1、3.4.5 源码编译
1、下载源码,执行以上修改
首先
build.xml更改
其实都是把http改为https,否则这会无法访问,在2020年1月之后就不可以访问了
2、执行 ant eclipse
3、import 指定 eclipse
4、/Users/xxx/IdeaProjects/zookeeper 直接根目录下执行 ant即可
2、Zookeeper三种角色 & 节点类型
Leader、Follower和Observer
只有Leader可以写数据,其他节点只能同步数据,Follower参与选举
Observer不参与选举
所以只能一个leader进行写,单机写入最多每秒上万QPS,这是没法扩展的,所以zk适合是写少读多的场景
持久化节点、临时节点、顺序节点(是和持久化节点和临时节点配合使用)
3、ZAB(Zookeeper Atomic Broadcast)
ZAB = 2PC + 过半写磁盘日志, proposal(os cache) + 过半ack + commit(forceSync磁盘)内存数据结构
4、顺序一致性
顺序一致性,其实是最终一致性。因为leader一定会保证所有的proposal同步到follower上都是按照顺序来走的,起码顺序不会乱
5、Zookeeper集群部署 & 核心参数
4核8G的机器,一般来说,每秒并发搞到1000是可以的
8核16G的机器,每秒并发搞到几千是可以的
16核32G的机器,每秒并发搞到上万或者是几万都是有可能的
tickTime : 默认2s,其他一些参数会以这个tickTime为基准来进行设置
dataDir : 数据快照
dataLogDir : 日志数据,proposal日志文件
snapCount : 默认10万个事务,存储一次快照
initLimit : 默认是10, 10 * tickTime,20s,启动完毕之后,follower和leader之间的数据同步,如果超过这个时间,leader直接对外提供服务了
syncLimit : 默认值是5,5 * 2 = 10s,leader和follower之间会进行心跳,如果超过10s没有心跳,leader就把这个follower给踢出去了,认为他已经死了
maxClientCnxns : 每个客户端对zk的连接最大是60个
jute.maxbuffer : 一个znode最多可以存储1MB数据
server.x = zk01:2888:3888
3888 是用来leader选举的,2888是用来数据同步的
客户端支持非交互式
./zkCli.sh -server localhost:2181 get /zookeeper2
6、读写锁
[写锁,写锁,读锁,读锁,写锁,读锁,读锁,读锁]
写锁只关心前面一个节点,对前面的这个节点做监听,读锁,应该计算排在离自己最近的一把写锁
所谓的羊群效应,就是不能我释放锁了,把所有不是监听我的锁都惊醒了,curator读锁应该是判断的离自己最前面的一个写锁
7、leader选举
三台机器myid 1,2,3
如果是空的集群,他们zxid都是0,如果是1,2,3依次启动,则第二台机器当选为leader,当quorum=(3/2+1)=2,半数的机器的时候才会进行选举
leader选举
第一轮投票
myid=0的机器,投票(0,0),(myid,zxid),广播给集群其他节点
myid=1的机器,投票(1,0),(myid,zxid),广播给集群其他节点
myid=0的机器,接收到(1,0),和投出去(0,0)对比,因为不一样,需要重新调整选择(1,0)
myid=1的机器,接收到(0,0),和投出去(1,0)对比,不需要重新调整继续(1,0)
第二轮投票
myid=0的机器,投票(1,0),(myid,zxid),广播给集群其他节点
myid=1的机器,投票(1,0),(myid,zxid),广播给集群其他节点
myid=0的机器,接收到(1,0)
myid=1的机器,接收到(1,0)
投票一致了,都选择了myid=1的这台机器,所以leader就产生了,最后就算myid=3启动了,因为leader已经存在,所以只能follower跟随
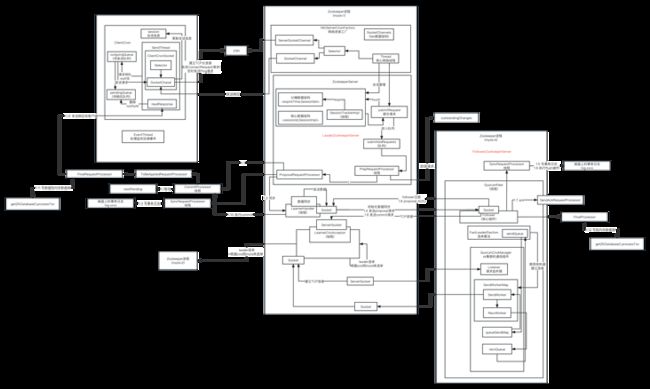
8、客户端源码
8.1、创建一个Zookeeper对象,Zookeeper对象中包含了一个ClientCnxn,这个对象不简单,代表一个客户端
8.2、ClientCnxn 三个重要的组件,
第一个组件是 ClientCnxnSocketNIO,使用NIO进行网络连接
第二个组件是 SendThread线程 用于客户端请求的发送
第三个组件是 EventThread线程 用于客户端接收watcher的回调
8.3、客户端命令会放入到 outgoingQueue 队列中,判断是否 finished,同时自己wait住,同时唤醒SendThread selector,让其干活,进行read/write
8.4、一旦SendThread run将outgoingQueue中的Packet写出去之后,会放入到pendingQueue中(说明已发送出去,但是还没有收到响应,一旦响应完毕,才会清除pendingQueue中的Packet)
8.5、SendThread read事件触发,之前outgoingQueue发送到zk server收到了响应
读取结果如果没有回调监听,直接表示finished=true,nofityAll packet,让客户端操作完成
如果有监听,比如说创建节点的时候指定了一个Watch,会标记finished=true,同时将Packet放入到waitingEvents(在EventThread中)
8.6、EventThread线程run方法会阻塞获取 waitingEvents 事件,处理监听回调watcher.process(pair.event)和回调函数processResult
9、session id的生成
Session生成算法
当前时间左移24,又移动8位
myid 左移 56
前两者相或,说白了,其实就是不单单用系统时间作为SessionId,要加myid(其实说白就是机器id)才能保证唯一性
session进行分桶设计,这样的好处是批量进行超时,不做无用功,比如说4和5个这个时间在同一个桶里面
(4/2 + 1) * 2 = 6
(5/2 + 1) * 2 = 6
(8/2 + 1) * 2 = 10
(9/2 + 1) * 2 = 10
SessionTrackerImpl 是一个线程,有后台线程,不断check线程超时,check的时候也是有逻辑的
tickTime 默认2s roundToInterval = (time / expirationInterval + 1) * expirationInterval 等于下一次 超时时间nextExpirationTime
ClientCnxn客户端周期性sendPing,通过 ClientCnxnSocketNIO 发送,维持和NIOServerCnxn也就是leader的心跳,每次请求也会进行touchSession
其实也是根据上面的 roundToInterval 算出来的,所以上面的 nextExpirationTime 时间肯定比要超时的桶时间小tickTime 倍数
所以超时check就是逻辑就是如果当前时间不到,就直接wait(nextExpirationTime - currentTime),然后直接超时session就可以,要知道不管是ping还是
touchSession都会让session往前桶走,所以相当于 touch是前走,超时是后追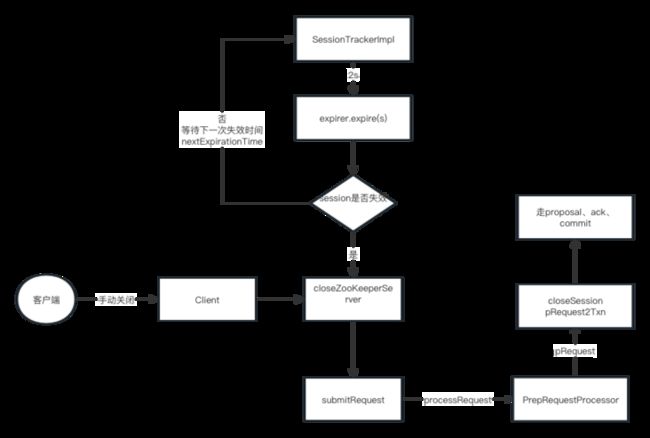
10、Leader选举流程(3888端口)
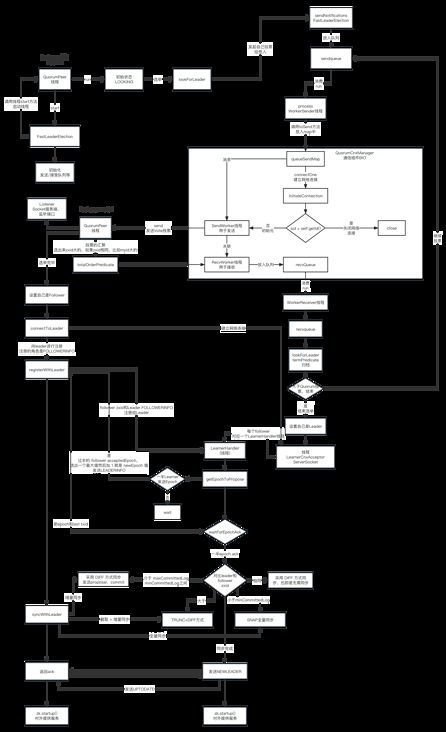
1、QuorumPeerMain是入口
2、解析zoo.cfg
3、创建并启动DatadirCleanupManager(用来周期性的清理log和snapshot)
4、创建网络通信组件,默认是 NIOServerCnxnFactory
5、创建QuourmPeer线程,是一个线程,这个可不简单,在 QuorumPeerMain 中会 start(是方法,不是线程start) QuourmPeer线程,里面做了很多关键事情
6、从快照文件中恢复数据,恢复log和snapshot
7、启动NIOServerCnxnFactory网络连接,是一个线程,让NIO开始监听干活,NIOServerCnxnFactory实现多路复用,ACCEPT、READ和WRITE事件,之后是
责任链的链条处理对应的是 LeaderZooKeeperServer
PreRequestProcessor -> ProposqlProcessor -> CommitProcessor -> toBeAppliedProcessor -> FinalProcessor
8、开始选举,两个事情
8.1、QuorumCnxManager.Listener创建3888,选举服务端端口监听,监听客户端的连接,创建SendWorker和RecvWorker线程,并启动
8.2、创建FastLeaderElection的时候不得了,starter -> new Messenger构造方法中,启动了 WorkerSender 和 WorkerReceiver 线程
9、启动 QuorumPeer 线程,走run方法,因为状态是LOOKING,走的是 FastLeaderElection.lookForLeader
sendNotifications 给其他节点发送通知的时候,会创建和Listener的连接,这里其实有一个问题,Zookeeper选举网络互连的核心思想是 : 只有大的server id才能连接小的server id,否则就算连接上也会被close
但是在3.4.5版本中 sendNotifications就开始和其他的peer开始建立连接,意思是说,我可以小的连接大的,会在Listener,也就是服务端判断,如果过来的server id比我小,断开
socket连接,其实应该在建立网络连接的时候判断,而不是建立完毕了再close
不断从 recvqueue 拿票
归票,这里有一个点需要注意 recvset 这个里面其实是包含了其他peer节点的票和自己的票(怎么会有自己的票呢?没有看到放进去啊?)
其实在sendNotifications的时候会判断,org.apache.zookeeper.server.quorum.QuorumCnxManager#toSend
这段代码很重要,就是自己给自己发送,直接放入到 recvQueue 中,就不走网络通信了
还有一层意义是自己不和自己网络连接,这样最终其实就放入到了
if (self.getId() == sid) {
b.position(0);
addToRecvQueue(new Message(b.duplicate(), sid));
/*
* Otherwise send to the corresponding thread to send.
*/
}
org.apache.zookeeper.server.quorum.FastLeaderElection#termPredicate走
org.apache.zookeeper.server.quorum.flexible.QuorumMaj#containsQuorum
public boolean containsQuorum(HashSet`` set){
// half = 1
return (set.size() > half);
} 票的核心数据结构 : (epoch, zxid, myid),上前往后一一比较,投票还有一个 logicalclock,可以不在同一个周期中进行选举
选举算法
sendQueue -> WorkerSender -> queueSendMap -> SendWorker -> RecvWorker -> recvQueue -> WorkerReceive -> recvqueue
归票的时候是会从 recvqueue 里面拿票
11、数据同步
选举完毕leader节点进入LEADING状态,follower节点将进入FOLLOWING状态,此时集群中节点将数据进行同步操作,以保证数据一致性。只有
数据同步完成,才能对外提供服务
leader :
会启动一个 LearnerCnxAcceptor,用来监听follower对其的网络连接,针对每一个 follower的连接都会创建一个 LearnerHandler线程服务于他
follower :
connectToLeader : 和leader建立网络连接
syncWithLeader 同步数据
主要要做的事情是三个:
1、leader 向 follower 发送 LEADERINFO 信息,告知 follower 新的 epoch 值
follower 接收解析 LEADERINFO 信息,若 new epoch 值大于 current accepted epoch 值则更新 acceptedEpoch
follower 向 leader 发送 ACKEPOCH 信息,反馈 leader 已收到新的 epoch 值,并附带 follower 节点的 last zxid
2、LearnerHandler 中 leader 在收到过半的 ACKEPOCH 信息之后将进入数据同步阶段
1和2其实在做一个事情,就是咱们版本一样了哈,可以同步数据了
3、同步策略
全量同步SNAP
若 follower 的 peerLastZxid 小于 leader 的 minCommittedLog 或者 leader 节点上不存在提案缓存队列时,将采用 SNAP 全量同步方式。 该模式下 leader 首先会向 follower 发送 SNAP 报文,随后从内存数据库中获取全量数据序列化传输给 follower, follower 在接收全量数据后会进行反序列化加载到内存数据库中
TRUNC(回滚同步)
若 follower 的 peerLastZxid 大于 leader 的 maxCommittedLog,则告知 follower 回滚至 maxCommittedLog; 该场景可以认为是 TRUNC+DIFF 的简化模式
RUNC+DIFF(先回滚再差异化同步)
在上文 DIFF 差异化同步时会存在一个特殊场景就是 虽然 follower 的 peerLastZxid 介于 maxCommittedLog, minCommittedLog 两者之间,但是 follower 的 peerLastZxid 在 leader 节点中不存在; 此时 leader 需告知 follower 先回滚到 peerLastZxid 的前一个 zxid, 回滚后再进行差异化同步
最后UPTODATE对外服务
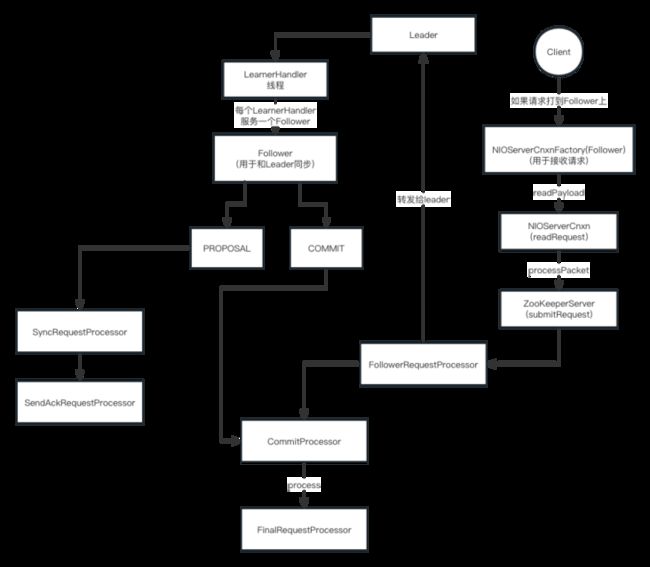
12、链条化处理
org.apache.zookeeper.server.NIOServerCnxn#readRequest,NIO服务端读取到客户端请求,甩到processor链条中进行处理
leader :
makeLeader -> new LeaderZooKeeperServer -> 创建一个责任链链条
PreRequestProcessor -> ProposalRequestProcessor 之后分两条分支
1、CommitProcessor -> ToBeAppliedRequestProcessor -> FinalRequestProcessor
2、SyncRequestprocessor -> AckRequestProcessor
follower :
两条线
存在意义是,其实客户端也是可以将请求发送给follower的,zk为了保证分布式数据一致性,使用ZAB协议,在客户端发起一次写请求的时候,假设请求到的是
follower,follower不会直接处理这个请求,而是转发给leader,由leader发起投票决定请求是最终能否执行成功
FollowerRequestProcessor -> CommitProcessor -> FinalRequestProcessor 这个链条有分为两个
如果client请求直接打到follower上,会转发给leader,走的是FollowerRequestProcessor 之后的链条
如果是leader的commit请求走的是 CommitProcessor -> FinalRequestProcessor的链条
SyncRequestProcessor -> SendAckRequestProcessor 这个链条是接受leader的proposal请求
13、Watcher机制
大致流程是Client向ZK中注册Watcher,如果注册成功的话,会将对应的Watcher存储在本地。当ZK服务器端触发Watcher事件之后,会向客户端发送通知,
客户端会从ClientWatchManager中取出对应的Watcher进行回调
1、客户端注册Watcher
2、服务端处理Watcher
3、客户端回调Watcher
客户的Watcher是由 ZKWatchManager 管理的
创建zookeeper客户端的时候给一个默认的Watcher
getData,getChildren,exist
ServerCnxn是一个关键,默认实现是 NIOServerCnxn ,代表了一个客户端和服务的连接,ServerCnxn 实现了Watcher接口
FinalRequestProcessor#processRequest
比如说getData的时候,如果加了Watcher的话,其实传递过来就是一个boolean值,是否加了Watcher,如果服务端会加到WatchManager中
在setData的时候,就是进行 dataWatches.triggerWatch(path,EventType.NodeDataChanged)传递回去,其实是通过 NIOServerCnxn 传递回去的
NIOServerCnxn 也是一个网络连接,直接发送给客户端
客户端直接使用EventThread进行处理,其实也是在getData的时候客户端判断有watcher,在本地保存
org.apache.zookeeper.ClientCnxn#finishPacket
// TODO 请解释清楚这里,其实很简单,就是比如说我要注册一个Watcher对吧,怎么也得让我这次注册成功之后,
// TODO 才有可能是服务端通知吧,所以这就是要做的注册Watcher
if (p.watchRegistration != null) {
// 最后回到WatchRegistration将对应的Watcher注册到对应的Map>中
p.watchRegistration.register(p.replyHeader.getErr());
} org.apache.zookeeper.ClientCnxn.SendThread#readResponse 如果有Watche通知,会放入到
EventThread#queueEvent 封装 WatcherSetEventPair(就是从ZKWatchManager中移除,放入到他里面的watchers中)的,
然后将WatcherSetEventPair 放入 waitingEvents 队列中,EventThread 线程 run 遍历WatcherSetEventPair中的watchers,调用process方法
Watcher的特性
1、一次性 : 物理是客户端还是服务端,一旦Watcher触发、都会将其从存储中移除
2、客户端串行执行 : 出啊性同步执行的过程,千万不要因为一个Watcher而影响整个客户端回调Watcher
3、轻量 : WatchedEvent是通知机制中最小的通知单元,只包含三部分内容 : 通知状态、时间类型、节点路径。而不会将节点的内容以通知的方式告知
客户端,而是需要客户端接收到通知之后,主动去服务端获取数据
DataTree
ConcurrentHashMap
DataNode 是由层级children的
SASL 主要应用于跨节点通信时的认证与数据加密
14、Follower请求转发
如感兴趣,点赞加关注,谢谢