Hive中数据库和表的操作(HSQL)
数仓管理工具Hive可以将HDFS文件中的结构化数据映射成表,
利用HSQL对表进行分析,HSQL的底层运行机制,默认是MapReduce计算,也可以替换成Spark、Tez、Flink
计算结果存储在HDFS,像Hive中的库、表、字段、表所属库、表的数据所在目录、分区等信息称为元数据,元数据默认存储在自带的derBy数据库,
也可以切换MySQL、Postgres、Oracle、MS SQL Server存储元数据,对应的库为hive数据库实例,对应的元数据表为hive数据库实例下的表
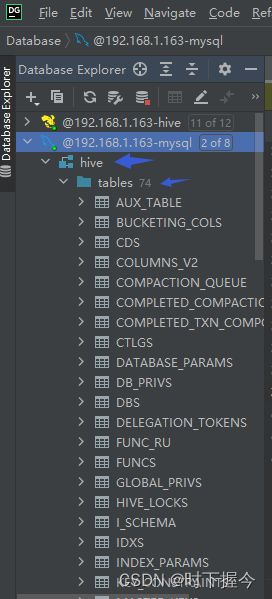
1. hive的安装方式
HiveServer1
HiveServer,也称HiveServer1,是Hive1.0.0版本之前的内置服务,允许客户端使用不同编程语言向 Hive 提交请求并返回结果。允许远程客户端使用不同编程语言向 Hive 提交请求并返回结果。但一次只能连接一个客户端,无法处理来自多个客户端的并发请求
HiveServer2
HiveServer2 是HiveServer1 的改进版,作为一种复合服务,包括基于 Thrift 的 Hive 服务(TCP或HTTP)以及用于 Web UI的 Jetty Web 服务。可以支持多客户端并发和身份认证。
metastore(元数据服务)
客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。
1.1 内嵌模式安装
- 使用内嵌的Derby数据库来存储元数据
- 数据库和Metastore服务都嵌入在主Hive Server进程中
- 一次只能一个客户端连接
- 不同路径启动hive,每一个hive拥有一套自己的元数据,无法共享
1.2 本地模式
- 采用外部数据库来存储元数据,目前支持的数据库有:MySQL、Postgres、Oracle、MS SQL Server
- Metastore服务嵌入在Hive Server进程中
- 每启动一次hive服务,都内置启动了一个metastore
- hive-site.xml中 hive.metastore.uris为空

1.3 远程模式
- 采用外部数据库来存储元数据
- 单独起metastore服务
- metastore服务和hive运行在不同进程
- hive.metastore.uris指定metastore服务运行的机器ip和端口

2. 外部表与内部表
未加 external修饰的表是内部表,数据默认存储位置:
由参数指定 hive.metastore.warehouse.dir
2.1 创建数据库
默认位置:/user/hive/warehouse
create database myhive;
2.2 删除数据库
-- 删除空数据库
drop database myhive ;
--删除的数据库里边有表,则必须加 cascade关键字
drop database myhive cascade;
2.3 映射文件夹
指定数据库对象(数据库实例、表)的映射文件夹,
也是 内部表、外部表(创建时不指定location的情况) 的数据存储位置
-- 指定内部表的数据存储位置
create database if not exists myhive location '/myhive';
2.4 创建内部表
use myhive;
create table t_covid(
dt string comment '日期',
country string comment '县',
state string comment '州',
country_code string comment '县编码',
cases int comment '确诊人数',
deaths int comment '死亡人数'
) comment '美国新冠数据'
row format delimited fields terminated by ',' -- 字段之间的分隔符
2.5 加载本地数据
加载hive服务部署主机的磁盘数据到内部表
load data local inpath '/export/data/covid.dat' into table t_covid;
将本主机文件/export/data/covid.dat 复制 一份到内部表数据存储位置
2.6 加载HDFS数据
加载分布式文件系统中的数据到内部表
hadoop dfs -put /export/testdata/covid1.dat /data/
load data inpath '/data' into table t_covid;
将分布式文件系统目录/data下的数据 剪切 一份到内部表数据存储位置
2.8 创建外部表
指定external关键字创建外部表
drop table if exists t_covid;
create external table t_covid(
dt string comment '日期' ,
country string comment '县',
state string comment '州',
country_code string comment '县编码',
cases int comment '确诊人数',
deaths int comment '死亡任务'
)comment '美国新冠数据'
row format delimited fields terminated by ',' -- 自定字段之间的分隔符
location '/input/data' --可选项,指定数据存储位置,默认存储在数据库的映射文件夹中
2.9 表类型判断
desc formatted tablename
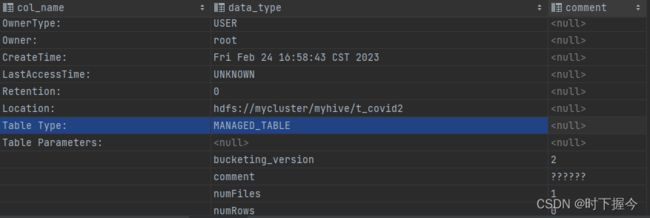
MANAGED_TABLE 内部表
EXTERNAL_TABLE 外部表
2.10 内部表与外部表的区别
当删除内部表时,元数据和表数据一起删除;
当删除外部表时,只删除元数据(映射信息),不删表数据.(元数据存储在数据库,表数据存储在HDFS),重新执行外部表建表语句,数据自动填充
外部表的表数据可以被多张外部表共享,
create external tablename()
row format delimited fields terminated by ‘,’
location ‘’; – 指向同一个表数据文件
内部表的表数据被内部表独占
3. 分区表和分桶表
分区,即对一个表数据文件按特征分到多个文件夹下存储,查询时可指定分区查找,避免全文件扫描
3.1 静态分区表
手动建立分区的文件夹,根据数据特征,手动把文件拆分到多个文件夹
create table p_covid(
dt_value string,
country string,
state string,
country_code string,
cases int,
deaths int
)
partitioned by (year string,month string,day string) -- 指定分区字段,字段名任意
row format delimited fields terminated by ',';
load data local inpath '/export/testdata/covid1.dat' into table p_covid partition (year='2023',month='02',day = '22');
load data local inpath '/export/testdata/covid2.dat' into table p_covid partition (year='2023',month='02',day = '23');
load data local inpath '/export/testdata/covid3.dat' into table p_covid partition (year='2023',month='02',day = '24');
对应查询语句:指定分区字段查询
select * from p_covid where year='2023' and month='02' and day='22';
查询结果

数据文件:




-- 手动添加分区
alter table p_covid add partition (year='2023',month='02',day = '25');
-- 查看分区文件夹信息
show partitions p_covid;
3.2 动态分区表
hive根据数据本身的特点,自动创建文件夹,自动把文件拆分成多份分到文件夹
- 开启动态分区功能
-- 开启动态分区的功能
set hive.exec.dynamic.partition=true;
-- 设置非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
- 动态分区,需要把文件映射成一张普通表,借助普通表完成动态分区表的建立
-- 建立普通表并加载本地数据
create table covid(
dt string comment '日期' ,
country string comment '县',
state string comment '州',
country_code string comment '县编码',
cases int comment '确诊人数',
deaths int comment '死亡任务'
) comment '美国疫情数据表'
row format delimited fields terminated by ',';
load data local inpath '/export/testdata/covid1.dat' overwrite into table covid ;
load data local inpath '/export/testdata/covid2.dat' overwrite into table covid ;
- 按年、月、日建立多级分区文件夹
-- 建立动态分区表,借助中间表完成数据初始化
create table d_covid(
country string,
state string,
country_code string,
cases int,
deaths int
)
partitioned by (year string,months string,day string)
row format delimited fields terminated by ',';
-- 2021-01-28
insert overwrite table d_covid
select country,state,country_code,cases,deaths,substring(dt_value,1,4) ,substring(dt_value,6,2),substring(dt_value,9,2) from p_covid;
- 查看表数据

3.3 分桶表
分桶,即将一个分区文件夹下的表数据文件,进一步拆分成多个比较小的文件,一个桶对应一个文件,这样做的目的时提高小表的JOIN效率,和用于小表的抽样
- 开启分桶功能
set hive.enforce.bucketing=true;
- 借助普通表covid,完成分桶表的建立和初始化
create table t_covid_bucket
(
dt_value string ,
country string ,
state string ,
country_code string ,
cases int ,
deaths int
)
clustered by(country_code) into 5 buckets
row format delimited fields terminated by ',';
insert overwrite table t_covid_bucket
select * from covid cluster by(country_code);
分桶机制:对字段 country_code的值取Hash值,再对桶数取模
,一个桶对应一个文件

3.4 分区分桶表
即先建立分区表,再在分区表的基础上建立分桶表
-- 建立分区分桶表
drop table if exists p_c_covid;
create table p_c_covid(
country string,
state string,
country_code string,
cases int,
deaths int
)
partitioned by (year string,months string,day string)
clustered by (country_code) into 3 buckets
row format delimited fields terminated by ',';
-- 借助普通表covid,完成分区分桶表的初始化
insert overwrite table p_c_covid
select country,state,country_code,cases,deaths,substring(dt,1,4) ,substring(dt,6,2),substring(dt,9,2) from covid;
表数据文件:
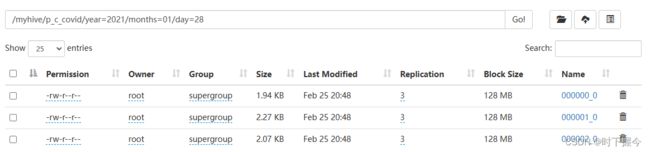
3.5 分区表和分桶表的区别
- 分区表是将一个文件拆分到多个文件夹,分桶表是将一个分区文件夹下的文件拆分成多个比较小的文件
- 一张表既可以是分区表也可以是分桶表
- Hive分区 和 MR中的分区是两个不同计算框架中的概念
4. 表的修改
4.1 表重命名
alter table t_covid_bucket rename to covid_bucket;
4.2 查询表结构
DESC FORMATTED t_covid_bucket1;
DESC t_covid_bucket1;
4.3 添加列
alter table covid add columns (testcolumn string);
4.4 更新列
alter table covid change column testcolumn ctest string;
4.4 删除列
重新定义列及类型,排除要删除的列,例如要删除c列
alter table covid replace columns ( a sting,b string, c int);
alter table covid replace columns ( a sting,b string);
4.4 删除表
drop table if exists t_covid_bucket1
4.5 清空表数据
只清除内部表数据
truncate table t_covid_bucket1;
delete t_covid_bucket1;
5. 数据加载方式
5.1 insert into
insert into covid
values(‘2021-01-28’,‘Autauga’,‘Alabama’,‘01001’,5554,69),
(‘2021-01-28’,‘Baldwin’,‘Alabama’,‘01003’,17779,225),
(‘2021-01-28’,‘Barbour’,‘Alabama’,‘01005’,1920,40);
values后面有3个语句,底层启动3个JOB任务
5.2 create … as
复制一张表的表结构及表数据
create table covid1
as select dt , country,state,country_code,cases,deaths from covid;
5.3 直接上传数据文件
表数据文件直接上传到数据库映射文件,默认: /user/hive/warehouse
hadoop dfs -put 表数据文件 /user/hive/warehouse/xxxx.db/xxx
5.4 load
加载本地磁盘文件
load data local inpath ‘表数据文件路径’ [overwrite] into table xxxx
load data inpath ‘表数据文件路径’ [overwrite] into table xxxx
5.5 insert…select
借助中间表
insert into xxx select * from temp;
insert overwrite table xxxx select * from temp;
5.6 location
HDFS先有数据,后有表 ,建表时使用location关键字
create external table t_covid2(
dt string comment ‘日期’ ,
country string comment ‘县’,
state string comment ‘州’,
country_code string comment ‘县编码’,
cases int comment ‘确诊人数’,
deaths int comment ‘死亡任务’
)comment ‘美国新冠数据’
row format delimited fields terminated by ‘,’ – 自定字段之间的分隔符
location ‘/input/data’;
5.7 第三方工具
Kettel、Sqoop
6. 数据导出方式
6.1 写出到本地
insert overwrite local directory ‘/export/testdat/’
– row format delimited fields terminated by ‘,’
select * from covid;
本地磁盘文件名:
/export/testdat/000000_0
/export/testdat/000001_0,
每行字段分割符,默认’\001’,可指定分割符
6.2 写出到HDFS
insert overwrite directory ‘/export/testdat/r.txt’
– row format delimited fields terminated by ‘,’
select * from covid;
6.3 写出到其它表
见 数据加载方式: 5.2 和 5.5
6.4 第三方工具
使用第三方工具(sqoop,Kettle,Datax,Presto),导出其他的存储平台(HBase、Spark、MySQL)