JavaSE基础(六) ---数组*
目录
一、数组的基本概念
1、数组是什么?
2、数组的创建和初始化
2.1、数组的创建
2.2数组的初始化
Java中数组的初始化可以分为“静态初始化”和“动态初始化”.
二、数组的使用
1、数组的访问
1.1数组元素的访问
1.2数组的遍历
1.3、Arrays工具类
1.4数组元素的遍历存储
三、引用类型---数组
1、Java虚拟机(JVM)的内存分布
2、基本类型变量和引用类型变量的区别
3、Java中的null
4、数组引用的一些注意事项
四、数组的应用
1、保存数据
2、数组传参--参数传数组类型(引用类型)
3、数组类型返回值
五、数组的相关练习
1、数组转字符串
2、数组拷贝的四种方法*
2.1、简单的拷贝(通过数组遍历)
2.2、 使用Arrays中copyOf方法进行拷贝
2.3、 System.arraycopy()拷贝
2.4数组克隆
2.5、拷贝数组某个范围
3、数组中的二分查找
4、数组中的顺序查找(查找指定数组元素)
5、数组排序(逆序排序)
6、数组的冒泡排序*
六、二维数组
本章节,将对java中数组的基本内容和一些知识点拓展进行整理。
在java中的数组跟我们的c语言会有点不一样,可以说是在一些方面的应用会更加方便和灵活,接下来我会从数组的基本概念开始介绍。✨✨✨
一、数组的基本概念
1、数组是什么?
可以理解成数组是一个具有多个相同类型元素的集合,比如:一个房子里住着6个男人,他们的性别都是男(想象成是一种类型),6个元素,那么该数组就是有6个相同类型元素的数组。
一个数组的创建,其实也是在内存上开辟了一块栈空间,而数组内所创建的元素(通过new运算符创建出来的对象)是在堆上的,把该数组的首元素地址存储在栈上开辟的栈空间内(此时在栈空间上的是一个引用变量),而引用变量是指向堆里的对象。
【注意】:数组在内存中的空间是连续的。
2、数组的创建和初始化
2.1、数组的创建
数组创建的基本格式:
T[ ] 数组名 = new T[N];
- T为数组中的元素类型
- “=”左边T[ ]括号内不能填写
- T[ ]为数组类型
- N为数组长度
//创建数组
int []arr1=new int[5]; //创建了一个可以存放5个整型元素的数组
double []arr2=new double[5]; //创建了一个可以存放5个双精度浮点型元素的数组
boolean []arr1=new boolean[7];//创建了一个可以存放7个布尔类型元素的数组
2.2数组的初始化
Java中数组的初始化可以分为“静态初始化”和“动态初始化”.
1、动态初始化:
在创建数组时,直接指定数组中元素的个数
//数组的动态初始化 int []arr1=new int[5]; double []arr2=new double[6];
2、静态初始化:
在创建数组的过程顺便给数组内的元素赋值,不指定数组的长度,系统会通过你数组内的元素自动计算元素个数。
//数组的静态初始化(有多种写法) int []arr1=new int[]{1,2,3,4}; int []arr2={1,2,3,4,5,6}; //静态初始化可以简写,new int[]可以省略,编译器编译代码时会还原 double []arr3=new double{1.2,4.5,8.8}; double []arr4={1.5,3.7,4.5};在Java中数组的初始化其实可以用c语言中数组初始化的格式([ ]在arr前),但不推荐使用
int arr1[]={1,2,3,4,5}; double arr2[]={1.2,2.5,6.6};静态初始化中的有元素类型一定要跟数组类型一致,不能掺杂其他不同的类型元素!
【使用动态或静态初始化时注意】:
- 静态初始化 和动态初始化 可以分成两步(省略格式就不可以分成两步)
//动态初始化分成两步
int []arr1;
arr1=new int[6];
//静态初始化分成两步
int []arr2;
arr2=new int{1,2,3,4,5,6};
//省略格式如果分成两步,会编译报错!
int []arr3;
arr3={1,2,3,4,5,6};- 在初始化数组的时候,如果苦恼于不知道要确定数组内容为什么时,可以使用动态初始化。
- 初始化数组时,如果只指定数组长度,并没有指定数组内容的话,数组内的元素会根据数组类型默认会对应其默认值。
| 类型 | 默认值 |
| int | 0 |
| short | 0 |
| long | 0 |
| float | 0.0f |
| double | 0.0 |
| char | /u0000 |
| boolean | false |
| byte | 0 |
如果数组类型为引用类型,其默认值为null (null表示引用表量不指向任何对象)
二、数组的使用
1、数组的访问
1.1数组元素的访问
数组在内存中是一段连续的空间,空间的编号都是从0开始的,依次递增,该编号称为数组的下标,数组可以通过下 标访问其任意位置的元素。比如:
public class TestDemo1 { public static void main(String[] args) { int arr1[]=new int[]{1,2,3,4,5,6}; System.out.println(arr1[0]); System.out.println(arr1[3]); System.out.println(arr1[5]); } } 运行结果为: 1 4 6也可以以通过数组的下标来对数组内的元素进行修改.
int []arr=new int[]{1,2,3,4}; arr[1]=4; System.out.println(arr[1]); //打印出来不是2而是4
【注意事项】
1. 数组是一段连续的内存空间,因此支持随机访问,即通过下标访问快速访问数组中任意位置的元素
2. 下标从0开始,介于[0, N)之间不包含N,N为元素个数,不能越界,否则会报出下标越界异常。

 java.lang.ArrayIndexOutOfBoundsException:数组下标越界异常
java.lang.ArrayIndexOutOfBoundsException:数组下标越界异常
1.2数组的遍历
"遍历" 是指将数组中的所有元素都访问一遍, 访问是指对数组中的元素进行某种操作,可以用for循环对数组内每一个元素进行打印或修改。
//数组遍历 int[]array = new int[]{1,2,3,4,5}; for(int i=0;i<5;i++) { System.out.print(array[i]+" "); } //打印结果为:1 2 3 4 5在Java中,我们可以不像c语言一样自己找元素的个数有几个才进行遍历,Java中可以识别数组长度,我们可以借助其进行遍历.(数组对象.length)
用上述for循环对数组进行遍历,可以帮助我们更方便地实现对数组每一个元素的打印或修改,即使该数组有几百个元素,也可以遍历。(但前提是得知道数组长度才可以)
在Java中,我们可以不像c语言一样自己找元素的个数有几个才进行遍历,Java中可以识别数组长度,我们可以借助其进行遍历.(数组对象.length)
//数组遍历(array.length) int[]array = new int[]{1,2,3,4,5}; for(int i=0;i
for-each遍历数组 (for循环的增强型)
for-each 是 for 循环的另外一种使用方式. 能够更方便的完成对数组的遍历. 可以避免循环条件和更新语句写错 .
int[] array = {1, 2, 3}; for (int x : array) { System.out.println(x); }for(int x:array):也就是把array中的一个元素(从下标0开始到结束),依次赋给变量x,然后执行语句直到循环结束。
1.3、Arrays工具类
我们还可以借助Java本身提供的一些工具类来对数组进行打印
Arrays.toStriig(该代码可以将数组转换为字符串)------(Arrays本质是对数组进行操作)
之后我们可以将字符串打印出来,该字符串也就数组的所有元素.但在使用它的时候,我们需要在工程最前面加上“导包” ------import java.util.arrays;否则没有该功能.
以下面代码为例:
import java.util.Arrays; public class TestDemo1 { public static void main(String[] args) { int arr1[]=new int[]{1,3,4,5}; System.out.println(Arrays.toString(arr1)); } }
在方法内部会对数组的元素进行组装,并加上两个括号.

1.4数组元素的遍历存储
数组的元素的存储,也就是对数组进行遍历的过程中,依次给数组对应下标的元素进行赋值。
以下面代码为例:
public class TestDemo1 { public static void main(String[] args) { int arr1[]=new int[4]; for (int i = 0; i < arr1.length; i++) { arr1[i]=i; System.out.print(arr1[i]+" "); } } } //运行结果0 1 2 3
三、引用类型---数组
1、Java虚拟机(JVM)的内存分布
内存是一段连续的存储空间,主要用来存储程序运行时数据的。比如:
1. 程序运行时代码需要加载到内存
2. 程序运行产生的中间数据要存放在内存
3. 程序中的常量也要保存
4. 有些数据可能需要长时间存储,而有些数据当方法运行结束后就要被销毁 如果对内存中存储的数据不加区分的随意存储,那对内存管理起来将会非常麻烦。
我们编写好后的.java文件在编译后变为.class字节码文件(让机器读取),然后把字节码文件放进JVM里运行。
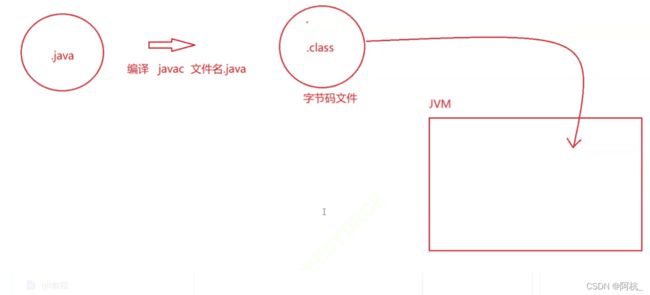
Java虚拟机对内存按照功能也进行了整理划分。
在Java虚拟机内存可划分为五部分:Java虚拟机栈、Java本地方法栈、堆、方法区、程序计数器
- Java虚拟机栈:内部存放局部变量(比如引用变量)
- Java本地方法栈:运行一些C/C++代码编写的程序【JVM其实是一个软件,一个由C/C++编写出来的软件】
- 堆:只要是对象,都会在堆上分配空间(数组的内部存储其实也是对象)
- 方法区:静态的成员变量
- 程序计数器:存储一些指令
划分内存的好处是什么❓
对不同的内存空间里存放的不同数据,更方便地管理
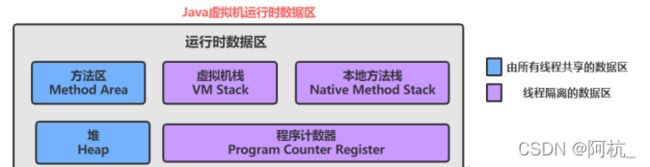
线程隔离地数据区可以理解成每一个线程里都有独立地虚拟机栈、本地方法栈、程序计数器。不同线程里的虚拟机栈、本地方法栈和程序计数器不是同一个。
线程共享的数据区是每一个线程共享同一个方法区和堆。

- 程序计数器 (PC Register): 只是一个很小的空间, 保存下一条执行的指令的地址(比如:你在跟朋友聊天,话说一半,突然有人打电话给你打断了你和朋友的对话,电话接完,你就得知道刚刚你和朋友聊到哪,再继续聊)
- 虚拟机栈(JVM Stack): 与方法调用相关的一些信息,每个方法在执行时,都会先创建一个栈帧,栈帧中包含有: 局部变量表、操作数栈、动态链接、返回地址以及其他的一些信息,保存的都是与方法执行时相关的一些信 息。比如:局部变量。当方法运行结束后,栈帧就被销毁了,即栈帧中保存的数据也被销毁了。
- 本地方法栈(Native Method Stack): 本地方法栈与虚拟机栈的作用类似. 只不过保存的内容是Native方法的局部变量. 在有些版本的 JVM 实现中(例如HotSpot), 本地方法栈和虚拟机栈是一起的
- 堆(Heap): JVM所管理的最大内存区域. 使用 new 创建的对象都是在堆上保存 (例如前面的 new int[]{1, 2, 3} ),堆是随着程序开始运行时而创建,随着程序的退出而销毁,堆中的数据只要还有在使用,就不会被销毁。
- 方法区(Method Area): 用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据. 方法编译出的的字节码就是保存在这个区域
【注意】:
- 堆上开辟的内存空间,如果不再使用的话会被销毁回收(但不像c语言一样malloc开辟内存空间后,需要free释放),JVM本身有垃圾回收器,会对其进行回收。
- 方法区(Method Area)不是存放方法的!而是存放已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的(二进制字节码)代码等数据
2、基本类型变量和引用类型变量的区别
基本数据类型创建的变量,称为基本变量,该变量空间中直接存放的是其所对应的值;
int a=1; float b=1.2f double c=1.5;
引用数据类型创建的变量,一般称为对象的引用,其空间中存储的是对象所在空间的地址。变量存的是地址,就被叫做引用变量。
int []arr=new int[]{1,2,3,4}; double []arr1=new double[]{1.5,1.2,4.4};其中arr和arr1是数组类型的引用变量,引用变量并不直接存储对象本身,而是存储数组在堆空间首元素的地址,之后我们可以通过引用变量去操作对象。
以下面代码为例:


从上图可以看到,引用变量并不直接存储对象本身,可以简单理解成存储的是对象在堆中空间的起始地址。
通过该地址,引用变量便可以去操作对象。有点类似C语言中的指针,但是Java中引用要比指针的操作更简单。
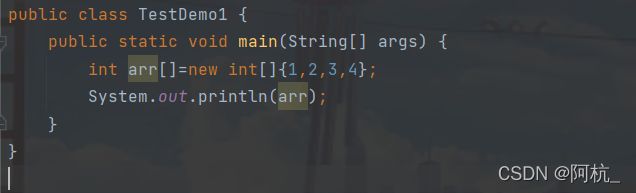
int [ ]arr=new int[ ]{1,2,3,4};
其中arr是引用变量,里面存的是地址。
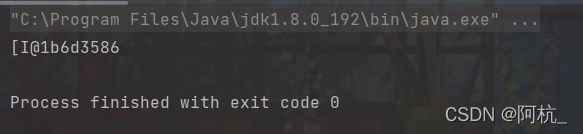
如果我们直接将arr变量打印出来,得到也会是个地址(但该地址是 真实地址的哈希值----独一无二的)
哈希值里的" [ "表示数组," I "表示整型
3、Java中的null
null 在 Java 中表示 "空引用" , 也就是一个不指向任何一个对象的引用

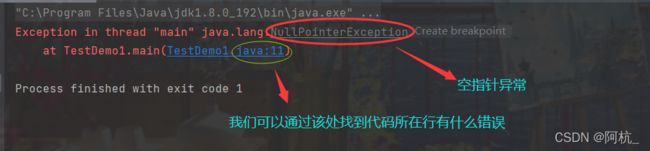
如遇到空指针异常,我们得去找是哪里的引用是空,从上面代码可以知道是11行有问题,而在11行里是 .length 前的arr引用异常。
在编译代码时null 的作用类似于 C 语言中的 NULL (空指针), 都是表示一个无效的内存位置. 因此不能对这个内存进行任何读写操作. 一旦尝试读写, 就会抛出 NullPointerException.
【注意】:Java 中并没有约定 null 和 0 号地址的内存有任何关联.
4、数组引用的一些注意事项
我们在使用引用变量要时刻注意有没有犯一些错误。
1、引用不能指向引用,(引用应当指向引用所指向的对象)
以下面代码为例:
import java.util.Arrays; public class TestDemo1 { public static void main(String[] args) { int []arr1=new int []{1,2,3,4}; int []arr2=new int [4]; arr2=arr1; System.out.println(Arrays.toString(arr2)); } } //运行结果为:[1, 2, 3, 4]该代码中的arr2=arr1,并不是arr2引用了arr1,而是arr2引用了arr1所指向的对象.
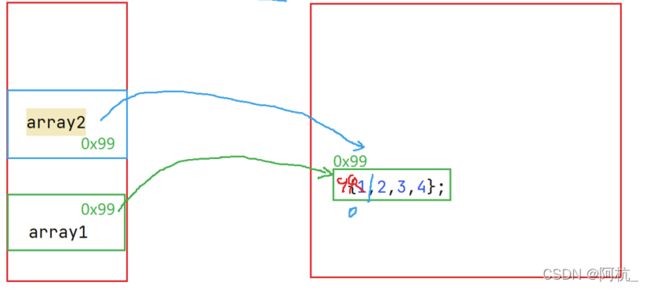
2、一个引用不可以同时指向多个对象
import java.util.Arrays; public class TestDemo1 { public static void main(String[] args) { int []arr1=new int []{1,2,3,4}; arr1=new int[]{2,3,4,5,6}; arr1=new int[]{3,4,5,6,7,8}; System.out.println(Arrays.toString(arr1)); } } //运行结果为:[3, 4, 5, 6, 7, 8]每一次重新new一个对象,会把该对象的首元素地址存储于arr1中,而上一个对象不再使用就会被JVM垃圾回收,不存在一个引用变量同时指向多个对象!
直到最后指向{3,4,5,6,7,8}。
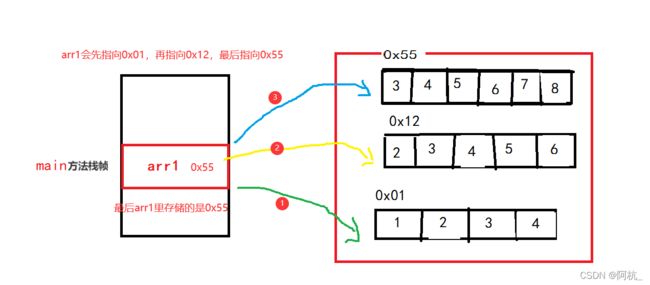
3、引用不一定都在栈上
目前只接触到局部变量,还没接触到成员变量,引用也可以在堆上的,只是现在还没了解。
4、引用赋值null
int [ ]arr=null;
引用赋值null代表该引用变量不指向任何对象。
四、数组的应用
1、保存数据
public static void main(String[] args) {
int[] array = {1, 2, 3};
for(int i = 0; i < array.length; ++i){
System.out.println(array[i] + " ");
}
}
2、数组传参--参数传数组类型(引用类型)
可以将数组作为参数,进行方法调用,而且在方法内部对数组内容进行修改,返回主方法后的数组也会被修改。
因为数组是引用类型,按引用类型来进行传递,可以修改其中存放的内容。引用变量里存放的地址还是那个地址,只不过是引用所指向的那个对象内部发生了修改。


[总结]:
所谓的 "引用" 本质上只是存了一个地址. Java 将数组设定成引用类型, 这样的话后续进行数组参数传参, 其实只 是将数组的地址传入到函数形参中. 这样可以避免对整个数组的拷贝(数组可能比较长, 那么拷贝开销就会很大).
3、数组类型返回值
在定义方法时,也可以以一个数组类型作为返回类型进行返回,下面以一个代码为例:
import java.util.Arrays; public class TestDemo1 { public static int[] arraymod(int []a,int n) { for (int i = 0; i < a.length; i++) { a[i]=n; } return a; } public static void main(String[] args) { int []arr1=new int[]{1,2,3,4}; int []arr2=arraymod(arr1,4); System.out.println(Arrays.toString(arr2)); } } //运行结果 [4, 4, 4, 4]此代码是把数组arr1和一个整型传进去,然后跟传进去数值,把数组里的每一个元素进行修改后,再将其数组返回去,存于引用变量arr2里去,最后将数组转为字符串打印出来。
五、数组的相关练习
1、数组转字符串
代码示例:


其实在本章前面Arrays工具类已经提及。
2、数组拷贝的四种方法*
2.1、简单的拷贝(通过数组遍历)
代码示例:
import java.util.Arrays; public class TestDemo1 { public static void main(String[] args) { int []arr1=new int []{1,2,3,4}; int []arr2=new int[4]; for(int i=0;i< arr2.length;i++) { arr2[i]=arr1[i]; } System.out.println("arr1数组:"+Arrays.toString(arr1)); System.out.println("arr2数组:"+Arrays.toString(arr2)); } } //运行结果: arr1数组:[1, 2, 3, 4] // arr2数组:[1, 2, 3, 4]该代码只是通过简单数组的遍历,将arr1里的元素赋给arr2里的下标位置。
2.2、 使用Arrays中copyOf方法进行拷贝
Arrays.copyOf基本格式:
int [ ]arr1=Arrays.copyOf(源数组(要拷贝的数组)src,新的数组长度new length);
代码示例:
import java.util.Arrays; public class TestDemo1 { public static void main(String[] args) { int []arr1=new int []{1,2,3,4}; int []arr2=Arrays.copyOf(arr1,4); System.out.println("arr1数组:"+Arrays.toString(arr1)); System.out.println("arr2数组:"+Arrays.toString(arr2)); } } //运行结果: arr1数组:[1, 2, 3, 4] // arr2数组:[1, 2, 3, 4]注意:要导包--import java.util.Arrays;
--------这种拷贝方法相对比较常用一些,虽说是拷贝其实是扩容.
2.3、 System.arraycopy()拷贝
System.arraycopy()基本格式:
System.arraycopy(Object src(要拷贝的数组),srcPos(目标数组的起始下标),Object dest(目的地数组),desPost(目的地数组的下标起始位置),length(要拷贝数组的长度))
srcPos:要拷贝数组的下标位置
desPost:拷贝到新数组的下标位置
代码示例:
import java.util.Arrays; public class TestDemo1 { public static void main(String[] args) { int []arr1=new int []{1,2,3,4}; int []arr2=new int[4]; System.out.println("arr1数组:"+Arrays.toString(arr1)); System.arraycopy(arr1,0,arr2,0,4); System.out.println("arr2数组:"+Arrays.toString(arr2)); } } //运行结果: arr1数组:[1, 2, 3, 4] // arr2数组:[1, 2, 3, 4]
2.4数组克隆
数组克隆基本格式:
int [ ] (新数组)=(要拷贝的数组).clone();
代码示例:
import java.util.Arrays; public class TestDemo1 { public static void main(String[] args) { int []arr1=new int []{1,2,3,4}; int []arr2=arr1.clone(); System.out.println("arr1数组:"+Arrays.toString(arr1)); System.out.println("arr2数组:"+Arrays.toString(arr2)); } } //运行结果: arr1数组:[1, 2, 3, 4] // arr2数组:[1, 2, 3, 4]数组的克隆,只是将要拷贝数组克隆了一个自己的副本,然后把副本的首元素地址存储于arr2引用变量里,让arr2引用变量指向副本对象。
【注意】:克隆后的副本对象和原来的数组对象不是同一个,它们的地址不一样.

2.5、拷贝数组某个范围
我们可以自行拷贝数组特定某个范围.
基本格式: int [ ]arr2=Arrays.copyRange(目标数组src,拷贝的起始位置from,拷贝到的终止位置to)
【注意】:遇见from,to这两个时,它们是遵循给左闭右开的"[0,4)",也就是当我们to输入4时,数组拷贝并不会到4,而只从0拷贝到3,和下标差不多.
代码示例:
import java.util.Arrays; public class TestDemo1 { public static void main(String[] args) { int []arr1=new int []{1,2,3,4}; int []arr2=Arrays.copyOfRange(arr1,0,4); System.out.println("arr1数组:"+Arrays.toString(arr1)); System.out.println("arr2数组:"+Arrays.toString(arr2)); } } //运行结果: arr1数组:[1, 2, 3, 4] // arr2数组:[1, 2, 3, 4]
3、数组中的二分查找
二分查找:
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。也就是说,二分查找的前提条件数组内必须是有序的。
数组二分查找的过程:
通过我们给定一个数,然后查找在数组是否有对应相同的元素,有的话返回下标位置,没有则返回一个负数.
1、首先我们先定义数组最左侧和最右侧元素下标和中间元素下标。
2、将我们给定的数与中间元素进行比较,如果给定的关键数大于中间元素,则说明中间元素左边的元素可以排除考虑;如果小于则说明中间元素右边的元素可以排除考虑;反之如果相等,则直接返回中间元素下标(即就是关键数的下标位置)
3、在判断完后,如果小于则不考虑中间元素左侧,那么就得重新定义中间元素和最右侧元素下标,将最左侧下标定义为前一个中间元素下标位置-1,然后再将中间元素(left+right)/2重新定义。反之,大于也一样,只不过将最左侧元素下标重新定义为中间元素位置+1.
4、不断进行反复操作,直到和中间元素一致返回下标;如果找不到,则最左侧的值将会大于最右侧的值,这是不符合的,直接跳出循环判断,返回负数.
代码示例:
import java.util.Arrays; public class TestDemo1 { public static int binaryArray(int[]arr,int n) { int left=0; int right=arr.length-1; while(left<=right) { int mid=(left+right)/2; if(arr[mid]【注意】:我们在定义中间值的时候可以使用无符号右移对right和left进行右移,跟除法差不多,无符号右移1位相当于对其除了个2;(相对更有效率)
4、数组中的顺序查找(查找指定数组元素)
数组中按顺序查找相对简单,只需对数组进行遍历判断是否有相对应的元素就可以。
代码示例:
public class Test1 { public static int arraySearch(int[]arr,int n) { for (int i = 0; i < arr.length; i++) { if(arr[i]==n) { return i; } } return -1; } public static void main(String[] args) { int []arr1=new int[]{1,2,3,4,5,6}; int ret=arraySearch(arr1,5); if(ret==-1) { System.out.println("找不到该数"); } else { System.out.println("找到该数下标为:"+ret); } } } //运行结果:找到该数下标为:4
5、数组排序(逆序排序)
给定一个数组, 将里面的元素逆序排列.
思路设定:两个下标, 分别指向第一个元素和最后一个元素. 交换两个位置的元素. 然后让前一个下标自增, 后一个下标自减, 循环继续直到最左边元素下标大于或等于最右边元素下标。
代码示例:
import java.util.Arrays; public class Test1 { public static void arraySort(int[]arr) { int left=0; int right=arr.length-1; while(left
6、数组的冒泡排序*
冒泡排序:
从序列中的第一个元素开始,依次对相邻的两个元素进行比较,如果前一个元素大于后一个元素则交换它们的位置。如果前一个元素小于或等于后一个元素,则不交换它们;这一比较和交换的操作一直持续到最后一个还未排好序的元素为止。
完成一趟比较后,会将序列中最大的数置于最后一个序列位置,之后再继续相同的比较操作,依次将序列中的元素从小到大排序,前一趟比较完后的最后一个数不再做考虑。因此,每进行下一趟时,序列中比较的次数要相对减一次。
比如一个序列中有5个元素,那就进行4趟循环,第一趟进行4次比较,第二趟进行4次比较,依次类推。
第一趟:
第二趟:
第三趟
第四趟
基本示例代码 :
import java.util.Arrays; public class Test1 { public static void arraySort(int[] arr) { for (int i = 0; i < arr.length - 1; i++) { //趟数循环 int temp = 0; for (int j = 0; j < arr.length - 1 - i; j++) { //每一趟内比较的次数,每进行一次比较,都会减少一次比较 if (arr[j] > arr[j + 1]) { temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } } } public static void main(String[] args) { int arr[] = {1, 15, 5, 11, 54, 8}; System.out.println("冒泡排序前的数组为:" + Arrays.toString(arr)); arraySort(arr); System.out.println("冒泡排序后的数组为:" + Arrays.toString(arr)); } } //运行结果:冒泡排序前的数组为:[1, 15, 5, 11, 54, 8] // 冒泡排序后的数组为:[1, 5, 8, 11, 15, 54]




我们还可以对此代码进行优化。
在该代码中,进行了许多次比较,无论是数组已经满足从小到大排序,还是会继续循环判断前一个数是否大于后一个数,会显得没什么效率。对此,可以对此代码进行修改,让其进行每一次比较时,再判断该数组是否已经满足条件,满足就直接返回,不满足的话就继续循环比较。
可以在比较循环前定义一个布尔类型变量为true,如果在某一趟数中,发生左值大于右值而进行交换的情况,则将该布尔类型的变量赋false,那么就继续判断。每一趟都重新定义一个布尔类型为ture,再进行相同操作。如果判断没进行过交换,则说明该数组已经满足顺序条件,break跳出循环。
代码示例:
import java.util.Arrays; public class Test1 { public static void arraySort(int[] arr) { for (int i = 0; i < arr.length - 1; i++) { //趟数循环 boolean ret=true; int temp = 0; for (int j = 0; j < arr.length - 1 - i; j++) { //每一趟内比较的次数,每进行一次比较,都会减少一次比较 if (arr[j] > arr[j + 1]) { temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; ret=false; } } if(ret) { break; } } } public static void main(String[] args) { int arr[] = {1, 15, 5, 11, 54, 8}; System.out.println("冒泡排序前的数组为:" + Arrays.toString(arr)); arraySort(arr); System.out.println("冒泡排序后的数组为:" + Arrays.toString(arr)); } } //运行结果:冒泡排序前的数组为:[1, 15, 5, 11, 54, 8] // 冒泡排序后的数组为:[1, 5, 8, 11, 15, 54]
六、二维数组
二维数组本质上也就是一维数组, 只不过每个元素又是一个一维数组.(一维数组不过是一组特殊的二维数组)
基本语法 :
数据类型[ ][ ] 数组名称 = new 数据类型 [行数][列数] { 初始化数据 };
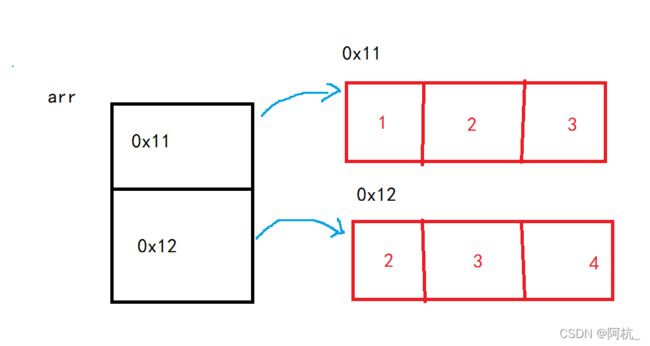
以该处为例:int[2][3]arr={{1,2,3},{2,3,4}};
二维数组内的行数其实也就是一个一维数组,以上面为例,arr引用变量里存了两个引用对象地址,每一个一维数组又指向了一个对象;列数是二维数组内一维数组长度。
代码示例:



【注意】:
Java中的二维数组可以让不同行数里的列数不一样,而且在定义二维数组时的列数长度可以省略,但是这样的话就会出现二维数组有对应的行数数量的一维数组,一维数组没有明确的长度。之后我们可以再重新对二维数组里的每一个一维数组new创建对象
代码示例:
import java.util.Arrays; public class Testdemo1 { public static void main(String[] args) { int [][]arr=new int[2][]; arr[0]=new int[]{1,2,3}; arr[1]=new int[]{1,2,3,4}; System.out.println(Arrays.toString(arr[0])); System.out.println(Arrays.toString(arr[1])); } } //运行结果:[1, 2, 3] // [1, 2, 3, 4]
二维数组的用法和一维数组并没有明显差别, 因此我们不再赘述. 同理, 还存在 "三维数组", "四维数组" 等更复杂的数组, 只不过出现频率都很低. }
