Java集合详解
集合详解
1、集合,也可以说是容器。由两大接口派生而来,一个是collection,主要用于存储单一元素;另一个是map接口,主要用于存储键值对。
Collection接口
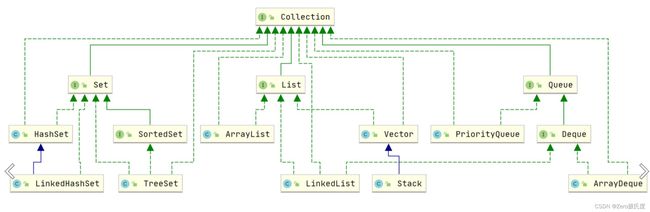
Map接口
2、集合和数组
在之前我们保存多个数据可以使用数组,但是数组有很多不足,如:
- 数组长度必须开始就要指定,一旦指定不能更改,无法扩容
- 数组保存的必须是同一类型的元素
- 使用数组进行增加和删除元素很麻烦(需要重新创建一个数组,然后将原数组的元素复制到新数组中)
集合和数组区别
共同点:其实都是存放数据的容器。
- 数组不可变,集合可变;
- 集合只能存放引用类型不能基本数据类型;
- 数组一旦创建,每个元素的类型一样,而集合里头的元素的类型可变;
- 集合重写了toString(),输出集合就是把集合的所有元素输出;数组没有重写toString(),输出数组是输出对象类型+地址哈希值;
- 数组是有序(放进去和出来的顺序一致)可重复的;集合除了list外都是无序不重复的;
- 集合通过接口创建对象(降低耦合性),数组通过类创建对象;
- 集合无序,没办法通过下标查找元素,需要用迭代器才能找到元素 iterator;数组可以通过下标查找/遍历元素;
2、List
-
list:是有序(怎么进去怎么出来)可重复;
有序的意思并不是说里面元素按照顺序排列,而是说添加进集合的顺序和输出顺序一致;
List接口下有三个实现类:
-
ArrayList:“长度可变的一维数组”;底层是一维数组,但一维数组是不可变的,所以ArrayLost实现实际是:先创建一个一维数组,当集合一旦长度要发生变化,就会继续创建新的一维数组,这样达到“可变”的效果。
-
LinkedList:底层:双向链表。
-
Vector:底层和ArrayList一样也是一维数组。区别是Vector是线程安全的,效率较低,很少使用。
-
//集合需要通过接口创建对象,降低耦合性。用接口List接收
List list = new ArrayList();
//自动装箱。相当于 list.add(new Integer(5)),存储的还是引用类型。不能存储基本类型
list.add(5);
list.add("one");
System.out.println(list);//集合复写了toString(),所以输出list地址会自动调用toString(),将集合中的每个元素都输出出来。按照输入的顺序输出,这就是有序
list.size(); //返回集合中的元素
list.remove("one");//删除集合中的某个元素
Collection的一些方法:
Collection c = new ArrayList(); //用父类接口类型变量指向子接口对象地址。父接口看不到子接口复写的方法(继承)
c.add(1);
Object o = new Object();
c.add(o);
System.out.println(c.size()); //输出集合中元素的个数
System.out.println(c);//输出集合c
System.out.println(c.contains(0));//判断集合中是否含有元素
//将集合转换成数组
Object[]objes = c.toArray();
for(int i = 0;i<objes.length-1;i++){
System.out.println(objes[i]);
}
//清空集合
c.clear();
3、Set
- Set:无序不可重复
- HashSet:底层是hash表。equal()相同,是重复的;不相同才是合法元素;
Set set = new HashSet();
set.add(10);
set.add("aa");
System.out.println(set); //无序:输出的顺序和输入顺序无关
//遍历集合中每一个元素
//方法1:迭代器
Iterator itr = set.iterator();
while(itr.hahNext()){
System.out.println(itr.next());
}
//方法2:增强for循环
for(Object o : set){
System.out.println(o);
}
//增强for循环也可以在数组中使用,底层仍然是迭代器
//iterator实质就是可以自身迭代的集合
set接口下的子接口sortedSet的实现类TreeSet:可排序的set集合
SortedSet ss = new TreeSet();//这里不能用set或者collection接收,因为父类看不到子接口重写的方法,所以Set是不具备排序的功能,只能用SortedSet接收;TreeSet实现SortedSet接口
TreeSet的数据结构是一个二叉树,被存储元素实现了Comparable接口,实现了compareTo方法,TreeSet集中在添加元素时,默认会调用被存储元素的compareTo方法完成比较!这就是为什么TreeSet可以对元素进行排序的原因。
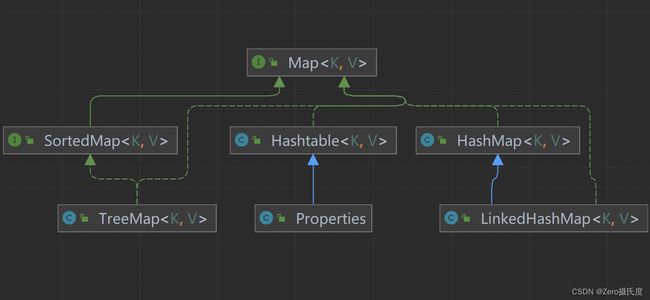
4、Map集合
1)类型:entry,map.entry
2)实现Map接口的子接口/类:
- SortedMap—>TreeMap 中的key存储元素的特点是无序不可重复,但是可以按照元素的大小顺序自动排序,SortedMap中的key等同于SortedSet
- Hashtable---->properties 属性类,也是以key-value的方式存储元素,但是key和value只能是字符串类型。
- HashMap---->LinkedHashMap
Map中的key是无序不重复的,Map集合以键值对的方式存储元素。
5、HashMap
底层是哈希表:一维数组+单向链表。复写了hashcode和equals
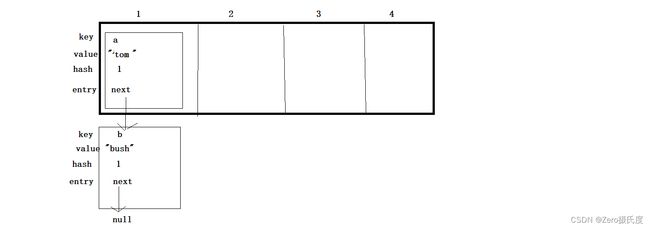
实现原理:哈希表本质是一个数组,只不过这个数组中的每一个元素又是单向链表。
-
添加/修改:
map.put(a)-----首先调用重写的hashcode()方法,得到a的哈希地址,也就是对应在一维数组的下标位置。如图,a的hashcode为1,则在一维数组第一个位置插入。
map.put(b)----首先先调用hashcode()方法,得到b的哈希地址,b.hashcode(),此时发现一维数组这个位置已经有了a,即b和a的哈希值相同,就会发生“哈希碰撞”。然后比较a和b的equals(),b.equals(a) ,如果为false,b节点就在a节点的位置下面连接,即a节点指向b节点。如果结果为true,就用新的value值替换原来的value值,即为修改操作。
-
查找:map.get(b)------先找b的hashcode值,调用hashcode()方法,确认在一维数组的哪个位置,确定位置后,跟这个位置的每个节点的key进行equals()比较,b.equals(a)==false,b.equals(b)==true,这样就找到了
System.out.println(map);因为没有重写toString,所以输出的是对象类型+哈希地址;
6、负载因子
哈希表底层实际上就是一个数组,数组的每一个元素是一个单向链表。数组的每一个位置称为桶,桶的数量称为容量,如上图哈希表的容量就是4 。哈希表中元素(也就是单向链表)的个数称为大小size;
**负载因子=size(大小)/ capacity(容量) **
- HashMap默认初始化容量为16,默认负载因子为0.75
- 负载因子过大时,代表元素个数多,则碰撞次数会加大,查找效率低,空间利用率高;负载因子过小,元素个数少,插入时碰撞次数更少,效率高,但是空间利用率低;因此默认的负载因子是0.75
- 碰撞次数小于5时采用链表,一旦超过8时就使用红黑树不再用链表了;而5~8之间是缓存带,既可以用采用链表也可以采用二叉树。
MapTest.java
import java.util.*;
public class MapTest
{
public static void main(String[] args)
{//1.创建Map集合,使用泛型
//HashMap的默认初始化容量16
//默认负载因子0.75
Map<String,String> persons=new HashMap<String,String>();
//2.存储键值对
persons.put("1000","jack");
persons.put("1001","jack");
persons.put("1002","king");
persons.put("1003","sun");
persons.put("1002","cook");
//Map中的key是无序不可重复的,和HashSet相同。所以1002-cook其实是修改1002-king的value值
//{1002=cook, 1000=jack, 1003=sun, 1001=jack}
System.out.println(persons);
//3.取得键值对(entry)的个数
System.out.println(persons.size());//4
//4.判断集合中是否包含相应的key
System.out.println(persons.containsKey("1003"));//true
//5.判断集合中是否包含相应的value
//因为Map中的key重复了,所以value采用的是覆盖,后面插入的覆盖之前的
System.out.println(persons.containsValue("king"));//false
//6.通过key取得value
System.out.println(persons.get("1002"));//cook
//7.通过key删除键值对
persons.remove("1002");
System.out.println(persons.size()); //3
//8.遍历Map:方法一:取得所有的key,输出Map的键值对,使用泛型。
//{1000=jack, 1003=sun, 1001=jack}
Set<String>keys=persons.keySet();
for(String key:keys)
{String value=persons.get(key);
System.out.println(key+"->"+value);
}
System.out.println("***********************");
//9.遍历map:方法二:取得所有的entry,输出Map的键值对。
Set entrys=persons.entrySet();
for(Object name:entrys)
{ Map.Entry entry=( Map.Entry)name;
String key=(String)entry.getKey();
String value=(String)entry.getValue();
System.out.println(key+":"+value);
}
//10.清空Map
persons.clear();
//11.判断该集合是否为空
System.out.println(persons.isEmpty());//true
System.out.println(persons);
}
}
7、遍历map
- 方法一,把map的key都set到Set集合中,然后通过迭代器,把key遍历出来,通过key去get到value,从而将key和value都遍历出来
//把map的key都set到Set集合中
Set<String>keys = persons.keySet();
//增强for循环将key遍历出来,并通过key去得到value
for(String key:keys){
String value = persons.get(key);
System.out.println(key+"->"+value);
}
- 方法二
获取所有的entry都放到set集合,然后迭代器迭代,通过entry直接get到key和value
//将entry放到set集合中,因为entry是包含key和value的
Set entrys=persons.entrySet();
//将entry遍历,从entry来获取key和value
for(Object name:entrys)
{ Map.Entry entry=( Map.Entry)name;
String key=(String)entry.getKey();
String value=(String)entry.getValue();
System.out.println(key+":"+value);
}