MySQL索引的生效与失效、SQL语句的执行流程、undo log和redo log
目录
一、数据准备
二、索引例子
1、索引用于排序时的例子
2、索引用于 where 筛选例子
3、索引条件下推
4、更多例子
三、SQL语句的执行流程
四、undo log与redo log
1、undo log
2、redo log
一、数据准备
下载地址:
链接:https://pan.baidu.com/s/15FLw7PItJIecT8tBZt7QjQ?pwd=fejt
提取码:fejt
①找到mysql配置文件:my.ini,在 [mysqld] 下添加 secure_file_priv= 重启 MySQL 服务器,让选项生效(为了下面文件导入操作权限)
②执行 db.sql 内的脚本,建表
③执行 LOAD DATA INFILE 'D:\\big_person.txt' INTO TABLE big_person; 注意实际路径根据情况修改
测试表 big_person(此表数据量较大,如果与其它表数据一起提供不好管理,故单独提供),数据行数 100 万条,列个数 15 列。为了更快速导入数据,这里采用了 load data infile 命令配合 *.txt 格式数据
 可以看到里面有1000000条记录
可以看到里面有1000000条记录
有这些数据项

二、索引例子
1、索引用于排序时的例子
create index first_idx on big_person(first_name);
create index last_idx on big_person(last_name);
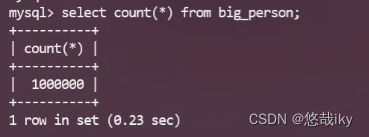
先看看里面有哪些索引,firtst_name和last_name索引是分别建在列上的

10条记录用了两秒多,实际开发中是不可以接受的
![]()
![]()
说明上面建的两个索引是失效的,那我们应该如何建立索引
我们把上面两个索引删掉,建立一个组合索引,多列排序需要用组合索引。
alter table big_person drop index first_idx;
alter table big_person drop index last_idx;
create index last_first_idx on big_person(last_name,first_name);
速度变成了0.03秒,通过explain,也能查看用到了刚刚建立的索引
多列排序需要遵循最左前缀原则,这时候发现是没有用到索引的,因为建立索引时lastname在左,如果单纯只用到firstname,没有从最左前缀也是不可以的。

多列排序升降序需要一致
2、索引用于 where 筛选例子
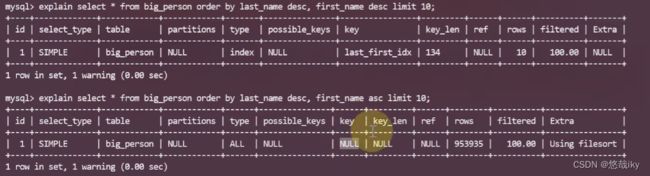
模糊查询需要遵循字符串最左前缀原则
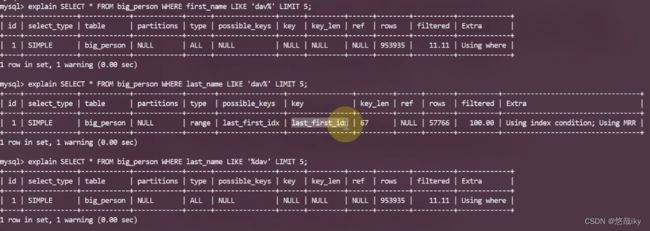
组合索引需要遵循最左前缀原则
create index province_city_county_idx on big_person(province,city,county);


函数及计算问题
在列上使用函数运算索引会失效,但是在值做函数运算不会失效
create index birthday_idx on big_person(birthday);
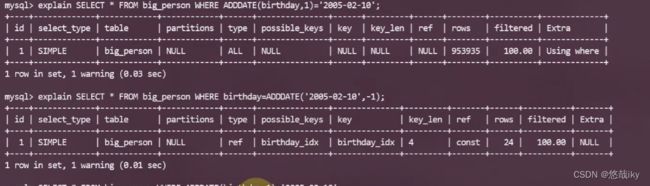
隐式类型转换问题
手机列本身类型为字符串类型,字符串和数值比较会出现隐式类型转换,本质上列上使用了函数导致索引失效。
create index phone_idx on big_person(phone);
3、索引条件下推
1、哪些条件能利用索引
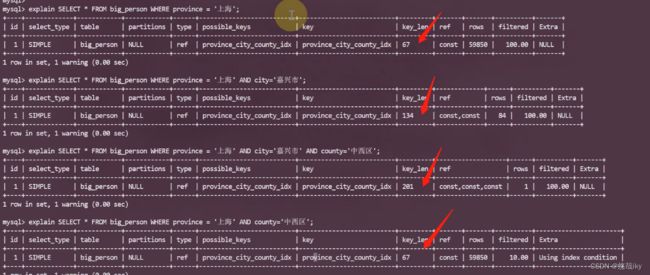
explain SELECT * FROM big_person WHERE province = '上海';
explain SELECT * FROM big_person WHERE province = '上海' AND city='嘉兴市';
explain SELECT * FROM big_person WHERE province = '上海' AND city='嘉兴市' AND county='中西区';
explain SELECT * FROM big_person WHERE province = '上海' AND county='中西区';
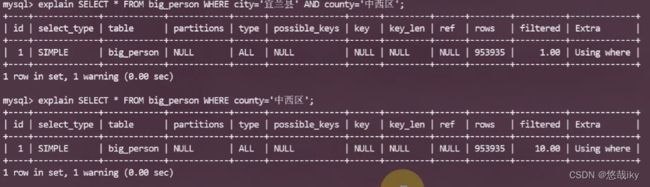
都用到了索引,但是并不是全部条件都用上,key_len是代表你所用到索引的长度,这个是组合索引,一个字段长度为67。看第四个省中间和市断开了,自然也只有省一个索引字段长度。
2、MySQL 执行条件判断的时机有两处:引擎层(包括了索引实现)和服务层
上面第 4 条 SQL 中仅有 province 条件能够利用索引,在引擎层执行
但 county 条件仍然要交给服务层处理
在 5.6 之前,服务层需要判断所有记录的 county 条件,性能非常低
5.6 以后,引擎层会先根据 province 条件过滤,满足条件的记录才在服务层处理 county 条件
3、索引条件下推
SELECT * FROM big_person WHERE province = '上海' AND county='中西区';
SET optimizer_switch = 'index_condition_pushdown=off';//这个是关闭下推,效率会慢许多
4、更多例子
1、二级索引覆盖例子
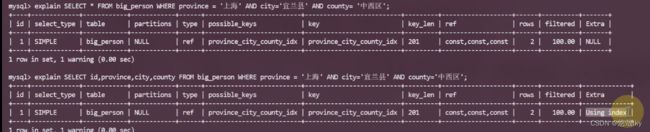
//select *要走两次索引,先走二级索引,找到主键值,再根据主键回到主键索引找到其他信息
explain SELECT * FROM big_person WHERE province = '上海' AND city='宜兰县' AND county= '中西区';
//索引覆盖:
explain SELECT id,province,city,county FROM big_person WHERE province = '上海' AND city='宜兰县' AND county='中西区';
Using index说明出现了索引覆盖
2、表连接需要在连接字段上建立索引
3、不要迷信网上说法,具体情况具体分析
create index first_idx on big_person(first_name);
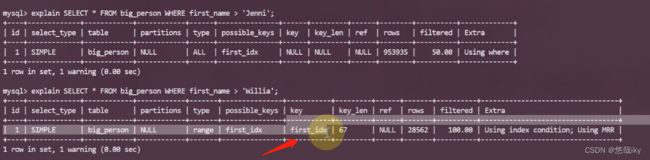
explain SELECT * FROM big_person WHERE first_name > 'Jenni';
explain SELECT * FROM big_person WHERE first_name > 'Willia';
explain select * from big_person where id = 1 or id = 190839;
explain select * from big_person where first_name = 'David' or last_name = 'Thomas';
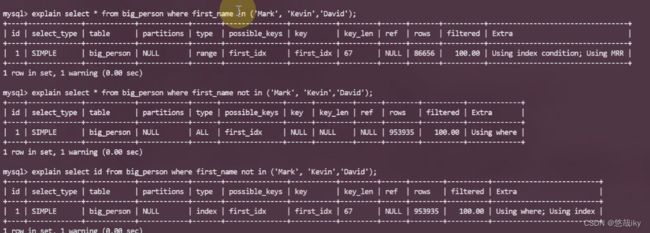
explain select * from big_person where first_name in ('Mark', 'Kevin','David');
explain select * from big_person where first_name not in ('Mark', 'Kevin','David');
explain select id from big_person where first_name not in ('Mark', 'Kevin','David');
为什么W会走索引呢?大于W的人名相对于比较少,占比少,应用索引。而比J大的记录人名很多,就算走索引也不会提高太多效率,所以不会走索引。
or并不是不会走索引,看第二个查询,走了两个索引,一定要以实际情况为准。
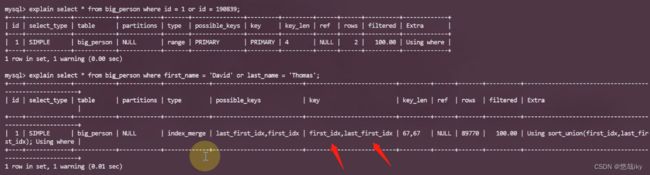
以上实验基于 5.7.27,其它如 !=、is null、is not null 是否使用索引都会跟版本、实际数据相关,以优化器结果为准
三、SQL语句的执行流程
执行 SQL 语句 select * from user where id = 1 时发生了什么
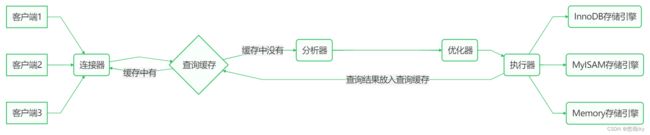
1.连接器:负责建立连接、检查权限、连接超时时间由 wait_timeout 控制,默认 8 小时
2.查询缓存:会将 SQL 和查询结果以键值对方式进行缓存,修改操作会以表单位导致缓存失效
3.分析器:词法、语法分析
4.优化器:决定用哪个索引,决定表的连接顺序等
5.执行器:根据存储引擎类型,调用存储引擎接口
6.存储引擎:数据的读写接口,索引、表都在此层实现
四、undo log与redo log
1、undo log
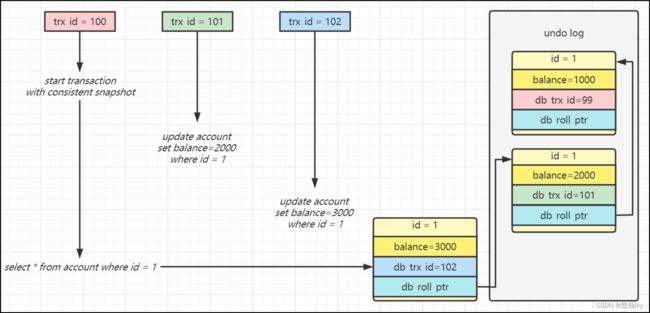
undo log的作用有两个:
回滚数据,以行为单位,记录数据每次的变更,一行记录有多个版本并存
多版本并发控制,即快照读(也称为一致性读),让查询操作可以去访问历史版本
事务有一个单调递增的编号,红色进行一个查询,绿色进行修改1号账户2000,蓝色修改1号为3000,绿色事务执行完之后蓝色事务也更新完了,最新数据是3000,红色事务是在绿蓝之后执行查询,因为是快照读也就是依靠这个undo log,因为有一个版本号,最新版本是102,红色查询事务会比较版本号,他只会找到小于等于自己的事务。
2、redo log
