Fast and Accurate Detection of Unknown Tags for RFID Systems – Hash Collisions are Desirable 理解+笔记
Fast and Accurate Detection of Unknown Tags for RFID Systems – Hash Collisions are Desirable 理解+笔记+翻译
名称:快速准确地检测RFID系统中的未知标签——哈希冲突是可取的
来源:IEEE/ACM TRANSACTIONS ON NETWORKING
链接:https://ieeexplore.ieee.org/document/8948356
作者:Xiulong Liu , Sheng Chen, Jia Liu, Wenyu Qu, Fengjun Xiao, Alex X. Liu, Jiannong Cao, Jiangchuan Liu
理解文章重点内容和脉络整理
介绍
-
本文提出了CSD、GP、BGP、CSD+GP、CSD+BGP、多阅读器场景下协议的使用。
-
现实需求:(1)当贴有标签的物品在被转移到仓库之前未被扫描时,会出现未知的RFID标签,这甚至会导致严重的安全问题。(2)未登记的带标签的物品被转移到仓库,或者带标签的物品被错放在不正确的区域。(3)未知标签的存在可能会造成严重的经济损失甚至安全问题,例如,化学试剂在食品区域的错误放置会污染食品,进一步威胁人类安全。
-
问题定义:给定 k 个已知标签的集合K,其 ID 预先在服务器上可用,如果系统中未知标签的数量超过预定义的阈值 u,未知标签检测协议需要以由用户指定的检测概率 α ∈(0, 1)发现未知标签的存在。
-
之前方案的不足:(1)标签识别协议能够收集RFID系统中所有标签的ID,但它们非常耗时。(2)未知标签识别协议能够只识别未知标签ID,但不能保证检测精度。(3)现存的位置标签检测协议能够满足精度,但需要在低成本的标签上进行复杂的计算。(4)其他基于ALoha协议都非常耗时。
-
通信模型:阅读器广播参数
以初始化时隙时间帧,其中S是哈希种子,f指示即将到来的时隙帧中的时隙数。然后,每个标签使用其ID计算哈希函数c=H(ID,S)modf,并在时间帧的第c个时隙中回复。 -
检测思路:由于服务器上有已知的标签ID和所有哈希参数,因此我们可以准确预测每个已知标签所选择的时隙。预空时隙(即,没有选择任何已知标签)可用于检测未知标签,因为在其中观察到的任何响应都可以指示未知标签的存在。
-
CSD的基本思想:在实际初始化一个时间帧之前,服务器会测试大量哈希种子,以找出一个特殊的碰撞种子,这会使所有已知的标签哈希在最后N个时隙中发生碰撞。所有前导的f− N个时隙预计为预空,即有效预空时隙的比率显著增加。
-
技术挑战:
- 保证所需的检测精度。
- 减少总的检测时间。时间成本包括计算成本和通信成本。计算成本是主要是寻找碰撞种子,通信成本主要是处理帧时隙的时间
- 使CSD+BGP扩展到多阅读的场景
-
新颖点:利用碰撞时隙
关键技术:确保CSD+BGP的检测精度
关键优势:(1)只需在低成本的标签上执行简单的计算操作
(2)相较之前的方案,实现了更低的时间,更快更准
CSD
-
通信模型:上文已经提到
-
前提条件:已知标签都是已知的,数据库中存储了标签的ID。由于hash函数和种子都是已知,则可以预测每个时隙的状态。预期的时隙状态分为:预期空时隙和预期忙时隙。
-
hash函数:当输入标签ID和哈希种子S后,可以得到一个值c。不同标签的时隙选择结果可以视为独立性和随机性。
-
检测的未知标签的基本思想:如果系统中没有未知标签,则所有预空时隙最终都必须为空。相反,如果系统中存在一些未知的标签,则一些预空时隙可能会变成忙时隙,即阅读器器可能会在预空时隙中接收到意外的标签响应。这种现象可以用来断言系统中未知标签的存在。显然,预空时隙对于检测未知标签是有用的,而预忙时隙则是无用的。
-
CSD的关键思想点:一个哈希种子可以使所有已知标签在少量时隙中发生哈希碰撞,那么帧利用率可以显著提高。因为预空时隙将会变多,则用于检测位置标签可用的时隙就会变多。
-
CSD检测:使用暴力搜索方法来寻找这种碰撞种子。具体来说,我们让服务器测试大量哈希种子,直到找到一个特殊的Sc,这使得所有已知的标签哈希在最后N个时隙中发生碰撞。请注意,种子搜索过程是在服务器端执行的,然后才实际运行Aloha协议。这种散列种子被称为碰撞种子,并将实际用于初始化即将到来的时间帧。作为一个有趣的结果,所有的前f−N个时隙将是预空时隙,用于检测系统中的未知标签。通过使用阅读器观察前f-N的实际状态个时隙,我们可以确定是否发现未知标签。在监测前f− N个时隙,阅读器终止时间帧而不执行剩余的N个时隙,因为它们肯定是无用的忙时隙。(下文中,N会被设为1)
-
CSD的参数配置:$P_{CSD}(v) ≥P_{CSD}(u)≥α 根 据 这 个 不 等 式 可 以 推 出 根据这个不等式可以推出 根据这个不等式可以推出f≥N(1-α)^{-\frac{1}{u}}$,当f越大时,通信成本就会越大,因此需要设置f实现等于,便可最小化通信开销。
-
CSD的开销成本:
-
计算成本:计算成本主要是后端服务器搜找碰撞种子是时间
- K个标签被哈希到f的后N个中的概率是pc。
- λ多次哈希后仍在N中的概率约等于1-eλpc,当设置此概率为99.9%时,λ≈7/pc。
- 计算成本是 T C S D c o m p = 7 k η t C ( 1 − α ) k u T^{comp}_{CSD}=\frac{7kηt_C}{(1-α)^{\frac{k}{u}}} TCSDcomp=(1−α)uk7kηtC
-
通信成本:通信成本主要是时隙在阅读器和标签之间的交换时间
T C S D c o m m = t p + N ( 1 − α ) − 1 u − 1 ∗ t r T^{comm}_{CSD}=t_p + N(1-α)^{-\frac{1}{u}-1}*t_r TCSDcomm=tp+N(1−α)−u1−1∗tr

-
-
问题所在:上述等式表明,随着已知标签数量k的增加,CSD的时间成本呈指数增长。当k=500时,它需要大约3.8×10227年的巨大时间成本。
GP+CSD
- 为了降低计算复杂度,我们将提出组划分(GP)操作,将系统中的标签划分为n个小规模的组。
- 如何分组:【2】中的分组方案需要高性能的标签。本文的分组:
- 使用组划分(GP)协议将整个标签群逻辑地划分为n个小组。具体而言,**阅读器向所有标签广播组n的数量和随机种子s。每个标签计算i=H(ID,s)mod n以确定其组索引i,然后将获得的组索引存储在其内存中。**我们使用Gi来表示组i,即组索引等于i的标签集,其中i ∈[0,n−1].注意,组Gi可能不仅包含已知标签,还包含一些未知标签,因为未知标签(如果有)也参与组划分过程。
- 由于hash参数s和所有已知标签id都是预先可用的,因此我们可以通过在服务器端虚拟地执行组分区过程来知道每个组Gi中已知标签的特定id。(知道这些信息后,就可以对每个组中的标签进行CSD)。
- GP+CSD的检测过程:
- 进行分组。
- 检测:阅读器首先发送与组索引i集成的SELECT命令,以激活该组中的标签。相反,其他组中的标签保持沉默。然后,阅读器初始化一个大小为f的时间帧,以检测是否有任何未知标签属于该组。
- 进行CSD即可
- 前提设计:(1)N=1;(2)η和tc表示hash函数计算出结果的用时;(3)tp表示阅读器发送参数所用时间;(4)ts表示发送Select命令的时间(5)tr表示一个时隙的持续时间;(5)假设每组中的标签数平均:k/n。
- 成本开销:
- 计算成本:

- 通信成本:

- 总时间成本(串行):

- 总时间成本(流水线):

- 计算成本:
- 参数配置:
- 确保精度(配置f-时帧长度):$P_{CSD}(v) ≥P_{CSD}(u)≥α 根 据 这 个 不 等 式 可 以 推 出 根据这个不等式可以推出 根据这个不等式可以推出f≥N(1-α)^{-\frac{1}{u}}$,当f越大时,通信成本就会越大,因此需要设置f实现等于,便可最小化通信开销。(优先确保了精度达到最佳和通信成本达到最小)
- 最小化时间(配置n-分组个数):
- 假设:

- 代入格式结果可得到:

- 通过证明可以得到定理1,在定理1中,可知n取n0时,计算成本最低,同时n0公式:

- 假设:
BGP+CSD
- GP的问题:分组过程中不能平均进行分组,各组中的标签的个数不一致,不均匀。同时,实验结果明显大于理论结果。
- BGP:
- 将标签分为2n个组。
- 我们能够知道每个组中有哪些已知标签。因此,我们能够知道每个组中已知标签的数量。我们从这些2n个群中选择第i个最大群和第i个最小群,然后对它们进行逻辑合并,得到合并群Gi。
- 直观地说,这样的n个标签组应该比从GP协议获得的更平衡,因为BGP将一个大的组与一个小的组配对。
- BGP+CSD:
- 通过Select命令广播组索引x, y,使组Vx和Vy中的标签活跃,其他保持静默。
- 剩余进程与CSD相同
- BGP相较于GP分配更加均匀,BGP+CSD相较于GP+CSD更加符合理论分析。
扩展到多阅读器场景
-
现实需求:单个读卡器的询问范围有限(通常小于10米)。
-
提出问题:在多阅读器RFID系统中,如果两个或多个相邻的RFID阅读器同时查询标签,由于信号损坏,位于其重叠区域的标签无法成功接收任何命令。
-
暴力解决方案:在任意阅读器Ri上执行 CSD+BGP 时,一个直接的解决方案是使用整组已知标签 K、参数 u 和α作为协议输入。与阅读器Ri相对应的参数f和n的配置如第III-C节所述。
-
暴击解决方案所存在的问题:
在推论2中,我们证明了我们的CSD+BGP协议的时间开销与它处理的已知标签的数量成线性增加函数。如果我们简单地使用大的通用集K作为任意阅读器Ri的协议输入,它不可避免地会导致阅读器上的巨大时间开销。事实上,阅读器Ri不能覆盖所有标签,只能覆盖系统中标签的一小部分,即Ki。
-
本文解决方案:
- 阅读器向覆盖范围内的标签发送随机种子和帧长,标签收到后,进行映射,最后回复给阅读器,阅读器通过从标签的回复,可以得到一个已知标签的bloom filter。
- 后端服务器将所有标签k进行同样(种子相同)的哈希映射,映射到0位的,表示是不相关的标签,被过滤掉,剩下的就是覆盖范围内的相关标签。(存在误报,因此这个数组ki` >= ki)
- 通过标签估计协议,估算覆盖范围内的标签个数Ni。并假设Ni中的标签都映射到了bloom filter的1位。
-
执行过滤操作的时间开销:
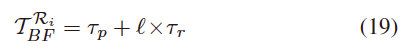
-
一个阅读器上的开销是:

-
证明在下方解释。
最后
实验+相关工作+结论+致谢
自我提升
公式推算


提出问题和解决问题

文章的新颖点

引文
[30] Jain’s fairness index
官方链接:https://en.wikipedia.org/wiki/fairness_measure (访问不了)
知乎讲解链接:https://zhuanlan.zhihu.com/p/424109114



[33] 标签估计
题目:Fast and accurate estimation of RFID tags
原文链接:https://ieeexplore.ieee.org/document/6720209
[31] 多阅读器的放置
题目:Season: Shelving interference and joint identification in large-scale RFID systems
原文链接:https://ieeexplore.ieee.org/abstract/document/5935154
[2] 其他分组
题目:Fast RFID sensory data collection: Trade-off between computation and communication costs
原文链接:https://ieeexplore.ieee.org/document/8716730
翻译
摘要
当贴着标签的物品在被转移到仓库之前未被扫描时,会出现未知的RFID标签,这甚至会导致严重的安全问题。本文研究了未知标签检测这一重要的实际问题。现有的解决方案要么需要低成本的标签来执行复杂的操作,要么需要较长的检测时间。因此我们提出了Collision-Seeking Detection (CSD) protocol,在该协议中,服务器找到一个碰撞种子,使大量已知标签在大小为 f 的时间帧的最后 N 个时隙中发生哈希碰撞。因此,所有前导的 f-N 预空时隙都可用于检测未知标签。一个具有挑战性的问题是,寻找碰撞种子的计算成本非常巨大。因此,我们提出了一个补充协议,称为Balanced Group Partition (BGP),将标签群分成n个小组。组的数量n能够在通信成本和计算成本之间进行权衡。我们还对参数进行了理论分析,以确保所需的检测精度。我们的CSD+BGP的主要优势有两个:(1)它只需要标签来执行轻量级操作,这在经典的帧时隙Aloha算法中被广泛使用。它只需要标签来执行轻量级操作,这在经典的帧时隙 Aloha 算法中被广泛使用。 因此,它更适合低成本标签。(2)检测未知标签会更高效。仿真结果表明,CSD+BGP能够保证所需的检测精度,同时在单阅读器场景中实现1.7倍的加速比,在多阅读器场景中实现3.9倍的加速比。
1 介绍
1.1 动机和问题描述
射频识别(RFID)由于其各种有前途的优势,如长扫描距离、多个物体的同时识别,以及不需要视线,有望成为未来智能仓库管理的基石技术之一。通常,仓库中的标签应该与服务器上保存的标签ID一致。然而,当未登记的标签物品被转移到仓库或标签物品被错放在不正确的区域时,无法确保这种理想的一致性。我们将其ID在服务器上不可用的标签称为未知标签。未知标签的存在可能会造成严重的经济损失甚至安全问题,例如,化学试剂误放在食品区域会污染食品,进一步威胁人类安全。显然,以一种准确且高效的方式检测未知标签的存在是非常重要的。因此,本文研究未知标签检测问题,其形式定义如下。给定 k 个已知标签的集合K,其 ID 预先在服务器上可用,如果系统中未知标签的数量超过预定义的阈值 u,未知标签检测协议需要以由用户指定的检测概率 α ∈(0, 1)发现未知标签的存在 。
1.2 现有技术的局限性
可用于解决未知标签检测问题的现有方案分为三类:标签识别协议[15]、[16]、未知标签识别协议[17]、[18]和专用未知标签检测协议[13]、[14]、[19]、[20]。接下来,我们将讨论它们的局限性:(1)标签识别协议不分青红皂白地收集RFID系统中所有标签的ID,因此我们可以通过比较收集到的标签ID集和数据库中的ID,自然地了解是否存在未知标签。虽然可行,但它们非常耗时,因为会重新收集大量已知的标签ID。(2)未知标签识别协议旨在只识别未知标签ID,而不是识别所有标签ID。虽然重新收集已知标签ID的大量时间被切断,但它们无法确保上述问题定义中描述的检测准确性。(3)最先进的未知标签检测协议,WP[14]能够满足要求的检测精度。然而,它不适用于低成本的RFID标签,因为在标签侧执行的操作比经典的帧时隙Aloha算法中使用的操作复杂得多,[15].此外,它仍然非常耗时,尤其是在多阅读器RFID系统中。
1.3 基本方案
我们提出了碰撞搜索检测(CSD)协议,该协议遵循帧时隙Aloha算法[15]。具体而言,阅读器广播参数
1.4 技术挑战和解决方案
在完成检测协议的设计之前,我们需要解决三个技术挑战。
第一个挑战是保证所需的检测精度。我们知道,在一个时帧内预空时隙的比率,即f−N / f 显著影响检测精度。因此,我们需要研究的一个关键参数是帧大小f。我们提出了充分的理论分析来证明,如果帧大小f满足 f ≥ N ( 1 − α ) − 1 u f≥N(1-α)^{-\frac{1}{u}} f≥N(1−α)−u1则所提出的CSD协议可以保证所需的检测精度。
第二个挑战是减少总检测时间。有两种类型的成本:查找碰撞种子的计算成本和执行时隙时间帧的通信成本。虽然通信成本很小,但我们发现CSD的计算成本非常巨大。为了在这两种成本之间取得平衡,我们提出了一种称为组划分的补充协议,(GP),它将标签总体划分为n个小组。CSD协议在每个小组上执行。仿真结果表明,由于概率随机性,从GP中划分的组可能具有不同的大小。这种不平衡问题使得CSD+GP的实际时间效率与理想情况相去甚远,并促使我们进一步提出称为平衡组划分(Balanced Group Partition,BGP)的增强型补充协议。
第三个挑战是使拟议的CSD+BGP协议可扩展到多阅读器场景。一个简单的解决方案是使用整个已知标签集合K作为每个阅读器的输入。然而,它的时间效率并不高,因为每个阅读器的检测时间随着它处理的已知标签数量呈指数增长。 为了提高时间效率,我们提出使用帧时隙作为布隆过滤器,以去除每个阅读器不相关的已知标签ID。
1.5 与现有相比的新颖性和优势
与之前的文献[2]、[21]–[23]不同,本文的主要创新之处在于,在解决未知标签检测问题时,故意创建哈希碰撞,以提高时间帧的利用率。关键技术深度是保证CSD+BGP的检测精度,并优化相关参数以最小化其检测时间。与之前的方案相比,我们的CSD+BGP协议的主要优势有两个:(1)它只需要标签来执行一些轻量级操作,这在经典的帧时隙Aloha算法中被广泛使用。因此,它适用于低成本标签。繁重的计算任务,例如搜索碰撞种子和优化参数,都是在服务器端执行的。(2)它非常省时。与目前最先进的检测协议相比,仿真结果表明,CSD+BGP在单阅读器情况下可实现1.7倍的加速比,在多阅读器情况下可实现3.9倍的加速比。
本文的其余部分组织如下。第二节介绍了CSD的详细设计。在第三节和第四节中,我们依次介绍了补充协议GP和BGP。在第五部分中,我们进行了广泛的模拟,以评估CSD+BGP的性能。我们将在第六节讨论相关工作。最后,第七节总结本文。
2 基本协议:CSD
在本节中,我们将首先介绍所提出的碰撞搜索检测(CSD)协议的详细设计。然后,将进行理论分析,以确保CSD协议所需的检测精度,并最小化所涉及的时间成本。
2.1 CSD协议的详细设计
建议的CSD协议遵循EPC Global C1G2标准[24]中规定的经典帧时隙Aloha(FSA)算法。具体而言,阅读器广播初始化参数< S,f >以开始时隙时间帧,其中S是散列种子,f指示即将到来的时隙时间帧中的时隙数。接收到这些参数后,每个标签都会重置其时隙计数器c∈ [0,f−1] 通过使用它的ID来计算c=H(ID,S)mod f。然后,阅读器在每个时隙结束时广播QueryRep命令,通知标签将时隙计数器c减量1。一旦标签的时隙计数器c变为0,它将用1位标签响应回复阅读器,这足以宣布它在该时隙中的存在。可以解释为,标签在第c个时隙中应答,其中c=H(ID,S)mod f。未知标签检测问题的一个自然假设是,我们预先知道正常标签(本文称为已知标签)的ID。由于散列参数也是已知的,我们可以提前预测每个时隙的状态。一把来说,时帧预期包含两种类型的时隙:没有已知标签回复的预期空时隙,有至少一个已知标签回复的预期忙时隙。
在上述过程中,标签中嵌入的哈希函数可以是MD5、SHA-1或其他轻量级哈希函数,[25]–[28].标签ID和散列种子S的组合用作散列函数的输入。例如,如果标签ID为101··1,哈希种子为110101,则哈希函数的输入将是字符串101··1110101。**散列函数通常有一个属性:“对散列输入的一个小的修改将极大地改变散列结果,以至于新的散列结果看起来与旧的散列结果不相关。”**因此,可以将不同标签的时隙选择结果视为独立性和随机性。
接下来,我们将解释如何检测系统中的未知标签。如果系统中没有未知标签,则所有预空时隙最终都必须为空。相反,如果系统中存在一些未知的标签,则一些预期空时隙可能会变成忙时隙,即阅读器可能会在预空时隙中接收到意外的标签响应。这种现象可以用来断言系统中未知标签的存在。显然,预空时隙对于检测未知标签是有用的,而预忙时隙则是无用的。现有的基于FSA的方法随机使用散列种子来初始化时隙时间帧,这导致帧利用率低。例如,如果我们利用帧大小f等于已知标签数量的正常设置,则一个时间帧中预空时隙的比率仅为36.8%[15]。如果有一个散列种子可以使所有已知标签在少量时隙中发生散列碰撞,那么帧利用率可以显著提高。使用的散列函数通常具有抗原像性的特性[29]。也就是说,如果散列函数h(·)生成了散列值z,则很难找到精确散列到z的值x。因此,给定目标时隙索引和哈希函数,我们无法直接为所有目标标签ID派生可用的哈希种子。本文使用蛮力搜索方法来寻找这种碰撞种子。具体来说,我们让服务器测试大量散列种子,直到找到一个特殊的Sc,这使得所有已知的标签散列在最后N个时隙中发生碰撞。请注意,种子搜索过程是在服务器端执行的,然后才实际运行Aloha协议。这种散列种子被称为碰撞种子,并将实际用于初始化即将到来的时间帧。作为一个有趣的结果,所有的前f−N个时隙将是预空时隙,用于检测系统中的未知标签。通过使用阅读器观察前f-N的实际状态个时隙,我们可以确定是否发现未知标签。在监测前f− N个时隙,阅读器终止时间帧而不执行剩余的N个时隙,因为它们肯定是无用的忙前时隙。表一总结了本文中的主要符号。
2.2 参数配置
在下文中,我们将研究 CSD 协议中涉及的最重要参数 f 的配置,它显着影响 CSD 的检测精度及其时间成本。正如我们所知,碰撞种子Sc对于系统中的已知标签是特殊的,这使得它们在一个时间帧的最后N个时隙中发生碰撞。但是,对于未知标签,服务器费力找到的碰撞种子 Sc 与随机挑选的哈希种子相同。因此,使用碰撞种子来初始化一个时间帧,每个未知标签都有1/f被散列到该时间帧的任意时隙的相同概率。由于在大小为 f 的时帧内有 f-N 个预空时隙,因此阅读器可以发现某个未知标签的概率为 (f-N) / f 。如果系统中存在v个未知标签,我们可以在至少发现其中一个时发现未知标签的存在。因此,相应的检测概率,表示为PCSD(v),可以如下计算。
P C S D ( v ) = 1 − [ 1 − ( f − N f ) ] v = 1 − ( N f ) v ( 1 ) P_{CSD}(v)=1-[1-(\frac{f-N}{f})]^v = 1-(\frac{N}{f})^v \qquad\qquad(1) PCSD(v)=1−[1−(ff−N)]v=1−(fN)v(1)
从式(1)中很容易看出,PCSD(v)是一个关于v的单调递增函数。因此,当,v ≥ u,我们有PCSD(v)≥ PCSD(u)。为了保证所需的检测精度,即PCSD(v)≥ α ,我们只需要确保不等式PCSD(u)= 1− (N / f)^u ≥ α。通过解这个不等式,我们得到了** f ≥ N ( 1 − α ) − 1 u f≥N(1-α)^{-\frac{1}{u}} f≥N(1−α)−u1这是确保所需检测精度的充分条件。虽然较大的帧大小f可以增加检测概率,但这意味着同时会涉及更多的时间开销。因此,为了保证所需的检测精度,同时实现CSD协议的最大时间效率,我们将帧大小f设置为其最小值,即 f = N ( 1 − α ) − 1 u f=N(1-α)^{-\frac{1}{u}} f=N(1−α)−u1。**
3 补充方案:GP
在本节中,我们首先深入分析了基本 CSD 协议的性能并指出了它的缺点,这促使我们进一步提出了 Group Partition (GP) 协议。然后,我们描述了CSD+GP协议的详细设计,其中GP是对基本CSD协议的补充。最后,我们提出了严格的理论分析来优化我们的CSD+GP协议中涉及的参数,从而保证所需的检测精度和最小化时间成本。
3.1 GP协议的动机
在第II-B节中,我们只讨论了如何保证CSD的检测精度和最小化帧大小,即最小化通信成本事实上,基本CSD协议涉及两种时间成本:(1)计算成本,记为 T C S D c o m p T^{comp}_{CSD} TCSDcomp ,是在服务器端搜索碰撞种子的时间成本;(2)通信成本,记为 T C S D c o m m T^{comm}_{CSD} TCSDcomm,是用于在阅读器和标签之间交换数据的所有时隙的总和。
接下来,我们首先计算CSD协议的计算成本。哈希种子是碰撞种子,当且仅当它使所有k个已知标签哈希在一个时间帧的最后N个时隙中发生碰撞时。并且,k个已知标签中的每一个都有概率N / f被散列到大小为f的时间帧的最后N个时隙之一。因此,对于任意散列种子,它是碰撞种子(用pc表示)的概率计算如下。
p c = ( N f ) k = ( 1 − α ) k u ( 根 据 I I − B ) ( 2 ) p_c = (\frac{N}{f})^k = (1-α)^{\frac{k}{u}} \qquad(根据II-B) \qquad\qquad (2) pc=(fN)k=(1−α)uk(根据II−B)(2)
我们让服务器测试λ个散列种子。我们至少能找到其中一个碰撞种子的概率是KaTeX parse error: Unexpected character: '' at position 25: …^{λ}≈1−e^{λp_c}̲,其中e是自然常数。在这里,我们将这个概率设置为99.9%,并计算出λ=7/p_c。( l n 0.001 = − 6.907755 ln 0.001 = -6.907755 ln0.001=−6.907755)也就是说,通过测试7/pc个哈希种子,我们可以找到至少一个碰撞种子,其概率相当高,为99.9%。请注意,如果在测试7/pc个散列种子之后仍然没有找到碰撞种子,我们将继续测试更多散列种子,直到找到碰撞种子。幸运的是,这只是一个概率很小的事件,概率只有0.1%。因此,测试散列种子的计算成本T comp CSD计算如下。
T C S D c o m p = λ ∗ k ∗ η ∗ t c = 7 k η t c ( 1 − α ) k u ( 3 ) T^{comp}_{CSD}=λ*k*η*t_c=\frac{7kηt_c}{(1-α)^{\frac{k}{u}}} \qquad\qquad (3) TCSDcomp=λ∗k∗η∗tc=(1−α)uk7kηtc(3)
其中η表示服务器计算哈希函数H(ID,S)mod f并检查哈希结果是否不小于f-N所需的时钟周期数。tc表示时钟周期的持续时间,这取决于服务器的CPU频率。
另一方面,CSD协议的通信成本可以如下计算。其中tp表示从阅读器向标签传输帧初始化参数S,f 的时隙的持续时间;和 tr表示从标签向阅读器传输1位响应的时隙的持续时间。然后,CSD的总时间(5)
T C S D c o m m = t p + ( f − N ) t r = t p + N [ ( 1 − α ) − 1 u − 1 ] ∗ t r ( 4 ) T C S D = T C S D c o m p + T C S D c o m m = 7 k η t c ( 1 − α ) k u + t p + N [ ( 1 − α ) − 1 u − 1 ] ∗ t r ( 5 ) T^{comm}_{CSD}=t_p+(f-N)t_r=t_p+N[(1-α)^{-\frac{1}{u}}-1]*t_r \qquad\qquad (4) \\ \\ T_{CSD} =T^{comp}_{CSD}+T^{comm}_{CSD} \\ =\frac{7kηt_c}{(1-α)^{\frac{k}{u}}}+t_p+N[(1-α)^{-\frac{1}{u}}-1]*t_r \qquad\qquad (5) TCSDcomm=tp+(f−N)tr=tp+N[(1−α)−u1−1]∗tr(4)TCSD=TCSDcomp+TCSDcomm=(1−α)uk7kηtc+tp+N[(1−α)−u1−1]∗tr(5)
我们从式(5)中观察到,CSD协议的总时间成本相对于N的值单调增加。因此,我们应该将N设置为其最小值,即N=1。因此,我们有f =(1−α)^−1/ u,CSD的总时间成本可以转换为如下。
T C S D = T C S D c o m p + T C S D c o m m = 7 k η t c ( 1 − α ) k u + t p + [ ( 1 − α ) − 1 u − 1 ] ∗ t r = 7 f k k η t c + t p + ( f − 1 ) ∗ t r ( 6 ) T_{CSD} =T^{comp}_{CSD}+T^{comm}_{CSD} \\ =\frac{7kηt_c}{(1-α)^{\frac{k}{u}}}+t_p+[(1-α)^{-\frac{1}{u}}-1]*t_r \\ =7f^kkηt_c+t_p+(f-1)*t_r \qquad\qquad (6) TCSD=TCSDcomp+TCSDcomm=(1−α)uk7kηtc+tp+[(1−α)−u1−1]∗tr=7fkkηtc+tp+(f−1)∗tr(6)
上述等式表明,随着已知标签数量k的增加,CSD的时间成本呈指数增长。图1中的数值结果清楚地表明了这一点。例如,当k=10时,CSD的总时间成本小于1s;然而,当k=500时,它需要大约3.8×10227年的巨大时间成本。因此,对于通常包含数千个已知标签的大规模RFID系统,基本CSD协议的可扩展性不好。注意,tp,tr,η,和tc在获得图1中的结果时使用将在第五节中规定。造成如此巨大时间开销的根本原因在于寻找碰撞种子的高计算复杂度,根据等式(3),碰撞种子计算复杂度为O(fk)。为了降低计算复杂度,我们将提出组划分(GP)操作,将系统中的标签划分为n个小规模的组。在每个小规模组上,我们可以以较低的计算成本O(fk/n)执行CSD协议。所有n个小组的总计算成本将是O(nfk/n),这仍然显著小于O(fk)。Liu等人在[2]中提出了一种方法,将标签群体划分为n个小群体。基本思路如下。服务器将已知的标签映射到一个大的一维空间,并找出n− 1在空间中选择适当的边界点,以生成n个范围。他们的期望是,每个范围内的标签数量等于平均值k/n。映射到同一范围的标签将被视为同一组中的标签。然后,阅读器广播范围参数以激活相应组中的标签。这种方法要求标签执行一些复杂的操作(例如,理解范围参数),这些操作可应用于高性能标签,例如[2]中考虑的传感器增强RFID标签。然而,本文不能借用它,因为我们专注于低成本的RFID标签。
3.2 CSD+GP协议的详细设计
在下文中,我们将描述我们的CSD+GP协议的详细设计。首先,我们使用组划分(GP)协议将整个标签群逻辑地划分为n个小组。具体而言,**阅读器向所有标签广播组n的数量和随机种子s。每个标签计算i=H(ID,s)mod n以确定其组索引i,然后将获得的组索引存储在其内存中。**我们使用Gi来表示组i,即组索引等于i的标签集,其中i ∈[0,n−1].注意,组Gi可能不仅包含已知标签,还包含一些未知标签,因为未知标签(如果有)也参与组划分过程。由于hash参数s和所有已知标签id都是预先可用的,因此我们可以通过在服务器端虚拟地执行组分区过程来知道每个组Gi中已知标签的特定id。我们用ki来表示Gi组中已知标签的数量,这显然满足 ∑ i = 0 n − 1 k i = k \sum^{n-1}_{i=0}k_i=k ∑i=0n−1ki=k。
CSD协议分别在n个标签组上执行,以检测系统中是否存在未知标签。具体来说,当在某个组Gi上执行CSD协议时,阅读器首先发送与组索引i集成的SELECT命令,以激活该组中的标签。相反,其他组中的标签保持沉默。然后,阅读器初始化一个大小为f的时间帧,以检测是否有任何未知标签属于该组。每组的详细未知标签检测过程与第II-A节相同。
接下来,我们将分别分析每个组对应的计算成本和通信成本。对于某个组Gi,服务器还需要找到一个碰撞种子,以使该组中的已知标签在大小为 f 的相应时间帧的最后一个时隙中进行哈希碰撞。与等式(2)类似,随机选取的散列种子是组Gi的期望碰撞种子的概率(用pi_c_表示)可以如下计算。 p c i = ( 1 f ) k i p_c^i=(\frac{1}{f})^{k_i} pci=(f1)ki。
其中ki是组Gi中已知标签的数量,f是时帧的大小。使用第III-A节中的分析,我们知道,在测试7/pi-c次种子后,我们可以以99.9%的高概率找到Gi群的碰撞种子。对应于组Gi的CSD的计算成本,用T comp CSD,Gi表示,,可计算如下。
T C S D , G i c o m p = 7 p c i ∗ k i ∗ η ∗ t c = 7 f k n k n η t c ( 8 ) T^{comp}_{CSD,G_i}=\frac{7}{p^i_c}*k_i*η*t_c=7f^{\frac{k}{n}}\frac{k}{n}ηt_c \qquad\qquad (8) TCSD,Gicomp=pci7∗ki∗η∗tc=7fnknkηtc(8)
在等式(8)中,ki项被k/n替换,因为每个组平均包含k/n个已知标签。因此,pi c的项被(1/f)k/n代替。
另一方面,在组Gi上执行CSD协议的通信成本不仅包括从阅读器向标签发送Select命令和帧初始化参数的时间,还包括执行f时隙时间帧的时间。因此,在标签组Gi上执行CSD协议的通信成本由T comm CSD,Gi表示,,可计算如下。
T C S D , G i c o m m = t s + t p + ( f − 1 ) t r ( 9 ) T^{comm}_{CSD,G_i}=t_s+t_p+(f-1)t_r \qquad\qquad (9) TCSD,Gicomm=ts+tp+(f−1)tr(9)
其中 ts是用于将选择命令从阅读器传输到标签的时隙长度; tp是用于将帧初始化参数从RFID阅读器传输到标签的时隙长度; tr是时间范围内每个时段的持续时间。通过联合考虑等式(8)和(9),在标签组Gi上执行CSD协议的总时间成本(表示为T Gi CSD)计算如下。
T C S D G i = T C S D , G i c o m p + T C S D , G i c o m m = 7 f k n k n η t c + t s + t p + ( f − 1 ) t r ( 10 ) T^{G_i}_{CSD}=T^{comp}_{CSD,G_i}+T^{comm}_{CSD,G_i} \\ =7f^{\frac{k}{n}}\frac{k}{n}ηt_c+t_s+t_p+(f-1)t_r \qquad\qquad (10) TCSDGi=TCSD,Gicomp+TCSD,Gicomm=7fnknkηtc+ts+tp+(f−1)tr(10)
执行CSD+GP协议的一种简单方法是在n个标签组上逐个执行CSD协议。以这种串行方式执行CSD+GP的总时间,用ts GP表示,可以如下计算。
T G P s = ∑ i = 0 n − 1 T C S D G i = ∑ i = 0 n − 1 ( T C S D , G i c o m p + T C S D , G i c o m m ) ( 11 ) T_{GP}^{s}=\sum^{n-1}_{i=0}T^{G_i}_{CSD}=\sum^{n-1}_{i=0}(T^{comp}_{CSD,G_i}+T^{comm}_{CSD,G_i}) \qquad\qquad (11) TGPs=i=0∑n−1TCSDGi=i=0∑n−1(TCSD,Gicomp+TCSD,Gicomm)(11)
受[2]的启发,我们可以以流水线方式执行CSD+GP协议。如图2所示,当执行标记组Gj的时间帧以检测该组中是否存在任何未知标记时,我们可以同时开始查找下一组Gj+1的碰撞种子,其中j ∈ [0,n− 2]. 我们使用tpgp来表示以这种流水线方式执行CSD+GP协议的总时间成本,其计算如下。
T G P p = T C S D , G 0 c o m p + ∑ j = 1 n − 1 m a x ( T C S D , g j c o m p , T C S D , G j − 1 c o m m ) + T C S D , G n − 1 c o m m ( 12 ) T^p_{GP}=T^{comp}_{CSD,G_0}+\sum^{n-1}_{j=1}max(T^{comp}_{CSD,g_j},T^{comm}_{CSD,G_{j-1}})+T^{comm}_{CSD,G_{n-1}} \qquad\qquad (12) TGPp=TCSD,G0comp+j=1∑n−1max(TCSD,gjcomp,TCSD,Gj−1comm)+TCSD,Gn−1comm(12)
在下面的内容中,我们将比较在串行模式下和在流水线模式下执行CSD+GP协议的时间成本。因此,我们使用等式。(11) (12)计算T s GP和T p GP之间的差值,如下所示。
T G P s − T G P p = ∑ j = 1 n − 1 [ T C S D , G i c o m p + T C S D , G i c o m m − m a x ( T C S D , g j c o m p , T C S D , G j − 1 c o m m ) ] T^{s}_{GP}-T^{p}_{GP}=\sum^{n-1}_{j=1}[T^{comp}_{CSD,G_i}+T^{comm}_{CSD,G_i}-max(T^{comp}_{CSD,g_j},T^{comm}_{CSD,G_{j-1}})] TGPs−TGPp=j=1∑n−1[TCSD,Gicomp+TCSD,Gicomm−max(TCSD,gjcomp,TCSD,Gj−1comm)]
我们从上面的方程中观察到,差T s GP,−tpgp总是大于0,这意味着在流水线模式下执行CSD+GP协议更具时间效率。因此,在本文的剩余部分中,建议的CSD+GP协议默认以流水线方式工作。
3.3 参数配置
组数n和使用的帧大小f在检测精度和时间效率方面显著影响CSD+GP协议的性能。因此,我们将在下文中提出严格的理论分析来优化这些参数。
3.3.1 确保检测精度
未知标签检测协议最基本的性能指标是其实际检测精度。对于任意未知标签,它将通过group partition操作分配到n个标签组中的一个Gi。对于Gi组,相应时间帧中抢占时隙的比率为f−1/f。因此,这个未知标签的概率为f−1 / f被检测。当从v个未知标签中检测到至少一个未知标签时,我们可以报告未知标签的存在。因此,我们的CSD+GP协议可以检测到系统中未知标签的存在的概率(用PGP()表示)可以计算如下。
P G P ( v ) = 1 − [ 1 − ( f − 1 f ) ] v = 1 − ( 1 f ) v ( 13 ) P_{GP}(v)=1-[1-(\frac{f-1}{f})]^v = 1-(\frac{1}{f})^v \qquad\qquad (13) PGP(v)=1−[1−(ff−1)]v=1−(f1)v(13)
我们可以从式(13)中观察到,检测概率PGP(v)是关于v的单调递增函数。因此,我们有PGP(v)≥PGP(u)when v ≥ u。为了满足PGP(v)的检测精度,我们只需要保证PGP(u)≥ α。解决这个不等式,我们仍然有 f ≥ ( 1 − α ) − 1 u f≥(1-α)^{-\frac{1}{u}} f≥(1−α)−u1,这与我们之前的分析一致。
3.3.2 最小化时间开销
从等式中很容易观察到。(8) (9)计算成本T comp CSD,Gi和通信成本T comm CSD,Gi都是关于帧大小f的单调递增函数。因此,我们可以断言,我们的CDS+GP协议的总时间开销,即等式(12)中的tpgp,也是相对于帧大小f的单调递增函数。因此,我们应该将帧大小f设置为它的最小整数值,即 f = ( 1 − α ) − 1 u f=(1-α)^{-\frac{1}{u}} f=(1−α)−u1。
根据式(8),我们知道CSD+GP协议用于寻找每个组Gi的碰撞种子的计算复杂度为O(fk/n)。为了降低计算复杂度,n应设置为相对较大的值。然后,我们的CSD+GP协议的时间成本可以近似如下。
T G P p ≈ T G P ‘ p = ∑ j = 1 n − 1 m a x ( T C S D , g j c o m p , T C S D , G j − 1 c o m m ) ( 14 ) T G P ‘ p = ( n − 1 ) ∗ m a x [ 7 f k n k n η t c , t s + t p + ( f − 1 ) t r ] = m a x [ 7 f k n k ∗ ( n − 1 ) n η t c , ( n − 1 ) [ t s + t p + ( f − 1 ) t r ] ] ( 15 ) T^{p}_{GP}≈T^{`p}_{GP}=\sum^{n-1}_{j=1}max(T^{comp}_{CSD,g_j},T^{comm}_{CSD,G_{j-1}}) \qquad\qquad (14) \\ T^{`p}_{GP}=(n-1)*max[7f^{\frac{k}{n}}\frac{k}{n}ηt_c \quad , \quad t_s+t_p+(f-1)t_r] \\ =max[7f^{\frac{k}{n}}\frac{k*(n-1)}{n}ηt_c \quad , \quad (n-1)[t_s+t_p+(f-1)t_r]] \qquad\qquad (15) TGPp≈TGP‘p=j=1∑n−1max(TCSD,gjcomp,TCSD,Gj−1comm)(14)TGP‘p=(n−1)∗max[7fnknkηtc,ts+tp+(f−1)tr]=max[7fnknk∗(n−1)ηtc,(n−1)[ts+tp+(f−1)tr]](15)
在接下来的内容中,我们提出定理1来证明,通过求解等式(16),我们可以获得使时间成本 tp GP最小的最佳组数。请注意,如果no的值不是整数,我们将使用其最近的整数。
定理1:给定已知标签数k、容差阈值u和所需检测概率α,使近似时间成本 T p GP最小化的最佳组数no应满足以下等式。
7 ( 1 − α ) − 1 u ∗ k n 0 k η t c n 0 = t c + t p + ( ( 1 − α ) − 1 u − 1 ) t r ( 16 ) \frac{7(1-α)^{-\frac{1}{u}*\frac{k}{n_0}}kηt_c}{n_0}=t_c+t_p+((1-α)^{-\frac{1}{u}}-1)t_r \qquad\qquad (16) n07(1−α)−u1∗n0kkηtc=tc+tp+((1−α)−u1−1)tr(16)
证明(软件翻译):
4 增强型补充协议:BGP
在本节中,我们将首先指出GP协议中固有的不平衡问题,这促使我们进一步提出平衡组划分(BGP)协议。然后,我们给出了CSD+BGP的详细设计,并给出了一些数值结果来说明它比CSD+GP的优势。最后,我们将CSD+BGP扩展到多阅读器RFID系统。
4.1 BGP协议的动机
在之前的GP协议中,将k个已知标签随机散列为n组。为了便于理解,在分析和优化第III-B节中CSD+GP协议的性能时,我们假设每个标签组恰好包含KN个已知标签。然而,我们从图3(a)中的模拟结果中观察到,每组中已知标签的数量差异很大。这种现象是由GP协议中的组划分过程的概率性质造成的。这种不平衡问题会导致大型组的巨大计算开销,因为计算成本相对于组中已知标记的数量呈指数增长。因此,CSD+GP的时间效率将严重恶化。图3(b)中的数值结果显示,我们的CSD+GP协议的实际时间成本剧烈波动,始终保持远大于理论值。为了更好地检测未知标签,我们提出了平衡组划分(BGP)协议,以实现组间相对平衡的标签分布。
4.2 CSD+BGP协议的详细设计
我们通过对GP协议进行一些简单但非常有效的修改,提出了BGP协议。具体来说,如果我们希望最终将标签划分为n个组,我们将首先调用GP协议将标签划分为2n个组:V0,V1…Vn,Vn+1…V2n-1。如上所述,我们能够知道每个组中有哪些已知标签。因此,我们能够知道每个组中已知标签的数量。若Vi比Vj包含更多的已知标签,则我们认为组Vi是大于Vj。对于每个i∈ [0,n−1] 我们从这些2n个组中选择第i个最大群和第i个最小群,然后对它们进行逻辑合并,得到群Gi。因此,我们得到n个逻辑组:G1,G2,··,Gn。直观地说,这样的n个标签组应该比从GP协议获得的更平衡,因为BGP将一个大的组与一个小的组配对。对于任意逻辑组Gi,我们假设它是通过合并组Vx和Vy获得的。在对组Gi执行CSD时,我们让阅读器发送一个包含组索引x和y的SELECT命令,以同时激活Vx和Vy组中的标签。因此,虚拟组Gi中的标签将像我们预期的那样参与CSD协议。
我们进行了一系列仿真,以验证所提出的BGP协议的有效性。图4(a)中的数值结果表明,n个组之间的标签分布比图3(a)中的标签分布更平衡。我们计算以下Jain公平性指数[30],以定量评估分别对应于图3(a)和图4(a)的标签分布平衡。
J = ( ∑ i = 0 n − 1 ∣ G i ∣ ) 2 n ∑ i = 0 n − 1 ∣ G i ∣ 2 ( 18 ) J=\frac{(\sum^{n-1}_{i=0}|G_i|)^2}{n\sum^{n-1}_{i=0}|G_i|^2} \qquad\qquad (18) J=n∑i=0n−1∣Gi∣2(∑i=0n−1∣Gi∣)2(18)
式(18)中J的值范围为1 / n(最坏情况)到1,(最佳案例)。如果n组是完全平衡的(即
|Gi |=k / n,对于每个i ∈ [0,n−1] ),J将达到其最大值1。我们发现,与GP相比,所提出的BGP协议可以显著地将J值从0.8936增加到0.9957。这两个J值分别对应于图3(a)和图4(a)中的标签分布。此外,图4(b)中的仿真结果表明,所提出的CSD+BGP协议的实际时间开销与理论时间开销非常匹配。也就是说,BGP协议的性能比以前的GP协议好得多。因此,我们将使用BGP协议作为基本CSD的补充,并在本文的其余部分使用CSD+BGP作为最终未知标记检测协议。
4.3 多阅读器RFID系统
一个实际的RFID应用场景(例如仓库)通常有数百甚至数千平方米。为了无缝覆盖这么大的区域,我们通常需要部署多个阅读器 R1、R2、. . . ,Rx,因为单个阅读器只有有限的询问范围(通常小于 10 米)。在多阅读器RFID系统中,如果两个或多个相邻的RFID阅读器同时查询标签,由于信号损坏,位于其重叠区域的标签无法成功接收任何命令。为了避免这种阅读器碰撞,我们需要有效地部署阅读器。由于提出了许多有效的阅读器调度方法[31]、[32],我们不会在这方面做更多的努力。在本文中,我们主要关注如何在每个阅读器上高效地执行CSD+BGP协议。在任意阅读器Ri上执行 CSD+BGP 时,一个直接的解决方案是使用整组已知标签 K、参数 u 和α作为协议输入。与阅读器Ri相对应的参数f和n的配置如第III-C节所述。在下文中,我们将首先提出一些理论分析,指出这种简单解决方案的不足。然后,我们将使用bloom filter技术提出一种更高效的解决方案,用于在多阅读器RFID系统中执行CSD+BGP。
在推论2中,我们证明了我们的CSD+BGP协议的时间开销与它处理的已知标签的数量成线性增加函数。如果我们简单地使用大的通用集K作为任意阅读器Ri的协议输入,它不可避免地会导致阅读器上的巨大时间开销。事实上,阅读器Ri不能覆盖所有标签,只能覆盖系统中标签的一小部分,即Ki。我们让阅读器Ri执行一个时隙时间帧,并将监控的时间帧用作bloom过滤器,以排除K-Ki中最不相关的已知标签,从而获得一组更小的已知标签Ki`。它满足K包含Ki`包含Ki。具体来说,我们在一开始就设置 Ki`=K。 然后,阅读器 Ri 使用任意挑选的哈希种子 S 和帧大小 F 对其询问范围内的标签执行帧时隙 Aloha 协议。 每个标签将在时隙中响应索引为 H(ID, S) mod F。 根据时隙位状态,我们可以得到一个0位的布隆过滤器,其中位0代表一个空时隙; 位 1 表示忙时隙。 这种布隆过滤器可用于确定已知标签是否在 Ri 的询问范围内。 详细情况如下。 我们为 Ki` 中的每个已知标签 ID 计算上面的哈希函数,如果标签 ID 被哈希到位 0,这肯定不在 Ri 的询问区域内,因为阅读器在该时隙中没有收到它的响应。 然后,哈希到位 0 的标签将从集合 Ki` 中删除。
我们使用Ni来表示实际上在阅读器Ri的询问区域内的标签数量,这是我们未知的。我们可以使用现有的标签基数估计协议[33],以非常小的开销(例如,大约1秒)准确地估计Ni的值。当且仅当 N i 个标签都没有选择相应的时隙时,布隆过滤器中的任意位为 0。因此,位bloom过滤器中某个位为0的概率可以计算为 ( 1 − 1 l ) N i (1-\frac{1}{l})^{N_i} (1−l1)Ni,这显然等于二进制bloom过滤器中位0的比率。对于K-Ki中每个不相关的已知标签ID,它有概率 ( 1 − 1 l ) N (1-\frac{1}{l})^{N} (1−l1)N被排除在Ki`之外。因此,集合Ki`中剩余的已知标签id的数量预计为|K |−| K− Ki |× ( 1 − 1 l ) N i (1-\frac{1}{l})^{N_i} (1−l1)Ni,它可以比通用集大小|K|小得多。直观地说,阅读器Ri的检测时间成本可以显著降低,因为我们使用了更小的已知标签集Ki`,而不是整个已知的标签集K。然而,上述bloom过滤过程并非无成本,相应的时间成本(用T Ri BF表示)计算如下。
T B F R i = t p + l ∗ t r ( 19 ) T^{R_i}_{BF}=t_p+l*t_r \qquad\qquad(19) TBFRi=tp+l∗tr(19)
另一方面,根据推论2,在阅读器Ri上执行CSD+BGP的时间成本表示为T Ri BGP,可以如下计算。
T B G P R i = Φ ( u , α ) φ ( u , α ) ∗ [ ∣ K ∣ − ∣ K − K i ∣ ∗ ( 1 − 1 l ) N i ] + Φ ( u , α ) ( 20 ) T^{R_i}_{BGP}=\frac{Φ(u,α)}{φ(u,α)}*[|K|-|K-K_i|*(1-\frac{1}{l})^{N_i}]+Φ(u,α) \qquad\qquad(20) TBGPRi=φ(u,α)Φ(u,α)∗[∣K∣−∣K−Ki∣∗(1−l1)Ni]+Φ(u,α)(20)
其中Φ(u,α)>0 和 φ(u,α)>0可以通过u和α的值直接计算。Φ(u,α) 和 φ(u,α)可以在推论2中找到。根据公式(20),很容易发现,较大的bloom过滤器长度l有助于减少在阅读器Ri上执行CSD+BGP的时间成本。然而,根据等式(19),更大的布卢姆过滤器长度l也意味着需要执行更长的时间来移除不相关的已知标签。基本上,布卢姆过滤器长度l在两种时间成本之间进行权衡,即T Ri BF和T Ri BGP。由于篇幅限制,本文中我们不研究为每个阅读器优化布卢姆过滤器长度的复杂方法。一个简单的解决方案是在可行空间中枚举布卢姆过滤器长度的可能值,以找到使每个阅读器Ri的总时间成本最小化的最佳值,即T Ri total=T Ri BF+T Ri BGP。这种简单的解决方案只需要线性计算成本。
除了最大限度地提高CSD+BGP的时间效率外,我们还需要讨论在多阅读器系统中是否仍能保证其检测精度。下面对CSD+BGP在多阅读器系统中的未知标签检测精度进行了详细的理论分析。事实上,任意未知标签应该位于阅读器的独占区域或多个阅读器共享的重叠区域。因此,该标签将至少参与一次检测过程。给定CSD+BGP协议中的帧大小f,可以检测出该未知标签的概率不小于f−1/f。如果系统中有u个未知标签,我们发现未知标签存在的概率将至少是 1 − ( 1 − f − 1 f ) u = 1 − ( 1 f ) u 1-(1-\frac{f-1}{f})^u=1-(\frac{1}{f})^u 1−(1−ff−1)u=1−(f1)u。在第III-C.2节中,框架尺寸应满足f=(1− α)− ^1/ u^ 。将f的值代入1− (1 f)u,我们发现,检测概率不小于α,在多阅读器RFID系统中,我们仍然可以确保CSD+BGP所需的检测精度。
推论2:给定容差阈值u,检测概率α,表示为TBGP的CSD+BGP协议的时间开销是相对于已知标签数k的线性增加函数,即 T B G P = Φ ( u , α ) φ ( u , α ) ∗ k + Φ ( u , α ) T_BGP=\frac{Φ(u,α)}{φ(u,α)}*k+Φ(u,α) TBGP=φ(u,α)Φ(u,α)∗k+Φ(u,α),其中Φ(u,α)和φ(u,α)可以通过u和α的值直接计算。
证明:我们从方程观察(16) k/nop 的值与 u 和 α 的值密切相关。 因此,我们将 k/nop 视为 u 和 α的函数,即 k/nop = φ(u,α),这使得等式 (16) 坚持。 共同考虑方程式 (12)(16),CSD+BGP的时间成本可以进一步变换如下。(21)中用 ( 1 − α ) − 1 u (1-α)^{-\frac{1}{u}} (1−α)−u1表示f,用k/φ(u,α)表示nop。
T B G P = [ t s + t p + ( f − 1 ) ∗ t r ] ∗ ( n o p + 1 ) ( 21 ) T B G P = [ t s + t p + ( ( 1 − α ) − 1 u − 1 ) ∗ t r ] ∗ [ k φ ( u , α ) + 1 ] ( 22 ) T_{BGP} = [t_s+t_p+(f-1)*t_r]*(n_{op}+1) \qquad\qquad(21) \\ T_{BGP} = [t_s+t_p+((1-α)^{-\frac{1}{u}}-1)*t_r]*[\frac{k}{φ(u,α)}+1] \qquad\qquad (22) TBGP=[ts+tp+(f−1)∗tr]∗(nop+1)(21)TBGP=[ts+tp+((1−α)−u1−1)∗tr]∗[φ(u,α)k+1](22)
为了实现清晰的表示,我们使用Φ(u,α)来表示复杂的表达式 t s + t p + ( ( 1 − α ) − 1 u − 1 ) ∗ t r t_s+t_p+((1-α)^{-\frac{1}{u}}-1)*t_r ts+tp+((1−α)−u1−1)∗tr。并将其代入上述等式。然后,我们可以得到这样的推论 T B G P = Φ ( u , α ) φ ( u , α ) ∗ k + Φ ( u , α ) T_{BGP}=\frac{Φ(u,α)}{φ(u,α)}*k+Φ(u,α) TBGP=φ(u,α)Φ(u,α)∗k+Φ(u,α)。
5 性能评估
在本节中,我们将首先简要描述我们将与提议的协议进行比较的基准协议。然后,将指定模拟设置。之后,我们将评估我们的协议在单阅读器和多阅读器场景中的时间效率和准确性。
5.1 基准规定
以下简要介绍了六种具有代表性的协议:
- 增强型动态帧时隙Aloha(EDFSA)[15]:这是一个众所周知的基于Aloha的标签识别方案。在EDFSA中,标签回复从时间帧中随机选择的时隙中的ID。如果时隙中只有一个标签应答,阅读器可以成功接收时隙中的标签ID。重复帧,直到识别出所有标签。
- Tree Hopping(TH)[16]:它是一种先进的基于树的标签识别方案。在TH中,阅读器估计未识别标签的基数,然后使用具有最佳长度的查询字符串来识别标签。如果标签发现查询的字符串是其ID的前缀,它将向阅读器回复其ID。如果只有一个标签回复ID,阅读器可以识别标签ID。阅读器尝试使用不同的查询字符串来识别所有标签。[16]中的关键点是如何尽可能减少传输的查询字符串的数量。
- Collect Unknown-tag (CU)[17]:它是概率未知标签识别的一种代表性方案。在CU中,阅读器初始化一个时隙时间框架以查询所有标签。在预期的空时隙中回复的标签肯定是未知标签。然后,阅读器在此类时隙的末尾发送一个特殊命令,以标记这些未知标签。重复多个帧以使标记的未知标签的比率达到所需水平。然后,调用标签识别协议来识别标记的未知标签。
- Basic Unknown tag Identification Protocol (BUIP) [18]:它是完全未知标签识别的代表性方案,即以100%的置信度识别所有未知标签。与CU不同,BUIP不仅使用预期的空时隙来标记未知的RFID标签,还使用预期的单时隙来停用已知的RFID标签。停用所有已知标签后,剩余的活动标签以及标记的标签肯定是未知标签,将由标签识别方案完全收集。
- Single Echo based Batch Authentication Plus (SEBA+) [20]:它是一种具有代表性的未知标签检测协议。阅读器初始化一个时隙时间帧,每个标签伪随机选择一定数量的时隙来回复响应。由于服务器知道所有哈希参数和已知的标签ID,因此它可以预测每个时隙的状态。如果阅读器在预期的空时隙中收到标签响应,将发现未知标签的存在。
- White Paper (WP) [14]:这是最先进的未知标签检测协议。在WP中,阅读器广播一个长且复杂的种子向量来指导标签时隙选择过程。期望向量中的种子可以使相应的时隙为空。如果阅读器收到来自时间范围的任何响应,它可以检测未知标签的存在。
5.2 仿真设置
我们主要评估了相关协议的时间效率,并验证了我们的CSD+BGP协议的实际检测精度。为了公平比较,我们对每个协议使用相同的无线通信设置,如下所示。阅读器和标签之间的无线传输速率为40Kb/s,即从标签向阅读器传输1位数据需要25us,反之亦然[20]。任何两个连续的数据传输之间都有一个等待时间302us[33]。也就是说,在阅读器和标签之间交换m位数据的时隙的持续时间应该是(25m+302)us。另一方面,在评估CSD+BGP协议的计算成本时,我们将tc设置为4.17×10−10s和η=344[27]。这里,tc是具有2.4 GHz CPU的服务器的时钟周期,η是计算哈希函数并在服务器上检查结果所需的时钟周期数。因为CU和BUIP旨在准确识别所有未知标签的ID。为了他们的利益,我们只模拟他们标记未知标签的过程,这足以检测未知标签。收集未知标签的特定ID的时间成本也不计算在内。在[14]中,默认的假设是,所有标签,尤其是已知标签,在运行WP之前都具有相同的哈希种子集。然后,阅读器可以简单地发送一个种子索引向量(而不是详细的散列种子)来通知标签应该使用哪些种子。然而,实际上,来自不同租户的标记在内存中可能根本没有相同的哈希种子。一个简单的对策是,在运行WP之前,将同一组哈希种子动态写入所有标记的内存,然而,出于安全考虑,这可能是不允许的。因此,在执行WP时,仅将种子索引向量传输到标签在实践中可能不起作用。出于实际原因和公平比较,在模拟WP协议时,我们让阅读器发送种子向量,而不是种子索引。此外,长种子向量被分割成96位片段,并通过多个时隙传输[22]。接下来,我们将分别在单阅读器和多阅读器场景中进行仿真,以评估这些协议的性能。每组模拟重复数十次,我们报告平均结果。
5.3 单阅读器场景
我们首先考虑单个阅读器场景,其中阅读器能够覆盖成千上万的RFID标签。这样的假设是合理的,因为我们可以使用以下方法[34]显著扩展单阅读器的阅读范围。首先,我们可以使用覆盖面积更大的强大RFID天线,例如Impinj LHCP远场天线可以覆盖139平方米[35]。其次,一个阅读器可以连接多个天线以扩展其标签查询范围,例如,Impinj R420阅读器最多可以支持32个RFID天线[36]。结合使用上述对策,理论上,单个阅读器的监控面积可以扩展到4448平方米,足以覆盖数千个标签项目。下面将对协议进行并列比较。
5.3.1 时效
已知标签的数量k、未知标签的容差阈值u和所需的检测精度α,可能会显著影响相关协议的性能。因此,我们进行模拟来研究这些参数的影响。除非另有规定,否则在进行模拟时,我们使用默认设置k=10000、u=5和α=95%。
- k的影响:我们把k的值从10000改为30000。我们从图5(a)中的模拟结果中观察到,我们的CSD+BGP协议总是最快的,k值变化。例如,当k=30000时,EDFSA、TH、CU、BUIP、SEBA+和WP的执行时间分别为221.2s、102.5s、70.6s、57.2s、26.4s和12.1s。我们的CSD+BGP协议的时间开销仅为6.1s,这意味着它比最先进的WP协议实现了1.98倍的加速比。此外,每个协议的执行时间随着已知标签数量的增加而增加,因为需要处理更多的标签ID。
- u的影响:我们将u的值从5变为15。我们从图5(b)中的仿真结果中观察到,所提出的CSD+BGP协议在u值不同的情况下保持显著优于其他协议。例如,当k=5时,EDFSA、TH、CU、BUIP、SEBA+和WP的执行时间分别为72.6s、32.7s、23.6s、19.0s、8.8s和4.0s。我们的CSD+BGP协议的时间开销仅为2.0秒,这仍然意味着比最先进的WP协议快2倍。此外,EDFSA、TH、CU 和 BUIP 的执行时间随着 u 值的变化而保持稳定,而 SEBA+、WP 和我们的 CSD+BGP 协议的执行时间随着 u 值的增加而减少。 根本原因是,更大的容忍阈值 u 意味着对未知标签检测协议的要求更宽松,从而导致检测时间更短。
- α的影响:我们将α的值从0.90更改为0.99。我们从图5(c)中的模拟结果中观察到,所提出的CSD+BGP协议在不同的α值下持续是最快的。例如,当α=0.99时,EDFSA、TH、CU、BUIP、SEBA+和WP的执行时间分别为73.8s、30.0s、33.0s、19.3s、13.8s和6.3s。我们的CSD+BGP协议的时间开销仅为3.7s,这意味着比最先进的WP协议的速度快1.7倍。此外,EDFSA、TH和BUIP的执行时间随着α值的变化保持稳定,而CU、SEBA+、WP和我们的CSD+BGP协议的执行时间随着值的增加而增加。根本原因是,α的值越大,意味着对未知标签检测协议的要求越严格,从而导致检测时间越长。
5.3.2 检测精度
[14]、[20]中的作者提出了足够的理论分析,以保证专用未知标签检测协议(即SEBA+和WP)的检测精度。两篇文献的仿真结果表明,它们的协议确实能够满足未知标签检测精度的要求。因此,我们不再进行模拟来评估它们的检测精度。在这组模拟中,我们的主要目标是验证我们的CSD+BGP协议在系统中实际出现的未知标签数量不同的情况下的实际检测概率。这里,实际检测概率通过成功检测到未知标签的模拟次数与模拟总数的比率来测量。系统中真正出现的未知标签的数量,即v,从1到15不等。我们从图5(d)中的模拟结果中观察到,当v的值超过给定的容差阈值u=5时,CSD+BGP的实际检测概率始终大于所需的检测概率α。这意味着我们的CSD+BGP协议能够满足单阅读器RFID系统所需的检测精度。
5.4 多阅读器场景
为了无缝地覆盖大型监控区域,我们需要部署多个重叠的阅读器。在本节中,我们将评估多阅读器RFID系统中相关协议的性能。如图6(a)所示,我们在网格中部署了5×5个RFID阅读器,以覆盖30m×30m的区域。由于遮挡和多径的影响,阅读器沿不同角度的探测距离可能不一致,并假定遵循正态分布Nor(5m,0.25m)。也就是说,我们假设每个阅读器的探测距离的平均值为5米,但标准方差为0.25米。多个阅读器的部署不可避免地会引发阅读器协作问题。也就是说,如果附近的两个阅读器同时探测位于其重叠区域的标签,这些标签将无法正确接收来自阅读器的任何命令。为了避免阅读器碰撞问题,几项研究工作[31],,[32],[37]被提出来研究最优的阅读器调度策略。由于阅读器调度策略不是本文的重点,我们只使用了一种类似于Colorwave方案的贪婪方法[37]。具体来说,我们给出了一个距离阈值D,以指示两个阅读器是否可能碰撞。例如,如果每个阅读器的平均探测距离为5米,我们可以说距离大于D=14米的两个阅读器不会相互碰撞。我们使用一种颜色来尽可能无碰撞地标记阅读器。然后,我们使用另一种颜色来标记其余未着色阅读器中没有碰撞的阅读器。重复阅读器着色过程,直到所有阅读器都着色。显然,我们可以同时激活相同颜色的阅读器来执行查询协议,而不会出现阅读器碰撞问题。在以某种颜色对阅读器同时执行检测协议后,我们转而以另一种颜色激活阅读器,同时执行检测协议。重复此过程,直到在所有阅读器上执行未知标记检测。我们使用图6(b)所示的概率密度随机生成每个标签的位置。
5.4.1 时间效率
在这组模拟中,我们将已知标签k的数量从10000更改为100000,从而调查其对在多阅读器RFID系统中的每个协议性能的影响。我们可以从图6(c)中的模拟结果中进行两个主要观察。首先,提出的CSD+BGP协议在k值变化时总是最快的。例如,当k=100000时,EDFSA、TH、CU、BUIP、SEBA+和WP的执行时间分别为543.0s、233.7s、1648.2s、1337.9s、616.6s和282.2s。我们的CSD+BGP协议的时间开销仅为72.9秒,这意味着比现有的WP协议快3.9倍,比TH协议快3.2倍。其次,与单阅读器场景对应的仿真结果不同,CU、BUIP、SEBA+和WP的执行时间非常长,而TH协议成为第二快的协议。根本原因是,CU、BUIP、SEBA+和WP只是将所有阅读器视为一个逻辑阅读器,因此它们无法利用多个阅读器。相反,在EDFSA、TH和我们的CSD+BGP中,每个阅读器只需要处理其覆盖范围内的标签。它可以被解释为一个繁重的标签询问任务被分成多个小块,每个小块都由一个阅读器执行。因此,EDFSA、TH和CSD+BGP的执行时间可以显著缩短。
5.4.2 检测精度
在这组模拟中,我们将研究我们的CSD+BGP协议在多阅读器RFID系统中的实际检测概率。未知标签的数量从1到15不等。我们从图6(d)中的模拟结果中观察到,当v的值超过给定的容差阈值u=5时,CSD+BGP的实际检测概率远远大于所需的检测概率α。比较图5(d)和图6(d)中的模拟结果,我们发现当v正好等于u时,多阅读器RFID系统中CSD+BGP的实际检测概率远高于单阅读器RFID系统中的检测概率。根本原因是,一些未知标签可能位于两个相邻阅读器的重叠区域。因此,与仅由一个阅读器覆盖的未知标签相比,这种未知标签被检测到的几率更大。因此,在多阅读器RFID系统中,发现未知标签的存在相对容易。综上所述,提出的CSD+BGP协议也能满足多阅读器RFID系统中未知标签检测精度的要求。
6 相关工作
RFID系统中未知标签的存在可能会对经济利益甚至人身安全造成严重风险。因此,学术界做出了大量努力来解决未知的标签问题。我们将现有未知标签相关作品分为三类:未知标签识别旨在识别未知标签的确切ID;未知标签估计是对RFID系统中未知标签的基数进行估计;未知标签检测的目标是检测系统中是否存在具有预定义概率的未知标签。
6.1 未知标签识别
在某些情况下,我们需要准确识别RFID系统中未知标签的ID。然后,我们可以采取适当的对策来处理这些未知标签,例如,精确定位未知标签的位置,并将相应的标签项移出系统。他收集未知标签(CU)协议[17]是经典帧时隙aloha机制的变体。RFID阅读器在预空时隙中发送一个特殊命令,以标记未知标签。然后,标签识别协议将收集已标记的未知标签。在CU中,每一轮的时间范围内,所有已知标签都会持续竞争,从而严重影响未知标签的标记过程。为了克服这个缺点,基本未知标签识别协议(BUIP)[18]不仅使用预空时隙来标记未知RFID标签,而且还使用预单时隙来停用已知RFID标签。具体地说,如果只有一个标签在前单时隙中应答,那么这个标签应该是已知的标签,并且将被停用。因此,争夺时帧的已知标签的数量将在几个时帧后迅速减少。在[38]中,Liu等人首先提出了基于过滤的未知标签识别(FUTI)协议,以在位级别而非时隙级别标记未知标签。因此,它有望实现比CU和BUIP协议更好的时间效率。然后,他们进一步提出了一种增强的未知标签识别协议,称为交互式未知标签识别,(IFUTI),它利用交互式过滤器不仅标记未知标签,还加速识别标记未知标签的过程。从时间效率的角度来看,IFUTI协议的性能优于其他未知标签识别协议。就识别精度而言,[17]、[38]中的未知标签识别协议只能识别给定比例的未知标签,而[18]中的协议可以识别系统中的所有未知标签,可信度为100%。就可部署性而言,CU和BUIP(只需要C1G2投诉命令)比IFUTI更容易应用于COTS RFID标签。
6.2 未知标签估算
有时,用户知道RFID系统中未知标签的大致基数就足够了。例如,系统中的未知标签可能意味着刚刚搬进物流仓库的新产品。考虑到新产品的数量,经理需要为该区域分配适当数量的工人。提出了一批有效的标签基数估计协议来准确估计RFID系统中存在的标签数量。然而,他们无法告诉我们,与上一轮库存相比,有多少标签新进入了系统。为此,肖等人提出了零差分估计器(ZDE)协议[41],在该协议中,阅读器在标签清点过程中观察到的时隙时间帧被转换为二进制向量(位0表示空时隙,位1表示非空时隙)。如果系统中出现未知标记,向量中的某些位0将变成1。他们定量地建立了未知标签数量和从0到1变化的位数之间的函数关系。然后,可以通过使用状态改变的比特数来估计未知标签的数量。与使用统一哈希的ZDE不同,Gong等人提出了信息计数,(INC)[42],它在标签端使用几何哈希函数。得益于几何分布特性,与ZDE相比,INC中的帧尺寸可以显著减小。
6.3 未知标签检测
在RFID系统中频繁执行未知标签识别或估计协议通常会浪费大量时间,因为系统可能根本不包含任何未知标签。一个有效的解决方案是首先执行一个轻量级的未知标签检测协议来检测系统中是否存在未知标签。只有在检测结果为阳性时,才会调用重量级的识别或估计协议。接下来,我们将讨论现有的未知标签检测协议。如果阅读器发现空时隙变为非空时隙或预期的单时隙变为碰撞时隙,则[19]中提出的基于单回波的批量认证(SEBA)协议会发现未知标签的存在。[20]中提出的基于单回声的批量认证Plus(SEBA+)协议利用Bloom Filter(BF)技术来扩展之前的SEBA协议。在SEBA+协议中,每个标签在一个时间范围内伪随机选择h>=1个时隙(而不是单个时隙)来回复响应。在SBF-UDP[13]中,通过使用多个散列函数将已知标签散列到过滤器,在服务器端构造采样bloom过滤器BF。然后,阅读器向所有标签广播散列参数和采样bloom过滤器BF。在接收到过滤器后,每个标记还使用相同的哈希参数来计算哈希函数,并检查BF中所有对应的位是否都是1s。如果对任何相应的位进行了采样,但结果是0,则标签将自身标记为未知标记,并将此事件报告给阅读器。SBF-UDP使用随机散列种子,已知标签均匀分布在整个bloom过滤器上,这会导致较大的1位比率,导致采样bloom过滤器的效率较低。在白皮书(WP)协议[14]中,阅读器广播种子向量V以指导标签的通信。具体而言,向量中指定的种子数等于后续时间帧的大小f。根据构造种子向量的规则,如果使用种子V[i],则不会将已知标签散列到第i个时隙。在实际执行查询标签的时间帧时,WP 协议要求标签可以在第 i 个时隙中响应当且仅当 H(ID, V[i]) mod f = i。显然,已知的标签在时帧内根本不会响应。如果阅读器收到任何响应,就会发现未知标签的存在。因此,所有时隙都是预空时隙,可用于检测未知标签。WP[14]中固有的默认假设是,系统中的所有标签(甚至包括未知标记)都具有相同的哈希种子集。因此,为了节省时间,阅读器只需要发送一个种子索引向量。然而,假设所有标签,尤其是未知标签都具有相同的哈希种子集是不合理的,因为未知标签通常属于多租户仓库中的其他用户。
7 结论
本文研究了未知标签检测这一重要的实际问题,并做出了以下主要贡献。首先,我们提出了碰撞搜索检测,(CSD)协议。与以前试图避免哈希碰撞的工作不同,提出的CSD协议故意创建哈希碰撞以提高帧利用率。其次,我们提出了一种称为组划分的补充协议,(GP)协议有效地降低了CSD的计算成本,另一个增强的补充协议称为平衡组划分(BGP)协议进一步解决了GP中的不平衡问题。第三,我们使用bloom filter技术使CSD+BGP可扩展到多阅读器RFID系统。最后,我们提出了充分的理论分析来优化相关参数,以保证所需的检测精度和最小化检测时间。大量仿真结果表明,我们的CSD+BGP协议能够保证所需的检测精度,同时与最先进的未知标签检测协议相比,显著缩短了检测时间。