5.21学习周报
文章目录
- 前言
- 文献阅读
-
- 摘要
- 简介
- 方法介绍
- 讨论
- 结论
- 时间序列预测
前言
本周阅读文献《Streamflow and rainfall forecasting by two long short-term memory-based models》,文献主要提出两种基于长短时记忆网络的混合模型用于对水流量和降雨量进行预测。小波-LSTM(即WLSTM)模型,应用小波变换的trous算法进行时间序列分解,小波变换将高频和低频提取到不同的子时间序列中,将时间序列分解为更简单的分量,把传统的数据流预测数据驱动模型集成了数据预处理技术来进行预测。另一个模型将LSTM与卷积层相结合,应用CNN提取时间特征。最后通过实际的案例证明提出的两个模型在时序预测方面提高了LSTM的预测精度。其次,总结了水质预测的一些常用的方法,机器学习和深度学习组合,多种深度学习方法组合,超参数优化,数据分解,时空分析。
This week,I read an article which proposes two hybrid models, based on long short-term memory network (LSTM), for monthly streamflow and rainfall forecasting. One model, wavelet-LSTM , applies a trous algorithm of wavelet transform to do series decomposition.Traditional data-driven models for streamflow forecasting require data pre-processing techniques integrated with novel models to forecast streamflow. And the other, convolutional LSTM (namely, CLSTM), couples convolutional neural network to extract temporal features.The results obtained indicate that the wavelet transform and convolutional layers improved the forecast accuracy of LSTM, especially for longer time step ahead forecasting. Then I summarize some common methods of water quality prediction,for example, combining machine learning and deep learning,combining multiple deep learning methods,hyperparameter optimization,data decomposition and spatiotemporal analysis.
文献阅读
题目:Streamflow and rainfall forecasting by two long short-term memory-based models
作者:Lingling Ni ,Dong Wang ,Vijay P. Singh,Jianfeng Wu,Yuankun Wang ,Yuwei Tao ,Jianyun Zhang ,
摘要
Prediction of streamflow and rainfall is important for water resources planning and management. In this study, we developed two hybrid models, based on long short-term memory network (LSTM), for monthly streamflow and rainfall forecasting. One model, wavelet-LSTM (namely, WLSTM), applied a trous algorithm of wavelet transform to do series decomposition, and the other, convolutional LSTM (namely, CLSTM), coupled convolutional neural network to extract temporal features. Two streamflow datasets and two rainfall datasets are used to evaluate the proposed models. The prediction accuracy of WLSTM and CLSTM was compared with that of multi-layer perceptron (MLP) and LSTM. Results indicated that LSTM was applicable for time series prediction, but WLSTM and CLSTM were superior alternatives.
简介
合适的数据预处理提高了数据驱动模型的性能,将数据预处理技术与机器学习相结合,许多研究表明,具有更高的准确性。基于小波的模型是最受欢迎的混合模型之一,因为它通常可以显着提高预测准确性。小波变换(WT)可以将时间序列分解为单独的子序列,并为数据驱动的模型提供更连贯的序列结构,因此它已成为水文和气象预报的流行工具。与WT类似,卷积神经网络(CNN)使用基于滤波器组的离散卷积操作来检测特征的局部合相,滤波器组是指卷积层。本研究的目的是研究LSTM在预测流量和降雨方面的潜力,并开发两个基于LSTM的模型来提高预报的准确性。一种模型将LSTM与小波变换(以下简称WLSTM)耦合,并采用小波变换将时间序列分解为更简单的分量。另一个模型将LSTM与卷积层(以下简称CLSTM)相结合,应用CNN提取时间特征。
方法介绍
小波变换 (WT)
小波变换是一种工具,可将数据切割成不同的频率分量,然后以与其比例相匹配的分辨率研究每个分量。它的主要特性是它提供了所考虑过程的时间尺度本地化。自然界中观测到的水文序列通常是离散信号,因此通常首选离散小波变换(DWT)。
离散小波变换可以通过金字塔算法计算,该算法在多个时间和频率分辨率下计算其表示。通过两组线性滤波器(小波和缩放滤波器),小波和缩放系数定义为:
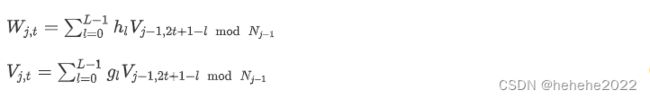
典型的DWT是一种非冗余变换,其敏感性容易变化,因此在应用于与预测相关的问题时是一个不希望出现的特征。这个问题是由边界条件引起的,可以通过trous(AT)小波变换来克服,它促进了对观测数据中潜在过程特性的理解。
性能度量
以下三种性能度量用于定性评估所开发模型的性能:均方根误差(RMSE),纳什-萨特克利夫模型效率系数(NSE)和平均绝对相对误差(MARE),分别表示为

两种混合预测模型
小波-LSTM模型(即WLSTM)
在水文和水资源领域,基于小波的预测通常采用Mallat离散小波变换算法,其中执行WT会将一些未来信息发送到预报中。此问题通常通过迭代地将追加-分解-采样 (ADS) 操作应用于测试数据集来解决,这非常耗时。为了克服“未来数据”问题,以及ADS运算的高计算成本,本研究应用了trous(AT)算法进行时间序列分解,不需要未来时间(>t)的数据来计算当前(t)的小波(缩放)系数。由于AT的特性,WT可以直接对整个数据集执行,而不是迭代应用ADS操作。WLSTM 模型首先选择需要分解的解释变量,然后使用 AT 将所选解释变量和目标变量的时间序列划分为几个更稳定的子序列。然后,它删除了受序列开始时边界条件影响的小波系数。之后,它将整个数据集分为训练集和测试集。训练包含两层 LSTM 且顶部有一个密集层的网络,以使用 q (用作输入的先前时间步长的数量)滞后记录计算 p (我们想要预测的下一个时间段的数量)提前一步预测。
CLSTM
第二个模型将LSTM与卷积神经网络(CNN)耦合,即CLSTM。在 CLSTM 中,应用卷积层堆栈来捕获变量的时间特征。CNN提取的特征被馈送到一个包含两层LSTM的网络,上面有一个密集层。然后,训练整个 CLSTM 模型以使用 q 滞后记录计算 p 提前预测。
应用
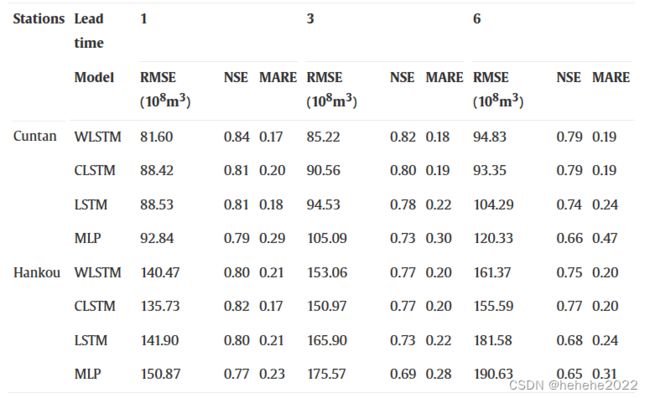
在Cuntan的情况下,WLSTM模型在RMSE方面对提前6个月和8个月的预测具有最佳的准确性。对于提前1步预测,所有神经网络均显示出令人满意的结果,当预测步骤调整为 3 和 6 时,与其他基于 LSTM 的模型相比,MLP 的性能迅速下降。尽管CLSTM的RMSE,MARE和NSE高于LSTM,但与WLSTM相比,它并没有显着提高预测准确性。WLSTM的表现优于LSTM。
讨论
用于多步骤提前预测时MLP和LSTM之间的区别,于 MLP,滞后记录被视为固定大小的输入,而提前多步预测是固定大小的输出。这种处理模式是一对一的情况,其中所有时间记录通过神经元权重直接相互连接,而 LSTM 的处理方式与 MLP 不同,因为它被视为序列到序列(即一次处理序列输入的一个元素,然后一个接一个地生成输出)的问题。LSTM 一次处理一个元素的输入序列,并生成序列输出,其中过去的时间信息由存储单元隐式维护。与LSTM类似,CLSTM和WLSTM将预测作为序列到序列问题进行处理。
关于CLSTM和WLSTM之间的区别。CLSTM 和 WLSTM 都可以看作是数据预处理方法,因为它们都应用卷积操作来提取数据的时间局部信息。小波变换将高频和低频提取到不同的子时间序列中。CNN在一个卷积层的水平上对时间局部信息进行编码。但是,WLSTM 的筛选器是预先指定的结构化筛选器,而 CLSTM 的筛选器是由数据训练的,这些数据是可学习的。此外,卷积层的输出由非线性函数激活。从应用结果可以看出,尽管WLSTM显示出其优于LSTM的优越性,但在大多数情况下,可学习和非线性CLSTM的性能优于WLSTM。有人建议,当解释变量较小且更期望准确预测峰值时,WLSTM 似乎是更好的选择。如果没有关于建模的先验信息,CLSTM 似乎是更好的选择,因为它在大多数情况下表现良好。在这项研究中,我们只应用了两个卷积层来构建CLSTM作为数据不足的极限。可用于训练 CLSTM 的数据越多,可以堆叠的卷积层就越多。此外,堆叠卷积层越大,输入数据的表示形式就越丰富,预测结果就越好。
结论
由于溪流的非线性和非平稳性,传统的数据流预测数据驱动模型需要与新模型集成的数据预处理技术来预测溪流。长短时记忆(LSTM)是一种流行的神经网络(NN),适用于时序数据。本文研究了LSTM在流量和降雨预报中的潜在用途,并提出了两种基于LSTM的模型来执行多步提前预测。一个模型WLSTM应用“trous”小波变换算法进行序列分解,另一个模型CLSTM耦合卷积层来提取时间特征。利用该模型预测长江昆滩站和后口站月流量,对济南站、温江站进行月降雨量预报。
将结果与MLP和LSTM的结果进行比较。结果表明,LSTM适用于水流量和降雨预报,小波变换和卷积层提高了LSTM的预报精度,特别是对于长时间提前的预测。CLSTM 和 WLSTM 是更好的替代方案,当预计预测的时间更长时。
时间序列预测
深度学习神经网络中的超参数,超参数是用于设计深度学习网络以实现所需预测性能结果的变量。调整超参数是开发深度学习算法的重要过程之一,因为它会影响网络架构的设计和性能。深度学习中的超参数是隐藏层的数量、每层中的神经元数量、学习率、正则化技术、激活函数、动量、批量大小、时期数和优化器算法。深度学习模型依赖于隐藏层的数量和神经元的数量来训练网络架构的过程。学习率是指网络权重更新期间的步骤,并根据不同的优化器算法而变化。Dropout,L1和L2是用于避免网络训练过度拟合的正则化技术类型。深度学习模型中最常用的激活函数是整流线性单元 (ReLU),ReLU在网络设计中可以考虑几种变体,即指数线性单元(ELU),参数化ReLU和LeakyReLU。用于深度学习模型的其他激活函数是线性、S 形和双曲正切。在优化器算法方面,有几种类型的算法,即梯度下降(GD),自适应梯度算法(AdaGrad),均方根传播(RMSProp)和自适应矩估计(ADAM)。GD有其变体,即随机梯度下降(SGD)和小批量梯度下降(MGD),考虑不同类型的优化器算法会产生不同的预测结果。因此,为深度学习预测网络设计超参数的最佳组合可能会带来卓越的模型性能和预测结果的高精度。
超参数优化技术,为网络架构找到最佳值是获得最佳性能和高预测准确性的重要过程。超参数搜索有几种方法,即手动搜索、网格搜索、随机搜索、贝叶斯优化和元启发式算法。在手动搜索方法中,根据试错过程选择超参数值集,直到模型产生最低的训练误差。同时,在网格搜索中,为每个超参数选择一组值,并训练所选值的所有组合,然后进行测试以找到最佳选择。除此之外,随机搜索是一种随机训练和测试已设置的搜索空间或网格内超参数组合的方法。贝叶斯优化是一种全局优化方法,它构建概率模型来近似目标函数,即代理函数。同时,元启发式算法是一种基于遗传算法(GA)、粒子群优化(PSO)和蝙蝠算法(BA)等计算智能范式解决优化问题的方法。比如,《A water quality prediction model based on variational mode decomposition and the least squares support vector machine optimized by the sparrow search algorithm (VMD-SSA-LSSVM) of the Yangtze River, China》提出一种改进的最小二乘支持向量机(LSSVM)模型,用变分模态分解(VMD)对输入数据进行去噪,麻雀搜索算法(SSA)是一种新颖的元启发式优化算法,用于计算LSSVM模型的最优参数值。
深度学习模型
水质预测常用的深度学习模型CNN,RNN,LSTM,GRU
LSTM展示了与传统的机器学习和统计预测模型相比,解决时间序列预测问题的能力更高。这是由于LSTM单元的优点,该单元执行自循环记忆,解决梯度消失问题。
机器学习
考虑到单个模型在空水质预测中的局限性,使用了机器学习和深度学习方法的组合,以获得最佳结果和模型的鲁棒性。此外,使用迁移学习方法可以进一步提高深度学习预测模型的性能。迁移学习 (TL) 已应用于深度学习,以在搜索监测站点遇到数据不足时改进模型学习过程。
多种深度学习方法
混合预测模型也可以基于多种深度学习方法的组合形成,以解决由于数据集在空间和时间方面的变化而导致的复杂时间序列预测问题。
优化算法
开发的深度学习预测模型由基于所选方法(如层数、神经元数和激活函数)的不同架构配置组成。超参数的最佳值显着提高了深度学习模型在水质预测模型过拟合中的准确性。优化算法的应用可以减少超参数搜索处理时间,并很好地增强预测模型。
深度学习结合数据分解
经验模态分解 (EMD)、离散小波变换 (DWT) 和变分模态分解 (VMD) 等数据分解方法将实际时间序列数据分解为多个子序列,以形成单独的模型并生成独立的预测结果,然后再合并进行最终预测。
比如,《Dissolved Oxygen Forecasting in Aquaculture: A Hybrid Model Approach》提出了一种基于集成经验模态分解(EEMD)的LSTM(长短期记忆)神经网络的新型混合溶解氧浓度预测方法。用EEMD算法将原始传感器数据分解为多个固有模式函数(IMF),用特征选择仔细选择与原始传感器数据密切相关的IMF,并将其集成到NN的两个输入中。然后构建了基于EEMD的混合LSTM预测模型。《A novel hybrid water quality forecast model based on real-time data decomposition and error correction》提出了一种通过使用数据分解、纠错和机器学习的新型混合模型,模型使用改进的完整集成经验模式分解以及自适应噪声和双向长短期记忆(BLSTM)神经网络。
深度学习结合时空分析
水质污染是一种复杂的现象,它受到许多因素的影响,这些因素在特定时间和地点形成复杂的数据集,使水质污染物预测变得复杂。此外,水质预报依赖于从特定研究区域或可能受地理和气候条件等其他因素影响的区域中的多个监测站获得的时间序列数据。因此,有必要对区域内监测站与周围环境进行水质相关性分析,以求解时空分布,突出其他变量对水质的影响。基于输入变量和预测目标的不同组合进行时空分析。可以总结出输入数据的时空特征,以识别变量对目标变量的显著性。除此之外,还进行时空相关性分析以搜索目标特征的重要参数。预测模型的输入参数只会选择相关性高的参数,以避免过度拟合和降低计算能力。时空分析还能够提高单个深度学习模型在水质预测中的性能。因此,根据数据集的可变性和计算能力,可以使用时空分析设计最佳方法,以供将来考虑。比如:《Inlet Water Quality Forecasting of Wastewater Treatment Based on Kernel Principal Component Analysis and an Extreme Learning Machine》建立了核主成分分析(KPCA)和极限学习机(ELM)相结合的模型来预测污水处理的进水水质。KPCA用于进水水质的特征提取和降维,ELM用于未来的进水水质预测。结果表明该方法可为污水处理水质预测提供可靠有效的参考。