Linux系统编程:进程的管理和创建
目录
一. 什么是进程
二. Linux对进程的管理方法
2.1 PCB描述进程
2.2 进程的组织
2.3 进程的查看
三. 子进程的创建
3.1 子进程创建函数fork的使用
3.2 子进程创建的原理
四. 总结
一. 什么是进程
进程(process)是指计算机中已经存在并运行的程序,是系统进行资源分配和调度的基本单位,是计算机操作系统结构的基础。我们在Window/Linux启动一个软件,或者在执行一条指令,都会在系统层面创建进程。
在Windows下打开任务管理器(快捷键Ctrl + Shift + Esc),可以查看当前系统中存在的进程。我们可以看到,Windows下的进程被分为了应用进程和后台进程,在Linux下也一样,进程被分为了前端进程和后端进程。
 图1.1 通过任务管理器查看Windows下的进程
图1.1 通过任务管理器查看Windows下的进程
Linux操作系统要对进程进行管理,管理的原则为先描述后组织,即:要先将进程信息通过结构体描述记录起来,然后再通过特定的数据结构进行组织。每次新创建一个进程,都会在内存再创建一个与之对应的进程控制块PCB(process control block),我们常说的运行程序之前,要现将程序载入内存,不仅仅是将代码和数据载入内存,还有创建对应的PCB。每一个PCB,都指向对应的代码和数据。
我们可以认为,进程 = 对应的数据和代码 + 对应的进程控制块PCB
二. Linux对进程的管理方法
2.1 PCB描述进程
进程控制块,简称PCB,是用于描述进程信息的结构体,不同的操作系统中PCB的名称可能会有所不同,在Linux下,PCB的名称为:struct task_struct {...}
PCB中应当包含进程的如下信息:
- 标识符(进程编号):每个进程都有唯一的编号,用于区分其他进程。
-
状态: 任务状态,退出代码,退出信号等。
-
优先级:相对于其他进程的优先级。
-
程序计数器:即将被执行的下一条指令存储的地址。
-
内存指针: 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
-
上下文数据: 进程执行时处理器的寄存器中的数据。
-
I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
-
记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
-
其他信息
Linux系统依靠双向链表组织进程信息,PCB的定义大体如下:
struct task_struct
{
//进程属性信息
... ...
struct task_struct* _prev; //前一个进程
struct task_struct* _next; //后一个进行
}2.2 进程的组织
Linux要对进程进行管理,就要对进程进行组织,Linux依靠双向链表管理进程控制块PCB,每一个PCB都指向与之对应的代码和数据。
当创建新进程时,新建的PCB要插入到链表中,执行的操作就等同于双向链表节点的插入,时间复杂度为O(1),进程结束或强制终止,就相当于链表节点的删除,进程状态发生改变,就更改PCB中的相应信息。
结论:对进程的管理,本质就是对PCB链表的增删查改。
 图2.1 进程的组织
图2.1 进程的组织
在Linux系统中,还存在运行队列,每当有一个进程载入到内存之中,它的PCB就会被插入到运行队列的尾部等待CPU运行,CPU运行处于运行队列头部的进程。当CPU运行新的进程之前,需要将头部的进程删除(完成全部程序的运行)或者将其挪到运行队列的尾部(还没完成全部程序的运行)。
进程调度,本质就是在task_struct运行队列中选择一个进程的过程。
 图2.2 运行队列
图2.2 运行队列
2.3 进程的查看
进程查看的指令:
- ps -- 查看当前终端下的进程。
- ps axj -- 查看系统中所有进程。
- ps axj | grep '...' -- 查看指定的进程。
- ps axj | head -1 && ps axj | grep '...' -- 带上头部查看指定进程
- ps axj | head -1 && ps axj | grep '...' | grep -v grep -- 在查看指定进程的同时去除grep进程
为了方便演示,我们打开两个终端,在一处写死循环.cpp代码,生成可执行文件(取文件名myproc)并运行,在另一处终端使用上面的指令进行进程查看,如图2.3所示。
 图2.3 进程查看
图2.3 进程查看
使用top指令也可以查看进程,top指令类似于Windows下的任务管理器。
在Linux系统中,每创建一个新的进程,都会在/myproc目录下新建一个目录来记录进程信息,使用ls /proc命令,可以查看/proc文件中的文件,每个目录文件对应一个进程,目录文件的文件名为进程的编号(pid)。
 图2.4 查看进程目录
图2.4 查看进程目录
如图2.5所示,将myproc文件运行起来,使用指令ps axj | head -1 && ps axj | grep myproc查看其进程pid,然后通过ll /proc/(pid) 查看这个进程对应的目录中的内容,里面有cwd和exe两个文件,它们的意义为:
- cwd -> 当前进程的工作路径。
- exe -> 可执行程序的路径和文件名。
通过ps相关指令查看进程id相对复杂,我们可以在代码中使用下面的两个函数来查看当前进程和其父进程的id:
- pid_t getpid() -- 获取当前进程的id。
- pid_t getppid() -- 获取父进程的id。
上面两个函数,被包在头文件sys/types.h中。
- 强制终止进程:kill -9 [进程id]
三. 子进程的创建
3.1 子进程创建函数fork的使用
- 函数原型:pid_t fork(void)
- 函数返回值:若创建成功,给父进程返回子进程的编号,给子进程返回0,若失败返回-1
在pid_t ret = fork()之后,进程一分为二,一个父进程,一个子进程。
fork()函数的使用一般是希望父进程和子进程执行不同的代码,一般通过if/else if/else体系结构,判断fork()函数的返回值,来区分希望父进程和子进程运行的代码。
如代码3.1所示,使用fork创建子进程,父子进程都死循环打印进程的pid和ppid。如图3.1,我们可以看到,虽然父进程和子进程的代码都是while(1)死循环,但依旧交替运行父子进程的代码,我们无法确定父子进程的运行顺序,也并不是说一个进程要完成其全部运行之后,其他的进程才能够执行。
代码3.1:fork的使用
1 #include
2 #include
3 #include
4
5 int main()
6 {
7 pid_t ret = fork(); //创建子进程
8
9 if(ret < 0)
10 {
11 //子进程创建失败
12 perror("fork");
13 }
14 else if(ret == 0)
15 {
16 //子进程代码
17 while(1)
18 {
19 printf("Child process, ret:%d, pid:%d, ppid:%d\n", ret, getpid(), getppid());
20 sleep(1);
21 }
22 }
23 else
24 {
25 //父进程代码
26 while(1)
27 {
28 printf("Parent process, ret:%d, pid:%d, ppid:%d\n", ret, getpid(), getppid());
29 sleep(1);
30 }
31 }
32
33 return 0;
34 }
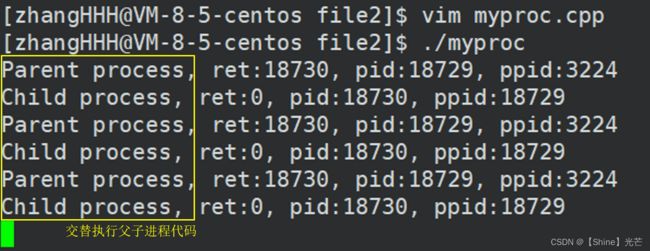 图3.1 代码3.1的运行结果
图3.1 代码3.1的运行结果
3.2 子进程创建的原理
或许有人会问,C/C++函数不是只能有一个返回值吗,为什么父子进程会有两个不同的返回值?之就要设计到fork内部和实现了。
如果3.2所示,我们可以推测,fork内部一定调用了某些系统接口,创建出了子进程,那么,在fork函数返回时,到return处实际上已经分为父进程和子进程了,父进程和子进程的返回值ret不同,就实现了fork对于父子进程的不同返回值。
而创建子进程时,会首先拷贝一份父进程的PCB,然后修改器内部的属性,然后添加到列表中去等待运行。
子进程被创建出来后,父子进程的运行顺序无法确定,具体的进程运行顺序是由Linux系统中的调度器来决定的。
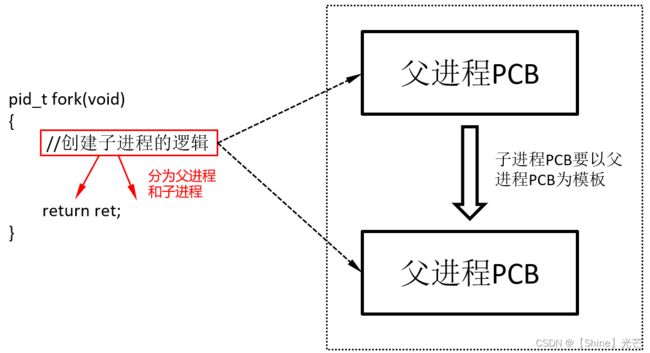 图3.2 子进程创建逻辑
图3.2 子进程创建逻辑
四. 总结
- 进程是指计算机中已经存在并运行的程序,进程 = 对应的PCB + 对应的代码和数据。
- 操作系统对进程进行管理时,会先使用task_struct对进行信息描述(PCB),然后使用双向链表对PCB进行组织,对进程的管理,本质上就是对PCB链表的增删查改。
- 通过ps、top、ls /proc 等指令,可以查看进程信息。通过getpid和getppid函数可以获取当前进程和父进程的id。
- 通过fork可以创建子进程。