MySQL高级(进阶)语句
MySQL高级(进阶)语句
- 一、MySQL高级语句
- 二、MySQL的函数语句
-
- 1.数字函数
- 2.聚合函数
- 3.字符串函数
- 三、结合函数的一些指令
-
- 1.group by
- 2.having
- 3.别名
- 4.子查询
- 5.EXISTS
- 四、连接查询
-
-
- 1.inner join——等值相连
- 2.left join——左联接
- 3.right join——右联接
-
- 五、CREATE VIEW(视图)
- 六、UNION联集
-
- 1.交集值
- 2.无交集值
- 3.CASE
- 七、数值计算
-
- 1.算排名
- 2.算累积总计
- 3.算总和百分比
- 4.算累积总和百分比
- 5.空值(NULL) 和无值("') 的区别
- 八、正则表达式
- 九、存储过程
-
- 1.创建存储过程
- 2.调用存储过程
- 3.查看存储过程
- 4.存储过程的参数
- 5.删除存储过程
- 6.存储过程的控制语句
一、MySQL高级语句


---- SELECT ---- 显示表格中一个或数个栏位的所有资料
语法: SELECT "栏位" FROM "表名";
SELECT Store_Name FROM Store_Info;

---- DISTINCT ---- 不显示重复的资料
语法: SELECT DISTINCT "栏位" FROM "表名";
SELECT DISTINCT Store_Name FROM Store_Info;

---- WHERE ---- 有条件查询
语法:SELECT "栏位” FROM "表名" WHERE "条件";
SELECT Store_Name FROM Store_Info WHERE Sales > 1000;

---- AND OR ---- 且 或
语法:SELECT "栏位" FROM "表名” WHERE "条件1" {[ANDIOR] "条件2"}+;
SELECT Store_Name FROM Store_Info WHERE Sales > 1000 OR (Sales < 500 AND Sales > 200);

---- IN ---- 显示己知的值的资料
语法: SELECT "栏位" FROM "表名" WHERE "栏位" IN ('值1','值2', ...);
SELECT * FROM Store_Info WHERE Store_Name IN ('Los Angeles','Houston');

---- BETWEEN ---- 显示两个值范围内的资料
语法:SELECT "栏位" FROM "表名" WHERE "栏位" BETWEEN '值1' AND '值2';
SELECT * FROM Store_Info WHERE Date BETWEEN '2020-12-06' AND '2020-12-10';

---- 通配符 ---- 通常通配符都是跟LIKE一起使用的
% : 百分号表示零个、一个或多个字符
_ : 下划线表示单个字符
'A_Z':所有以‘A’起头,另一个任何值的字符,且以Z'为结尾的字符串。例如,'A.BZ’和‘A.22’都符合这一个模式,而‘AKK2'并不符合(因为在A和Z之间有两个字符,而不是一个字符)。
'ABC%':所有以'ABC’起头的字符串。例如,'ABCD’和'ABCABC’都符合这个模式。
'%XYZ':所有以'XYZ’结尾的字符串。例如,'WXYZ’和‘ZZXYZ’都符合这个模式。
'%AN%':所有含有'AN'这个模式的字符串。例如,'LOS ANGELES’和'SAN FRANCISCO'都符合这个模式。
'_AN%':所有第二个字母为‘A'和第三个字母为'N’的字符串。例如,'SAMN FRANCITSCO’符合这个模式,而'LOS ANGELES'则不符合这个模式。
---- LIKE ---- 匹配一个模式来找出我们要的资料
语法:SELECT "栏位" FROM "表名" WHERE "栏位" LIKE {模式};
SELECT * FROM Store_Info WHERE Store_Name like '%os%';

---- ORDER BY ---- 按关键字排序
语法:SELECT "栏位" FROM "表名" [WHERE "条件"] ORDER BY "栏位" [ASC,DESC];
#ASC是按照升序进行排序的,是默认的排序方式。
#DESC是按降序方式进行排序。
SELECT Store_Name,Sales,Date FROM Store_Info ORDER BY Sales DESC;

二、MySQL的函数语句
1.数字函数
| 函数名 | 解释 |
|---|---|
| abs(x) | #返回x的绝对值 |
| rand() | #返回0到1的随机数 |
| mod(x,y) | #返回x除以y以后的余数 |
| power(x,y) | #返回x的y次方 |
| round(x) | #返回离x最近的整数 |
| round(x,y) | #保留x的y位小数四舍五入后的值 |
| sqrt(x) | #返回x的平方根 |
| truncate(x,y) | #返回数字x截断为y位小数的值 |
| ceil(×) | #返回大于或等于x的最小整数 |
| floor(x) | #返回小于或等于x的最大整数 |
| greatest(x1,x2…) | #返回集合中最大的值 |
| least(x1,x2…) | #返回集合中最小的值 |
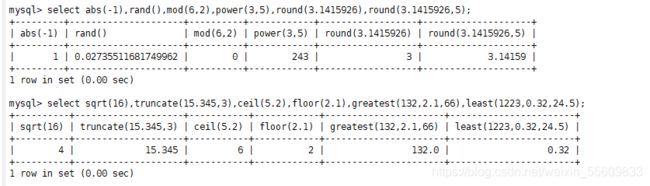
SELECT abs(-1),rand(),mod(5,3),power(2,3),round(1.89);
SELECT round(1.8937,3),truncate(1.235,2),ceil(5.2),floor(2.1),least(1.89,3,6.1,2.1);
2.聚合函数
| 函数名 | 解释 |
|---|---|
| avg() | #返回指定列的平均值 |
| count() | #返回指定列中非 NULL值的个数 |
| min() | #返回指定列的最小值 |
| max() | #返回指定列的最大值 |
| sum(x) | #返回指定列的所有值之和 |
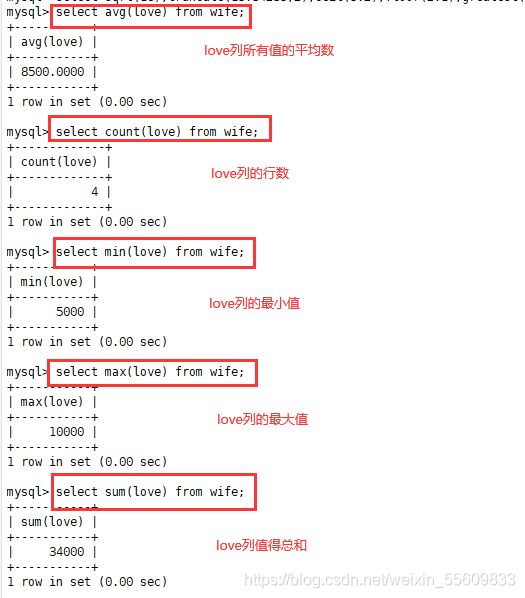
SELECT avg(Sales) FROM Store_Info;
SELECT count(store_Name) FROM Store_Info;
SELECT count(DISTINCT store_Name) FROM Store_Info;
SELECT max(Sales) FROM Store_Info;
SELECT min(sales) FROM Store_Info;
SELECT sum(sales) FROM Store_Info;
SELECT count(DISTINCT store_Name) FROM Store_Info;
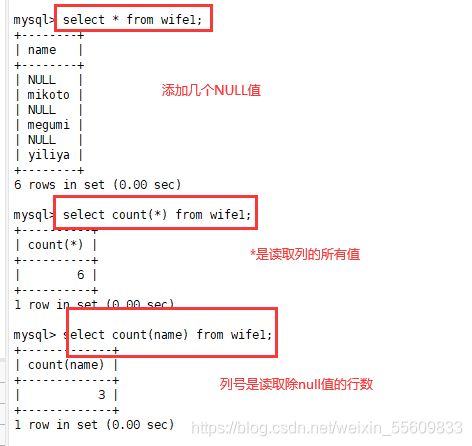
SELECT count(*) FROM Store_Info;
#count(*)包括了所有的列的行数,在统计结果的时候,不会忽略列值为NULL
#count(列名)只包括列名那一列的行数,在统计结果的时候,会忽略列值为NULL的行
3.字符串函数
| 函数名 | 解释 |
|---|---|
| trim() | #返回去除指定格式的值 |
| concat(x,y) | #将提供的参数x和y拼接成一个字符串 |
| substr(x,y) | #获取从字符串x中的第y个位置开始的字符串,跟substring()函数作用相同 |
| substr(x,y,z) | #获取从字符串x中的第y个位置开始长度为z的字符串 |
| length(x) | #返回字符串x的长度 |
| replace(x,y,z) | #将字符串z替代字符串x中的字符串y |
| upper(x) | #将字符串x的所有字母变成大写字母 |
| lower(x) | #将字符串x的所有字母变成小写字母 |
| left(x,y) | #返回字符串x的前y个字符 |
| right(x,y) | #返回字符串x的后y个字符 |
| repeat(x,y) | #将字符串x重复y次 |
| space(x) | #返回x个空格 |
| strcmp (x,y) | #比较x和y,返回的值可以为-1,0,1 |
| reverse(x) | #将字符串x反转 |
SELECT concat(Region,Store_Name) FROM location WHERE Store_Name = 'Boston';
#如sql_mode开启开启了PIPES_AS_CONCAT,"||"视为字符串的连接操作符而非或运算符,和字符串的拼接函数concat相类似,这和Oracle数据库使用方法一样的
SELECT Region || ' ' || Store_Name FROM location WHERE Store_Name = 'Boston';
SELECT substr(Store_Name,3) FROM location WHERE Store_Name = 'Los Angeles';
SELECT substr(Store_Name,2,4) FROM location WHERE Store_Name = 'New York';
SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);
#[位置]:的值可以为 LEADING(起头),TRAILING(结尾),BOTH(起头及结尾)。
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格
SELECT TRIM(LEADING 'Ne' FROM 'New York');
SELECT Region,length(Store_Name) FROM location;
SELECT REPLACE(Region,'ast','astern')FROM location;



三、结合函数的一些指令
1.group by
---- GROUP BY ---- 对GROUP BY后面的栏位的查询结果进行汇总分组,通常是结合聚合函数一起使用的
GROUP BY有一个原则,就是SELECT后面的所有列中,没有使用聚合函数的列,必须出现在GROUP BY后面。
语法:SELECT "栏位1",SUM("栏位2") FROM "表名" GROUP BY "栏位1";
SELECT Store_Name,SUM(Sales) FROM Store_Info GROUP BY Store_Name ORDER BY sales desc;

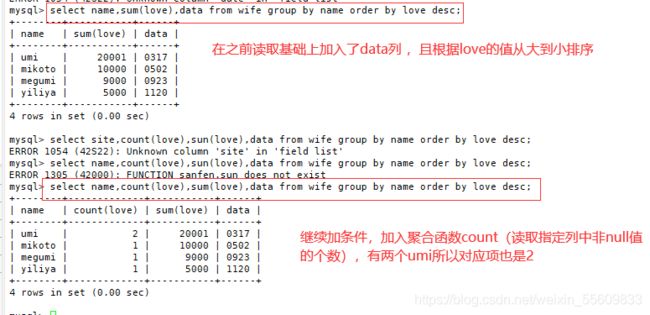
2.having
---- HAVING ---- 用来过滤由GROUP BY语句返回的记录集,通常与GROUP BY语句联合使用
HAVING语句的存在弥补了wHERE关键字不能与聚合函数联合使用的不足。如果被SELECcT的只有函数栏,那就不需要GROUP BY子句。
语法:SELECT "栏位1",SUM("栏位2") FROM "表格名" GROUP BY "栏位1" HAVING (函数条件);
SELECT Store_Name,SUM(Sales) FROM Store_Info GROUP BY Store_Name HAVING SUM (Sales) > 1500;

3.别名
---- 别名 ---- 栏位别名表格别名
语法:SELECT "表格别名"."栏位1” [AS] "栏位别名" FROM "表格名" [AS] "表格别名"
SELECT A.Store_Name Store,SUM(A.Sales) "Total Sales" FROM Store_Info A GROUP BY A.Store_Name;
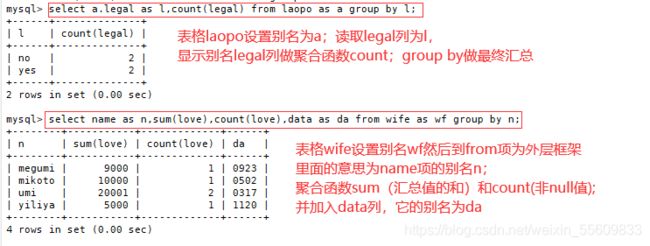
4.子查询
---- 子查询 ---- 连接表格,在WHERE子句或 HAVING子句中插入另一个 SQL语句
语法: SELECT "栏位1" FROM "表格1" WHERE "栏位2" [比较运算符] #外查询
(SELECT "栏位1" FROM "表格2" WHERE "条件"); #内查询
#可以是符号的运算符,例如=、>、<、>=、<= ;也可以是文字的运算符,例如LIKE、 IN、 BETWEEN
SELECT SUM(Sales) FROM Store Info WHERE Store Name IN
(SELECT Store_ Name FROM location WHERE Region = 'West') ;
SELECT SUM(A. Sales) FROM Store Info A WHERE A. Store Name IN
(SELECT Store Name FROM location B WHERE B.Store Name = A. Store Name) ;

5.EXISTS
用来测试内查询有没有产生任何结果,类似布尔值是否为真
如果有的话,系统就会执行外查询中的SQL语句
若是没有,那整个SQL语句就不会产生任何结果
SELECT 字段1 FROM 表1 WHERE EXISTS (SELECT * FROM 表2 WHERE 条件);
例:
use sanfen;
select region from laopo where exists (select * from wife where money = '10000');
select site from laopo where exists (select * from wife where money = '801');
select * from laopo where love = '10000';
select * from laopo where love = '801';
select name from laopo;

四、连接查询
1.inner join——等值相连
只返回两个表中联接字段相等的行
SELECT 字段 FROM 表1 INNER JOIN 表2 ON 表1.字段 = 表2.字段;
例:
select * from laopo AS A inner join wife AS B on A.name = B.name;

2.left join——左联接
返回包括左表中所有记录和右表中联接字段相等的记录
SELECT 字段 FROM 表1 LEFT JOIN 表2 ON 表1.字段 = 表2.字段;
例:
select * from laopo AS A left join wife AS B on A.name = B.name;
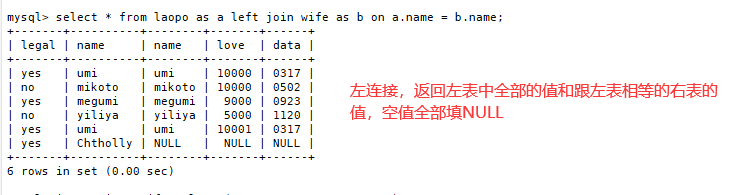
3.right join——右联接
返回包括右表中的所有记录和左表中联接字段相等的记录
SELECT 字段 FROM 表1 RIGHT JOIN 表2 ON 表1.字段 = 表2.字段;
例:
select * from laopo AS A right join wife AS B on A.name = B.name;
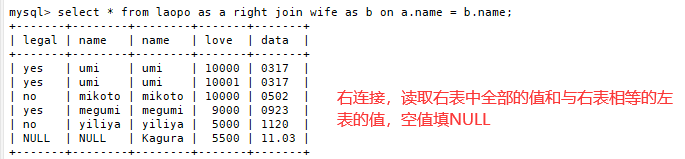
五、CREATE VIEW(视图)
CREATEVIEW----视图,可以被当作是虚拟表或存储查询。
视图跟表格的不同是,表格中有实际储存资料,而视图是建立在表格之.上的一个架构,它本身并不实际储存资料。
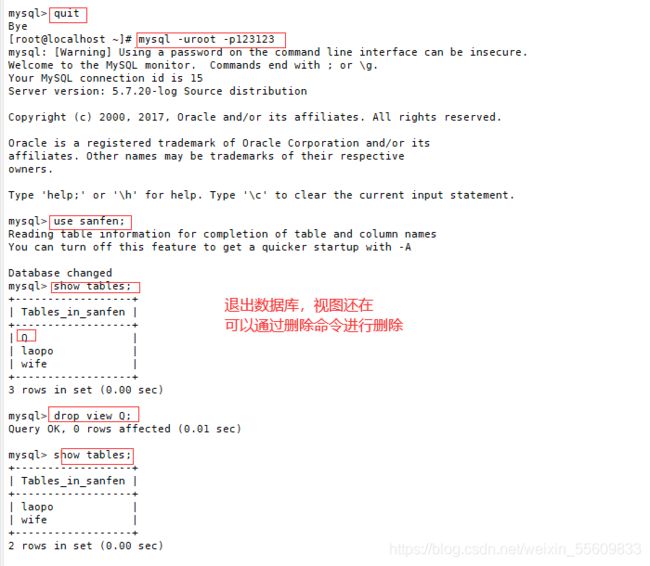
临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。
视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。比如你要对几个表进行连接查询,而且还要进行统计排
序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一一个表查询一样,很方便。
语法: CREATE VIEW "视图表名" AS "SELECT 语句";
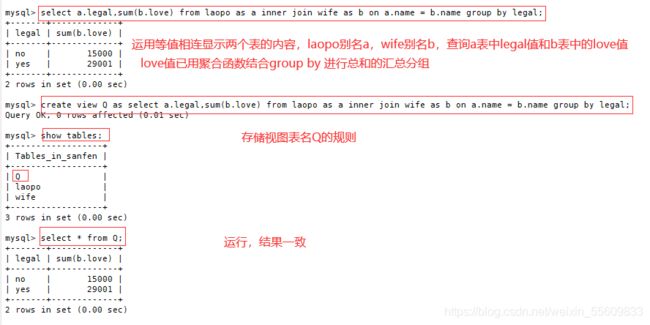
select a.legal,sum(b.love) from laopo as a inner join wife as b on a.name = b.name group by legal;
create view Q as select a.legal,sum(b.love) from laopo as a inner join wife as b on a.name = b.name group by legal;
Query OK, 0 rows affected (0.01 sec)
show tables
drop view Q
六、UNION联集
将两个SQL语句的结果合并起来,两个sQL语句所产生的栏位需要是同样的资料种类
UNION:生成结果的资料值将没有重复,且按照字段的顺序进行排序
语法: [SELECT 语句1] UNION [SELECT 语句2];
UNIONALL:将生成结果的资料值都列出来,无论有无重复
语法: [SELECT 语句1] UNION ALL [SELECT 语句2] ;
select legal from laopo union select love from wife;
mysql> select name from laopo union select name from wife;
mysql> select name from laopo union all select name from wife;

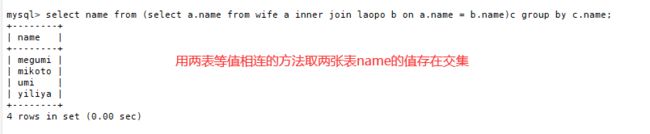
1.交集值
取两个SQL语句结果的交集
select name from (select a.name from wife a inner join laopo b on a.name = b.name)c group by c.name;
select distinct name from wife where name in (select name from laopo);

2.无交集值
显示第一个SQL语句的结果,且与第二个SQL语句没有交集的结果,还不能重复
select distinct name from wife where (name) not in (select name from laopo);
select a.*,b.* from wife a left join laopo b using (name);
select distinct name from wife a left join laopo b using(name) where b.name is null;


3.CASE
是SQL用来作为IF-THEN-ELSE之类逻辑的关键字
SELECT CASE (字段名)
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
……
ELSE 结果N
END
FROM 表名
#条件可以是一个数值或是公式,且 ELSE 子句不是必须的
例:
select * from wife;
mysql> select case name
-> when 'kagura' then love + 1000
-> when 'yiliya' then love - 1000
-> else love * 2
-> end
-> A,name
-> from wife;

七、数值计算
创建表即插入数据,方便举例
create table game (name char(10),atk int(5));

1.算排名
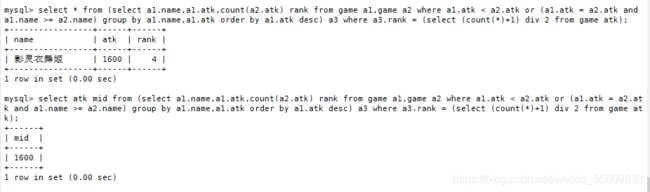
表格自我连接(self join),然后将结果依序列出,算出每一行之前(包括那一行本身)有多少行数
select a1.name,a1.atk,count(a2.atk) rank from game a1,game a2 where a1.atk <a2.atk or (a1.atk=a2.atk and a1.name=a2.name) group by a1.name order by a1.atk desc;
#当A1的atk字段值小于A2的atk字段值、或者两表atk字段值相等并且name字段值相等时,从A1和A2表中查询A1的name字段值、A1的atk字段值、和A2的atk字段的非空值 rank是别名,并为A1的name字段分组
#最后A1的atk字段降序排序

select * from (select a1.name,a1.atk,count(a2.atk) rank from game a1,game a2 where a1.atk < a2.atk or (a1.atk = a2.atk and a1.name >= a2.name) group by a1.name,a1.atk order by a1.atk desc) a3 where a3.rank = (select (count(*)+1) div 2 from game atk);
select atk mid from (select a1.name,a1.atk,count(a2.atk) rank from game a1,game a2 where a1.atk < a2.atk or (a1.atk = a2.atk and a1.name >= a2.name) group by a1.name,a1.atk order by a1.atk desc) a3 where a3.rank = (select (count(*)+1) div 2 from game atk);
#将之前算排名的SQL语句结果赋予别名为A3
#A3的rank字段的非null值+1除2取商[(5+1)/2 商为3]
#当rank字段为3时,查询atk字段的值并赋予别名mid
2.算累积总计
select a1.*,sum(a2.atk)
-> sum_atk from game a1,game a2 where a1.atk < a2.atk
-> or(a1.atk=a2.atk and a1.name=a2.name)
-> group by a1.name order by a1.atk desc;
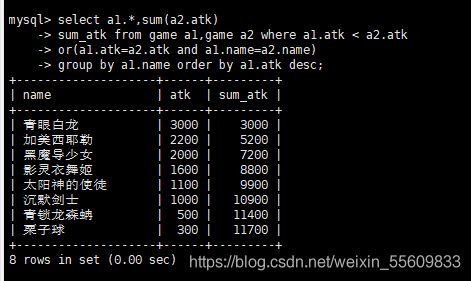
3.算总和百分比
select a1.*,a1.atk/(
-> select sum(atk) from game)
-> dsum from game a1,game a2 where a1.atk < a2.atk
-> or (a1.atk=a2.atk and a1.name=a2.name)
-> group by a1.name;
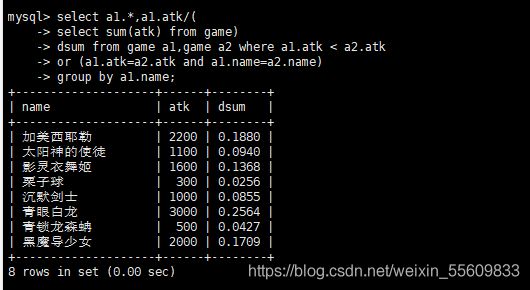
4.算累积总和百分比
select a1.name,a1.atk,sum(a2.atk),sum(a2.atk)/ (select sum(atk) from game) dsum from game a1,game a2 where a1.atk < a2.atk or (a1.atk=a2.atk and a1.name=a2.name) group by a1.name order by a1.atk desc;
select a1.name,a1.atk,sum(a2.atk),round(sum(a2.atk)/ (select sum(atk) from game)*100) || '%' dsum from game a1,game a2 where e a1.atk < a2.atk or (a1.atk=a2.atk and a1.name=a2.name) group by a1.name order by a1.atk desc;
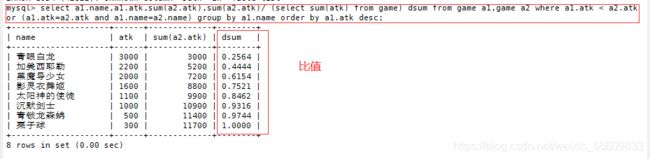

5.空值(NULL) 和无值("’) 的区别
1.无值的长度为0,不占用空间的;而NULL值的长度是NULL, 是占用空间的。
2. IS NULL或者IS NOT NULL, 是用来判断字段是不是为NULL或者不是NULL, 不能查出是不是无值的。
3.无值的判断使用=’ ‘或者<>’ '来处理。<>代表不等于。
4.在通过count()指定字段统计有多少行数时,如果遇到NULL 值会自动忽略掉,遇到无值会加入到记录中进行计算。


八、正则表达式
匹配模式描述
| 匹配模式 | 描述 | 实例 |
|---|---|---|
| ^ | 匹配文本的开始字符 | ‘^bd’ 匹配以 bd 开头的字符串 |
| $ | 匹配文本的结束字符 | ‘qn$’ 匹配以 qn 结尾的字符串 |
| . | 匹配任何单个字符 | ‘s.t’ 匹配任何 s 和 t 之间有一个字符的字符串 |
| ***** | 匹配零个或多个在它前面的字符 | ‘fo*t’ 匹配 t 前面有任意个 o |
| + | 匹配前面的字符 1 次或多次 | ‘hom+’ 匹配以 ho 开头,后面至少一个m 的字符串 |
| 字符串 | 匹配包含指定的字符串 | ‘clo’ 匹配含有 clo 的字符串 |
| p1 | p2 | 匹配 p1 或 p2 |
| […] | 匹配字符集合中的任意一个字符 | ‘[abc]’ 匹配 a 或者 b 或者 c |
| [^…] | 匹配不在括号中的任何字符 | ‘[^ab]’ 匹配不包含 a 或者 b 的字符串 |
| {n} | 匹配前面的字符串 n 次 | ‘g{2}’ 匹配含有 2 个 g 的字符串 |
| {n,m} | 匹配前面的字符串至少 n 次,至多m 次 | ‘f{1,3}’ 匹配 f 最少 1 次,最多 3 次 |
语法: SELECT "栏位" FROM "表名" WHERE "栏位" REGEXP { 模式};
SELECT * FROM Store Info WHERE Store Name REGEXP 'os' ;
SELECT * FROM Store Info WHERE Store_ Name REGEXP '^[A-G] ';
SELECT * FROM Store_ Info WHERE Store_ Name REGEXP 'Ho|Bo' ;

九、存储过程
存储过程是一组为 了完成特定功能的SQL语句集合。
存储过程在使用过程中是将常用或者复杂的工作预先使用SQL语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据
库服务器中。当需要使用该存储过程时,只需要调用它即可。存储过程在执行上比传统SQL速度更快、执行效率更高。
存储过程的优点:
1、执行一.次后,会将生成的二进制代码驻留缓冲区,提高执行效率
2、SQL语句加上控制语句的集合,灵活性高
3、在服务器端存储,客户端调用时,降低网络负载
4、可多次重复被调用,可随时修改,不影响客户端调用
5、可完成所有的数据库操作,也可控制数据库的信息访问权限
1.创建存储过程
DELIMITER $$ #将语句的结束符号从分号;临时改为两个$$(可以是自定义)
CREATE PROCEDURE Proc() #创建存储过程,过程名为Proc,不带参数
-> BEGIN #过程体以关键字BEGIN开始
-> select * from Store_ Info; #过程体语句
-> END $$ #过程体以关键字END 结束
DELIMITER ; #将语句的结束符号恢复为分号

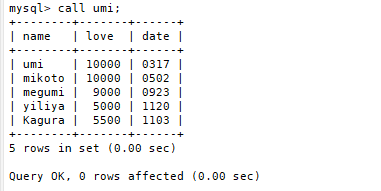
2.调用存储过程
CALL Proc;
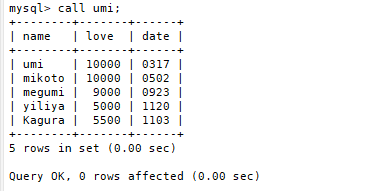
3.查看存储过程
SHOW CREATE PROCEDURE [数据库. ]存储过程名; #查看某个存储过程的具体信息
SHOW CREATE PROCEDURE Proc;
SHOW PROCEDURE STATUS [LIKE '%Proc%'] \G
4.存储过程的参数
IN输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
OUT输出参数:表示过程向调用者传出值(可以返回多个值) (传出值只能是变量)
INOUT输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
DELIMITER c r e a t e p r o c e d u r e u m i 1 ( i n l a o p o c h a r ( 20 ) ) − > b e g i n − > s e l e c t ∗ f r o m w i f e w h e r e n a m e = l a o p o ; − > e n d create procedure umi1(in laopo char(20)) -> begin -> select * from wife where name=laopo; -> end createprocedureumi1(inlaopochar(20))−>begin−>select∗fromwifewherename=laopo;−>end
delimiter $$
call umi1(‘umi’);

5.删除存储过程
存储过程内容的修改方法是通过删除原有存储过程,之后再以相同的名称创建新的存储过程。
DROP PROCEDURE IF EXISTS umi1; #仅当存在时删除,不添加IF EXISTS时,如果指定的过程不存在,则产生一个错误

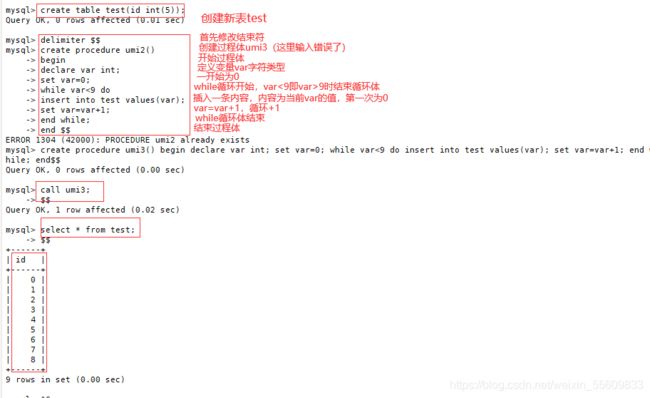
6.存储过程的控制语句
create table t (id int(10));
insert into t values(10);
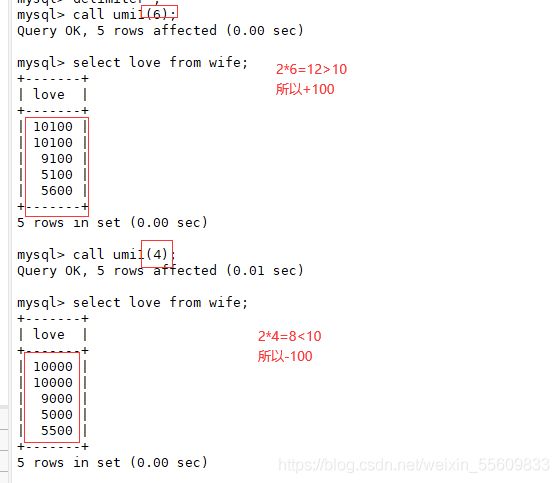
(1)条件语句if-then-else ,... end if
DELIMITER $$
create procedure umi1(in num int(10))
-> begin
-> declare var int;
-> set var=num*2;
-> if var>=10 then
-> update wife set love=love+100;
-> else
-> update wife set love=love-100;
-> end if;
-> end $$
DELIMITER ;
CALL Proc2(6) ;

(2)循环语句while .... end while
DELIMITER $$
create procedure umi2()
-> begin
-> declare var int;
-> set var=0;
-> while var<9 do
-> insert into test values(var);
-> set var=var+1;
-> end while;
-> end $$
DELIMITER ;
CALL umi3;