第二篇 --【Shell】
写在开始 : 2万字长文讲 Shell ,一篇就够了, 主要用作个人复习使用!


上图引用地址 : https://zhuanlan.zhihu.com/p/47296738
Shell编程概述
Shell 本身并不是内核的一部分,它只是站在内核的基础上编写的一个应用程序,它和 QQ、迅雷 等软件没啥区别。然而 Shell 也有它的特殊性,就是开机立马启动,并呈现在用户面前;用户通过 Shell 来使用 Linux,不启动 Shell 的话,用户就没办法使用 Linux。
在计算机科学中,Shell 俗称壳(用来区别于核),是指“为使用者提供操作界面”的软件(command interpreter,命令解析器)。它类似于 DOS 下的 COMMAND.COM 和后来的 cmd.exe。它接收用户命令,然后调用相应的应用程序。
Shell 并不是简单的堆砌命令,我们还可以在 Shell 中编程,这和使用 C++、Java、Python 等常见的编程语言并没有什么两样。
Shell 虽然没有 C++、Java、Python 等强大,但也支持了基本的编程元素,例如:
- 变量、数组、字符串、注释、加减乘除、逻辑运算等概念;
- if…else 选择结构,case … in … 开关语句,for、while、until 循环;
- 函数,包括用户自定义的函数和内置函数(例如 printf、export、eval 等)。
站在这个角度讲,Shell 也是一种编程语言,它的编译器(解释器)是 Shell 这个程序。我们平时所说的 Shell,有时候是指连接用户和内核的这个程序,有时候也指 Shell 编程
Shell名词解释
Shell
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 也是一个命令行解释器,是用户和内核之间的接口。用户可以在 Shell 中输入命令,然后,它解释命令来执行所需的任务。此外,它还可以执行程序和 Shell 脚本。Shell脚本是一组命令,用户应该遵循标准语法向 Shell 写入命令。
总的来说,Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。Shell 既是一种命令语言,又是一种程序设计语言,如果要与内核打交道就必须学习 Shell 语言。
分类
Shell 是提供与内核沟通接口的命令解释器程序,但实际上 Shell 是这种解释器的统称,Linux 系统的 Shell 种类很多,包括 Bourne Shell(简称 sh)、Bourne Again Shell(简称 bash)、C Shell(简称 csh)、K shell(简称 ksh)、Shell for Root 等等。如下图:
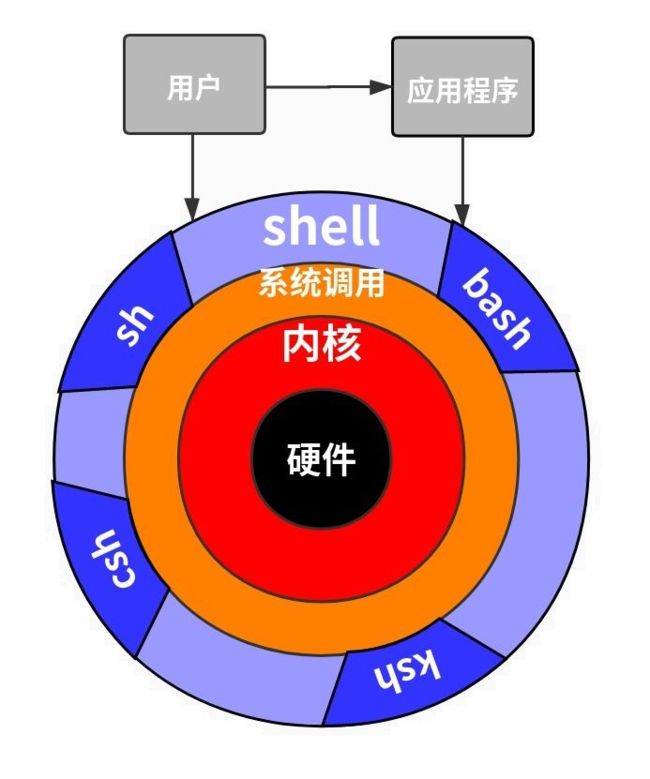
也就是说 sh 和 bash 都是 Linux 系统 Shell 的一种,其中 bash 命令是 sh 命令的超集,大多数 sh 脚本都可以在 bash 下运行。Linux 系统中预设默认使用的就是 bash。
以下命令可看OS支持哪种Shell类型:
[root@localhost ~]# cat /etc/shells
/bin/sh
/bin/bash
/usr/bin/sh
/usr/bin/bash
要想知道 bash 在操作系统中具体的位置,可通过以下命令查看:
[root@localhost ~]# which bash sh
/usr/bin/bash
/usr/bin/sh
She Bang
She Bang 是 Shell 脚本开头字符 #! 也可以叫 Sha Bang,当 Shell 文件被 Linux 系统读取时,内核会通过 #! 表示的值( 0x23, 0x21 )识别出随后的解释器路径并调用,最后再将整个脚本内容传递给解释器。由于 Shell 当中 # 字符同时表示注释,因此 Shell 解释脚本文件时会自动忽略该行。
总结: #! 就是告诉系统解释此脚本文件的 Shell 程序在哪(其后路径所指定的程序)。例如:
#!/bin/bash
echo ""hello!"
- 它应该始终在脚本的第一行。
- 在 #! 和解释器的路径之间, # 之前不应有任何空格。
echo 是 bash 中的内置命令,用于通过传递参数来显示标准输出。它是用于将文本/字符串行打印到屏幕上的最广泛使用的命令。
脚本
计算机编程中,脚本是用于适当的运行时环境的一组命令,这些命令用于自动执行任务。
而Shell 脚本,其实就是利用 Shell 的功能,编写能够直接运行的脚本文件。
第一个Shell脚本HelloWorld!
- 打开文本编辑器,新建一个文本文件,并命名为 hello.sh。
- 在 hello.sh 中输入代码:
#!/bin/bash
echo "Hello World!"
- 使用 bash 或 sh 运行脚本:
bash hello.sh
- 扩展名 sh 代表 shell,扩展名并不影响脚本执行,见名知意就好。
- **#! **是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行,即使用哪一种 Shell;后面的 /bin/bash 就是指明了解释器的具体位置。 echo 命令用于向标准输出文件(Standard Output,stdout,一般就是指显示器)输出文本。在 .sh 文件中使用命令与在终端直接输入命令的效果是一样的。
- 最后会输出结果 Hello World!
Shell脚本执行
脚本的执行并非只有 bash 和 sh ,还有 source 和 . 且它们之间还存在一些细微的差异
使用路径
格式: 相对路径/脚本.sh 或 绝对路径/脚本.sh 。
注意:脚本文件必须为可执行文件(拥有 x 权限)。
bash 或 sh
格式: bash 脚本.sh 或 sh 脚本.sh 。
source 或 .
格式: source 脚本.sh 或 . 脚本.sh
区别
bash 或 sh 执行脚本时会新开一个 bash,不同 bash 中的变量无法共享。而 source 或 . 是在同一个 bash 里面执行的,所以变量可以共享。
可以使用 export 命令,它可以将当前进程的变量传递给子进程去使用
所以,将来在配置环境变量(profile 文件)的时候,所有的变量前必须加 export
Shell基础
注释
要在 bash 中编写单行注释,必须在注释的开头使用井号 # 。
有两种方法可以在 bash 脚本中插入多行注释:
- 通过在 << COMMENT 和 COMMENT 之间加上注释,可以在 bash 脚本中编写多行注释。
- 也可以通过将注释括在 : ’ 和单引号 ’ 之间来编写多行注释。
提示:EOF 表示 End Of File,表示文件结尾,这里代指从哪开始到哪结束。EOF 只是一个名称而已,可以使用任意非关键字名称进行替换,例如 COMMENT,通常都使用 EOF。
变量
变量是将数据或有用的信息作为值存储的容器。变量的值可以更改,并且可以多次使用。变量是任何类型的数据(例如整数,浮点数,字符等)的临时存储。
定义变量时,变量名不加 $ 符号,而引用变量时则需要使用 $ 。
Shell 的变量声明规则:
- 可以包含字母,数字和下划线。
- 只能以字母和下划线开头,不能定义以任何数字开头的变量名称。
- 严格区分大小写。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用标点符号。
- 变量名称与值之间的等号 = 的两侧不能有空格。
- 不能使用 bash 里的关键字(可用 help 命令查看保留关键字)。
variable=v
variable='v'
variable="v"
# 变量的声明与赋值
name="zhangsan"
# 变量的调用
echo $name
echo ${name}
# 修改变量的值,已定义的变量,可以被重新赋值
name="lisi"
# 只读变量
url="https://www.baidu.com"
readonly url
# 测试只读变量是否可以被修改
url="https://www.google.com"
# 删除变量
unset name
# 将命令结果复制给变量
info=`ls /usr/`
info=$(ls /usr/)
调用变量时,变量名外面的花括号 {} 是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界
调用变量时,推荐给所有变量加上花括号 {} ,这是个良好的编程习惯。
Shell 也支持将命令的执行结果赋值给变量,一是把命令用反引号(位于 Esc 键的下方)包围起来;二是把命令用 $() 包围起来,区分更加明显,所以推荐使用这种方式;
类型
- 局部变量:局部变量在脚本或命令中定义,仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。例如,不同会话创建的变量无法互相访问。
- 环境变量:所有的程序,包括 Shell 启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。
- Shell 变量:Shell 变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量
引号
当希望变量存储更复杂的值时,就需要使用引号。引号用于处理带有空格字符的文本和文件名。这是因为 Bash 使用空格来确定单独的项目。在 Shell 中,变量的值可以由单引号 ’ ’ 包围,也可以由双引号 " " 包围;
单引号 ’ ’ 包围变量的值时,单引号里面是什么就输出什么,即使内容中有变量和命令(命令需要反引起来)也会把它们原样输出。这种方式比较适合定义显示纯字符串的情况,即不希望解析变量、命令等的场景。
双引号 " " 包围变量的值时,输出时会先解析里面的变量和命令,而不是把双引号中的变量名和命令原样输出。这种方式比较适合字符串中附带有变量和命令并且想将其解析后再输出的变量定义。
位置参数
运行 Shell 脚本文件时我们还可以给它传递一些参数,这些参数在脚本文件内部可以使用 $n 的形式来接收。例如,$1 表示第一个参数, $2 表示第二个参数,依次类推。
这种通过 $n 的形式来接收的参数,在 Shell 中称为位置参数。
注意:如果参数个数太多,达到或者超过了 10 个,那么就得用 ${n} 的形式来接收了,例如 10 、 {10}、 10、{23}。 {} 的作用是为了帮助解释器识别参数的边界,这跟使用变量时加 {} 是一样的效果。
特殊变量
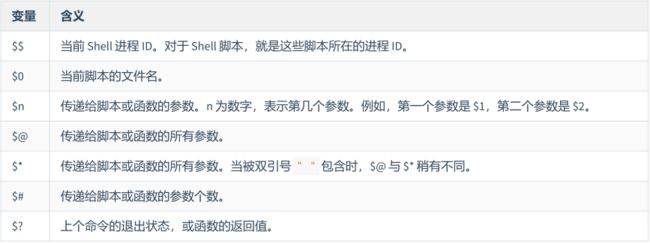
$* 和 $@ 作用都是获取传递给脚本或函数的所有参数。在没有被双引号包围时,两者没有区别,接收到的每个参数都是独立的,用空格分隔。
当被双引号包围时, $@ 与没有被双引号包围时没有变化,每个参数依然是独立的。但是 $* 被双引号包围时,会将所有参数看作一个整体。
$? 是一个特殊变量,用来获取上一个命令的退出状态,或者上一个函数的返回值。所谓退出状态,就是上一个命令执行后的返回结果。退出状态是一个数字,一般情况下,大部分命令执行成功会返回 0,失败返回 1,这和 C 语言的main() 函数是类似的。
字符串
字符串可以由单引号 ’ ’ 包围,也可以由双引号 " " 包围,也可以不用引号。
- 由单引号 ’ ’ 包围的字符串:
- 任何字符都会原样输出,在其中使用变量是无效的。
- 字符串中不能出现单引号,即使对单引号进行转义( ’ )也不行。
- 由双引号 " " 包围的字符串:
- 如果其中包含了某个变量,那么该变量会被解析(得到该变量的值),而不是原样输出。
- 字符串中可以出现双引号,只要它被转义( " )就行。
- 不被引号包围的字符串:
- 不被引号包围的字符串中出现变量时也会被解析,这一点和双引号 " " 包围的字符串一样。
- 字符串中不能出现空格,否则空格后边的字符串会作为其他变量或者命令解析。
**Shell 中获取字符串长度很简单 **
name=kaka
echo ${#name}
4
# 使用expr length 获取string长度
expr length ${str}
# awk 获取域的个数
# 如果大于10个字符长度需确认
echo "abd" |awk -F "" '{print NF}'
# 通过awk+length获取字符串长度
echo "kaka"|awk '{print length($0)}'
脚本语言, 字符串拼接:
- 在 PHP 中,使用 . 即可连接两个字符串;
- 在 JavaScript 中,使用 + 即可将两个字符串合并为一个。
- 在 Shell 中你不需要使用任何运算符,只需要将两个字符串并排放在一起就能实现拼接
#!/bin/bash
name="zhangsan"
age=18
str1=$name$age # 中间不能有空格
str2="$name $age" # 如果被双引号包围,那么中间可以有空格
str3=$name": "$age # 中间可以出现别的字符串
str4="$name: $age" # 这样写也可以
str5="${name}同学: ${age}岁" # 这个时候需要给变量名加上大括号
echo $str1
echo $str2
echo $str3
echo $str4
echo $str5
运行结果
# bash demo.sh
zhangsan18
zhangsan 18
zhangsan: 18
zhangsan: 18
zhangsan同学: 18岁
截取

数组
和其他编程语言一样,Shell 也支持数组。数组(Array)是若干数据的集合,其中的每一份数据都称为元素
(Element)。
Shell 没有限制数组的大小,理论上可以存放无限量的数据。和 C++、Java 等类似,Shell 数组元素的下标也是从 0 开始计数。
获取数组中的元素要使用下标 [index] ,下标可以是一个整数,也可以是一个结果为整数的表达式;当然,下标必须大于等于 0。遗憾的是,常用的 Bash Shell 只支持一维数组,不支持多维数组。
数组定义
在 Shell 中,用括号 () 来表示数组,数组元素之间用空格来分隔
array_name=(ele1 ele2 ele3 ... elen)
# Shell 是弱类型的,它并不要求所有数组元素的类型必须相同
arr=(20 "kaka")
# Shell 数组的长度不是固定的,定义之后还可以增加元素
nums[2]=66
# 代表在最后增加一个元素, 长度扩展到3
# Shell 还支持只给特定元素赋值
ages=([3]=24 [5]=19 [10]=12)
# 以上代码就只给第 3、5、10 个元素赋值,所以数组长度是 3
获取
# 获取数组元素的值,一般使用下面的格式:其中,array_name 是数组名,index 是下标
${array_name[index]}
# 使用 @ 或 * 可以获取数组中的所有元素
长度
# 数组长度,就是数组元素的个数。使用 @ 或 * 可以获取数组中的所有元素,然后用 # 来获取数组元素的个数
# echo ${#arr[@]}
# echo ${#ages[*]}
拼接
# 拼接数组的思路是:先利用 @ 或 * ,将数组展开成列表,然后再合并到一起
array_new=(${array1[@]} ${array2[@]})
array_new=(${array1[*]} ${array2[*]})
删除
# 使用 unset 关键字来删除数组元素 , array_name 表示数组名,index 表示数组下标。
unset array_name[index]
快捷键
ctrl+c 强制终止当前命令
ctrl+z 强制终止当前命令
ctrl+d 退出当前终端
ctrl+l 清屏,相当于clear
ctrl+a 在命令行输入命令的时候,把当前光标移动到命令行的开头
ctrl+e 在命令行输入命令的时候,把当前光标移动至命令行的结尾
ctrl+u 在命令行输入命令的时候,删除或者剪切所有命令
ctrl+k 在命令行输入命令的时候,删除或者剪切光标之后的内容
ctrl+y 在命令行粘贴ctrl+u或者ctrl+k剪切的内容
ctrl+s 暂停屏幕输出
ctrl+q 恢复屏幕输出
Linux三剑客(拓展了解⭐)
# grep 文本过滤 适合查找
# grep [选项] "搜索内容" 文件名
# sed 按脚本指令处理编辑文本文件(自动编辑文件,简化对文件反复操作) 适合修改文件
# sed [选项] '[动作]' 文件名
# 例:
sed '3c 4 abc 11 22 33' xxx.txt
# 将xxx.txt文件中第三行的内容换成“4、abc、11、22、33”
sed '2p' xxx.txt
# 查看某文档的第二行
# awk 处理文本文件,文本分析 适合取列
# awk [选项] '脚本命令' 文件名
查看日志的命令(与三剑客相关)
按照关键字找日志信息
查询日志文件里包括debug的日志行号cat -n xx.log | grep "debug"
按照日期查询
sed -n '/2023-06-16 11:11:11.070/,/2023-06-16 11:16:14.158/p'xx.log
日志太多 分页查看
cat -n xx.log |grep "debug" | more
日志太多 筛选过滤后输出到一个文件cat -n xx.log | grep "debug" >debug.txt
Shell高级
运算符
算数运算符

Shell 和其它编程语言不同,Shell 不能直接进行算数运算,必须使用数学计算命令;
expr 是一款表达式计算工具,使用它能完成表达式的求值操作
关系运算符
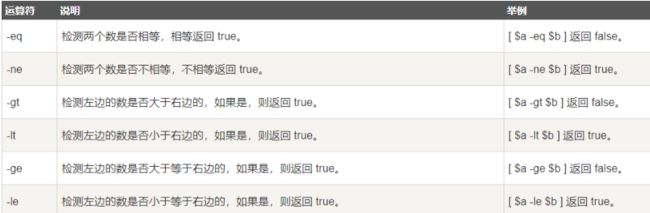
关系运算符只支持数字,不支持字符串,除非字符串的值是数字
逻辑运算符


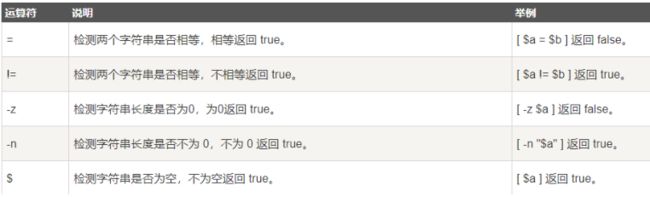
字符串运算符
文件测试运算符
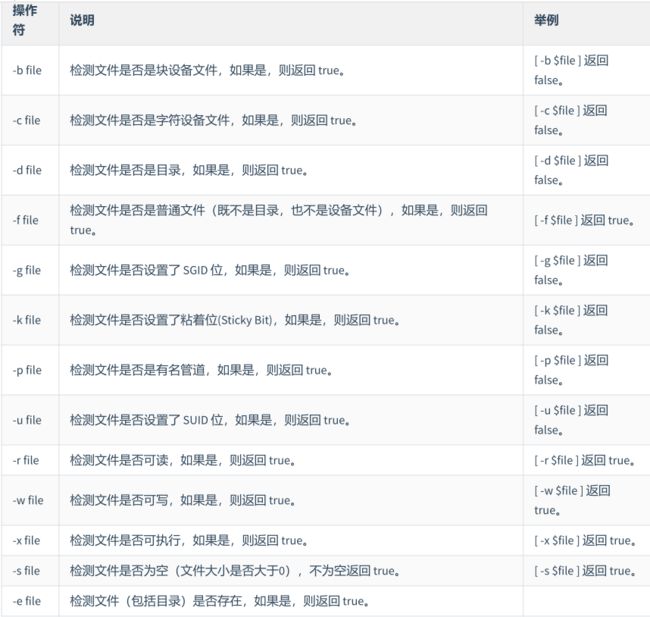
echo 打印数据
## 显示普通字符串
echo "Hello World"
## 显示转义字符
echo "\"Hello World\""
## 显示变量
name="zhangsan"
echo "$name Hello World"
## 显示换行
echo -e "OK! \n"
echo "Hello World"
## 显示不换行
echo -e "OK! \c"
echo "Hello World"
## 显示结果定向至文件
echo "Hello World" > myfile
## 原样输出字符串
echo '$name\"'
## 显示命令执行结果,推荐方式
echo $(date)
## 显示命令执行结果
echo `date`
test 命令
test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试
数字为真的情况
-eq等于 -ne不等于 -gt大于 -ge大于等于 -lt小于 -le小于等于
字符串为真 =等于 !=不等于 -z字符串(字符串长度为零则真) -n字符串
文件测试

流程控制
# if
if condition1
then
command1
elif condition2
then
command2
else
commandN
fi
# case
case 值 in
模式1)
command1
command2
...
commandN
;;
模式2)
command1
command2
...
commandN
;;
esac
循环
# for
# 当变量值在列表里,for循环即执行一次所有命令,使用变量名获取列表中的当前取值。
# 命令可为任何有效的shell命令和语句。in列表可以包含替换、字符串和文件名。
# in列表是可选的,如果不用它,for循环使用命令行的位置参数。
for var in item1 item2 ... itemN
do
command1
command2
...
commandN
done
# while while 循环用于不断执行一系列命令,也用于从输入文件中读取数据;命令通常为测试条件。
while condition
do
command
done
# break 命令允许跳出所有循环(终止执行后面的所有循环)
#!/bin/bash
while :
do
echo -n "输入 1 到 5 之间的数字:"
read aNum
case $aNum in
1|2|3|4|5)
echo "你输入的数字为 $aNum!"
;;
*)
echo "你输入的数字不是 1 到 5 之间的! 游戏结束"
break
;;
esac
done
# continue 不会跳出所有循环,仅仅跳出当前循环
#!/bin/bash
while :
do
echo -n "输入 1 到 5 之间的数字: "
read aNum
case $aNum in
1|2|3|4|5)
echo "你输入的数字为 $aNum!"
;;
*)
echo "你输入的数字不是 1 到 5 之间的!"
continue
echo "游戏结束"
;;
esac
done
函数
linux shell 可以用户定义函数,然后在shell脚本中可以随便调用。
可以带function fun() 定义,也可以直接fun() 定义,不带任何参数。
参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。
#!/bin/bash
## 第一个函数------------------------------
demoFun(){
echo "这是我的第一个 shell 函数!"
}
echo "-----函数开始执行-----"
demoFun
echo "-----函数执行完毕-----"
## 函数返回值------------------------------
funWithReturn(){
echo "这个函数会对输入的两个数字进行相加运算..."
echo "输入第一个数字: "
read aNum
echo "输入第二个数字: "
read anotherNum
echo "两个数字分别为 $aNum 和 $anotherNum !"
return $(($aNum+$anotherNum))
}
funWithReturn
# 函数返回值在调用该函数后通过 $? 来获得。
echo "输入的两个数字之和为 $? !"
## 函数参数------------------------------
funWithParam(){
echo "第一个参数为 $1 !"
echo "第二个参数为 $2 !"
echo "第十个参数为 $10 !"
echo "第十个参数为 ${10} !"
echo "第十一个参数为 ${11} !"
echo "参数总数有 $# 个!"
echo "作为一个字符串输出所有参数 $* !"
}
funWithParam 1 2 3 4 5 6 7 8 9
Shell实战
开机启动项
# 需求:服务器开机后自动与 cn.ntp.org.cn 同步时间。
touch /usr/local/scripts/auto_ntpdate.sh
echo '#!/bin/bash' >> /usr/local/scripts/auto_ntpdate.sh
echo 'yum info ntp && ntpdate cn.ntp.org.cn' >> /usr/local/scripts/auto_ntpdate.sh
chmod u+x /usr/local/scripts/auto_ntpdate.sh
echo '/usr/local/scripts/auto_ntpdate.sh' >> /etc/rc.local
chmod u+x /etc/rc.local
虚拟机初始化脚本
比如服务器集群现状如下:
node01 的 ip 是 192.168.88.101
node02 的 ip 是 192.168.88.102
node03 的 ip 是 192.168.88.103
- 首先,使用最初始的 example 虚拟机克隆出一台完整虚拟机。
- 然后,启动虚拟机并修改网络配置与主机名:
- 修改网络配置中的 IPADDR 并重启网络;
- echo node01 > /etc/hostname 修改主机名
- 接下来 sh init.sh 运行脚本。
- 最后,拍摄快照方便后期回退。
- 然后通过已经初始化完成的 node01 完整克隆出 node02 和 node03,修改它两的网络配置与主机名即可
虚拟机初始化脚本 init.sh 完整内容如下
#!/bin/bash
## -bash: ./init.sh: /bin/bash^M: bad interpreter: No such file or directory
## vim 或者 vi 的命令模式下,输入命令 set fileformat=unix 即可解决上述问题
echo -e "\e[1;44m【在 /opt 目录和 /var 目录下创建 yjx 目录,在 /usr/local 目录下创建 scripts 目录】\e[0m"
sleep 2
mkdir -p /opt/yjx /var/yjx /usr/local/scripts
echo -e "\e[1;44m【关闭并禁用 firewalld 防火墙】\e[0m"
sleep 2
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
echo -e "\e[1;44m【关闭 SELinux】\e[0m"
sleep 2
sed -i '/^SELINUX=/c SELINUX=disabled' /etc/selinux/config
echo -e "\e[1;44m【安装 wget】\e[0m"
sleep 2
yum -y install wget
echo -e "\e[1;44m【修改 yum 源为阿里源】\e[0m"
sleep 2
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all
yum makecache
echo -e "\e[1;44m【安装常用依赖】\e[0m"
sleep 2
yum -y install man man-pages telnet perl net-tools openssl-devel ntp lrzsz zip unzip vim rsync
echo -e "\e[1;44m【与中国 NTP 时间服务器 cn.ntp.org.cn 进行时间同步】\e[0m"
sleep 2
yum info ntp && ntpdate cn.ntp.org.cn
echo -e "\e[1;44m【修改 hosts 文件,添加集群环境机器 IP 与域名映射】\e[0m"
sleep 2
echo "192.168.88.100 basenode" >> /etc/hosts
echo "192.168.88.101 node01" >> /etc/hosts
echo "192.168.88.102 node02" >> /etc/hosts
echo "192.168.88.103 node03" >> /etc/hosts
echo -e "\e[1;44m【安装 JDK 并设置环境变量】\e[0m"
sleep 2
rpm -ivh jdk-8u351-linux-x64.rpm
echo 'export JAVA_HOME=/usr/java/jdk1.8.0_351-amd64' >> /etc/profile
echo 'export PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile
source /etc/profile
echo -e "\e[1;44m【安装 Tomcat】\e[0m"
sleep 2
tar -zxf apache-tomcat-9.0.72.tar.gz -C /opt/yjx/
echo -e "\e[1;44m【安装 MySQL】\e[0m"
sleep 2
rpm -e --nodeps `rpm -qa | grep mariadb`
tar -xvf mysql-8.0.18-1.el7.x86_64.rpm-bundle.tar
rpm -ivh mysql-community-common-8.0.18-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-8.0.18-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-8.0.18-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-8.0.18-1.el7.x86_64.rpm
rpm -ivh mysql-community-devel-8.0.18-1.el7.x86_64.rpm
systemctl start mysqld
systemctl enable mysqld
temppasswd=`grep "A temporary password" /var/log/mysqld.log | awk '{print $NF}'`
mysql -uroot -p$temppasswd --connect-expired-password << EOF
SET GLOBAL validate_password.policy = low;
SET GLOBAL validate_password.length = 6;
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
USE mysql;
UPDATE user SET host = '%' WHERE user = 'root';
COMMIT;
FLUSH PRIVILEGES;
EXIT
EOF
systemctl restart mysqld
echo -e "\e[1;44m【添加时间同步服务至开机启动】\e[0m"
sleep 2
touch /usr/local/scripts/auto_ntpdate.sh
echo '#!/bin/bash' >> /usr/local/scripts/auto_ntpdate.sh
echo 'yum info ntp && ntpdate cn.ntp.org.cn' >> /usr/local/scripts/auto_ntpdate.sh
chmod u+x /usr/local/scripts/auto_ntpdate.sh
echo '/usr/local/scripts/auto_ntpdate.sh' >> /etc/rc.local
chmod u+x /etc/rc.local
echo -e "\e[1;44m【删除 JDK Tomcat MySQL 安装包和虚拟机初始化脚本】\e[0m"
sleep 2
rm jdk* -rf
rm apache-tomcat* -rf
rm mysql* -rf
rm init.sh -rf
echo -e "\e[1;41m【即将关闭计算机】\e[0m"
sleep 2
shutdown -h now
服务器之间相互免密钥
生成密钥
# 分别在三台机器上运行以下命令生成密钥对:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 运行以上命令后会在 ~/.ssh/ 目录下生成一对密钥对。
[root@node01 ~]# ls ~/.ssh/
id_rsa id_rsa.pub known_hosts
取消主机名和host校验
分别在三台机器上修改 /etc/ssh/ssh_config 文件的配置,在 Host * 节点下配置以下信息:
# 严格的密钥检查 no
StrictHostKeyChecking no
# 如果不希望生成已知主机列表文件,可以将已知主机列表文件信息写入黑洞(不会再生成 known_hosts 文件)
#UserKnownHostsFile /dev/null

这样以后再也不会弹出将该主机添加到当前设备的已知主机列表中的提示信息了。
如果将已知主机列表文件信息写入了黑洞,那么远程访问时会弹出以下警告:
Warning: Permanently added 'node02,192.168.88.102' (ECDSA) to the list of known hosts.
这个警告不影响任何操作,只是看着比较碍眼。解决办法:在文件夹 ~/.ssh/ 下创建 config 文件,命令如下:
vim ~/.ssh/config
在新建的文件中写入如下内容: LogLevel=quiet 。
拷贝公钥
接下来把自己的公钥互相传递给其他主机,这个公钥文件必须放在对方主机的 ~/.ssh/authorized_keys 文件中。
可以使用命令将公钥文件自动传递过去,分别在三台机器运行以下命令:
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node01
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node02
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node03
前面已经通过脚本修改了 hosts 文件,添加了集群环境机器 IP 与域名映射,所以这里可以直接使用主机名
传输文件测试是否已免密或者使用 ssh 协议登录对方主机进行测试:
[root@localhost ~]# scp anaconda-ks.cfg root@node02:~
Warning: Permanently added 'node02,192.168.88.102' (ECDSA) to the list of known hosts.
anaconda-ks.cfg
[root@localhost ~]# ssh root@node02
Warning: Permanently added 'node02,192.168.88.102' (ECDSA) to the list of known hosts.
Last login: Sat Jun 4 21:07:25 2022 from node01
集群启动脚本
在 /usr/local/bin 目录下创建对应服务的脚本:
# vim /usr/local/bin/tomcat
tomcat脚本内容如下:
#!/bin/bash
user=$(whoami)
case $1 in
"start")
for i in node01 node02 node03
do
echo -e "\e[1;34m==================== $i Tomcat 启动 ====================\e[0m"
ssh $user@$i "/opt/yjx/apache-tomcat-9.0.72/bin/startup.sh"
done
;;
"shutdown")
for i in node01 node02 node03
do
echo -e "\e[1;34m==================== $i Tomcat 停止 ====================\e[0m"
ssh $user@$i "/opt/yjx/apache-tomcat-9.0.72/bin/shutdown.sh"
done
;;
esac
修改脚本权限为用户读写执行 rwx ,组读执行 r-x ,其他用户无权限 — :
# chmod 750 /usr/local/bin/tomcat
JPS 脚本
jps 是 JDK 提供的一个查看当前系统 Java 进程的小工具,全称是 Java Virtual Machine Process Status Tool。
- -q :忽略输出的类名,Jar 名以及传递给 main 方法的参数,只输出 PID
- -m :输出传递给 main 方法的参数,如果是内嵌的 JVM 则输出为 null
- -l :输出应用程序主类的完整包名,或者是应用程序 JAR 文件的完整路径
- -v :输出 JVM 的参数
- -V :输出通过标记文件传递给 JVM 的参数(.hotspotrc 文件,或者通过参数 -XX:Flags= 指定的文件)
- -J :传递 JVM 参数到由 javac 调用的 java 加载器中,例如:-J-Xms512m,把启动内存设置为 512M。使用 -J 选项可以非常方便的向基于 Java 开发的底层虚拟机应用程序传递参数
# 创建一个查看所有服务器 JPS 进程的脚本
[root@node01 ~]# vim /usr/local/bin/jpsall
jpsall 脚本内容如下:
#!/bin/bash
user=$(whoami)
# $#:传递给脚本或函数的参数个数
params_count=$#
# 如果没有参数,直接运行 "jps"
if [ $params_count -lt 1 ]
then
for i in node01 node02 node03
do
echo -e "\e[1;34m==================== $i ====================\e[0m"
ssh $user@$i jps
done
exit
fi
# 如果有参数,运行 "jps -参数"
for i in node01 node02 node03
do
echo -e "\e[1;34m==================== $i ====================\e[0m"
params=""
for p in $@
do
params+="$p "
done
ssh $user@$i "jps $params"
done
修改脚本权限为用户读写执行 rwx ,组读执行 r-x ,其他用户读执行 r-x :
[root@node01 ~]# chmod 755 /usr/local/bin/jpsall
文件分发脚本
在 /usr/local/bin 目录下创建 kakarsync 脚本,如下:
[root@node01 ~]# vim /usr/local/bin/kakarsync
kakarsync 脚本内容如下:
#!/bin/bash
# 获取输入参数的个数
param_count=$#
# 如果没有参数,直接退出
if [ $param_count -lt 1 ]
then
echo -e "\e[1;31mYou must pass in the file name parameter.\e[0m"
exit
fi
# 如果有参数,遍历参数(文件或目录名称)
for p in $@
do
echo -e "\e[1;34m==================== $p 开始同步 ====================\e[0m"
# basename:显示文件路径名的基本文件名,例如 /opt/bd 会显示 bd;/opt/bd/test.txt 会显示 test.txt
file_name=$(basename $p)
echo file_name=$file_name
# 获取文件的上级目录的绝对路径
# -P:如果切换的目标目录是一个符号链接,则直接切换到符号链接指向的目标目录
parent_dir=`cd -P $(dirname $p); pwd`
echo parent_dir=$parent_dir
# 获取当前用户名称
user=$(whoami)
# 循环处理文件
for i in node01 node02 node03
do
echo -e "\e[1;34m==================== $i ====================\e[0m"
rsync -av --delete $parent_dir/$file_name $user@$i:$parent_dir
done
done
修改脚本权限为用户读写执行 rwx ,组读执行 r-x ,其他用户无权限 — :
[root@node01 ~]# chmod 750 /usr/local/bin/kakarsync
测试没问题后, shutdown -h now 关机,拍摄快照方便后期回退。
写在最后 :
一周之计在周一! 下雨天, 一起加油吧,朋友们!
如果本文对您有一点点帮助,可以点赞、关注、收藏一下!