opening query log file" file=/prometheus /queries.active err="open /prometheus/queries.active: permission denied"
panic: Unable to create mmap-ed active query log
goroutine 1 [running]:
github.com/prometheus/prometheus/promql.NewActiveQueryTracker({0x7fffcfb19f02, 0xb}, 0x14, {0x3c76360, 0xc0009bb360})
/app/promql/query_logger.go:121 +0x3cd
main.main()
/app/cmd/prometheus/main.go:637 +0x6f13
[root@jenkins ~]# chmod 777 -R Prometheus/
[root@jenkins ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3e0e4270bd92 prom/prometheus "/bin/prometheus --c…" 2 minutes ago Exited (2) 2 minutes ago prometheus
[root@jenkins ~]# docker start 3e0e4270bd92
3e0e4270bd92
[root@jenkins ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3e0e4270bd92 prom/prometheus "/bin/prometheus --c…" 2 minutes ago Up 2 seconds 0.0.0.0:9090->9090/tcp prometheus
3、浏览器查看
http://10.10.10.10:9090

四、Grafana安装与使用
安装文档:https://grafana.com/grafana/download?platform=docker
1、安装
[root@jenkins ~]# docker run -d --name=grafana -p 3000:3000 grafana/grafana-enterprise
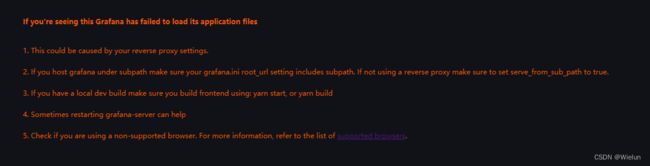
2、报错
升级下Google浏览器版本即可
If you're seeing this Grafana has failed to load its application files
1. This could be caused by your reverse proxy settings.
2. If you host grafana under subpath make sure your grafana.ini root_url setting includes subpath. If not using a reverse proxy make sure to set serve_from_sub_path to true.
3. If you have a local dev build make sure you build frontend using: yarn start, or yarn build
4. Sometimes restarting grafana-server can help
5. Check if you are using a non-supported browser. For more information, refer to the list of supported browsers.
3、访问登录
http://10.10.10.10:3000/login
直接输入账号密码设置即可,默认admin/admin


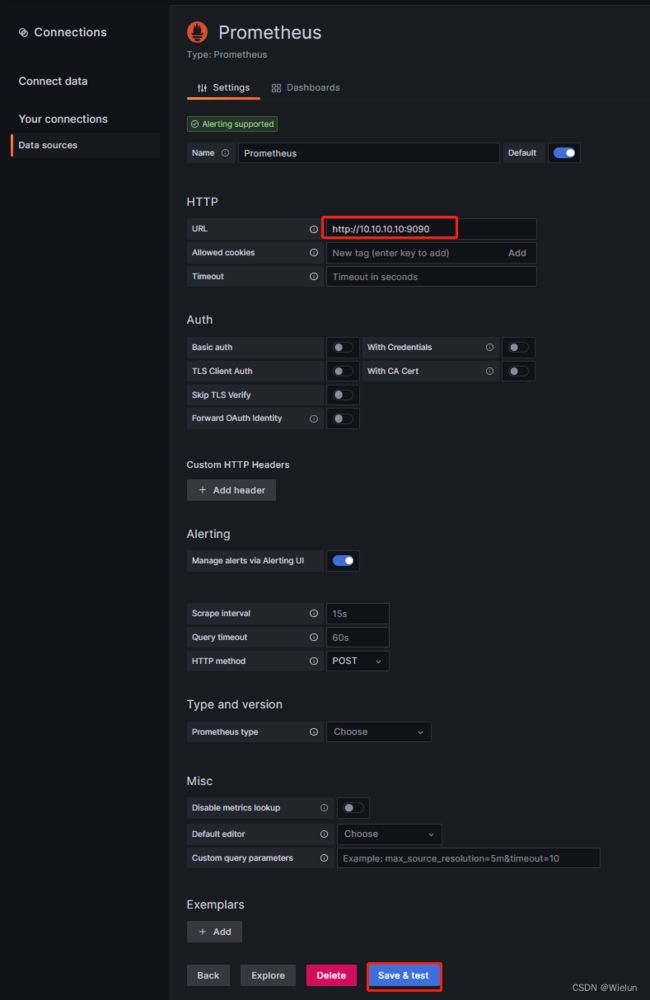
4、添加数据源



五、监控Linux服务器
1、安装node_exporter
node_exporter:用于监控Linux系统的指标采集器。
使用文档:https://prometheus.io/docs/guides/node-exporter/
项目代码:https://github.com/prometheus/node_exporter
下载地址:https://github.com/prometheus/node_exporter/releases/tag/v1.5.0
[root@server1 ~]# tar xf node_exporter-1.5.0.linux-amd64.tar.gz
[root@server1 ~]# mv node_exporter-1.5.0.linux-amd64 /usr/local/node_exporter
[root@server1 ~]# cat /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
[Service]
ExecStart=/usr/local/node_exporter/node_exporter
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
[root@server1 ~]# systemctl daemon-reload
[root@server1 ~]# systemctl enable node_exporter && systemctl start node_exporter
[root@server1 ~]# netstat -lntup|grep 9100
tcp6 0 0 :::9100 :::* LISTEN 4136/node_exporter

2、配置prometheus.yml
[root@jenkins ~]# cat Prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "Linux Server"
static_configs:
- targets: ["10.10.10.11:9100"]
[root@jenkins ~]# docker restart prometheus
3、Prometheus测试
查看节点是否添加成功

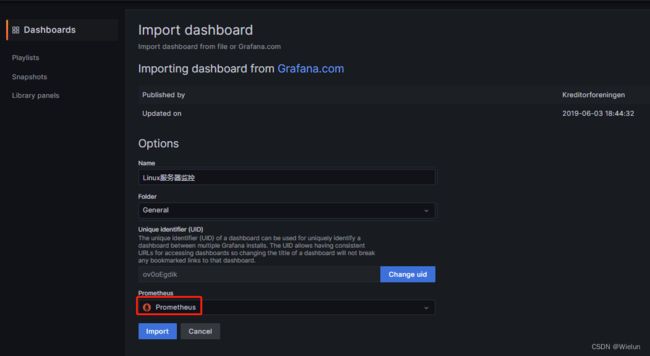
4、Grafana导入dashboard
dashboard模板地址: https://grafana.com/grafana/dashboards/
选择这个模板:https://grafana.com/grafana/dashboards/10180-kds-linux-hosts/

添加:


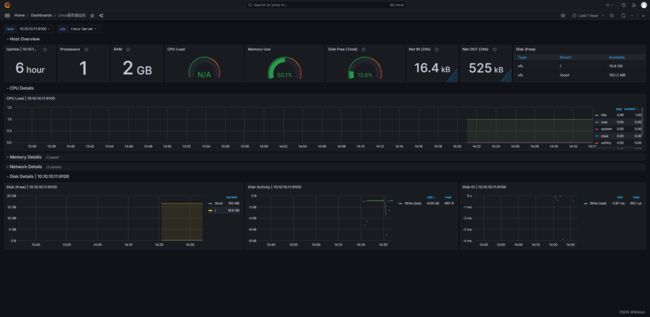
六、监控Docker服务器
1、安装cAdvisor
cAdvisor(Container Advisor):用于收集正在运行的容器资源使用和性能信息。
项目代码:https://github.com/google/cadvisor
docker run -d \
-v /:/rootfs:ro \
-v /var/run:/var/run:ro \
-v /sys:/sys:ro \
-v /var/lib/docker/:/var/lib/docker:ro \
-v /dev/disk/:/dev/disk:ro \
-p 9200:8080 \
--name=cadvisor \
google/cadvisor:latest
[root@server1 ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
94926b13c0ba google/cadvisor:latest "/usr/bin/cadvisor -…" 10 seconds ago Up 9 seconds 0.0.0.0:9200->8080/tcp cadvisor
2、配置prometheus.yml
[root@jenkins ~]# cat Prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "Linux Server"
static_configs:
- targets: ["10.10.10.11:9100"]
- job_name: "Docker Server"
static_configs:
- targets: ["10.10.10.11:9200"]
[root@jenkins ~]# docker restart prometheus
3、Prometheus测试

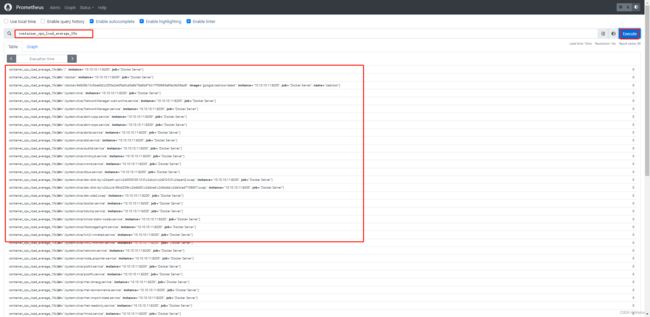
4、Grafana导入dashboard


5、docker nginx测试
[root@server1 ~]# docker run -d nginx
