python爬虫爬取虎扑湖人论坛专区帖子数据,并存入MongoDB数据库中
今天就带大家从头到尾一步一步带着大家爬取虎扑论坛帖子的数据,里面涉及到的一些知识,我会给出学习的连接,大家可以自行去学习查看。
前期准备
首先我们打开虎扑NBA论坛,我选择的是湖人专区(小湖迷一个)。虎扑湖人专区
我们需要爬取的数据有这些

好了 每一个小帖子我们需要爬取图中的这七个数据,接下来我们利用浏览器的开发者模型,查看我们需要的东西。
我举个例子:
首先打开浏览器的开发者模式,谷歌浏览器快捷键是F12
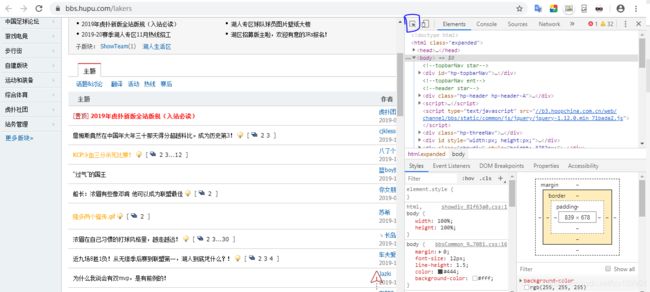
点击蓝色方框内的小箭头,点击后放在帖子主题上我们会定位到该主题所在的前端位置。

右侧蓝框内就是左边主题所在的位置,我们可以看到,这个主题是在 a 标签内部 同时又被b标签包括着。
这里,咱们需要注意一下,因为论坛的第一条帖子主题是加粗的,其他的帖子并没有加粗。
好了 我们可以将这条信息 写为 【帖子主题 |a class_truetit】
接着就是按照相同的套路获取剩下六条数据了,这里我直接把这七条数据进行汇总,大家也可以一个一个按照上面的方法进行一一查找比对。
| 名字 | 数据 |
|---|---|
| 帖子主题 | a class_truetit |
| 作者 | a class_aulink |
| 创贴时间 | div class_author box |
| 回复数 | span class_ansour box |
| 浏览数 | span class_ansour box |
| 最后回复的人 | span class_endauthor |
| 最后回复时间 | div class_endreplay box |
好了,前期准备工作完成了 ,接下来咱们开始写爬虫了。
开始写爬虫
首先需要导入pymongo、requests、BeautifulSoup 这三个模块
import pymongo
import requests
from bs4 import BeautifulSoup
这里需要你简单的掌握BeautifulSoup的用法,具体教程BeautifulSoup4.0基础
pymongo 这个模块是用来连接MongoDB数据库的模块。具体用法见链接MongoDB数据库教程
首先写一个数据库连接的方法
def mongoconne():
client = pymongo.MongoClient("mongodb://localhost:27017/")//数据库连接
mydb = client["runoodbd"]//进入到该数据库,如果不存在就创建
mycol = mydb["HUPU"]//进入到该表,如果没有就创建
return mycol
接下来写数据库插入函数
def insertmongo(mycol,title,author,starttime,replaynumber,browsenumber,endauthors,endreplaytimes):
mydict = {"title":"title","author":"author","starttime":"starttime","replaynumber":"replaynumber","browsenumber":"browsenumber","endauthors":"endauthors","endreplaytimes":"endreplaytimes"}
mydict["title"]=title
mydict["author"]=author
mydict["starttime"]=starttime
mydict["replaynumber"]=replaynumber
mydict["browsenumber"]=browsenumber
mydict["endauthors"]=endauthors
mydict["endreplaytimes"]=endreplaytimes
mycol.insert_one(mydict)
这里我写的比较麻烦,但是理解起来比较容易。方法参数分别为上一个数据库连接函数返回的参数,还有七个帖子数据。首先初始化一个mydict 字典,然后给对应的key赋值相应的value。这个字典的初始化也可以写成下面这种形式
message = ('title','author','starttime','replaynumber','browsenumber','endauthors','endreplaytimes')//很显然,这是一个元组
mydict = mydict.fromkeys(message)
print(str(mydict))
输出结果是:
{'title': None, 'author': None, 'starttime': None,'replaynumber': None,'browsenumber': None,'endauthors': None,'endreplaytimes': None}
字典 fromkeys() 方法
接下来开始获取帖子数据
def findallmess(link,number):
titleset=[]
authorset=[]
starttimeset=[]
replaynumberset=[]
browsenumberset=[]
endauthorset=[]
endreplaytimeset=[]
link = link+str(number)
re = requests.get(link)
soup = BeautifulSoup(re.text,"lxml")
print(re.text)
titles = soup.findAll('a',class_='truetit')#.b.text
authors = soup.findAll('a',class_='aulink')#text
starttimes = soup.findAll('div',class_='author box')#text.a.find_next_sibling("a")
replaynumbers = soup.findAll('span',class_='ansour box')#text.split("/") [0].strip()browsenumber = replaynumber[1].strip()
endauthors = soup.findAll('span',class_="endauthor")#text
endreplaytimes = soup.findAll('div',class_="endreply box")#text .a
for title in titles:
#print(title.text)
titleset.append(title.text)
for author in authors:
authorset.append(author.text)
for starttime in starttimes:
starttimeset.append(starttime.a.find_next_sibling("a").text)
for replaynumber in replaynumbers:
replaynumberset.append(replaynumber.text.split("/")[0].strip())
browsenumberset.append(replaynumber.text.split("/")[1].strip())
for endauthor in endauthors:
endauthorset.append(endauthor.text)
for endreplaytime in endreplaytimes:
endreplaytimeset.append(endreplaytime.a.text)
整体思路就是为每一个数据创建一个集合用于存储数据,然后通过soup.findAll()方法获取本页面所有的特定信息,返回值是集合形式。然后通过for循环对集合里面的每一个元素进行处理,添加到我们事先初始化的集合里。里面可能会涉及到一些数据的处理,不懂的同学可以百度搜一下,说的很明白的。
总结
目前的爬虫就是将当前连接页面下载下来,然后通过解析和查询方法,找到我们需要的数据,然后存入到数据库中。后续,我们会继续学习如何进行免登录,查找ajax返回的数据,以及学习自动化爬虫框架。
如果还有不明白的地方,欢迎大家浏览,全部代码我会上传到Github上。
代码地址