ECCV2022 多目标跟踪(MOT)汇总
一、《Towards Grand Unification of Object Tracking》
作者: Bin Yan1⋆, Yi Jiang2,†, Peize Sun3, Dong Wang1,†,Zehuan Yuan2, Ping Luo3, and Huchuan Lu
School of Information and Communication Engineering, Dalian University of
Technology, China 2 ByteDance 3 The University of Hong Kong Peng Cheng Laboratory
论文链接:https://arxiv.org/pdf/2207.07078.pdf
Github: https://github.com/MasterBin-IIAU/Unicorn
1、摘要
我们提出了一种统一的方法,称为Unicorn,它可以用相同的模型参数同时解决四个跟踪问题(SOT、MOT、VOS、MOTS)。由于对象跟踪问题本身的分散定义,大多数现有的跟踪器被开发用于解决单个或部分任务,并对特定任务的特征进行过度专门化。相比之下,Unicorn提供了一个统一的解决方案,在所有跟踪任务中采用相同的input, backbone, embedding和head。第一次,我们完成了跟踪网络架构和学习范式的巨大统一。在8个跟踪数据集中,Unicorn的表现与特定任务的对手相当或更好。
2、方法

Unicorn方法简单但是效果很好,从网络设计可以看到本工作主要是统一了不同任务之间的输入,并复用了embedding特征来做sot和mot任务。
二、《Tracking Objects as Pixel-wise Distributions》
作者: Zelin Zhao1 ⋆, Ze Wu2, Yueqing Zhuang2, Boxun Li2, and Jiaya Jia1,3
The Chinese University of Hong Kong MEGVII Technology SmartMore
论文链接:https://arxiv.org/pdf/2207.05518.pdf
Github:https://github.com/dvlab-research/ECCV22-P3AFormer-Tracking-Objects-as-Pixel-wise-Distributions
1、摘要
多目标跟踪(MOT)需要通过帧来检测和关联对象。与通过检测到box或中心点进行跟踪不同,我们建议将跟踪对象作为像素级分布。我们在一个名为P3Afrorter的基于转换器的架构上实例化了这个想法,该架构具有像素级传播、预测和关联。在流信息的引导下传播像素级特征,以便在帧之间传递消息。此外,P3AForter采用元架构生成多尺度对象特征映射。在推理过程中,提出了一种基于像素级预测的像素级关联方法来通过帧恢复对象连接。P3AFrorter在MOT17基准上的MOTA为81.2%,为首个超过80%的transformer方法。
2、方法

网络结构如上。1)通过backbone相邻帧特征进行编码,获得HxWxD的特征。2)P3AFormer用Deformable DETR的上采样结构,获得了多个尺度的特征。3)通过相似性计算,将先前帧的相似特征加权到当前帧上。4)用一个transformer的结构,输出detection的结果。

匹配用的还是hungarian matching,dist的计算用的是heatpoint的位置,如文中公式(6)。感觉这篇paper的作用是提出了一个新的检测器,在tracking的创新上不是很多。
三、《Robust Multi-Object Tracking by Marginal Inference》
作者:Yifu Zhang1†, Chunyu Wang2, Xinggang Wang1, Wenjun Zeng3, and Wenyu Liu1‡
Huazhong University of Science and Technology Microsoft Research Asia Eastern Institute for Advanced Study
论文链接:https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136820020.pdf
1、摘要
视频中的多目标跟踪需要解决相邻帧中对象之间一对一分配的基本问题。大多数方法为了解决这个问题,首先丢弃特征距离大于阈值的不可能对,然后使用匈牙利算法连接对象来最小化整体距离。然而,我们发现,对于不同的视频,从Re-ID特征计算出的距离的分布可能会有显著的差异。所以没有一个单一的最优阈值允许我们安全地丢弃不可能的对。为了解决这个问题,我们提出了一种有效的方法来实时计算每一对目标的边际概率。边际概率可以看作是一个明显比原始特征距离更稳定的归一化距离。因此,我们可以对所有的视频都使用一个单一的阈值。该方法是通用的,可以应用于现有的跟踪器,以获得IDF1度量的约1个点的提升。
2、方法

本文解决了一个问题,ReID的阈值设定难的问题。文中认为对于每个场景,reid直出的特征直接用来卡阈值是比较难的,比如mot17-04要卡0.2,而mot17-09要卡0.3。本文作者提出了一种归一化的方式,能保证不同的视频序列可以用相同的阈值,以提高算法性能。计算方式是GC出一个概率来替代dist用于匈牙利匹配。
四、《ByteTrack: Multi-Object Tracking by Associating Every Detection Box》
作者:Yifu Zhang1, Peize Sun2, Yi Jiang3, Dongdong Yu3, Fucheng Weng1,Zehuan Yuan3, Ping Luo2, Wenyu Liu1, Xinggang Wang1†
1Huazhong University of Science and Technology 2The University of Hong Kong 3ByteDance Inc.
论文链接:https://arxiv.org/pdf/2110.06864.pdf
Github:https://github.com/ifzhang/ByteTrack
1、摘要
多目标跟踪(MOT)的目的是估计视频中物体的边界框和身份。大多数方法是通过关联分数高于阈值的检测盒来获得身份的。检测分数较低的物体,如被遮挡的物体,会被简单地扔掉,从而带来不可忽视的真实物体缺失和轨迹碎片化。为了解决这一问题,我们提出了一种简单、有效、通用的关联方法,通过将几乎每个检测框关联起来,而不是只将高分的检测框进行跟踪。对于低分数的检测框,我们利用它们与轨迹的相似性来恢复真实的对象,并过滤掉背景检测。当应用于9个不同的最先进的跟踪器时,我们的方法可以持续提高了IDF1分数,从1分到10分。为了提出MOT的最新性能,我们设计了一个简单而强大的跟踪器,名为字节跟踪器。这是我们第一次在MOT17测试集上实现了80.3 MOTA,77.3 IDF1和在单个V100 GPU上运行速度为33.1 HOTA。ByteTrack在MOT20、HiEve和BDD100K跟踪基准测试上也取得了最先进的性能。
2、方法


本文的做法很简单,先通过正常的匹配方式将正常的检测结果和轨迹做匹配,然后在第二部分check了下低于阈值的检测结果和未匹配成功的轨迹,如果可以匹配上的话则把这些结果捞回来。
五、《PolarMOT: How Far Can Geometric Relations Take Us in 3D Multi-Object Tracking?》
作者:Aleksandr Kim, Guillem Bras´o, Aljoˇsa Oˇsep, and Laura Leal-Taix´e
Technical University of Munich, Germany
论文链接:https://arxiv.org/pdf/2208.01957.pdf
1、摘要
大多数(3D)多目标跟踪方法都依赖于基于外观的线索来进行数据关联。相比之下,我们研究了仅通过编码三维空间中物体之间的几何关系作为数据驱动的数据关联的线索,我们可以得到多远。我们将三维检测编码为图中的节点,其中对象之间的空间和时间成对关系通过图边缘上的局部极坐标进行编码。这种表示使我们的几何关系对全局变换和平滑的轨迹变化不变,特别是在非完整运动下。这使得我们的图神经网络能够学习有效地编码时间和空间交互,并充分利用上下文和运动线索,通过将数据关联作为边缘分类来获得最终的场景解释。我们在nuScenes数据集上建立了一个新的最先进的技术,更重要的是,表明我们的方法PolarMOT在不同地点(波士顿、新加坡、卡尔斯鲁厄)和数据集(nuScenes和KITTI)上都非常好。
2、方法
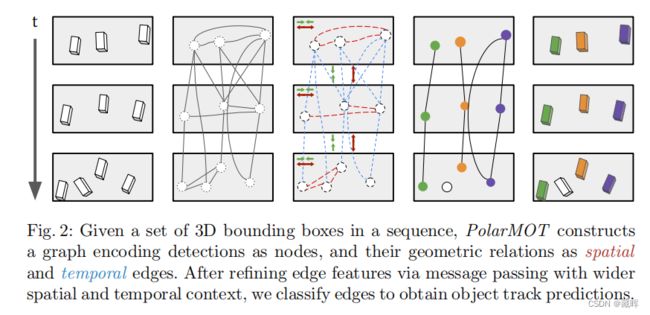
给定一组序列中的三维边界框,PolarMOT构造一个图,将检测编码为节点,它们的几何关系作为空间和时间边。通过更宽的时空上下文传递细化边缘特征,对边缘进行分类以获得目标轨迹预测。
△与MPNTrack很像,就是那篇文章用的是外观特征来构建边,这个用的是3D box。
六、《MOTCOM: The Multi-Object Tracking Dataset Complexity Metric》
作者:Malte Pedersen1, Joakim Bruslund Haurum1,2, Patrick Dendorfer3, and
Thomas B. Moeslund1,2
1 Aalborg University, Denmark2 Pioneer Center for AI, Denmark3 Technical University of Munich, Germany
论文链接:https://arxiv.org/pdf/2207.10031.pdf
1、摘要
目前还不存在一个全面的度量指标来描述多对象跟踪(MOT)序列的复杂性。这种度量指标的缺乏降低了可解释性,使数据集的比较复杂化。作为一种补救方法,我们提出了新的MOT数据集复杂性度量(MOTCOM),它是三个子度量的组合,主要来自于MOT中的关键问题:遮挡、不稳定运动和视觉相似度。MOTCOM的见解可以开启关于跟踪器性能的微妙讨论,并可能导致对为不太知名的数据集或旨在解决子问题的新贡献的更广泛的承认。
本文主要是对数据集做评测的,想提出一个指标可以综合评价数据集,且与HOTA、MOTA、IDF1等更贴合。
七、《MOTR: End-to-End Multiple-Object Tracking with Transformer》
作者:Fangao Zeng1⋆, Bin Dong1⋆, Yuang Zhang2⋆, Tiancai Wang1⋆⋆,Xiangyu Zhang1, and Yichen Wei1
1 MEGVII Technology 2 Shanghai Jiao Tong University
论文链接:https://arxiv.org/pdf/2105.03247.pdf
Github:https://github.com/megvii-research/MOTR
1、摘要
目标的时间建模是多目标跟踪(MOT)中的一个关键挑战。现有的方法通过基于运动和基于外观的相似性启发式来关联检测来跟踪。关联的后处理性质阻止了对视频序列中的时间变化的端到端利用。在本文中,我们提出了MOTR,它扩展了DETR [6],并引入了“跟踪查询”来对整个视频中的跟踪实例进行建模。跟踪查询被逐帧传输和更新,以执行随时间变化的迭代预测。我们建议使用跟踪感知的标签分配来训练跟踪查询和新对象查询。我们进一步提出了时间聚合网络和集体平均损失来增强时间关系建模。MOTR可以作为未来时间建模和基于Transformer的跟踪器研究的更有力的基线。

2、方法
MOTR的整体架构。“Enc”表示一个卷积神经网络的主干和为每一帧提取图像特征的Transformer Decoder。检测查询qd和跟踪查询qtr的连接被输入到可变形的DETR解码器(Dec)中,以产生隐藏的状态。隐藏状态用于生成新生对象和被跟踪对象的预测Yb。查询交互模块(QIM)将隐藏状态作为输入,并为下一帧生成跟踪查询。
 查询交互模块(QIM)的结构。QIM的输入是Decoder Transformer产生的隐藏状态和相应的预测分数。在推理阶段,我们保留新生的对象,并根据置信度分数删除退出的对象。时间聚合网络(TAN)增强了长程时间建模。TAN的做法是将先前的隐藏状态和当前的筛选后的tracker做一个Transformer的编码,获得时序增强后的隐藏状态。
查询交互模块(QIM)的结构。QIM的输入是Decoder Transformer产生的隐藏状态和相应的预测分数。在推理阶段,我们保留新生的对象,并根据置信度分数删除退出的对象。时间聚合网络(TAN)增强了长程时间建模。TAN的做法是将先前的隐藏状态和当前的筛选后的tracker做一个Transformer的编码,获得时序增强后的隐藏状态。
△这个框架简单高效,可以基于视频end-to-end的迭代,更贴近mot场景。但是存在一个问题,是没有考虑目标丢失后找回的情况,这可能也是其在MOT17上IDF1较低的原因。但是该方法利用了时序去做识别,相当于所有目标都上了一个类似sot的网络,在dancetrack这种目标变化较大的场景,有时序信息识别效果会有较大的提高,匹配的抗干扰性也会比其他方法好。
八、《Tracking Every Thing in the Wild》
作者:Siyuan Li, Martin Danelljan, Henghui Ding, Thomas E. Huang, Fisher Yu
Computer Vision Lab, ETH Zürich
论文链接:https://arxiv.org/pdf/2207.12978.pdf
1、摘要
当前的多类别多对象跟踪(MOT)度量标准使用类标签来对每个类评估的跟踪结果进行分组。类似地,MOT方法通常只将对象与相同的类预测关联起来。MOT中的这两种流行策略隐式地假设分类性能接近完美。然而,这与最近的大规模MOT数据集的情况相差甚远,这些数据集包含大量具有许多罕见或语义相似类别的类。因此,由此产生的不准确分类导致跟踪次优和跟踪器的基准不足。我们通过分离分类和跟踪来解决这些问题。我们引入了一种新的度量方法,跟踪万物精度(TETA),将跟踪测量分为三个子因素:定位、关联和分类,允许即使在不准确的分类下对跟踪性能进行全面的基准测试。TETA还处理了大规模跟踪数据集中具有挑战性的不完全注释问题。我们进一步介绍了一个跟踪万物跟踪器(TETer),它使用类范例匹配(CEM)来执行关联。
2、方法

这篇文章的本质思想是认为分类对单帧来说挺难的,不同类别又不能匹配在一起。不如把tracking和分类放开来做,先检测出所有目标,然后把他们关联起来。最后用丰富的时序帧信息对这个物体做一个分类,这样可以得到更准确的类别。
九、《Tracking by Associating Clips》
作者:Sanghyun Woo1, Kwanyong Park1,Seoung Wug Oh2, In So Kweon1, and Joon-Young Lee2
1 KAIST 2 Adobe Research
论文链接:https://arxiv.org/pdf/2212.10149.pdf
1、摘要
今天的Tracking-by-detection范式已成为多对象跟踪的主要方法,其工作方法是检测每一帧中的对象,然后跨帧执行数据关联。然而,它的顺序帧匹配特性从根本上遭受到视频中的中间中断,如物体遮挡、快速的摄像机运动和突然的光线变化。此外,它通常会忽略两帧之外的时间信息来进行匹配。在本文中,我们研究了一种将对象关联作为clip-wise matching的替代方法。我们的新视角将单个长视频序列视为多个短片段,然后在剪辑内部和剪辑之间执行跟踪。这种新方法的好处有两方面。首先,我们的方法对跟踪错误积累或传播具有鲁棒性,因为视频分块允许绕过中断的帧,而短片段跟踪避免了传统的容易出错的长期跟踪内存管理。第二,在剪辑匹配过程中对多帧信息进行聚合,从而产生比当前帧匹配更准确的远程轨迹关联。
对比的方法挺少了,指标应该比较低。
2、方法

文中将实例化基于剪辑的跟踪器定义剪辑内跟踪和内部跟踪。前者用了一个Transformer结构来做clip内的时序匹配,后者用iou做了clip之间的匹配。

十、《Large Scale Real-World Multi-Person Tracking》
作者:Bing Shuai, Alessandro Bergamo, Uta Buechler Andrew Berneshawi, Alyssa Boden, Joseph Tighe
AWS AI Labs
论文链接:https://arxiv.org/pdf/2211.02175.pdf
Link:https://amazon-science.github.io/tracking-dataset/personpath22.html
1、摘要
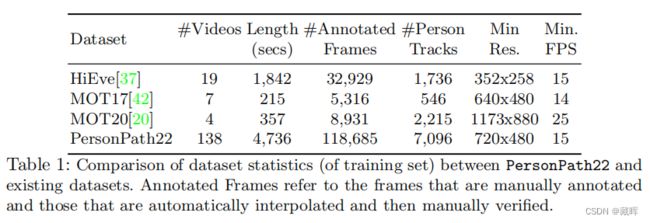
本文提出了一种新的大规模多人跟踪数据集——PersonPath22,它比目前可用的高质量多对象跟踪数据集,如MOT17、HiEve和MOT20数据集要大一个数量级。由于缺乏针对这项任务的大规模训练和测试数据,限制了社区了解其跟踪系统在各种场景和条件下的性能的能力,如人员密度的变化、正在执行的行动、天气和一天时间。PersonPath22数据集专门提供各种各样的条件,我们的注释包括丰富的元数据,这样就可以沿着这些不同的维度评估跟踪器的性能。训练数据的缺乏也限制了对跟踪系统进行端到端训练的能力。因此,性能最高的跟踪系统都依赖于在外部图像数据集上训练的强探测器。我们希望这个数据集的发布将使利用基于大规模视频的训练数据的新的研究线成为可能。
2、方法