(2022,核调制)使用可扩展指纹技术进行责任披露的生成模型
Responsible Disclosure of Generative Models Using Scalable Fingerprinting
公众号:EDPJ
目录
0. 摘要
1. 简介
2. 相关工作
3. GAN 指纹识别网络
3.1 流程
3.2 指纹调制
4. 实验
4.1 有效性和保真度
4.2 容量
4.3 可扩展性
4.4 保密性
4.5 稳健性和免疫性
4.6 深度造假检测和溯源
5. 结论
参考
S. 总结
S.1 主要思想
S.2 架构 & loss
S.3 使用指纹进行核调制
0. 摘要
在过去的几年里,深度生成模型的性能达到了一个新的水平。 生成的数据变得很难与真实数据区分开来。 虽然有很多用例受益于这项技术,但人们也非常担心这项新技术如何被滥用来生成深度造假(deepfake)并大规模传播错误信息。 不幸的是,随着真假之间的差距不断缩小,目前的深度造假检测方法是不可持续的。 相比之下,我们的工作能够负责任地披露这种最先进的生成模型,使模型发明者能够对他们的模型进行指纹识别,以便可以准确地检测到包含指纹的生成样本并溯源。 我们的技术通过高效且可扩展的特定生成大量具有不同指纹的模型来实现这一点。 我们推荐的操作点使用 128 bit 指纹,原则上会产生超过 10^38 个可识别模型。 实验表明,我们的方法满足了指纹识别机制的关键特性,并在深度造假检测和溯源方面取得了成效。
1. 简介
深度生成模型的阴暗面延缓了其产业化进程。 例如,在将 GPT-2(Radford 等人,2019 年)和 GPT-3(Brown 等人,2020 年)模型商业化时,OpenAI 倾向于保守地开源他们的模型,而不是只发布黑盒 API。 他们投入昂贵的人力来审查用户下载并监控其 API 的使用情况。 然而,如何以开放的方式追溯下游用例的责任,仍然是一项具有挑战性和全行业的任务。
为了率先完成这项任务,我们提出了一种模型指纹识别机制,可以负责任地发布和监管生成模型。 特别是,我们允许负责任的模型发明者对他们的生成器进行指纹识别并披露他们的责任。 因此,生成的样本包含可以准确检测并溯源的指纹。 这是通过高效且可扩展的特定生成大量具有不同指纹的生成器实例来实现的。 参见图 1 中部。
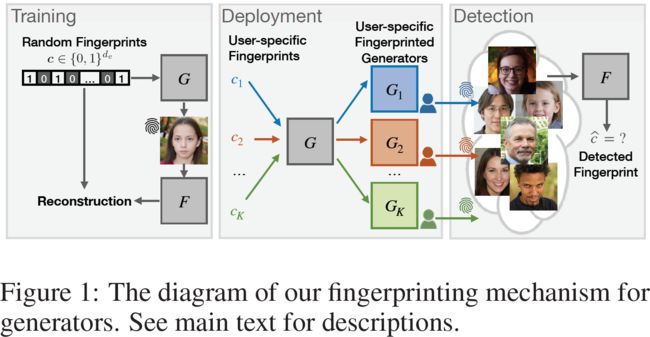
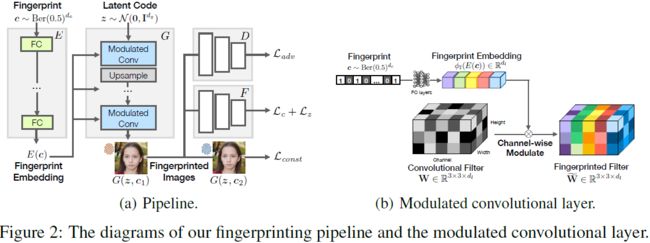
本着动态滤波器网络(Jia 等人,2016 年)和基于样式的生成器架构(Karras 等人,2019 年;2020 年)的精神,它们的网络滤波器不是自由学习的,而是以输入为条件的,我们学会了将唯一指纹参数化到每个生成器实例的滤波器中。 核心要点是将指纹自动编码器(AE)合并到 GAN 框架中,同时保留原始生成性能。 参见图 1 左侧。 特别是,给定一个 GAN 主干,我们使用来自编码器的指纹 embedding 来调制生成器的每个卷积滤波器(图 2(b)),并尝试从生成的图像中解码这个指纹。 我们使用指纹相关损失和原始对抗损失联合训练指纹自动编码器和 GAN。 示意图见图2(a),详情见第 3 节。
经过训练,负责的模型发明者能够有效地进行指纹识别并将不同的生成器实例发布给不同的用户下载,这些生成器实例具有相同的生成性能但具有不同的指纹。 每个用户下载对应一个唯一的指纹,由发明者的数据库维护。 因此,当模型被滥用时,模型发明者可以使用解码器从生成的图像中检测指纹,并在数据库中进行匹配,然后追溯用户的责任。 参见图 1 右侧。 基于这种负责任的披露形式,负责任的模型发明者(如 OpenAI)有办法在发布其强大的模型时减轻对社会的不利副作用,同时应该有一种自动溯源滥用的方法。
2. 相关工作
深度造假检测和溯源。 这些任务伴随着对深度伪造滥用的日益关注(Harris,2018 年;Chesney 和 Citron,2019 年;Brundage 等人,2018 年)。
- Deep fake detection 是一个二元分类问题,用于区分假样本和真实样本,同时溯源进一步追踪它们的来源。 在 GAN 生成的图像中发现视觉上难以察觉但机器可区分的模式,通过噪声模式匹配(Marra 等人,2019 年)、深度分类器(Afchar 等人,2018 年;Hsu 等人,2018 年;Yu 等人, 2019)或深度递归神经网络 (G¨uera & Delp, 2018) 使这些任务可行。
- (Zhang et al., 2019; Durall et al., 2019; 2020; Liu et al., 2020) 观察到真假在频域或纹理表示中的不匹配可以促进深度造假检测。
- (Wang et al., 2020; Girish et al., 2021) 随后将不同的 GAN 技术推广到开放世界。
- 除了溯源,(Albright & McCloskey,2019 年;Asnani 等人,2021 年)甚至逆向工程以在潜在生成源的超参数空间中进行预测。
然而,这些被动检测方法严重依赖于深度造假中的内在线索。 因此,它们几乎无法长时间对抗 GAN 技术的对抗性迭代。 例如,(Durall et al., 2020) 通过缩小生成的高频分量的差距来提高生成的真实性。 为了处理这种情况,人工指纹在 (Yu et al., 2021) 中被提出,通过将指纹植根到训练数据中来主动将线索嵌入到生成模型中。 这使得深度造假检测独立于 GAN 进化。 然而,作为间接指纹识别,(Yu et al., 2021) 无法扩展到大量指纹,因为它们必须为每个单独的指纹预处理训练数据并用每个指纹重新训练生成器。 我们的方法在精神上类似于 (Yu et al., 2021),但通过直接有效地对生成模型进行指纹识别具有根本优势:在训练一个通用指纹识别模型后,我们可以实例化大量具有不同指纹的特定生成器。
图像隐写术和水印。
隐写术旨在以隐藏的方式操纵载体图像,以便通过图像进行的通信只能被发送者和预期的接收者理解(Fridrich,2009)。
- 传统方法依赖于傅里叶变换(Cox 等人,2002 年;Cayre 等人,2005 年)、JPEG 压缩或最低有效位修改(Pevn`y 等人,2010 年;Holub 等人,2014 年)。
- 最近的作品利用深度神经编码器和解码器来隐藏信息(Baluja,2017 年;Tancik 等人,2020 年;Luo 等人,2020 年)。
水印旨在将所有权信息嵌入到载体图像中,以便验证所有者的身份和真实性。 它属于隐写术的一种形式,有时会与物理图像相互作用(Tancik 等人,2020)。
- 现有方法依赖于对数极坐标频域 (Pereira & Pun, 2000; Kang et al., 2010)、打印机-相机变换 (Solanki et al., 2006; Pramila et al., 2018) 或显示-相机变换 ( Yuan et al., 2013; Fang et al., 2018).
- 最近的作品还使用深度神经网络来检测图像何时被重新成像(Fan 等人,2018 年;Tancik 等人,2020 年)。
- 我们的指纹解决方案的概念和功能在水印的精神上是相似的,但在根本上不同。 特别是,我们没有修饰单个图像。 相反,我们的解决方案是第一个修饰生成器参数以便将信息编码到模型中的解决方案。
网络水印。网络水印技术将水印嵌入到网络参数而不是像素中,同时不会降低原始效用。 我们的解决方案与他们有共同的动机,但在概念、动机和技术方面有很大不同。
- 对于概念,现有的大多数工作仅适用于图像分类模型,仅 (Ong et al., 2021; Yu et al., 2021) 适用于生成模型,但效率和可扩展性较差。
- 对于动机,现有工作的目标是对单个模型进行指纹识别,而我们受到 (Ong et al., 2021; Yu et al., 2021) 的限制,在单次训练中,将指纹识别扩展到多达 10^38 个不同的生成器实例
- 对于技术,大多数现有作品在输入输出行为中嵌入指纹(Adi 等人,2018 年;Zhang 等人,2018 年;Ong 等人,2021 年),而我们的解决方案摆脱了这种触发输入以提高可扩展性。
3. GAN 指纹识别网络
在整篇论文中,我们代表负责任的模型发明者的观点,这被视为我们实验的监管中心。 编码器、解码器和训练数据都不应向公众开放。 只有指纹生成器实例被释放到开放端。
我们在开头列出了符号标记。 我们使用隐编码
![]()
来控制生成的内容。 我们设置 d_z = 512。我们将指纹
![]()
表示为一个比特序列。 它服从概率为 0.5 的伯努利分布。 我们在第 4.2 节中非平凡地选择了指纹长度 d_c。编码器 E 将 c 映射到其 embedding,生成器 G 将 (z,E(c)) 映射到图像域,鉴别器 D 将图像 x∼p_data 映射到真/假分类概率,解码器 F 将图像映射到 解码的隐编码和指纹(^z,^c)。 在以下公式中,为简洁起见,我们将 G(z,E(c)) 表示为 G(z, c)。
3.1 流程
我们在训练中考虑了三个目标。 首先,我们保留了 GAN 的原始功能来生成逼真的图像,尽可能接近真实分布。 我们使用不饱和对数损失来进行真/假二元分类:

我们通过解码器 F 重建隐编码以增加生成多样性并减轻 GAN 的模式崩溃问题

其中我们使用 F 的前 d_z 个输出元素对应于解码的隐编码。
第二个目标是重建指纹以便进行指纹检测。
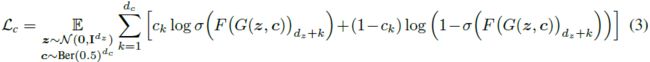
其中我们使用 F 的后 d_c 个输出元素作为解码指纹。σ(·) 表示将输出可微分地限制在 [0, 1] 范围内的 sigmoid 函数。 因此,重建是每个位的交叉熵二进制分类的组合。
值得注意的是,我们使用一个解码器来解码隐编码和指纹,这有利于它们的表示之间的明确分离,如下所述。
第三个目标是分离隐编码和指纹的 representation。 理想情况下,隐编码应该对生成的内容具有独占控制权。因此,具有不同指纹但具有相同隐编码的两幅图像应该具有一致的外观。 我们将一致性损失公式化为:

下图展示了分离效果。

我们最终的训练目标如下。 我们在对抗训练框架下对其进行优化:
![]()
其中 λ1 = 1.0、λ2 = 1.0、λ3 = 2.0 和 λ4 = 2.0 是超参数,用于平衡每个损失项的大小,每个损失都有助于解决方案的一个属性。 根据经验,权重设置在其幅度级别内不敏感。流程图见图 2(a)。
3.2 指纹调制
在架构层面,如何将 E(c) 嵌入到 G 中并非易事。要点是将指纹嵌入到生成器参数而不是生成器输入中,以便在训练通用模型后我们可以实例化有不同指纹的大量生成器。 正如第 4.3 节所验证的那样,这对于使我们的指纹识别高效且可扩展至关重要。 然后,我们仅将指纹生成器实例部署到用户下载,不包括编码器。
我们通过使用指纹 embedding 来调制生成器主干中的卷积滤波器来实现这一点。 给定第 l 层的卷积核
![]()
我们首先通过仿射变换 ϕ_l 投影指纹 embedding E(c),获得
![]()
该变换被实现为具有可学习参数的全连接神经层。 然后我们用 ϕ_l 中的相应值缩放 W 的每个通道。 具体来说,
![]()
流程图请参见图 2(b)。 我们在 4.1 节中与其他指纹嵌入架构进行了比较,并验证了这一架构的优势。 我们使用相同的指纹 embedding 对第 l 层的所有卷积滤波器进行调制。 我们在附录 A.2 节中研究了在哪一层进行调制可以实现最佳性能。 一个理想的权衡是调制所有的卷积层。
请注意,在训练期间,隐编码 z 和指纹 c 是联合采样的。 然而,为了部署,模型发明者首先对指纹 c_0 进行采样,然后用 c_0 调制生成器 G,然后仅将调制后的生成器 G(·, c0) 部署给用户。 对于该用户,调制发生器只允许一个输入,即隐编码。 一旦发生误用,发明人使用解码器对指纹进行解码并溯源用户,从而实现责任披露。
4. 实验
4.1 有效性和保真度
评估。有效性表明输入指纹始终出现在生成的图像中,并且可以被解码器准确检测到。 这是通过 30k 个随机样本(具有随机隐编码和随机指纹编码)的指纹检测按位精度来衡量的。 我们使用 128 位来表示指纹。 正如第 4.2 节中分析的那样,这是一个非常重要的设置。
此外,位匹配可能偶然发生。我们进行零假设检验来评估概率,越低越好。 给定解码指纹与相应真实编码之间的匹配位数 k,零假设 H_0:依概率得到这个匹配位数。 它根据 d_c 试验的二项式概率分布计算为
![]()
其中 d_c 是指纹位数。 p 值应低于 0.05 才能拒绝原假设。
保真度反映了原始生成受指纹识别影响的程度。 它还有助于避免人们怀疑指纹的存在,这可能会引起敌对的指纹去除。 我们报告了 30k 生成图像和 30k 真实测试图像之间的 Fr´echet Inception Distance (FID)。 较低的值表示生成的图像更逼真。
基线。 我们比较了七种基线方法。 第一个基线是 StyleGAN2 主干。 它提供了保真度的上限,但没有指纹识别功能。
第二个基线是 (Yu et al., 2021),这是另一种主动但间接的 GAN 指纹识别方法。 另外两个基线 outguess 和 steghide 与 (Yu et al., 2021) 类似。 他们只是用传统的基于 JPEG 压缩的图像水印技术取代了 (Yu et al., 2021) 中的深度图像指纹自动编码器,并且仍然存在低效率/可扩展性问题。
我们还将我们的机制与三种架构变体进行了比较。 这些变体的动机是以不同方式合并指纹。
- 变体 I:仅使用隐编码的 embedding 来调制卷积滤波器,同时通过生成器的输入提供指纹编码。 这是为了测试指纹调制的必要性。
- 变体 II:调制滤波器两次,分别用隐编码的 embedding 和指纹编码的 embedding。
- 变体 III:调制滤波器,用隐编码 embedding 和指纹编码 embedding 的串联。
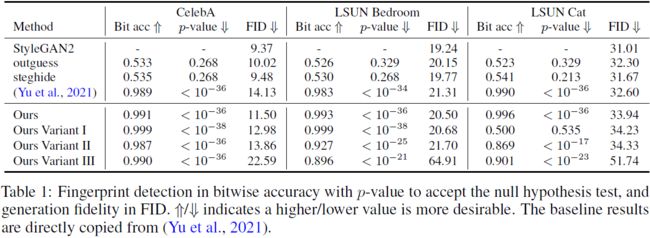
结果。 从表 1 中,我们发现:
- 两种传统的图像水印方法 outguess 和 steghide 无法在生成的图像中传递指纹,随机猜测 (∼ 0.5) 检测精度表明了这一点。 我们将此归因于深度生成模型和浅层水印技术之间的表示差距。
- 在 CelebA 上,所有其他方法都实现了几乎完美的指纹检测精度,p 值接近于零。 这是因为 CelebA 是一个具有有限多样性的标志性对齐数据集。 无论模型配置如何,指纹识别都能很好地与生成协同作用。
- 在 LSUN Bedroom 和 Cat 上,只有 (Yu et al., 2021) 和我们的最优模型获得饱和指纹检测精度。 我们的变体 I、II 和 III 并不总能达到饱和性能。 特别是我们的变体 I 在 LSUN Cat 上失败了。 我们认为滤波器调制是重建的有力方法。指纹调制对于它们的检测是必要的,而与指纹代码一起调制隐编码会影响指纹重建。
- 我们的方法具有与 (Yu et al., 2021) 相当的性能,并且在实践中具有显着优势:在部署期间,我们可以在 5 秒内对生成器实例进行指纹识别,而 (Yu et al., 2021) 则必须使用 3-5 天重新训练生成器实例。 这是 50000 倍的效率增益。
- 我们的方法导致 ≤2.93 可忽略不计的 FID 退化。 引入指纹识别功能是一个值得的权衡。
- 我们在下图中展示了来自几个生成器实例的未经整理的生成样本。 图像质量高,指纹是难以察觉的。这是由于等式 4 中的一致性损失 L_const:给定相同的隐编码,不同的生成器实例可以生成相同的图像。 他们的指纹仅在非显着背景中有线索,并且可由我们的解码器区分。

4.2 容量
容量表示我们的机制在两个指纹之间没有串扰的情况下可以容纳指纹的数量。 这是由 d_c、指纹比特长度和我们的检测精度(根据第 4.1 节)决定的。 然而,指纹比特长度的选择并不重要。 更长的长度可以容纳更多的指纹,但重建/检测更具挑战性。
为了找出最佳的指纹比特长度,我们进行了以下实验。 一方面,给定一个长度,我们评估我们的检测精度。 另一方面,我们估计了检测精度的底线要求。 这被模拟为一大袋(100 万)指纹样本中比特重叠的最大百分比。 检测精度和底线要求之间的差距应该越大越好。

在图 4 中,我们在 {32、64、128、256、512} 选项中改变指纹比特长度,并以红色绘制按位检测精度,以蓝色绘制底线要求。 我们发现:
- 底线要求随着指纹的位长增长单调递减,因为较大的位长会导致较少的指纹重叠。
- 测试精度也随着指纹的位长增长单调递减, 这是由于指纹重建/检测的挑战。
- 根据经验,测试准确性在开始时下降得更慢,然后比其底线要求更快。 因此,我们选择位长 128 作为最大间隙的最佳选择。 我们在所有实验中都坚持这一点。
- 考虑到我们的检测位精度 ≥0.991 和我们的指纹位长为 128,我们原则上推导出我们的机制可以容纳 2^(128 × 0.991) ≈ 10^38 个可识别指纹的大容量。
4.3 可扩展性
可扩展性是我们机制的优势之一:在训练期间,我们可以动态高效地实例化具有任意指纹的大容量生成器,因此指纹检测在测试期间可以很好地泛化。 为了验证这一点,我们有意降级我们的方法与仅有一组有限指纹的基线进行了比较。 这些基线代表不可扩展的指纹识别方法类别,这些方法必须为每个指纹重新训练生成器实例,例如 (Yu et al., 2021)。 我们不能直接与 (Yu et al., 2021) 进行比较,因为实例化大量生成器进行分析是不切实际的(耗时的)。 作为一种解决方法,我们使用≤1k 的真实样本来训练我们的检测器来模拟基线的不可扩展性。
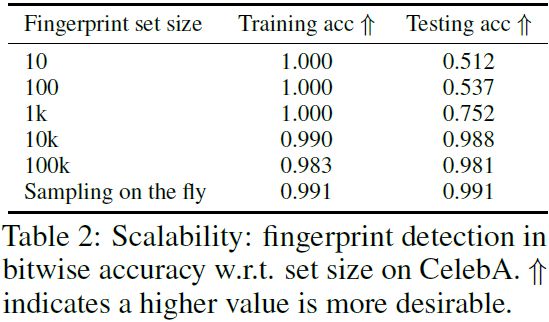
从表 2 中我们可以看出,除非我们可以用 10k 或更多的指纹样本实例化生成器,否则指纹检测无法泛化。 这表明有必要为 GAN 配备一种高效且可扩展的指纹识别机制,最好是动态的。
4.4 保密性
指纹的存在和价值不应轻易被第三方发现,否则可能会被删除。 事实上,我们指纹的保密性是另一个有利的特性,因为我们的指纹编码器与图像隐写术或水印不同,不会直接修饰生成的图像。 因此,传统的保密攻击协议,例如,人工训练集 (ATS) 攻击不适用。
相反,我们采用基于阴影模型的攻击(Salem 等人,2020 年)来尝试从生成的图像中检测指纹的存在和价值。 我们假设攻击者可以访问模型发明者的训练数据、指纹空间和训练机制。 他重新训练了他自己的影子指纹自动编码器。
- 对于指纹存在攻击(fingerprint presence attack),在 CelebA 数据集上,攻击者训练了一个基于 ResNet-18(He 等人,2016 年)的二元分类器,以区分 10k 个非指纹图像(5k 个真实图像加上 5k 个生成图像)和使用指纹生成器生成的 10k 个指纹图像。 我们发现接近饱和的 0.981 训练精度。 然后他将分类器应用于 1k 发明者生成的图像。 结果,我们发现指纹存在的测试准确度仅为 0.505,接近于随机猜测。
- 对于指纹值攻击(fingerprint value attack),在 CelebA 数据集上,攻击者将他的影子解码器(0.991 训练位精度)应用于 1k 发明者生成的图像。 结果,我们发现只有 0.513 按位测试精度,也接近于随机猜测。
- 我们得出结论,不同版本的指纹识别系统之间的不匹配会阻止攻击,从而保证其保密性。
4.5 稳健性和免疫性
开放端的深度造假可能会经历后处理环境并导致质量下降。 因此,对图像扰动的鲁棒性对我们的机制同样重要。 当它不适用于某些扰动时,我们的免疫特性会对其进行补偿。
按照 (Yu et al., 2019) 中的协议,我们评估了针对五种图像扰动的鲁棒性:裁剪和调整大小、高斯核模糊、JPEG 压缩、加性高斯噪声以及它们的随机组合。 我们考虑模型的两个版本:原始版本和免疫版本。 免疫模型表明,在训练期间,我们在将生成的图像提供给指纹解码器之前,使用相应的随机强度扰动来增强生成的图像。
值得注意的是,编码器、解码器和训练数据均不对公众开放。 因此,必须按照 (Yu et al., 2019) 中的规定,使用黑盒假设来试验抗扰动的鲁棒性。 换句话说,对抗性图像修改和指纹覆盖等需要访问编码器、解码器和/或训练数据的白盒扰动不适用于我们的场景。
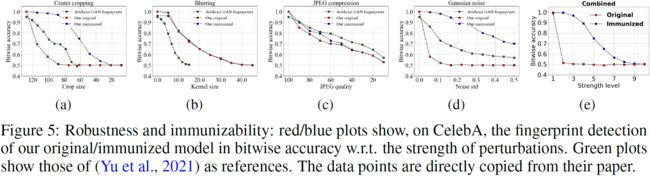
我们在图 5 中绘制了对应于每个扰动强度的原始/免疫模型与 (Yu et al., 2021) 模型之间指纹检测精度的比较。 我们发现:
- 对于所有扰动,指纹检测精度随着扰动强度的增加而单调下降。 对于红色图中的一些扰动,即模糊和 JPEG 压缩,精度在相当大的范围内缓慢下降。 我们考虑接受精度 ≥75%。 因此,模糊下的鲁棒工作范围为:高斯模糊核大小∼[0, 7]; 在 JPEG 压缩下是:JPEG 质量 ∼ [80, 100]。 通常,如果扰动超过此范围,图像将无法正常工作。 因此,我们验证了对模糊和 JPEG 压缩的鲁棒性。
- 对于其他扰动,虽然我们的原始模型不够稳健,但扰动增强在蓝点中进行了显着补偿。 我们考虑接受精度≥75%。 因此,裁剪下的免疫工作范围为:裁剪大小∼[60, 128]; 高斯噪声下为:噪声标准差∼[0.0,0.4]; 在组合扰动下是:上述原始或免疫可行范围的组合。 因此,我们验证了我们的模型对裁剪、高斯噪声和组合扰动的免疫能力。
- 比较 (Yu et al., 2021) 和我们的模型,对于模糊,他们在绿色图中的模型不如我们的原始/免疫模型稳健。 对于其他扰动,它们比我们的原始模型更稳健,但不如免疫模型。 这表明指纹解决方案的免疫能力的重要性,然而,这是 (Yu et al., 2021) 缺乏的。
4.6 深度造假检测和溯源
有效性、稳健性和免疫性反过来有利于我们最初的动机:深度造假检测和溯源。 前一个任务是区分真假的二元分类问题。 后一项任务是进一步精细地标记生成图像的来源。
我们将解决方案从被动分类器转移到主动指纹识别,并将这两个任务合并为一个具有 1+N 个类别的任务:1 个真实世界源和 N 个 GAN 源,其中 N 可以非常大,与我们在第 4.2 节中的容量 10^38 一样大。然后任务转换为验证一个解码指纹是否在我们的数据库中。 给定比特重叠阈值,这是通过将解码指纹与数据库中的每个指纹进行比较来实现的。 根据我们≥0.991的指纹检测精度,将阈值设置为128×0.95≈121应该是可靠的。那么溯源是微不足道的,因为我们可以直接根据指纹查找生成器实例。 如果指纹不在数据库中,则它应该是从真实图像解码的随机指纹。 我们使用我们的免疫模型来对抗第 4.5 节中的组合扰动。
基线。 我们将两个最先进的 deepfake 分类器(Yu 等人,2019 年;Wang 等人,2020 年)作为被动依赖固有视觉线索的基于学习的基线进行比较。 因为基于学习的方法只能枚举一组有限的训练标签,所以我们考虑两种场景:封闭世界和开放世界。 不同之处在于在训练期间是否看到测试 GAN 源。 这对我们的方法无关紧要,因为我们的方法可以处理任何 N ≤ 10^38。对于封闭世界,我们在来自 N + 1 个来源的每个 10k/1k 图像上训练/评估基线分类器。 对于开放世界,我们训练 N + 1 个 1-vs-the-other 二元分类器,当且仅当所有分类器都预测负面结果时才预测为 “the other” 标签。 我们测试来自每个真实来源或 N 个未见过的 GAN 来源的 1k 个图像。 此外,我们在比较中将 (Yu et al., 2021) 称为其他主动但间接的模型指纹识别基线。
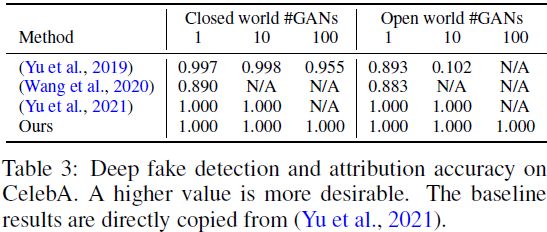
结果。 从表 3 我们发现:
- 当 GAN 源的数量不太大时,基于我们指纹的深度造假检测和溯源对封闭世界中的大多数基线表现同样完美(~ 100% 准确度)。 然而,当 N = 100 时,(Yu et al., 2021) 由于其效率和可扩展性有限而不适用。 由于其二进制分类的性质,(Wang 等人,2020)也不适用。
- 开放世界对我们的方法来说也是一个微不足道的场景,但对基线分类器提出了挑战(Yu 等人,2019 年;Wang 等人,2020 年)。 当未见过的 GAN 来源的数量增加到 10 时,(Yu et al., 2019) 甚至退化到接近随机猜测的程度。 这是基于学习的方法的常见泛化问题。 (Yu et al., 2021) 当 N 很大时仍然不切实际。
- 由于深度造假检测和溯源对我们的方法来说是一项微不足道的任务,它使我们的优势独立于 GAN 技术的发展。 它有利于模型跟踪并推动模型发明者负责任披露的新兴方向。
5. 结论
我们通过一种新颖的指纹识别机制实现了生成模型的责任披露。 它允许可扩展地临时生成大量具有不同指纹的模型。 我们进一步验证了其在深度造假检测和归因任务中的饱和性能。 我们呼吁我们社区的倡议,以维护生成模型的责任发布和监管。 我们希望责任披露将成为人工智能安全的一个重要基础。
参考
@inproceedings{
yu2022responsible,
title={Responsible Disclosure of Generative Models Using Scalable Fingerprinting},
author={Ning Yu and Vladislav Skripniuk and Dingfan Chen and Larry S. Davis and Mario Fritz},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=sOK-zS6WHB}
}
S. 总结
S.1 主要思想
通过使用指纹 embedding 调制卷积核把指纹嵌入到生成器中,使模型发明者能够对他们的模型进行指纹识别,以便可以准确地检测到包含指纹的生成样本并溯源。
S.2 架构 & loss
本文使用的主干网络是 StyleGAN2。使用的损失函数如公式 5 所示:
![]()
使用不饱和对数损失来进行真/假二元分类:
通过解码器 F 重建隐编码以增加生成多样性并减轻 GAN 的模式崩溃问题
其中使用 F 的前 d_z 个输出元素对应于解码的隐编码。
使用重建指纹损失以便进行指纹检测。
其中使用 F 的后 d_c 个输出元素作为解码指纹。
具有不同指纹但具有相同隐编码的两幅图像应该具有一致的外观。一致性损失公式化为:
S.3 使用指纹进行核调制
通过使用指纹 embedding 来调制生成器主干中的卷积滤波器。 给定第 l 层的卷积核
![]()
首先通过仿射变换 ϕ_l 投影指纹 embedding E(c),获得
![]()
该变换被实现为具有可学习参数的全连接神经层。 然后用 ϕ_l 中的相应值缩放 W 的每个通道。 具体来说,
![]()