看 AI 如何抢救破烂文档
- 一、什么是非结构化数据
- 二、非结构化数据分析
- 三、 文档图像分析与预处理
- 修正图形偏移
- 消除摩尔纹
- 四、消除反光
- 反光原理
- Python 消除图片反光方法
- 五、 版面分析与文档还原
- 5.1 物理版面 & 逻辑版面
- 5.2 版面元素检查
- 5.3 文档还原
- 5.4 文档还原的应用
- 六、整体小结
一、什么是非结构化数据
非结构化数据是指没有固定格式和规则的数据,例如文本、图片、视频、音频等。随着信息技术的迅速发展,非结构化数据越来越多,越来越重要,主要原因如下:
社交媒体和数字化内容的增长:随着社交媒体和数字化内容的普及,人们在日常生活中产生的非结构化数据数量不断增加。例如,人们通过社交媒体发布的照片、帖子、评论等都是非结构化数据。
大数据时代的到来:随着大数据时代的到来,组织和企业需要处理和分析更多的数据以实现商业目标,而非结构化数据往往包含有用的信息,可以为组织带来新的机会和价值。
人工智能和机器学习的发展:人工智能和机器学习需要大量数据来进行训练和学习,而非结构化数据可以提供更多样化且更真实的数据,以帮助算法更好地理解和预测未来的趋势和行为。
人们需要更全面的数据分析:非结构化数据可以提供更完整和全面的数据分析,因为它们包含了更丰富的信息,可以帮助组织更好地理解其客户、市场和业务。
二、非结构化数据分析
结构化的数据采集,只需要 ETL(extract > transform > load)。但想要处理非结构化的数据,就非常困难了,为什么困难呢?西红柿带你看个例子。

非结构化数据采集的场景坑:
- 场景及版式多样
- 采集设备不确定性
- 用户需求多样性
- 文档图像质量退化严重
- 文字检测及版面分析困难
- 非限定条件文字识别率低
- 结构化智能理解能力差
三、 文档图像分析与预处理
接下来,西红柿将分享一个实战案例。

首先,我们拿到了左边这张图片,他有这样几个问题:弯曲、阴影、摩尔纹、不清晰,这样几个问题。肉眼看起来就很难识别,更别说机器了。
但是莫慌,我有办法,以下是详细操作步骤。
修正图形偏移

针对形变的图像,算法计算偏移量,并进行形变矫正,最后填充边缘,就得到了一张修复后的图形。
消除摩尔纹
摩尔纹由于图像采集设备(如相机)中的传感器阵列和被拍摄物体中的细节之间的干涉效应造成的。
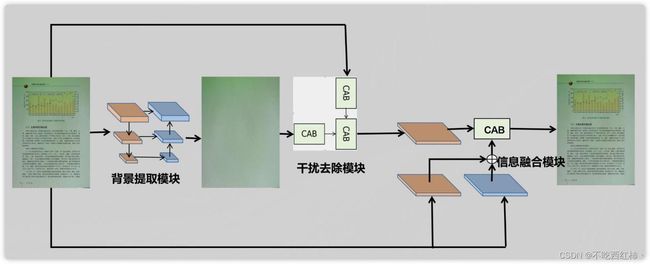
- 背景提取模块
- 干扰去除模块
- 信息融合模块
为了消除摩尔纹,可以使用以下 Python 代码:
import cv2
import numpy as np
def remove_moire(image):
# 将图像转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 使用傅里叶变换将图像转换到频域
f = np.fft.fft2(gray)
fshift = np.fft.fftshift(f)
# 创建一个高斯滤波器来过滤掉高频噪声
rows, cols = gray.shape
crow, ccol = rows // 2, cols // 2 # 中心位置
gauss_filter = np.zeros((rows, cols), np.float32)
radius = 20 # 半径越小,过滤越强烈。
for i in range(rows):
for j in range(cols):
distance = (i - crow) ** 2 + (j - ccol) ** 2
gauss_filter[i, j] = np.exp(-distance / (2 * radius ** 2))
# 将高斯滤波器应用于频域图像
filtered_fshift = fshift * gauss_filter
# 使用傅里叶逆变换将图像转换回空间域,并返回结果
filtered_f = np.fft.ifftshift(filtered_fshift)
filtered_image = np.fft.ifft2(filtered_f)
filtered_image = np.abs(filtered_image)
return filtered_image.astype(np.uint8)使用方法:
image = cv2.imread('input_tomato.jpg')
filtered_image = remove_moire(image)
cv2.imshow('Filtered Image', filtered_image)
cv2.waitKey(0)input_tomato.jpg 是待处理的图像文件名。运行代码后,将显示消除摩尔纹后的图像。
当然,以上例子,开源的基础消除摩尔纹的方法和效果展示。想要达到 合合信息在 valse2023 上的演示效果,光用开源 python 包,还不太行。
四、消除反光
反光原理
小学时候上晚自习,尤其是坐在前排的同学,可能看到的黑板是这样的,有灯的反光。

当强光源照射在光滑的平面上的时候,拍照效果也通常不太理想。还是不用慌,扫描全能王是合合信息的拳头产品之一,来学学人家是怎么做的。

消除反光的原理是通过图像增强技术来减少或者去除反光区域,主要包括以下几个步骤:
- 读取图像并将其转换为灰度图像。
- 使用高斯滤波器平滑图像以去除噪声。
- 使用 Sobel 算子检测边缘。
- 对于检测到的边缘,使用霍夫变换识别直线。
- 计算每条直线与水平线之间的夹角,并将其旋转回水平方向。
- 将旋转后的图像进行适当的裁剪,以去除可能存在的黑色边框。
Python 消除图片反光方法
开源方法,达不到合合信息(扫描全能王)的专业效果。
import cv2
import numpy as np
def remove_glare(image):
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 平滑处理
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 边缘检测
edges = cv2.Canny(blurred, 50, 200)
# 检测直线
lines = cv2.HoughLines(edges, 1, np.pi / 180, 100)
# 计算角度并旋转回水平方向
angles = []
for line in lines:
rho, theta = line[0]
angle = theta * 180 / np.pi
angles.append(angle)
median_angle = np.median(angles)
rotated = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
rotated = cv2.rotate(rotated, cv2.ROTATE_90_CLOCKWISE)
if median_angle > 0:
rotated = cv2.rotate(rotated, cv2.ROTATE_180)
# 裁剪图像
gray_rotated = cv2.cvtColor(rotated, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(gray_rotated, 1, 255, cv2.THRESH_BINARY)
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
x,y,w,h = cv2.boundingRect(contours[0])
cropped = rotated[y:y+h,x:x+w]
return cropped以上为我自学过程发现的开源 Python 方法,效果一般,非合合信息演示的那么牛。
五、 版面分析与文档还原
5.1 物理版面 & 逻辑版面
这里,西红柿先给大家介绍一个版面分析非常重要的概念。
- 物理版面是指实际存在的事物、人或组织,包括他们的位置、形状、大小等;
- 逻辑版面是指在这些物理元素之间建立起来的关系和联系,例如因果关系、逻辑关系等。
简单来说,物理版面强调的是各个元素之间的位置和属性,而逻辑版面则强调它们之间的相互作用和联系。通过将问题或主题放置在两个不同的版面上进行分析,我们可以更全面地了解它们,并从不同角度找到解决方案。
5.2 版面元素检查
要进行版面分析,首先要做的就是版面元素检测。报错文本、水印、二维码等等。
5.3 文档还原
通过前两步的版本 AI 算法分析(物理版面分析、逻辑版面分析),以及版面元素识别检查,我们就能讲文档还原了。
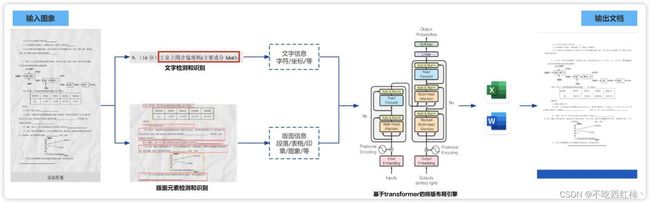
最终,我们得到了最右边的图片还原成 WORD 或者 EXCEL 版本的内容。
六、整体小结
完整的处理过程一共分为 6 个步骤: 图像输入 ——> 文档提取 ——> 手指去除 ——> 去摩尔纹 ——> 形变矫正 ——> 图像增强

以上处理过程,对算法感兴趣的小伙伴,可以自行研究。
如果想使用强大的功能抢救文档,可以在应用市场搜:扫描全能王,这个软件的核心底层原理就是上述内容,并且 CS 扫描全能王已经在 App Store 上 120 个国家的效率类免费应用,下载量排行榜位列第一。

图片来源:无锡视觉与学习青年学者研讨会 - 合合信息演讲
上海合合信息科技股份有限公司是行业领先的人工智能及大数据科技企业,致力于通过智能文字识别及商业大数据领域的 核心技术、C 端和 B 端产品以及行业解决方案为全球企业和个人用户提供创新的数字化、智能化服务。
当然,智能文档处理也不仅仅是上述内容,还有许许多多,感谢 VALSE 2023 无锡视觉与学习青年学者研讨会上,合合信息针对「语言文字识别与理解」 的精彩演讲。西红柿听完大受启发,以下配图就是大会上的 INTSIG 合合信息的分享。

智能文档处理,针对每个细分领域,其实都有很多有挑战、又有趣的事情,让我们一起探索吧~