AI 杀疯了,NovelAI开源教程
大家好,我是 Jack。
如果说 2021 年是“元宇宙”的元年,那么 2022 年或许就是“AI作画”的元年。
最近,“AI作画”的作品越来越多,掀起了一股热潮。比如之前在美国科罗拉多州博览会的艺术比赛中获得了第一名的作品,就是 AI 所作。

空间歌剧院(Thétre D’opéra Spatial)

基于Midjourney生成的图像
基于Midjourney生成的图像
想像一下:输入各种风格、主题、氛围的关键词,然后 AI 就会生成符合要求的作品,仿佛艺术就是一件“触手可及”的事情。
而现在,这一切已经成为了现实。
我们一起看下现在 AI 的作画水平。
一、AI 作品
输入文字关键词描述,AI 直接生成图像作品:




输入真实场景图片,图片二次元化:


这种算法,不是检索,检索网络上已有的作品,而完全地重新创作。
二、NovelAI
国外相继也推出了各种各样的产品,比如比较出名的 NovelAI,上述的 AI 作品都是通过 NovelAI 生成的。
NovelAI 的模型训练使用了数千个网站的数十亿张图片,包括 Pixiv、Twitter、DeviantArt、Tumblr 等网站的作品。
NovelAI 是一个收费的网站:

后来 NovelAI 的模型被指泄漏了出来,采用的就是一些 stable diffusion 模型。
也就是说,我们可以本地搭建这个服务了。
三、Stable Diffusion web UI
使用 Stable Diffusion web UI 开源项目,即可搭建。
这里简单说下搭建流程:
1、下载代码:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
2、创建 Anaconda 虚拟环境:
conda create -n novelai python==3.10.6
安装 3.10.6 是因为开源代码仓库说明的是推荐 3.10.6。
3、激活 conda 虚拟环境:
conda activate novelai
4、根据显卡驱动安装 GPU 版本的 Pytorch:
直接使用官网的命令安装,打开网页:
https://pytorch.org/get-started/locally/
根据自己的环境选择安装指令:

5、第三方库依赖安装:
进入项目根目录,然后作者注明的第三方依赖库。
python -m pip install -r requirements.txt
6、下载模型文件:
NovelAI 的模型训练文件泄漏出来了,我直接放到网盘分享出来了。
权重下载链接(提取码:jack ):
https://pan.baidu.com/s/1BJ-5Zo7FnCxh7ezJtYEqIg?pwd=jack
将模型文件解压缩放到 models 目录下,
在 models/Stable-diffusion 里,可以看到这几个文件:

7、运行 Web UI
python launch.py
第一次运行,这个过程中也会下载一些依赖库和权重文件,耐心等待即可。

看到 local URL 表明开启完成,直接打开这个本地连接。
然后你就能看到这个页面了:
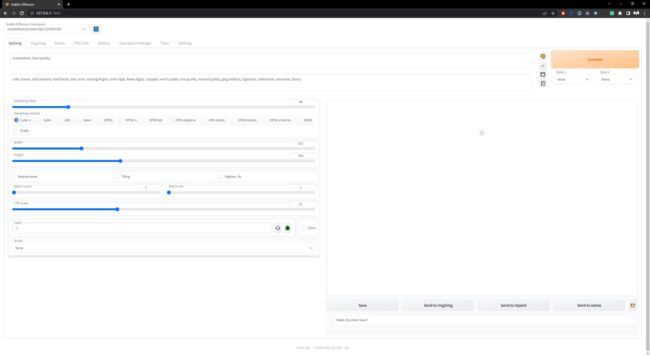
8、效果测试:
Prompt 输入:
masterpiece, best quality,obliques , 1girl, magic, vivid, looking at viewer, from above, black hair, black eyes, floating, flowing dress, {{{{intricate red dress}}}}, hibiscus flowers, d:, cleavage
Negative prompt 输入:
nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry,
steps、图片尺寸、CFG Scale 设置跟我一样,随机种子 Seed 设为:815804347。
点击 Generate 生成,你就能得到这样的结果:

如果对环境搭建有问题,可以参考我之前发布过的一期环境搭建视频教程:
AI杀疯了!2022年保姆级AI算法教程,新年必玩!_哔哩哔哩_bilibili
四、絮叨
其实高级玩法还有很多,比如使用 Textual Inversion 用某个人的图片集(30张左右),训练一个小模型,记录这个特征,然后进行多特征融合(写在 Prompt 描述里)。
就能生成像某个人的写实一些游戏风格作品。



图片来源于网络
还可以使用 img2img 进行风格、背景的替换等。
这些都可以使用 Stable Diffusion web UI 实现。
如果大家这些内容感兴趣,欢迎点个在看,喜欢的人多的话,我这周末就肝一期视频教程。
详细讲述,环境搭建 + Stable Diffusion web UI 使用技巧 + 各种玩法。
风险提示:
1、不要将 Stable Diffusion web UI 服务部署到公网服务器上,项目有漏洞,机器会被劫持;
2、不建议使用 naifu 版本,封装较多,容易被动手脚。建议使用开源的 Stable Diffusion web UI。
3、我的模型,我跑过,没问题。但不要随便下载网络上的其它开源模型,有反序列化攻击风险。
好了,今天就聊这么多吧。
我是 Jack,我们下期见~