算法训练Day21: 530.二叉搜索树的最小绝对差, 501.二叉搜索树中的众数, 236. 二叉树的最近公共祖先
文章目录
- 二叉搜索树的最小绝对差
-
- 思路
- #递归
- 代码如下:
- 二叉搜索树中的众数
-
- 递归法
-
- #如果不是二叉搜索树
- 整体代码如下
- 二叉树的最近公共祖先
-
- 题解
二叉搜索树的最小绝对差
| Category | Difficulty | Likes | Dislikes | ContestSlug | ProblemIndex | Score |
|---|---|---|---|---|---|---|
| algorithms | Easy (63.46%) | 440 | 0 | - | - | 0 |
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
差值是一个正数,其数值等于两值之差的绝对值。
示例 1:
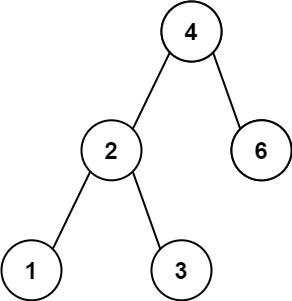
输入:root = [4,2,6,1,3]
输出:1
示例 2:
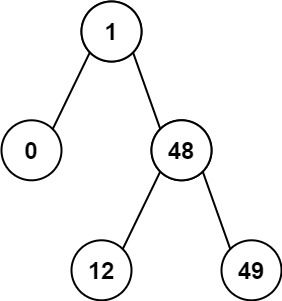
输入:root = [1,0,48,null,null,12,49]
输出:1
提示:
- 树中节点的数目范围是
[2, 104] 0 <= Node.val <= 105
**注意:**本题与 783 https://leetcode-cn.com/problems/minimum-distance-between-bst-nodes/ 相同
Discussion | Solution
思路
题目中要求在二叉搜索树上任意两节点的差的绝对值的最小值。
注意是二叉搜索树,二叉搜索树可是有序的。
遇到在二叉搜索树上求什么最值啊,差值之类的,就把它想成在一个有序数组上求最值,求差值,这样就简单多了。
#递归
那么二叉搜索树采用中序遍历,其实就是一个有序数组。
在一个有序数组上求两个数最小差值,这是不是就是一道送分题了。
最直观的想法,就是把二叉搜索树转换成有序数组,然后遍历一遍数组,就统计出来最小差值了。
代码如下:
#if 0
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode() : val(0), left(nullptr), right(nullptr) {}
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};
#endif
class Solution {
private:
vector<int> vec;
void traversal(TreeNode* root) {
if(root == NULL) return;
traversal(root->left);
vec.push_back(root->val);
traversal(root->right);
}
public:
int getMinimumDifference(TreeNode* root) {
vec.clear();
traversal(root);
if(vec.size()<2) return 0;
int result = INT_MAX;
for(int i = 1; i < vec.size();i++ ) {
result = min(result,vec[i] - vec[i-1]);
}
return result;
}
}
以上代码是把二叉搜索树转化为有序数组了,其实在二叉搜素树中序遍历的过程中,我们就可以直接计算了。
需要用一个pre节点记录一下cur节点的前一个节点。
代码如下:
class Solution {
private:
int result = INT_MAX;
TreeNode* pre = NULL;
void traversal(TreeNode* cur) {
if (cur == NULL) return;
traversal(cur->left); // 左
if (pre != NULL){ // 中
result = min(result, cur->val - pre->val);
}
pre = cur; // 记录前一个
traversal(cur->right); // 右
}
public:
int getMinimumDifference(TreeNode* root) {
traversal(root);
return result;
}
};
二叉搜索树中的众数
| Category | Difficulty | Likes | Dislikes | ContestSlug | ProblemIndex | Score |
|---|---|---|---|---|---|---|
| algorithms | Easy (54.43%) | 618 | 0 | - | - | 0 |
给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。
如果树中有不止一个众数,可以按 任意顺序 返回。
假定 BST 满足如下定义:
- 结点左子树中所含节点的值 小于等于 当前节点的值
- 结点右子树中所含节点的值 大于等于 当前节点的值
- 左子树和右子树都是二叉搜索树
示例 1:
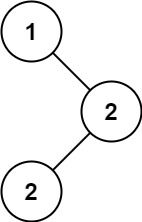
输入:root = [1,null,2,2]
输出:[2]
示例 2:
输入:root = [0]
输出:[0]
提示:
- 树中节点的数目在范围
[1, 104]内 -105 <= Node.val <= 105
**进阶:**你可以不使用额外的空间吗?(假设由递归产生的隐式调用栈的开销不被计算在内)
Discussion | Solution
递归法
#如果不是二叉搜索树
如果不是二叉搜索树,最直观的方法一定是把这个树都遍历了,用map统计频率,把频率排个序,最后取前面高频的元素的集合。
具体步骤如下:
- 这个树都遍历了,用map统计频率
至于用前中后序哪种遍历也不重要,因为就是要全遍历一遍,怎么个遍历法都行,层序遍历都没毛病!
这里采用前序遍历,代码如下:
// map key:元素,value:出现频率
void searchBST(TreeNode* cur, unordered_map<int, int>& map) { // 前序遍历
if (cur == NULL) return ;
map[cur->val]++; // 统计元素频率
searchBST(cur->left, map);
searchBST(cur->right, map);
return ;
}
2.把统计的出来的出现频率(即map中的value)排个序
有的同学可能可以想直接对map中的value排序,还真做不到,C++中如果使用std::map或者std::multimap可以对key排序,但不能对value排序。
所以要把map转化数组即vector,再进行排序,当然vector里面放的也是pair类型的数据,第一个int为元素,第二个int为出现频率。
代码如下:
bool static cmp (const pair<int, int>& a, const pair<int, int>& b) {
return a.second > b.second; // 按照频率从大到小排序
}
vector<pair<int, int>> vec(map.begin(), map.end());
sort(vec.begin(), vec.end(), cmp); // 给频率排个序
3.取前面高频的元素
此时数组vector中已经是存放着按照频率排好序的pair,那么把前面高频的元素取出来就可以了。
代码如下:
result.push_back(vec[0].first);
for (int i = 1; i < vec.size(); i++) {
// 取最高的放到result数组中
if (vec[i].second == vec[0].second) result.push_back(vec[i].first);
else break;
}
return result;
整体代码如下
#if 0
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode() : val(0), left(nullptr), right(nullptr) {}
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};
#endif
class Solution {
private:
void searchBST(TreeNode* cur, unordered_map& map) {
if(cur == NULL) return;
map[cur->val]++;
searchBST(cur->left,map);
searchBST(cur->right,map);
return;
}
bool static cmp(const pair& a,const pair& b) {
return a.second > b.second;
}
public:
vector findMode(TreeNode* root) {
unordered_map map;
vector result;
if(root == NULL) return result;
searchBST(root,map);
vector> vec(map.begin(),map.end());
sort(vec.begin(),vec.end(),cmp);
result.push_back(vec[0].first);
for(int i = 1; i < vec.size();i++ ) {
if(vec[i].second == vec[0].second) result.push_back(vec[i].first);
else break;
}
return result;
};
};
二叉树的最近公共祖先
| Category | Difficulty | Likes | Dislikes | ContestSlug | ProblemIndex | Score |
|---|---|---|---|---|---|---|
| algorithms | Medium (69.64%) | 2227 | 0 | - | - | 0 |
树 | 深度优先搜索 | 二叉树
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
示例 1:
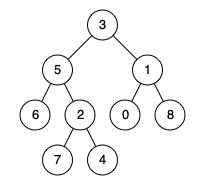
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
示例 2:
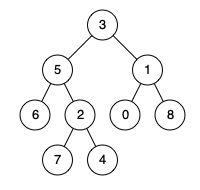
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。
示例 3:
输入:root = [1,2], p = 1, q = 2
输出:1
提示:
- 树中节点数目在范围
[2, 105]内。 -109 <= Node.val <= 109- 所有
Node.val互不相同。 p != qp和q均存在于给定的二叉树中。
Discussion | Solution
题解
#if 0
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
#endif
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root == q || root ==p || root == NULL) return root;
TreeNode* left = lowestCommonAncestor(root->left,p,q);
TreeNode* right = lowestCommonAncestor(root->right,p,q);
if(left != NULL && right != NULL) return root;
if(left == NULL && right != NULL) return right;
else if(left != NULL && right == NULL) return left;
else {
return NULL;
}
}
};
- 求最小公共祖先,需要从底向上遍历,那么二叉树,只能通过后序遍历(即:回溯)实现从底向上的遍历方式。
- 在回溯的过程中,必然要遍历整棵二叉树,即使已经找到结果了,依然要把其他节点遍历完,因为要使用递归函数的返回值(也就是代码中的left和right)做逻辑判断。
- 要理解如果返回值left为空,right不为空为什么要返回right,为什么可以用返回right传给上一层结果。
可以说这里每一步,都是有难度的,都需要对二叉树,递归和回溯有一定的理解。
) return right;
else if(left != NULL && right == NULL) return left;
else {
return NULL;
}
}
};
1. 求最小公共祖先,需要从底向上遍历,那么二叉树,只能通过后序遍历(即:回溯)实现从底向上的遍历方式。
2. 在回溯的过程中,必然要遍历整棵二叉树,即使已经找到结果了,依然要把其他节点遍历完,因为要使用递归函数的返回值(也就是代码中的left和right)做逻辑判断。
3. 要理解如果返回值left为空,right不为空为什么要返回right,为什么可以用返回right传给上一层结果。
可以说这里每一步,都是有难度的,都需要对二叉树,递归和回溯有一定的理解。
[参考文章]([代码随想录 (programmercarl.com)](https://programmercarl.com/0236.二叉树的最近公共祖先.html#java))