2024考研408-计算机组成原理第四章-指令系统
文章目录
- 前言
- 一、指令系统
-
- 现代计算机的结构
- 1.1、指令格式
-
- 1.1.1、指令的定义
- 1.1.2、指令格式
- 1.1.3、指令—按照地址码数量分类
-
- ①零地址指令
- ②一地址指令(1个操作数、2个操作数情况)
- ③二地址指令
- ④三地址指令
- ⑤四地址指令
- 1.1.4、指令-按照指令长度分类
- 1.1.5、指令-按照操作码长度分类
- 1.1.6、指令-按照操作类型分类
- 本节回顾
- 1.2、扩展操作码指令格式
-
- 1.2.1、扩展操作码格式
- 1.2.2、扩展操作码的设计体现(第一种)
- 1.2.3、另外一种扩展操作码设计
- 1.2.4、操作码分类
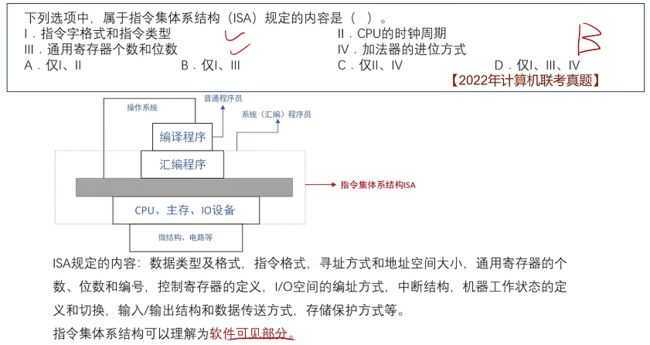
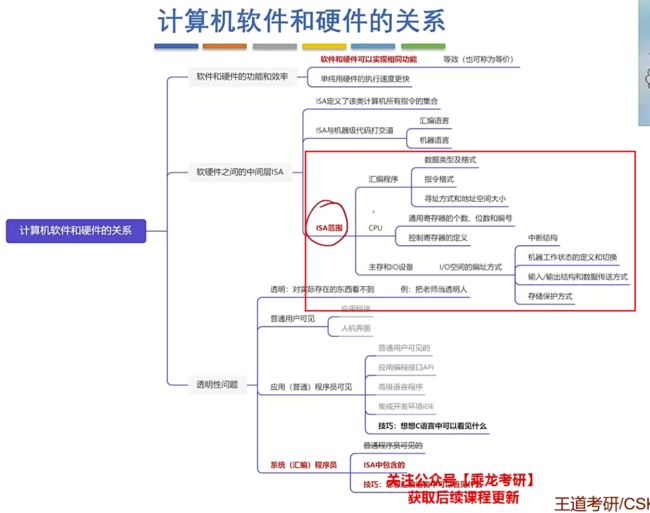
- 补充(ISA)
- 二、指令的寻址方式
-
- 2.1、指令寻址
-
- 2.1.1、回顾计算机知识点(PC程序计数器)
- 2.1.2、方式一:顺序寻址(三个例子)
- 2.1.3、方式二:跳跃寻址
- 本节回顾
- 2.2、数据寻址
-
- 2.2.1、认识数据寻址
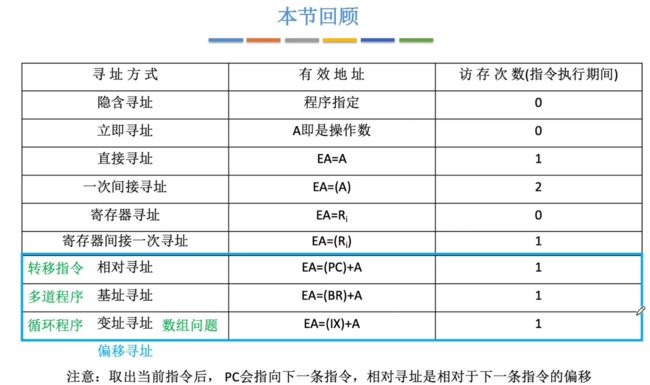
- 2.2.2、六种基本的寻址方式
-
- ①直接寻址
- ②间接寻址
- ③寄存器寻址
- ④寄存器间接寻址
- ⑤隐含寻址
- ⑥立即寻址
- 本节回顾
- 2.2.3、三种偏移寻址
-
- 2.2.3.1、认识偏移寻址
- ⑦基址寄存器(程序的起始存放位置作为"起点")
- ⑧变址寻址(程序员自己决定从哪里作为"起点")
-
- 变址寻址(详细)
- 基址&变址复合寻址(例子,含寻址流程)
- ⑨相对寻址
- 本节回顾
- 补充:硬件如何实现数的"比较"?
- ⑩堆栈寻址
- 本节所有寻址回顾
- 三、程序的机器级代码表示
-
- 3.1、高级语言与机器级代码之间的对应(探讨指令中地址码数据在哪儿?)
-
- 3.1.1、高级语言->汇编语言->机器语言
- 3.1.2、x86汇编语言指令基础
- 3.1.3、x86架构CPU的一些寄存器(通用寄存器、变址寄存器、堆栈指针)
- 总结
- 3.2、常用的X86汇编语言指令格式(Intel格式)
-
- 3.2.1、常见的算数运算指令(包含王道书指令示例解释)
- 3.2.2、常见的逻辑运算指令
- 3.1.3、其他指令
- 3.3、AT&T格式和Intel格式
-
- 3.3.1、认识了解AT&T格式和Intel格式
- 3.3.2、AT&T格式 VS Intel格式(区别描述)
- 3.4、选择语句机器级表示
-
- 3.4.1、程序中的选择语句
- 3.4.2、无条件转移指令jmp
- 3.4.3、条件转移指令jxxx
- 3.4.4、示例:选择语句的机器级表示
- 扩展:cmp指令的底层原理
- 3.5、循环语句机器级别表示
-
- 3.5.1、使用条件转移指令实现循环(针对for、while循环)
- 3.5.2、使用loop指令实现循环(loop)
- 3.6、过程(或称函数)调用的机器及表示
-
- 3.6.1、Call和ret指令(汇编指令)
-
- 3.6.1.1、高级语言以及x86汇编语言的函数调用(call、ret)
- 3.6.1.2、call、ret调用时如何确定返回的代码行号?(栈帧中存放IP旧值)
- 总结:函数调用的机器级表示
- 3.6.2、如何访问栈帧?
-
- 解决问题1:为什么函数调用栈会倒过来画?(主存位置映射原因)
- 解决问题2:如何访问栈帧中的数据?(pop、push或者mov)
-
- ①了解EBP、ESP寄存器作用
- ②使用pop、push指令来读写栈帧中数据
- ③使用简单指令mov来访问栈帧数据
- 总结:如何访问栈帧?
- 3.6.3、如何切换栈帧?(进入函数时执行enter,结束前执行leave)
-
- ①认识栈帧的切换
- ②使用enter指令来实现栈帧信息的保存
- ③使用leave指令来实现栈帧信息的回退(或称切换)
- 总结:函数调用的机器级表示
- 3.6.4、如何传递参数和返回值(栈帧内包含哪些内容,参数、返回值传递)
-
- 3.6.4.1、一个栈帧中可能包含的内容
- 3.6.4.2、汇编代码实战
- 总结:函数调用的机器级表示
- 总结
- 四、CISC和RISC的基本概念
-
- 4.1、认识CISC与RISC
- 4.2、CISC与RISC的设计思路
- 4.3、CISC与RISC的特性差异
前言
目前正在备考24考研,现将24计算机408学习整理的知识点进行汇总整理。
博主博客文章目录索引:博客目录索引(持续更新)
一、指令系统
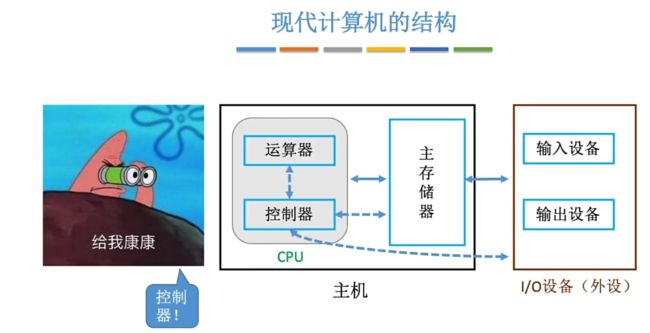
现代计算机的结构
重点探讨控制器需要支持的指令应该怎么设计。第五章控制器如何具体协调各个部件来控制工作。
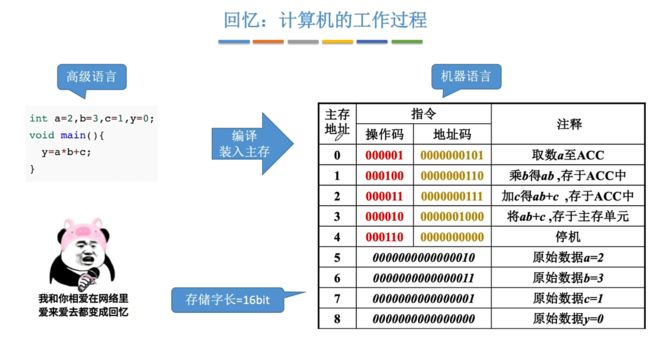
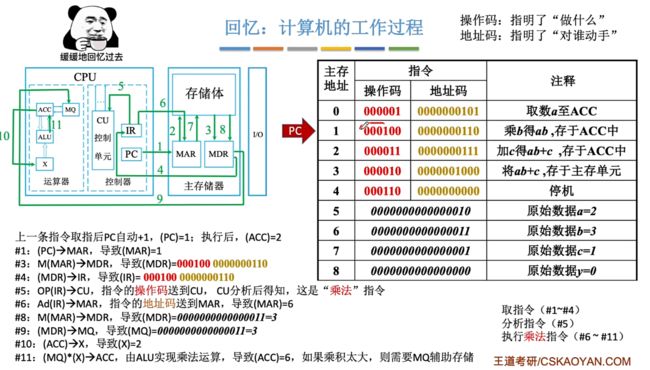
回忆:计算机的工作过程
指令包含操作码与地址码。
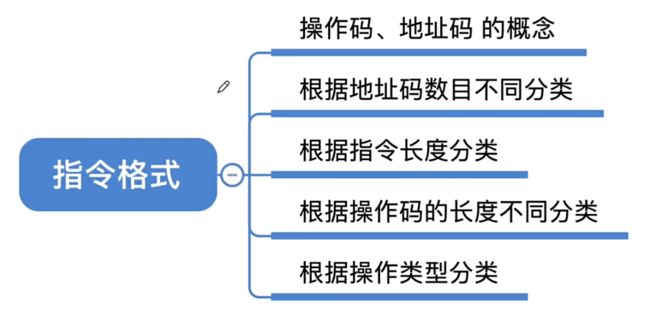
1.1、指令格式
1.1.1、指令的定义
不同指令集需要根据对应的CPU架构来使用。需要注意指令集与指令系统的概念。
一般来说PC中的都是X86架构,而手机则是基于ARM架构指令集

1.1.2、指令格式
包含:操作码(用户干什么)、地址码(对谁进行操作,根据干什么来设置指定数量的操作对象)
根据指令中地址码的数目,可以将指令分为多种如零地址指令、一地址指令、二地址指令…
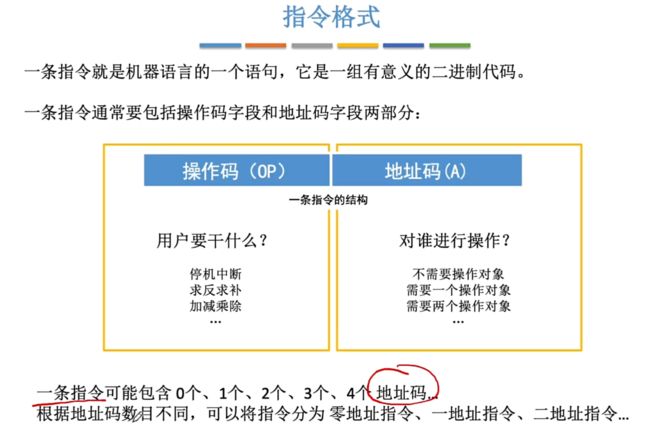
1.1.3、指令—按照地址码数量分类
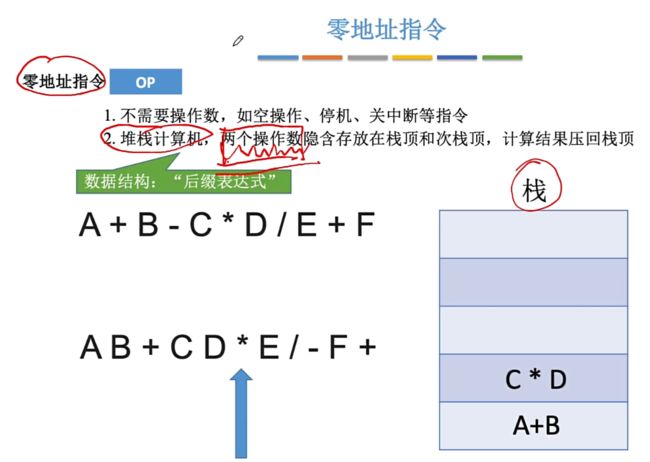
①零地址指令
零地址指令:只要给出操作码即可,一般分为两种:
①不需要操作数的操作如空操作、停机、关中断。
②针对于堆栈计算机,这类指令并不是说不需要操作数,而是说操作数隐含在栈顶和次栈顶中,计算结果则压回栈顶。【例如:数据结构中的"后缀表达式",由中缀表达式转后缀表达式】
②一地址指令(1个操作数、2个操作数情况)
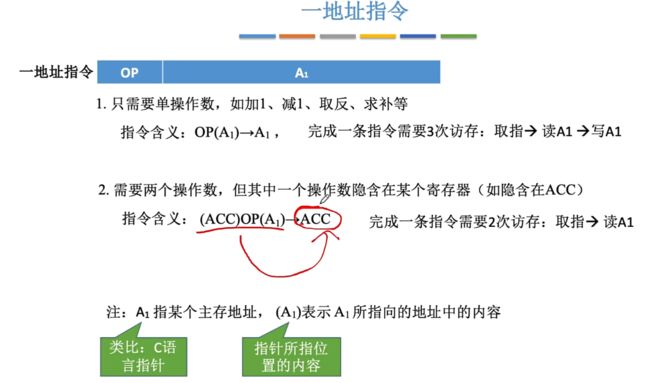
1、只需要1个操作数,例如加1,减1,取反,求补…
指令:OP(A1)->A1。
- 解释:首先从A1的主存单元中取出数据,接着对这个数据进行OP操作符操作,求得运算结果后再将运算结果放回A1所指向的主存单元。
- 执行该条指令需要三次访存:取读->读A1->写A1。【首先取读指的是从主存当中取出这个一地址指令,第二次访存根据A1所指的内容取读出A1所指的主存单元,第三次访存则是得到运算结果之后再将运算结果写回A1】
2、需要2个操作数,其中一个操作数隐含在某个寄存器里(如隐含在ACC)
指令:(ACC)OP(A1)->ACC
- 解释:将存放在ACC累加器中的数据以及A1地址中的数据读出来对两个数据进行OP操作,最终将运算的结果放入到ACC中。
- 执行该条指令需要两次访存:取读->读A1。【首先取读是从主存中取出指令,接着去A1地址中读出数据。注意对于从ACC累加器中读和写都不需要进行访存】
③二地址指令

二地址指令:经常用于2个操作数算数运算、逻辑运算。
指令:(A1)OP(A2)->A1。
- 解释:将A1地址、A2地址中的数据取出进行运算后存回A1。
- 执行该条指令需要四次访存:取读->读A1->读A2->写A1。
④三地址指令

三地址指令:同样也是两个操作数运算,但是最后存储的位置是在另一个新的位置。
指令:(A1)OP(A2)->A3。
- 解释:将A1地址、A2地址中的数据取出进行运算后存回A3。
- 执行该条指令需要四次访存:取读->读A1->读A2->写A1。
⑤四地址指令

四地址指令:实际上是在三地址指令的基础上新增了一个地址,该地址主要用于指向下一条要执行的指令地址
指令:(A1)OP(A2)->A3,A4。
- 解释:将A1地址、A2地址中的数据取出进行运算后存回A3,执行完指令后,将PC的值修改为A4所指的地址。
- 执行该条指令需要四次访存:取读->读A1->读A2->写A1。
额外:在四地址中才会去修改PC指向的地址,一般正常指令执行完后则会PC+1,指向下一条地址。
问题:地址码的位数有什么影响吗?
- n位地址码的直接寻址范围=2n
- 若是指令总长度固定不变,那么地址码的数量越多,寻址能力越差。(由于总长度固定不变,而地址码数量变多,那么地址码本身一条的长度范围就会越小,那么寻址能力就会越差)
1.1.4、指令-按照指令长度分类

- 指令字长(固定不变)、机器字长(可能发生改变)、存储字长(可能发生改变)
- 不同指令字长举例:半字长指令、单字长指令、双字长指令。(一般都是机器字长的多少倍)
- 指令字长会影响取指令的所需时间。
例如:机器字长=存储字=16bit,取一条双字长的指令则需要两次访存。
指令系统中不同策略:定长指令字结构、变长指令字结构。
1.1.5、指令-按照操作码长度分类
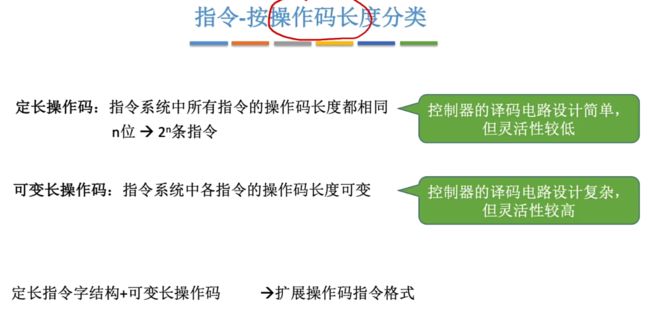
定长操作码:指令系统中所有指令的操作码长度都相同。
- 控制器的译码电路设计简单,但是灵活性较低。
可变长操作码:指令系统中各指令的操作码长度可变。
- 控制器的译码电路设计复杂,但是灵活性较高。
之后可以学习一种扩展操作码指令格式
- 定长指令字结构+可变长操作码:指令的总长度不变,但是操作码位数可以改变的。
1.1.6、指令-按照操作类型分类
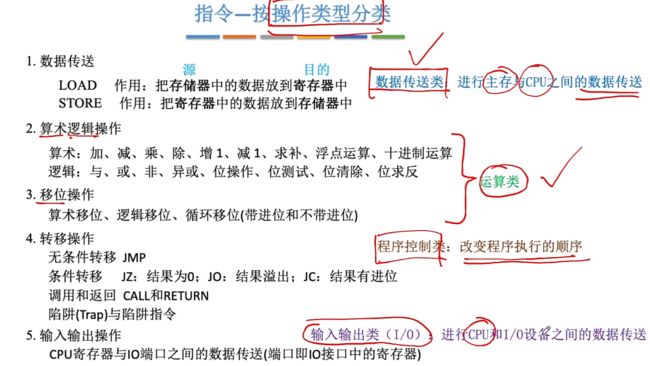
主要包含数据传送类、运算类(算数逻辑操作、移位操作)、程序控制类、输入输出类。
1、数据传送:LOAD、STORE
2、算数逻辑操作:算法运算、逻辑运算。
3、移位操作:算数、逻辑、循环移位。
4、转移操作:无条件转移、条件转移、调用和返回、陷阱指令
- 转移操作:转移程序流的指令。实际会改变PC的值。
5、输入与输出:CPU与IO设备之间数据交互。
本节回顾
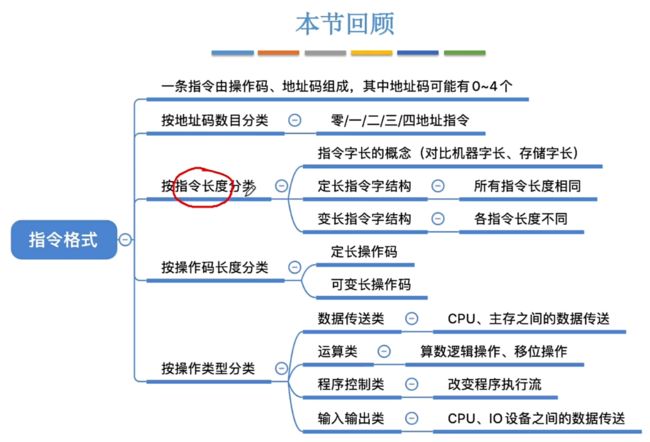
1.2、扩展操作码指令格式

1.2.1、扩展操作码格式
扩展操作码格式:定长指令字结+可变长操作码(指令长度固定,操作码长度不定)。
- 不同地址数的指令使用不同长度的操作码。
1.2.2、扩展操作码的设计体现(第一种)
一种扩展操作码的设计体现:
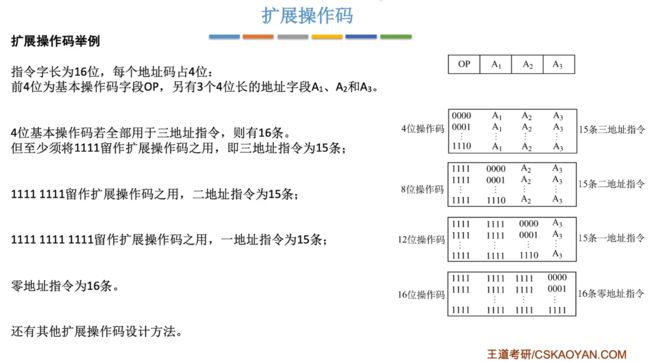
下面的三地址、二地址…,分别表示有几个地址,一个地址一般为4位,指定指令字长为16位(总长)来进行指令格式的划分:
三地址指令:15条,前4位作为操作码,0000-1110。
- 前4位1111无法作为操作码,因为前4位为1是用来区分三地址与二地址指令的。
二地址指令:15条,前8位作为操作码,第9为到16位为0000-1110。
- 前4位必须为1,表示含义就是说这一条指令是二地址。
一地址指令:15条,前12位为操作码,前8位都是1,第9位-12位分别为0000-1110
- 前8位必须为1,表示含义这一条指令是一地址。
零地址指令:16条,所有位都可供操作码,前12位都是1,第13位-116位分别是0000-1111
- 前12位必须为1,在零地址指令中,最后4位1111可以取作运算符!
设计扩展操作码指令格式注意点如下:

1、不允许短码是长码的前缀。
- 举例:三地址指令的操作码为4位,二地址指令的操作码为8位,其中三地址指令的4位相对于二地址指令的8位就是短码对长码,那么短码不允许为长码的前缀。这也是用来区分三、二地址指令格式的一个要点。
2、各指令的操作码一定不能重复。
通常情况,对于频率高的指令通常分配越短的代码,频率低的分配更长代码。
1.2.3、另外一种扩展操作码设计
设计思路:设置地址长度为n,上一层留出m种状态,下一层可扩展m*2n种状态。每一层使用上层留下来的状态+4位来进行确定对应的x位地址指令有几个。
接下来我们进行设计不同数量的地址指令:
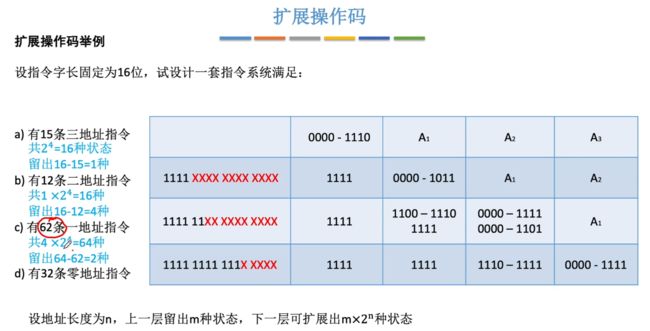
①15条三地址指令:0000 xxxx xxxx xxxx - 1110 xxxx xxxx xxxx 实际开始结束就是0000 - 1110
- 预留为16-15=1,也就是预留了1位。
②12条二地址指令:1111 0000 xxxx xxxx - 1111 1011 xxxx xxxx 实际开始结束就是0000-1011
- 总条数包含有:1 * 24 = 16
- 预留为:16 - 12 = 4
③62条一地址指令:1111 1100 0000 xxxx - 1111 1111 1101 xxxx 实际开始结束就是000000 - 111101
- 总条数包含有:4 * 24 = 64
- 预留为:64 - 62 = 2
④32条零地址指令:1111 1111 1110 0000 - 1111 1111 1111 1111 实际开始结束就是 0 0000 - 1 1111
- 总条数包含有:2 * 24 = 32
- 预留为:32 - 32 = 0
1.2.4、操作码分类

补充(ISA)
二、指令的寻址方式
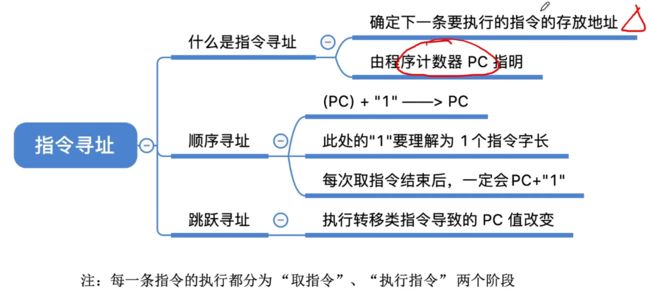
2.1、指令寻址
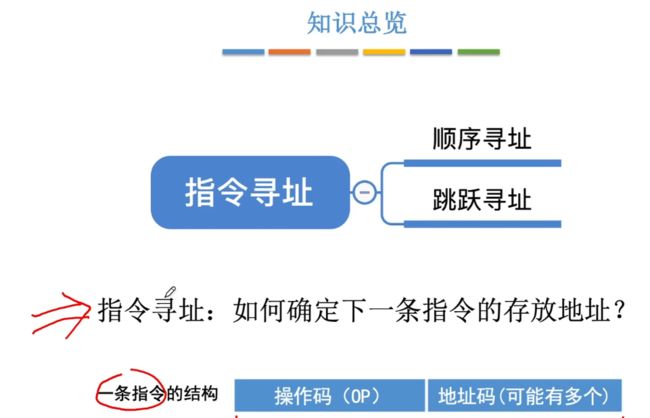
CPU可以通过顺序寻址、跳跃寻址来确定下一条指令的存放位置。本节主要就是来进行学习指令寻址的方式。
本节主要探讨的问题为:如何确定下一条指令的存放地址?
2.1.1、回顾计算机知识点(PC程序计数器)
程序计数器来记录下一条指令的存放地址。默认都是来对PC计数器来进行+1,正常都是顺序进行的。
针对于PC直接+1我们实际上要去探讨多种情况,并不是所有的情况都是要进行+1!
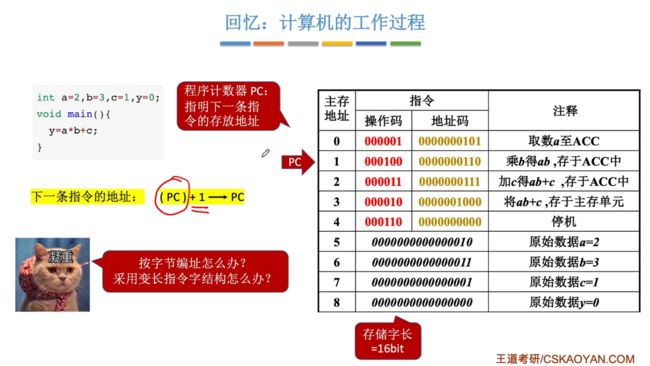
第一种情况:一般情况下是一个字节存储一条指令对于此种情况是PC+1,若是一条指令占据两个字节呢?
那么此时PC+2。
第二种情况:采用变长指令字结构,对于这种情况就会更加复杂了,不能再只是简单的进行+1、+2了。
2.1.2、方式一:顺序寻址(三个例子)
统一归类为顺序寻址方式:(PC)+n -> PC,下面列举了三种情况:
①系统采用定长指令字结构,若是主存按照字编址,指令字长为2B,则是PC+1,按照顺序来进行往下执行。
- 一般来说这里的"1"指的是指令字长。
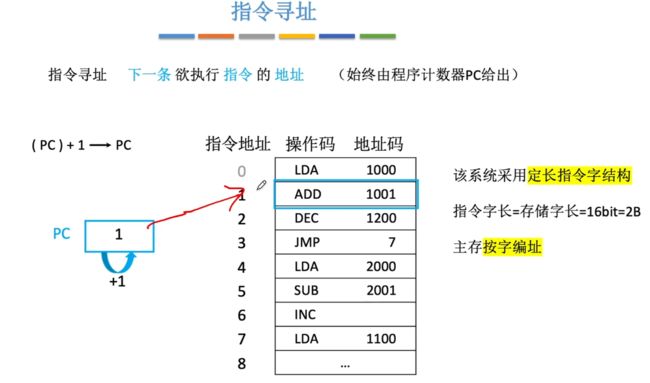
②系统采用定长指令字结构,若是主存按照字节编址,指令字长为2B,则是PC+2,依旧是按照顺序向下执行,此时是每两个单元了。
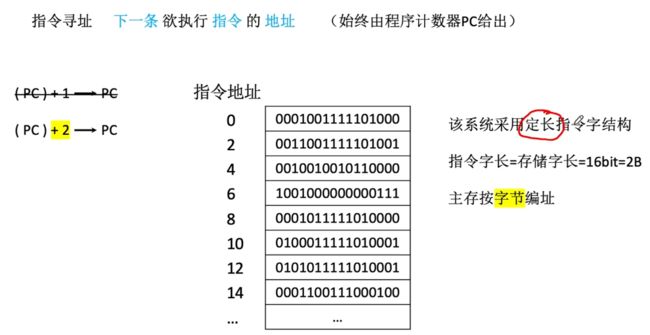
③系统采用变长指令字结构,主存按照字节编址,指令字长为2B,此时流程:读入一个字,根据操作码判断这条指令的总字节数n,最终修改PC的值,此时为PC+n。
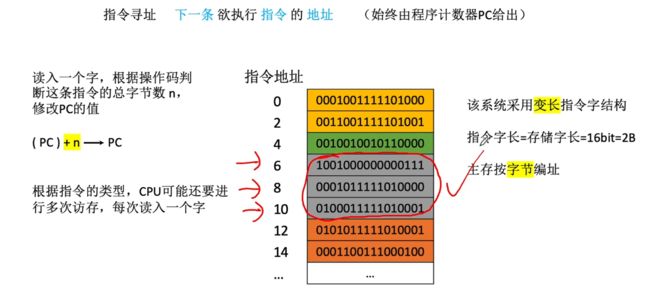
注意:根据指令的类型,CPU可能还需要进行多次访存,每次读入一个字。
2.1.3、方式二:跳跃寻址
跳跃寻址:一般由指令指出
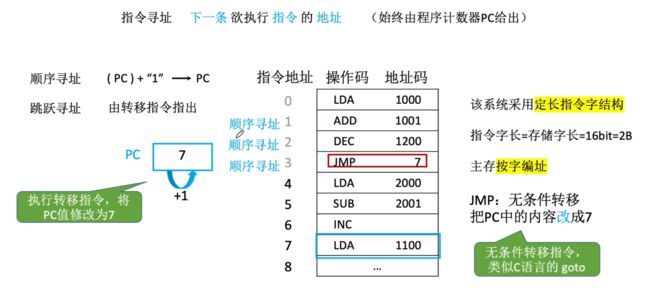
下面对于上图进行读取指令的介绍:
- 首先读取前三条指令,依次每读取一条默认PC+1。
- 接着读取第四条指令:读取到指令为JMP(还有Call以及其他一些跳转指令),那么首先PC会+1,但此时又此时JMP指令表示为跳转指令会进行无条件转移,此时则会将PC中的内容改为图中7。
本节回顾
2.2、数据寻址
EA:Effective address
2.2.1、认识数据寻址
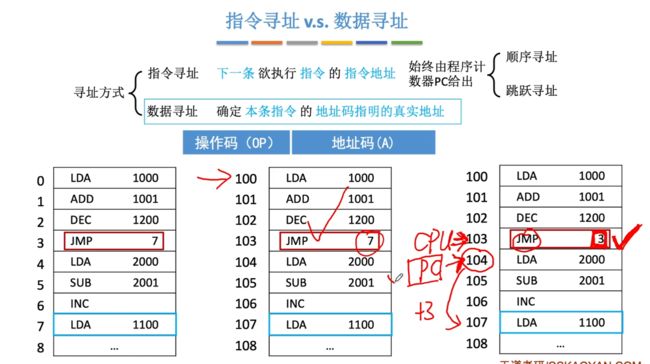
数据寻址探讨的问题:确定本条指令的地址码指明的真实地址
对于数据地址中读取的指令中的地址码,并不能够直接像上面的跳转寻址一样直接令PC=地址码,而是需要根据不同的指令来进行修改PC的值,修改方式有多种。
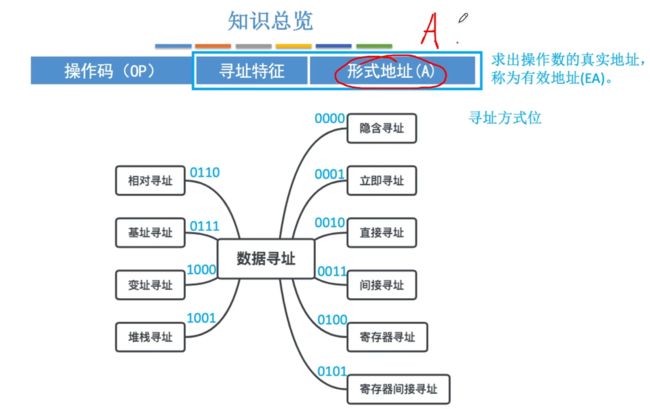
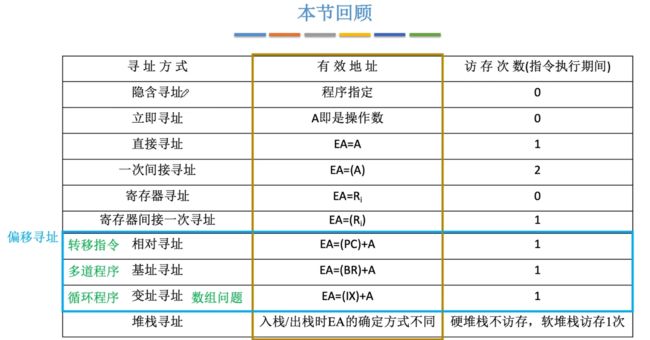
包含有10种数据寻址的方式:相对寻址、基址寻址、变址寻址、堆栈寻址、隐含寻址、立即寻址、直接寻址、间接寻址、寄存器寻址、寄存器间接寻址。
对于如何区别数据寻址的方式?
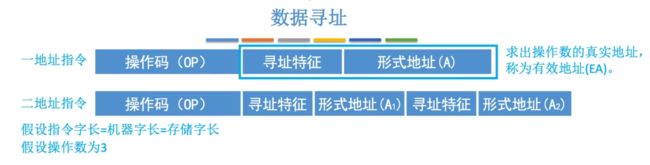
- 一地址指令:我们需要在原本的指令中添加一个寻址特征(在地址码前),不同的寻址方式用一个二进制表示寻址特征,四位即可表示所有的数据寻址方式。
- 二地址指令:由于二地址码中有两个地址码,所以每个地址码前都需要一个寻址特征,此时就会有两个寻址特征。
接下来默认这指令字长=机器字长=存储字长。
2.2.2、六种基本的寻址方式
①直接寻址
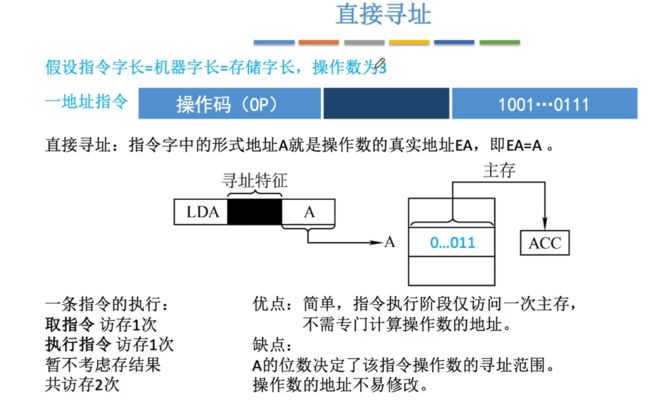
直接寻址:地址码直接就是操作数的真实地址,我们直接到主存中根据A的地址来取到这个数即可。
- EA=A
- 访存2次,取指令->执行指令(从主存指定地址中取出数据)
- 优点:简单,执行指令访存1次。
- 缺点:由于地址码存储的是主存地址,①寻址范围小(所以对于主存地址的范围有限,若是只分配到16位,那么范围也就只有216-1);②操作数地址不易修改(若是主存中的指定地址数据改变,那么原 本指令中的地址码就是错误的,除非我们修改该条指令的指向地址码。)
②间接寻址
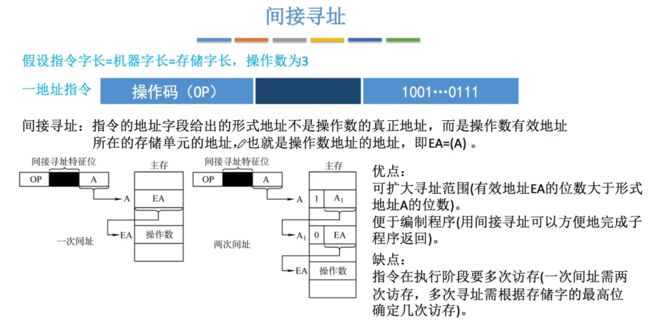
间接寻址:指令中的地址码存储的不是最终操作数的地址,我们首先需要在主存中确定该地址位置,接着从这个主存里取出到一个地址再去访问到的主存地址才是最终的操作数地址。(也就是说在主存中的地址里存储的不是最终操作数,而是存着最终操作数的主存地址)。
- EA=(A)
- 一次间接寻址:访存3次(取指令1次,执行指令2次),取指令 ->取出真实操作数的存储地址(从对应地址码指向的主存地址中取出真实存储操作数的主存地址) -> 取出操作数(到真实操作数的主存地址位置取数据)。
- 注意:对于间接寻址可能会有多次,那么多一次就需要多一次访存,对于2次间接寻址就需要访存4次(取指令1次,执行指令3次)。
- 好处:对于直接寻址中由于一次就能够存储到真实操作数,那么其地址码肯定是有限制的(因为只是保存在指令中的一部分)此时就可能出现无法识别整个主存空间的位数,通过间接寻址我们实际的范围就可以缩小来进行表示就解决了这么个范围限制问题,只不过需要多访存的开销。
- 坏处:由于间接寻址多要通过多次访存来得到最终地址,所以会有额外的访存开销!导致执行效率会变低。
③寄存器寻址
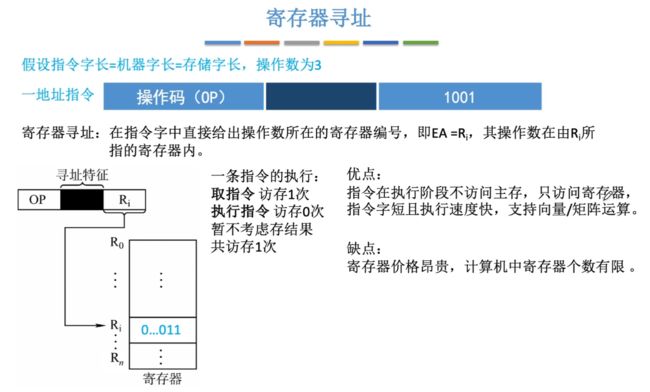
寄存器寻址:指令字中的地址码存储的是操作数所在的寄存器编号,操作数在寄存器当中。
- EA = Ri
- 访存1次(取指令1次,执行指令0次)
- 优点:无需访存,寄存器数量少即指令字短执行速度快,可以支持向量/矩阵计算。
- 缺点:寄存器昂贵,数量有限。
④寄存器间接寻址
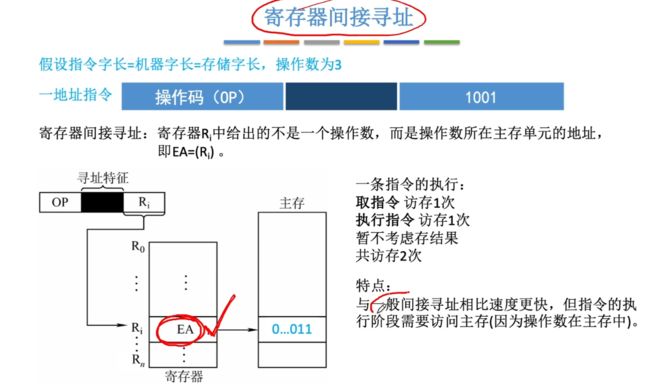
寄存器间接寻址:指令中的寄存器编号地址存储的是存放真实操作数的主存地址,我们需要到真实操作数的主存地址中去取出即可。
- EA = (Ri)
⑤隐含寻址
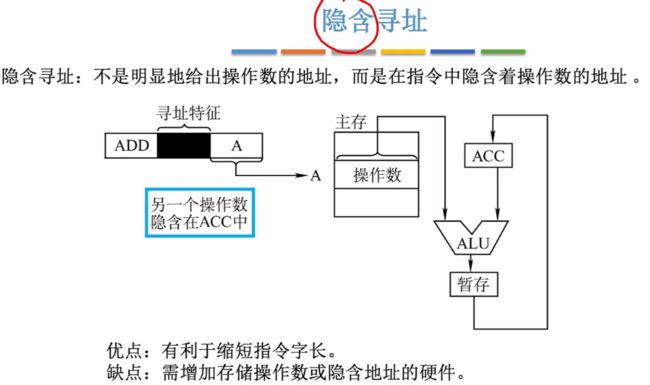
隐含寻址:不明显给出操作数的地址,而是在指令中隐含着操作数的地址。在该寻址中只需要给出一个操作数地址即可!
- 解释:实际给出的一个地址指向指定主存的地址,而另一个操作数默认是存储在ACC当中。
- 访存2次(取指令1次,执行指令1次)。
- 优点:由于只需要给出一个操作数地址,此时指令字长就会缩短。
- 缺点:需要增加存储操作数或隐含地址的硬件。
注意:上图中的隐含寻址指令是一地址指令,所以在执行指令中访存1次,若是对于零地址指令执行指令时就是访存0次,所以最终隐含寻址(最少)访存次数为0。
⑥立即寻址
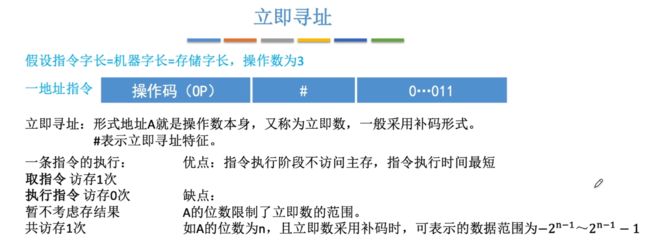
立即寻址:操作数本身的值直接就是存储在地址码中,采用的是补码形式。
- 特别:寻址特征位置为#,若是见到#就表示立即寻址。
- 访存1次(取指令1次,执行指令0次【无访存】)
- 优点:无需访存,指令执行时间短。
- 缺点:A的位数限制了立即数的范围,若是地址码的位数为n,由于是补码,此时表示数据范围为-2n-1 - 2n-1 - 1。
本节回顾
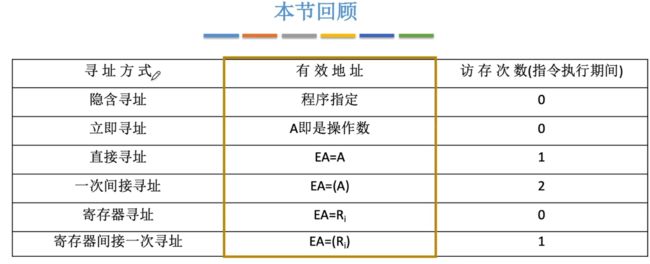
注意:这里的隐含寻址指的是零地址指令,最少在指令执行期间访存0次!
2.2.3、三种偏移寻址
2.2.3.1、认识偏移寻址
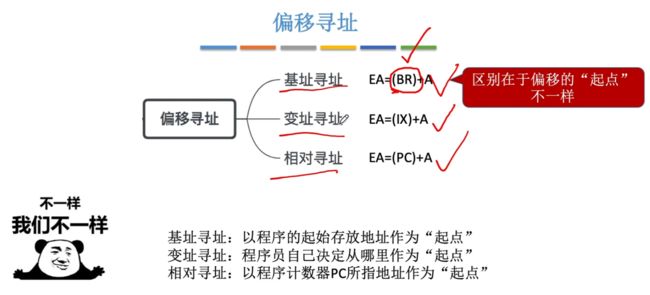
偏移寻址:以某个地址为起点,形式地址视为"偏移量"
属于偏移寻址包含三种:相对寻址、基址寻址、变址寻址。
- 基址寻址:以程序的起始存放位置作为"起点"。
- 变址寻址:程序员自己决定从哪里作为"起点"。
- 相对寻址:以程序计数器PC所指地址作为"起点"。
区别:在于偏移的"起点"不一样。
⑦基址寄存器(程序的起始存放位置作为"起点")
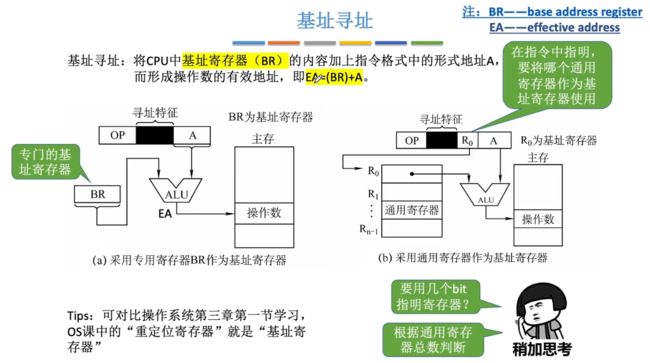
基址寄存器(BR,base address register):将CPU中基址寄存器(BR)的内容加上指令格式中的形式地址A,而形成的操作数的有效地址,即EA=(BR)+A。
- EA:Effective address。
对于基址寄存器可采用专用寄存器BR,也可采用通用寄存器来作为基准寄存器。
- 针对通用寄存器:需要指明第几个寄存器,所以会有专门位置来存储这个R0寄存器。
访问过程:若是主存地址从100开始,那么100地址的这条指令必须要使用基址寻址,否则本身地址码只能够表示5是无法定位当前程序段的,使用基址寻址后,首先获取到BR中的地址也就是100,接着100+5=105,即可定位到原始数据a=2,接着从主存中取出操作数即可!
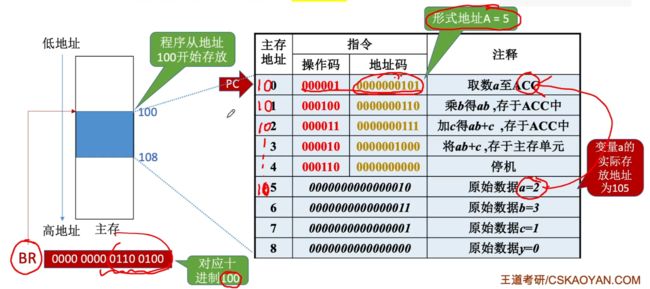
基址寻址的作用:将CPU中基址寄存器(BR)的内容加上指令格式中的形式地址A,而形成操作数的有效地址,即EA=(BR)+ A。
优点:①可以便于程序的浮动(通过这样子的寻址,我们若是想要修改操作数的值,只需要直接在对应的偏移位置105修改即可,下次访问还是可以根据偏移来读取到最新的值 );②方便实现多道程序并发执行;③可以扩大寻址范围。
- 扩展:程序运行前,CPU将BR的值修改为该程序的起始地址(存在操作系统PCB中)。
注意:基址寄存器是面向操作系统的,其内容由操作系统或管理程序确定。在程序执行的过程中,基址寄存器的内容不变(作为基地址),形式地址可变(作为偏移量)。
- 若是汇编程序员,可以对通用寄存器中的值进行修改,但是若是将通用寄存器指定为基址寄存器,那么无法对其进行修改,只有操作系统才能够对其进行修改处理。

⑧变址寻址(程序员自己决定从哪里作为"起点")
变址寻址(详细)
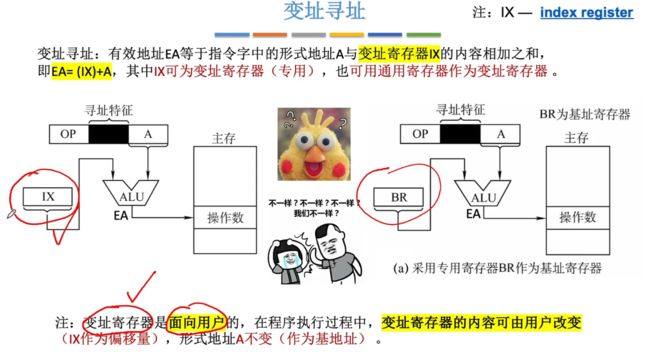
- 对于变址寄存器来说,用户可以自行去指定该寄存器中存储的地址!!!
变址寻址:有效地址EA等于指令字中的形式地址与变址寄存器IX的内容相加之和,即EA=(IX)+A,其中IX可为变址寄存器(专用),也可用通用寄存器作为变址寄存器。
注意:与基址寄存器类似,只是寄存器不同而已,变址寄存器是面向用户的,在程序执行过程中,变址寄存器中的内容可由用户改变(IX作为偏移量),形式地址A不变(作为基地址)。
实际应用举例:
首先看个例子,是一个for循环累加,对于循环操作每一条指令重复性的操作都是使用了单独一条指令,如果循环的次数更多呢?此时就会造成指令数冗余,如何解决呢?可以采用变址寻址。
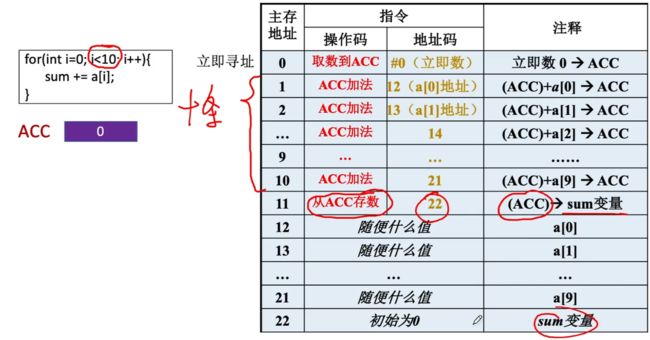
通过增加一个变址寄存器即可存储对应访问的数组偏移量,接着使用变址寻址指令后,地址码的值位对应数组的首位地址,此时使用首位地址+偏移量,即可确定数组元素的位置,接着搭配跳转指令,就可以完成循环了!
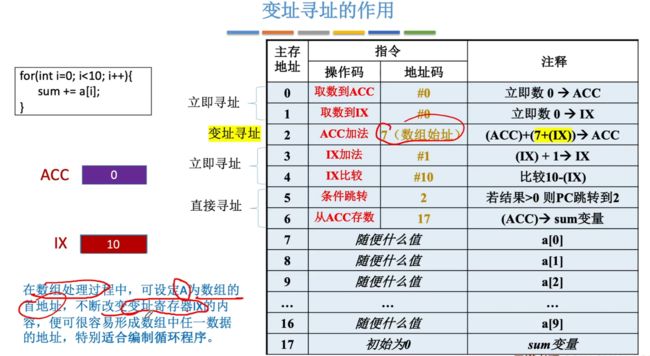
变址寻址的作用:在数组处理过程中,可以设定A为数组的首地址,不断改变变址寄存器IX的内容,便可很容易形成数组中任一数据的地址,特别适合编制循环程序。
变址寄存器中的值是我们普通程序员可以采用指令的方式去进行修改的,这一点与基址寄存器不一样。
基址&变址复合寻址(例子,含寻址流程)
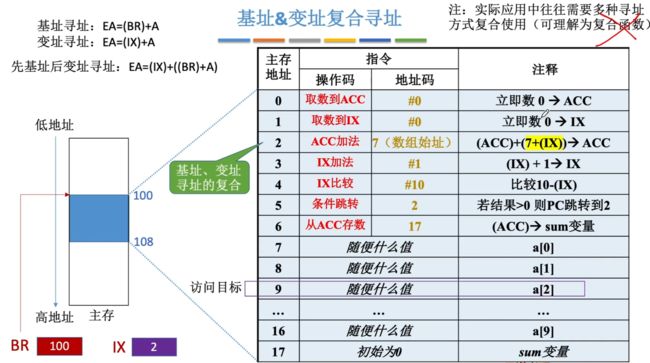
寻址流程:若是主存地址是从100开始,100-117,那么通过基址寄存器中可以存储当前程序的一个起始位置100,而变址寄存器中存储着数组访问的指定元素下标针对数组首地址偏移,此时若是我们想要对数组中的数据进行操作,我们就可以采用基址&变址复合寻址,此时可以构成如下命令:
- 先基址后变址:EA=(IX)+((BR) + A),对应的指令给出A地址(基于数组初始位置针对于该程序的偏移量),接着来定位数组在整个主存中的初始位置,接着加上(IX)偏移量即可确定要访问的指定数组元素在整个主存中的位置!
⑨相对寻址
相对寻址:把程序计数器PC的内容加上指令格式中的形式地址A而形成操作数的有效地址,即EA=(PC)+A,其中A时相对于PC所指地址的位移量,可正可负,补码表示。
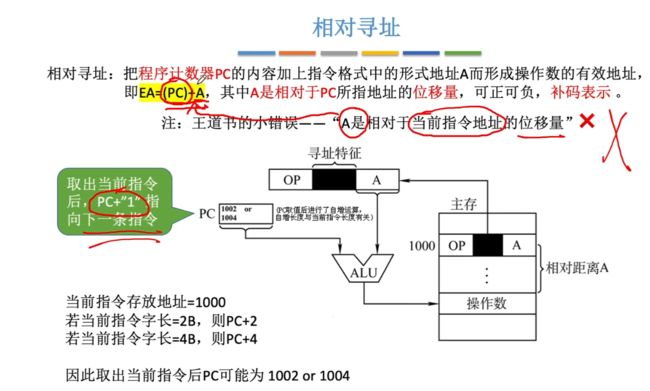
相对寻址的流程示例:
举个有问题的例子,下面情况若是采用直接寻址会出现错误:此时会直接跳转到主存地址2上,这就不对了:
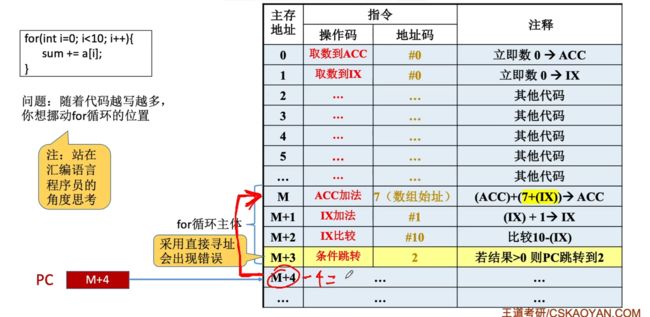
我们可以采用相对寻址,通过基于当前PC的位置来进行加减从而定位到循环的初始位置,需要注意的是,若是进行相对寻址前,首先会先执行PC+1,+1之后才会重新进行相对寻址修改PC的值(这里就是+1后-4,即可重新定位到M地址):
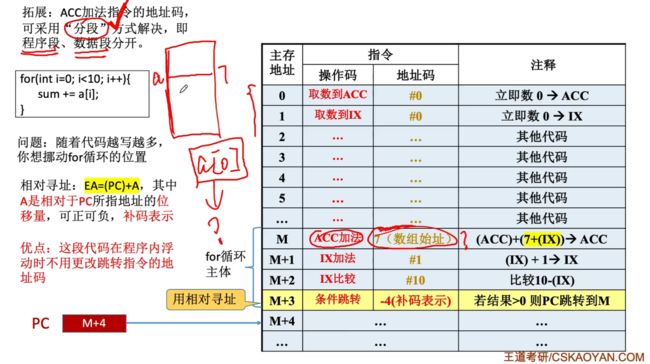 好处:当某段代码在程序内浮动时不用更改跳转指令的地址码,只需要使用PC去加减对应的偏移即可。
好处:当某段代码在程序内浮动时不用更改跳转指令的地址码,只需要使用PC去加减对应的偏移即可。

- 相对寻址方便浮动:指的是一段代码在程序内部的浮动,可以通过对PC进行偏移量来快速定位位置。
本节回顾
基址寻址方便浮动:指的是整段程序在内存中的浮动,可以通过基址寄存器来确定整个程序的初始位置。
相对寻址方便浮动:指的是一段代码在程序内部的浮动,可以通过对PC进行偏移量来快速定位位置。
补充:硬件如何实现数的"比较"?
实现原理:利用的是cmp指令,比较a与b,本质就是进行a-b,最终的结果会保存在状态字寄存器中PSW,接着根据PSW的几个标志位来进行判断决定是否需要进行转移。
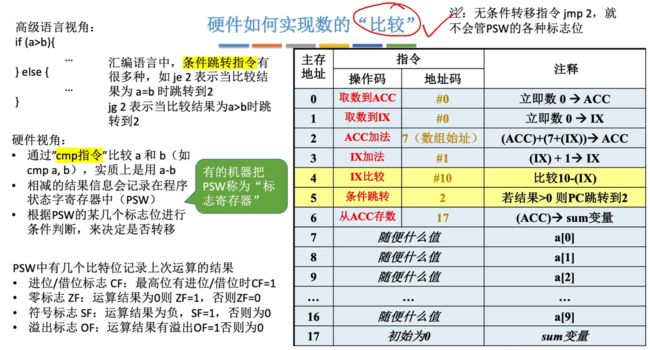
- je2(jump when equal):若是a=b相等,则进行跳转。
- jg2(jump when greater):若是a > b,则进行跳转。
- 若是jmp 2就不会管任何PSW中的标志位,直接进行跳转。
⑩堆栈寻址
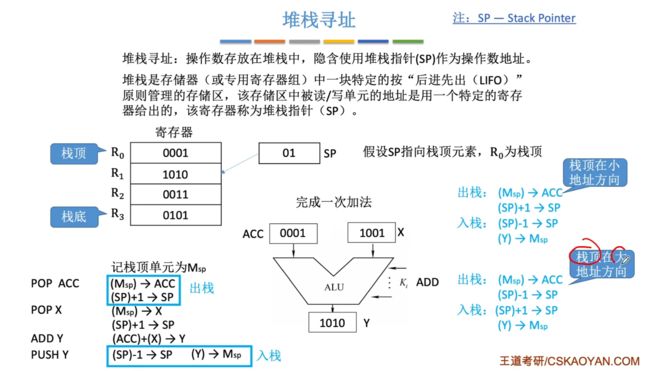
堆栈寻址:操作数存放在堆栈中,隐含使用堆栈指针(SP,stack pointer)作为操作数地址。
- 硬堆栈:使用多个寄存器来组成一个寄存器组实现堆栈。
- 软堆栈:在主存中划分一部分区域来作为堆栈。
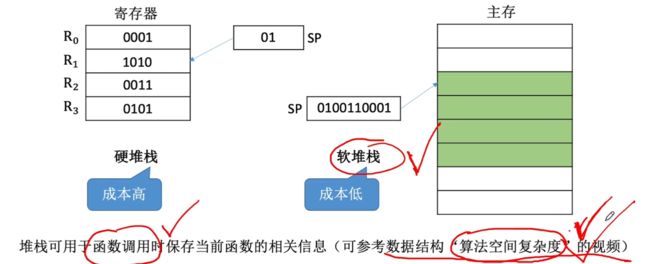
堆栈寻址流程:SP用于指向栈的位置,始终指向栈顶。入栈sp+1,出栈sp-1。
- 对于不同情况,栈顶可能会在小地址方向(入栈是从低到高)或者大地址方向(入栈是从高到低)。
实际应用:函数调用保存当前函数的相关信息。
注意:若是使用硬堆栈则不需要访存,软堆栈则需要访存。
本节所有寻址回顾
三、程序的机器级代码表示
3.1、高级语言与机器级代码之间的对应(探讨指令中地址码数据在哪儿?)
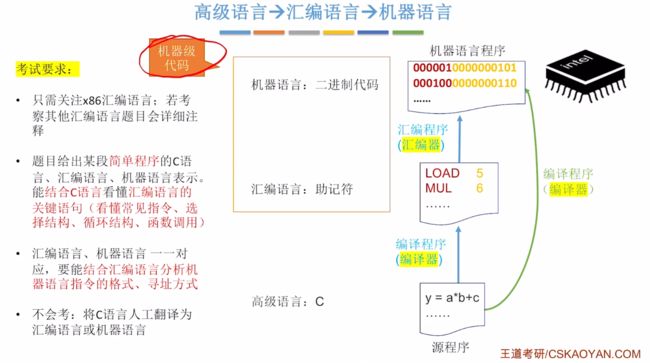
3.1.1、高级语言->汇编语言->机器语言
高级语言->汇编语言->机器语言
- 一条高级语言可能会转为多条汇编语言,一条汇编语言对应翻译一条机器语言(一一对应)
- 其中汇编语言、机器语言统称为机器级代码。
注意:对于汇编语言会详细注释版本,若是没有注释默认就是x86汇编语言。
主要掌握x86汇编语言指令基础即可。
- x86指的是86系列的汇编语言,一开始是1978年发明的cpu中使用的是8086汇编语言,之后则出现了80286、80386等一系列86汇编语言指令。
3.1.2、x86汇编语言指令基础
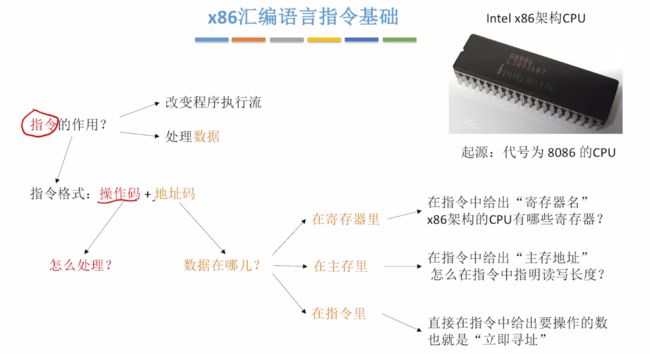
指令由操作码与地址码组成,操作码表示怎么处理?地址码则是表示的是数据在哪里。
对mov指令进行举例:
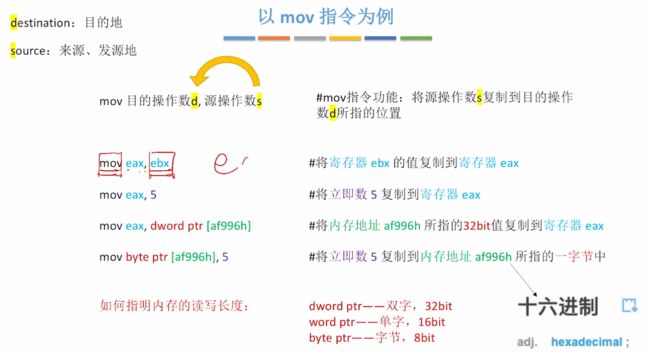
语法格式:mov 目的操作数d, 源操作数s
1、mov eax, ebx:将寄存器ebx的值复制到寄存器eax中。
2、mov eax, 5:将立即数5复制到寄存器eax中。
3、mov eax, dword ptr [af996h]:将内存地址af996h所指的32bit值复制到寄存器eax中。
4、mov byte ptr [af996h], 5:将立即数5复制到内存地址af996h所指的一字节中。
对于 [xxx]前的含义如下:
- dword ptr:双字,32bit
- word ptr:单字,16bit
- byte ptr:字节,8bit
3.1.3、x86架构CPU的一些寄存器(通用寄存器、变址寄存器、堆栈指针)
下面是三个部分寄存器:

①如EAX、EBX、ECX、EDX寄存器:
说明:以E开头的为寄存器,对于E.X,最后的X表示的是未知
mov eax, ebx:寄存器->寄存器,寄存器寻址。
mov eax, dword ptr [af996h]:主存->寄存器,直接寻址+基址寻址的组合方式。
mov eax, 5:立即数->寄存器。
②如ESI、EDI
说明:结尾为I的为index表示为变址寄存器,其中S是Source,D是Destination。
应用:通常变址寄存器用来表示线性表、字符串的处理。
③如EBP、ESP
说明:BP表示的是Base Pointer堆栈基指针,SP表示的是Stack Pointer堆栈顶指针。
应用:堆栈寄存器用于实现函数调用。
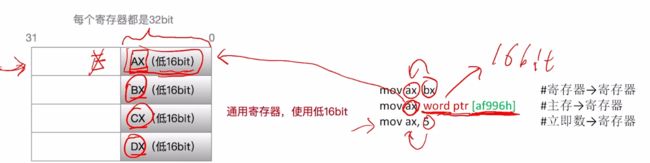
对于所有E开头的默认都是32bit,对于通用寄存器我们可以使用更加灵活一些,可以将E扩展部分去掉,剩余AX、BX、CX、DX用来表示低16位,此时就只有16位。
- 对于AX、BX、CX、DX还可以使用的更加灵活,可拆分为AX(AH、AL)、BX(BH、BL)、CX(CH、CL)、DX(DH、DL)每一个部分表示8bit。.
- 拆分完之后,可以将原先的命令修改为:
mov ah, bl、mov ah, byte ptr [af996h]、mov ah, 5。 - 小总结:对于通用寄存器我们可以使用16bit,也可以使用8bit,还可以使用32bit。

对于变址寄存器以及堆栈指针则都是32位,不能够像通用寄存器一样只能固定使用32bit。
更多例子:列举一条 mov eax, dword ptr[ebx],这里是将ebx所指主存地址的32bit复制到eax寄存器中,这里与之前列举的不一样这里的是寄存器间接寻址。其他更多情况如下图:

额外例子:针对于[ebx+8]指的是ebx寄存器偏移8个单位来找到该数据

总结
本章节探讨的是如何在汇编语言当中指明数据在哪个地方?下一小节来探讨汇编指令可以对数据进行哪些处理。
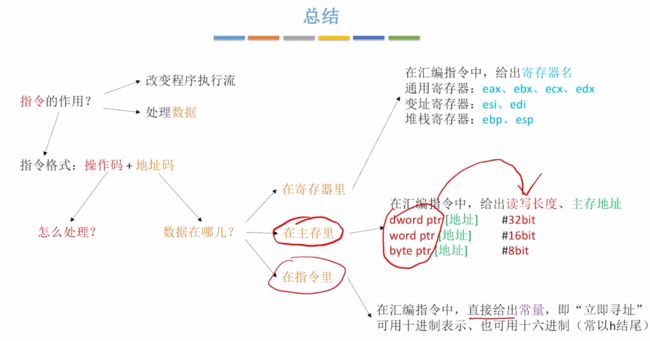
3.2、常用的X86汇编语言指令格式(Intel格式)
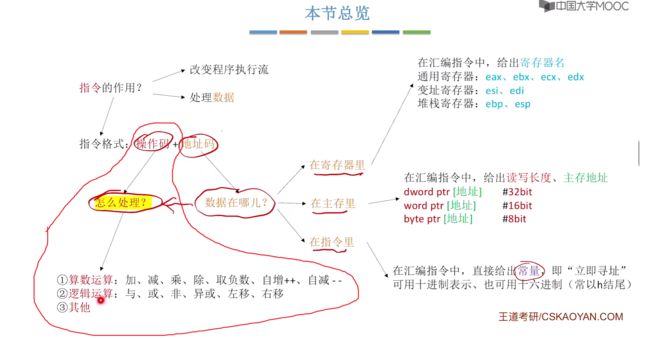
包含各类的算数运算、逻辑运算以及其他。
3.2.1、常见的算数运算指令(包含王道书指令示例解释)
在算数运算指令中,目的操作数d不可以是常量,只可能是寄存器、主存地址,而对于source则可以任意取,可以是常数也可以是来自于寄存器、主存等。
常见的算数运算指令如下:

额外对于上面指令着重解释的有除法,对于除法divide,可以看到只有一个操作数,该操作数表示的是除数,而对于被除数则是放在edx:eax(edx和eax两个寄存器中),商存入eax,余数存入edx。【实际这个被除数是隐含寻址】
edx:eax写法:在进行除法运算之前需要把被除数位扩展,例如32b/32b,需要将被除数这个32bit扩展为64位,也就是用64bit的被除数除以32bit的除数。由于寄存器默认是32bit,那么我们也说了需要32bit扩展为64bit的被除数,此时就需要两个寄存器,更高位放在edx,更低位放在eax,并且最终商会放在eax中,余数存放在edx中。
王道书对于指令示例解释
王道书解释:两个操作数,后面的放到前面中,对于左边的数不能够是常量,右边的可以是常量或者从内存、寄存器中取出的。

注意:在x86中指令不能两个数都是来自于主存,要么同时来自于寄存器,要么一个来自于寄存器,一个来自于主存,这个规则目的就是不要太多次访问主存,访问主存次数越多,越慢。
3.2.2、常见的逻辑运算指令
常见的逻辑运算指令:与、或、非、异或、左移、右移。
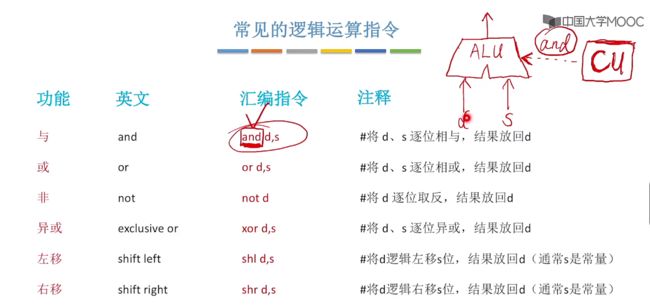
对于两个操作数的,最终的结果放在第一个操作数中。
若是一个操作数的,最终的结果依旧是放在该操作数中。
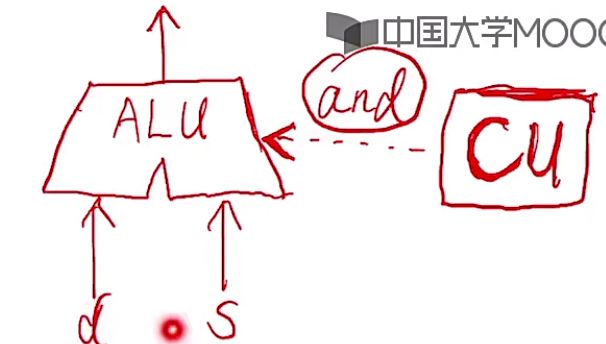
控制单元CU会依次执行并解析这些指令,当确定运算指令后(如add、or…)CU会给ALU算数逻辑运算单元发送与这条指令相对应的控制信号来进行相应操作,对应的d、s会相应的送到对应d、s端,最终结果从输出端输出。
3.1.3、其他指令
其他指令:分支结构、循环结构、函数调用、数据转移如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9hSOkUXd-1687531300346)(C:\Users\93997\AppData\Roaming\Typora\typora-user-images\image-20230623111945728.png)]
3.3、AT&T格式和Intel格式
3.3.1、认识了解AT&T格式和Intel格式
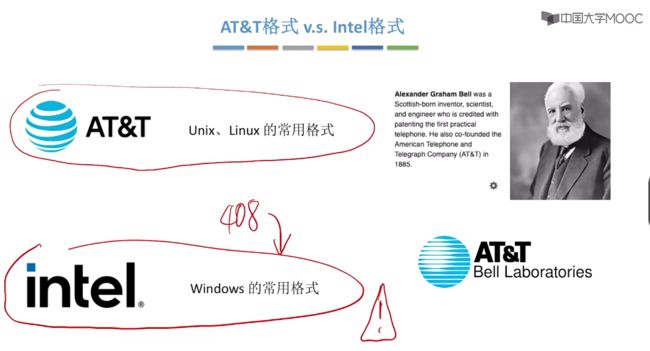
对于Intel格式就是3.2中学习的X86汇编语言格式,对于各大教材中的则是AT&T格式。
AT&T的创始人是贝尔,也就是贝尔实验室,对于计算机中使用的晶体管、unix系统、c语言都是贝尔实验室发明的。
往年的408都是使用intel格式的汇编语言,重点关注intel格式。
3.3.2、AT&T格式 VS Intel格式(区别描述)
如何精准看出AT&T格式与Intel格式区别?通过()、[]以及%即可确定,若是有()、%则表示AT&T格式,若是[]则是Intel格式。
- 最大的不同是源操作数、目的操作数位置相反。

下面是一些不同区别:
①源操作数、目的操作数位置相反。
②寄存器名之前加%。
③表示立即数之前需要加$符号。
④读写长度使用的是b、w、l来表示byte、word、dword。跟在操作符最后,如addw,addl,addb。
- 注意:在AT&T中,若是没有指明长度,默认与Intel一样也是32bit。
⑤对于指定寄存器、主存偏移量表示,原本Intel的是[ebx - 8],此时就变为了-8(%ebx),需要加一个括号并且前面跟上偏移的数字。
⑥较复杂的式子,Intel表示为mov eax, [ebx + ecx * 32 + 4],含义为[基址 + 变址 * 比例因子 + 偏移量],此时在AT&T中则表示
mov 4(%ebx, %ecx, 32), %eax。举例在数组中确定一个元素【基址 + 变址 * 比例因子】,接着在这个元素中找到指定属性获取【+ 偏移量】这种访问方式十分常见,所以就可以进行固定一种写法对于AT&T也是同样。
3.4、选择语句机器级表示
3.4.1、程序中的选择语句
在Intel X86处理器中,程序计数器PC(Program Counter)一般被称为IP(Instruction Pointer)

对于汇编语言遇到选择跳转时就需要跳转指令。
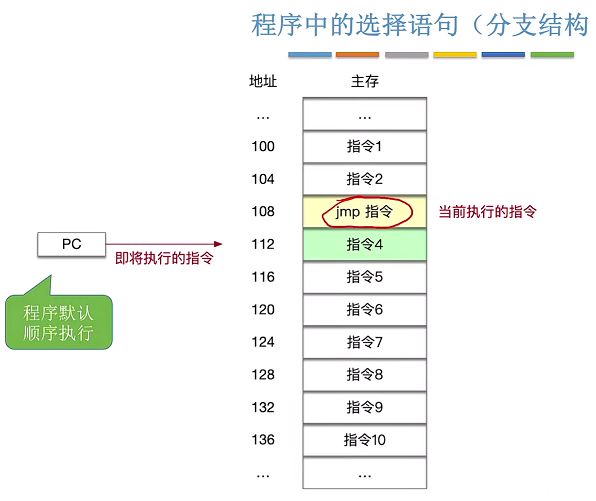
3.4.2、无条件转移指令jmp
无条件转移指令:jmp,会让pc无条件的转移到<地址>

举例:
- jmp 128:直接跳到主存地址为128位置。
- jmp eax:跳到对应eax通用寄存器内的指定地址。
- jmp [999]:地址可以来自于主存。
- jmp NEXT:直接跳转到指定的锚点位置NEXT(可以取任意合适的名字即可)。
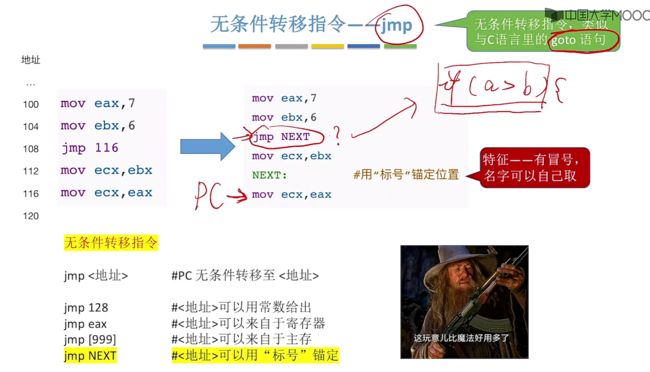
对于实际应用中,作为程序员无法提前知道对应的跳转位置地址在哪里,所以此时转变写法,通过使用标号锚点定位,如使用jmp NEXT,对应指定行则为NEXT:
3.4.3、条件转移指令jxxx
条件转移指令:jxxx,其需要和cmp指令搭配使用
包含的条件判断包含:==、!=、>、>=、<、<=

标准的搭配写法如下:
cmp eax, ebx # 比较eax、ebx寄存器值
jg NEXT # 若是>,那么跳转到NEXT标号位置
3.4.4、示例:选择语句的机器级表示
示例与c语言中的if进行比较:
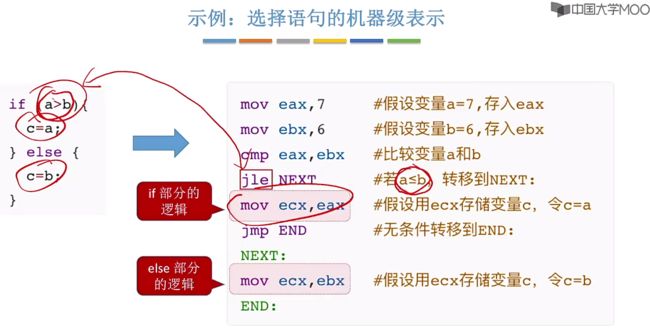
扩展:cmp指令的底层原理
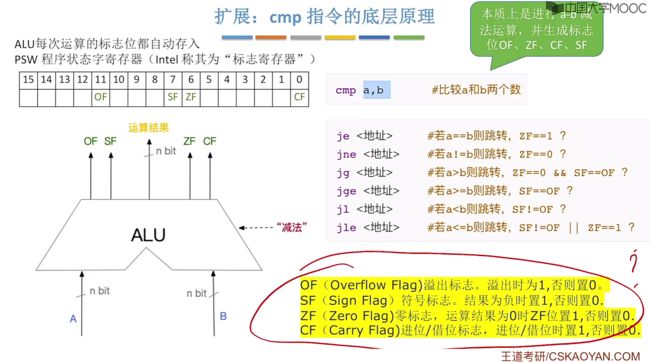
本质上是让ALU来进行减法运算,最终的计算得到结果后,相应的状态会保存在PSW中(在Intel中称为"标志寄存器")
最终通过相应的标志位来判断运算结果。一般在cmp指令后会跟着相应的跳转指令实际上就是对应看相应的状态标志,如下 :

3.5、循环语句机器级别表示
3.5.1、使用条件转移指令实现循环(针对for、while循环)
for循环、while循环都可以实现同一个循环:

可以采用条件转移指令实现循环,上述程序的实现需要4个部分组成:
①循环前初始化。
②是否直接跳过循环。
③循环主体。
④是否继续循环。
3.5.2、使用loop指令实现循环(loop)
使用loop指令实现循环:对于直接循环n次我们可以考虑使用一个寄存器以及一个loop循环来进行实现:
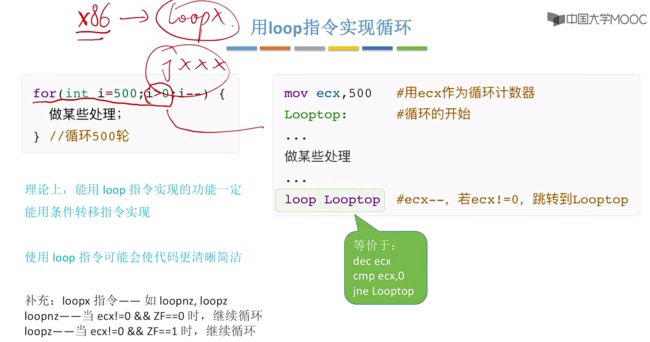
对于loop指令会对指定的寄存器ecx自动的进行—,直到ecx==0结束跳出循环。
一条loop Looptop指令等价于如下:
dec ecx # -1
cmp ecx, 0 # 比较两个操作数
jne Looptop # 若是不相等继续执行循环
注意:若是使用loop指令那么一定要搭配使用ecx。
使用loop指令的原因?使代码更加简洁。
补充:loopx指令,例如loopnz,loopz
- loopnz:也就是当ecx != 0 && ZF == 0,继续循环。其中nz表示not zero。
- loopz:就是当ecx != 0 && ZF == 1,继续循环。z表示为zero。
3.6、过程(或称函数)调用的机器及表示
3.6.1、Call和ret指令(汇编指令)
考察点在选择题中
3.6.1.1、高级语言以及x86汇编语言的函数调用(call、ret)
高级语言视角的函数调用过程:
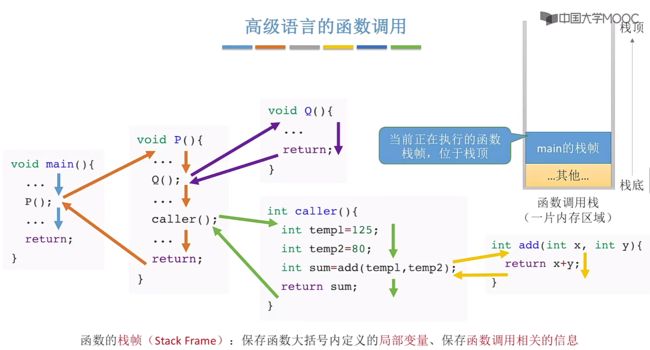
对于当前正在执行的函数栈帧,位于栈顶。
x86汇编语言的函数调用:
在汇编语言中,使用了call、ret两条指令来表示调用与返回

3.6.1.2、call、ret调用时如何确定返回的代码行号?(栈帧中存放IP旧值)
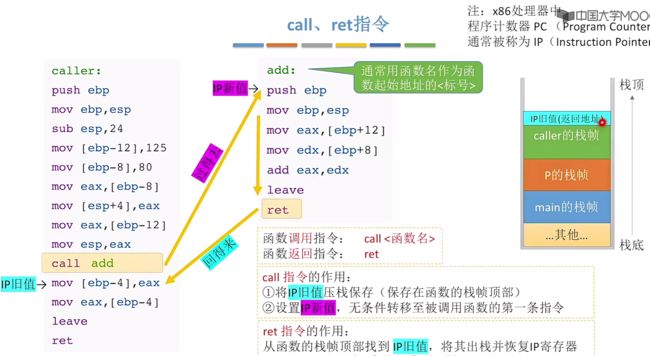
此时有一个问题,对于call、ret这些都会去更改PC的指向(在这里PC又称为IP),那么当进行call调用函数后,对应的函数结束时执行ret返回时,那么如何确定返回的代码行号位置呢?
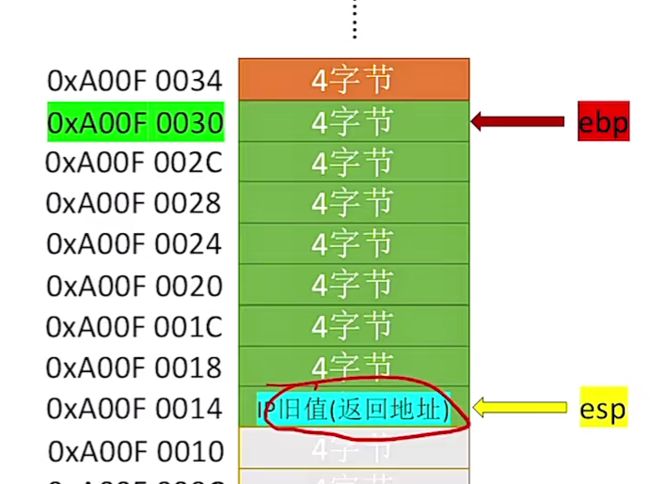
- 回到call指令,当执行call指令的时候(此时IP会指向mov指令,也就是call的下一行指令)①会将IP旧值压栈保存,保存在函数的栈帧顶部。②接着会设置IP新值,无条件的转移到被调用函数的第一条指令。
- 当被调用函数的指令执行到ret后,此时执行ret指令,会从函数的栈帧顶部找到IP的旧值,将其出栈并且恢复IP寄存器。
call作用:①会将IP旧值压栈保存,保存在函数的栈帧顶部。②接着会设置IP新值,无条件的转移到被调用函数的第一条指令。
ret指令作用:从函数的栈帧顶部找到IP的旧值,将其出栈并且恢复IP寄存器。
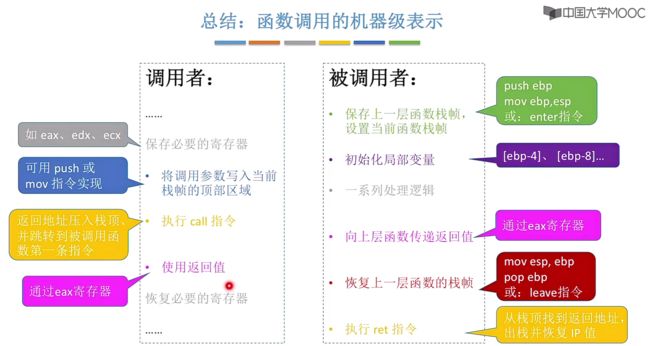
总结:函数调用的机器级表示
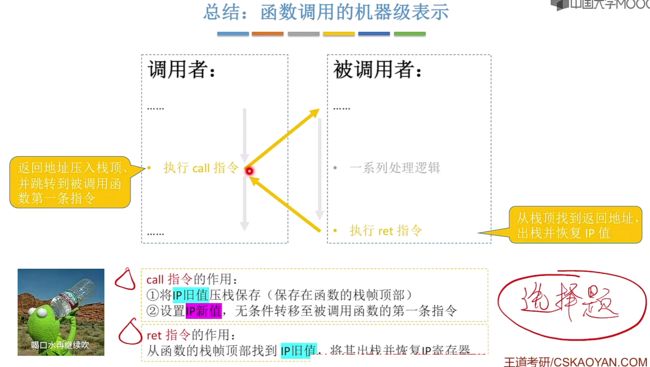
此时依旧有几个问题如下:
- 如何调用参数、返回值?对于call、ret两条指令并不可以带参数以及返回值。
- 如何访问栈帧中的数据?
- 每个栈帧中包含哪些内容?
- 为什么函数调用栈会倒过来画?
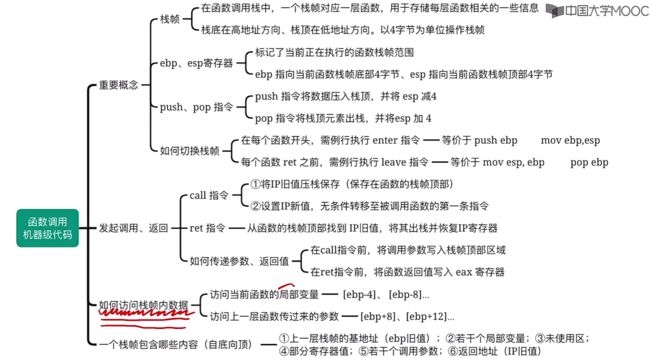
3.6.2、如何访问栈帧?
解决问题1:为什么函数调用栈会倒过来画?(主存位置映射原因)
在实际系统中,一个32位的操作系统会为进程分配4GB虚拟空间,分为操作系统内核区以及用户区,对于用户栈则保存在用户区当中!
由于这个存储位置原因,此时我们会将栈底放在高地址,栈顶放在低地址中,这也就是为什么函数调用栈会倒过来画的原因。
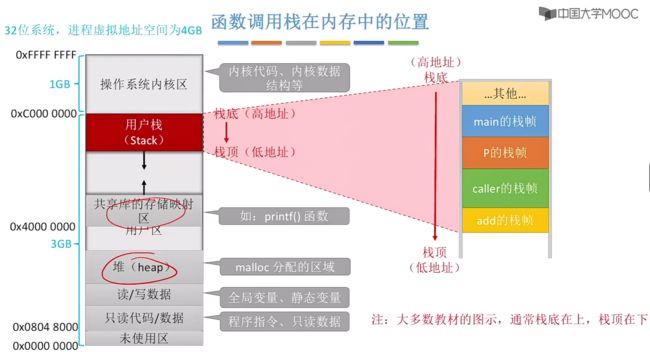
解决问题2:如何访问栈帧中的数据?(pop、push或者mov)
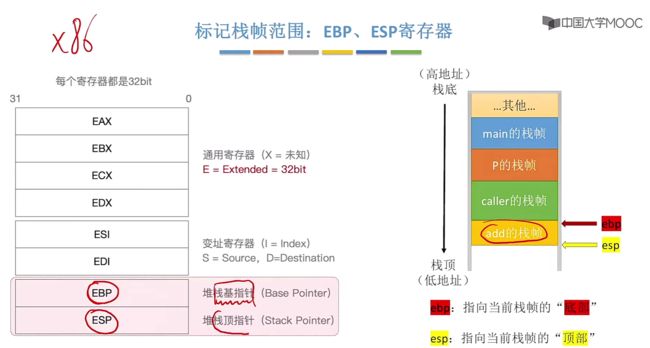
①了解EBP、ESP寄存器作用
标记栈帧范围:EBP、ESP寄存器。在一个CPU内部只有一个EBP和一个ESP。
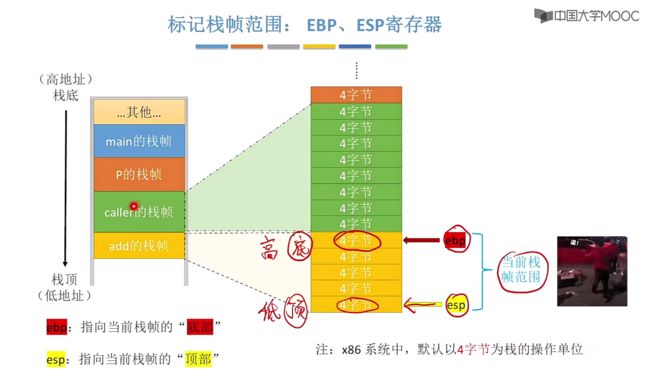
栈帧的内部在x86系统中,无论是读或写默认是以4字节为栈的操作单位。
- ebp是栈底(高地址),esp是栈顶(低地址)。
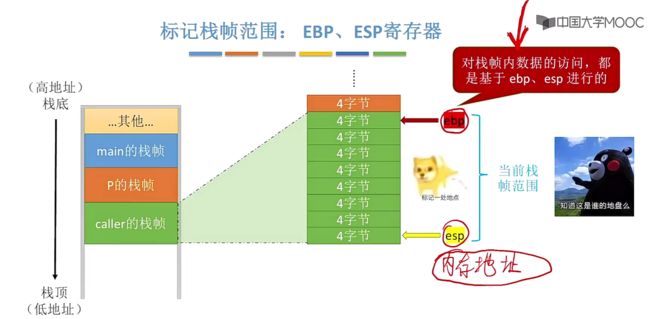
②使用pop、push指令来读写栈帧中数据
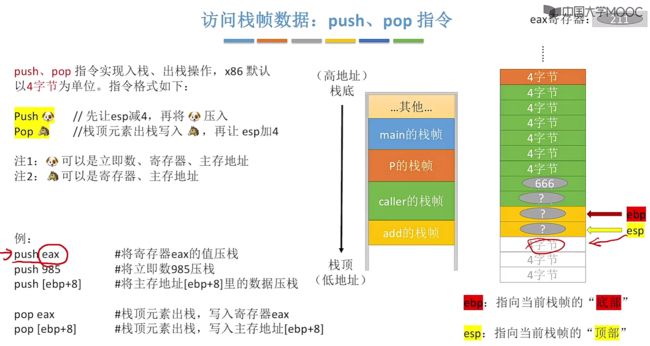
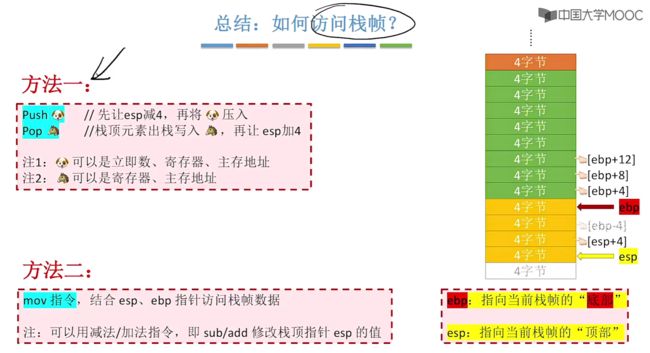
对于栈帧内数据的访问,都是基于ebp、esp进行的,那么此时问题就是如何使用ebp以及esp来对栈帧中的数据进行读或写?
- 对于访问栈帧中的数据我们可以采用push、pop指令来进行读出/写入操作。| push中可以是立即数、寄存器以及主存地址。pop可以是寄存器或者主存地址。
实际指令含义:
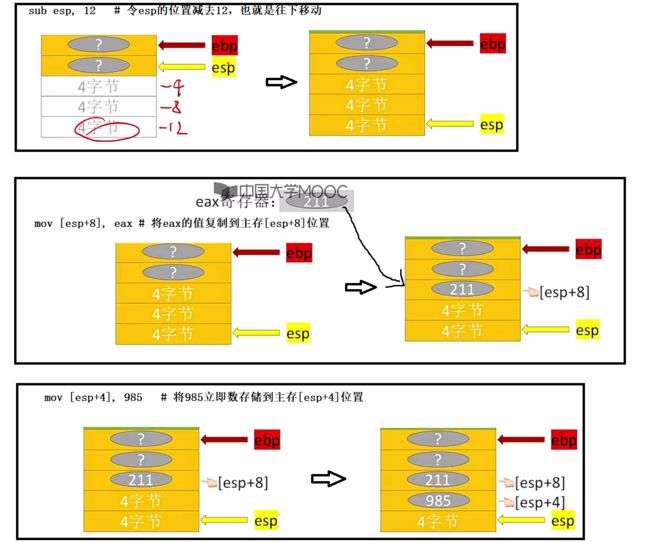
- pop xxx:先让esp减4,接着将xxx压入。
- push xxx:栈顶元素出栈写入xxx,再让esp加4。
实际例子:
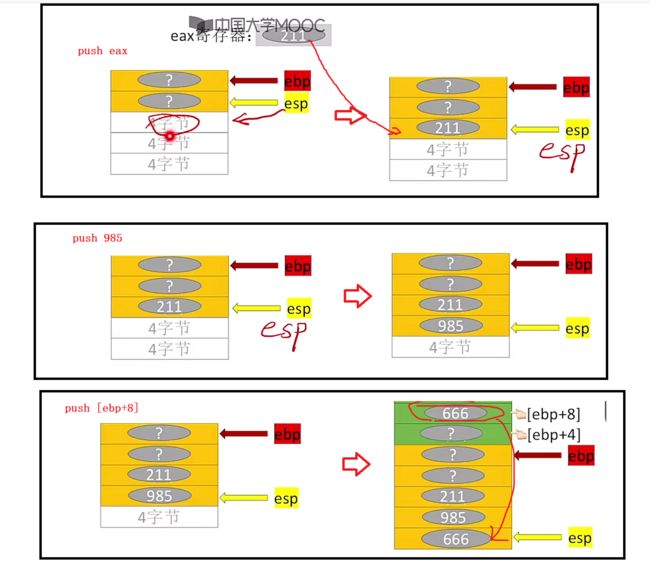
push eax # 将寄存器中的eax值压栈,此时esp+4
push 985 # 将立即数985压栈,此时esp+4
push [ebp+8] # 将主存地址[ebp+8]里的数压栈(两个位置,一个位置4位),此时esp+4
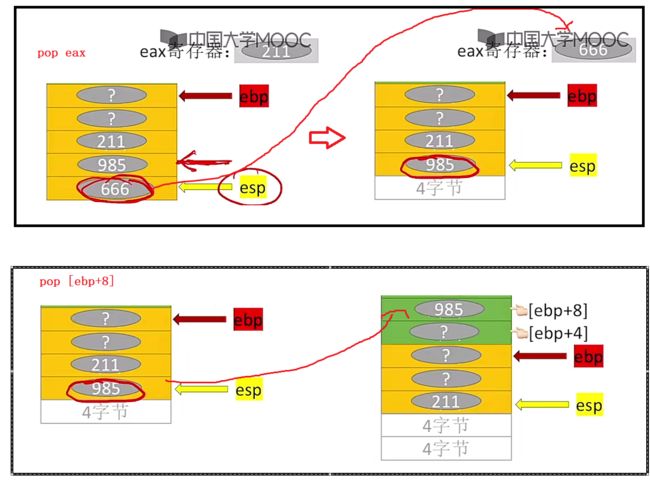
pop eax # 栈顶元素出栈,写入寄存器eax
pop [ebp+8] # 栈顶元素出栈,写入主存位置[ebp+8]
相对应下面的图示:
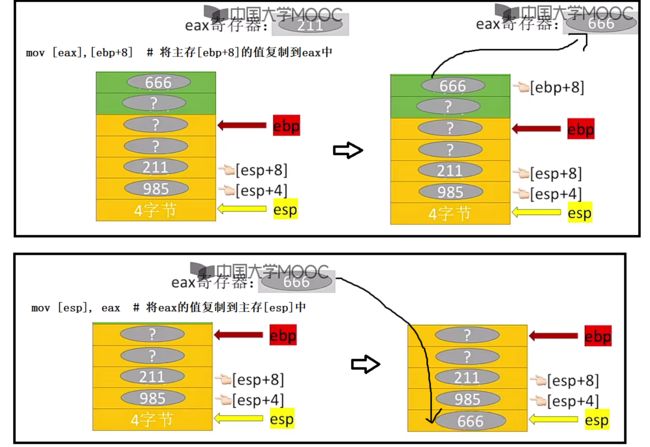
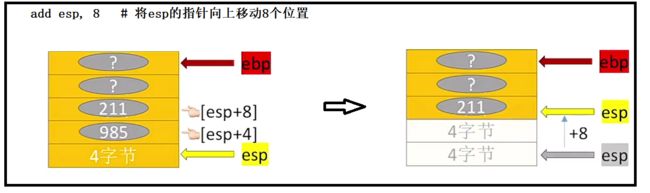
③使用简单指令mov来访问栈帧数据
更加简单的指令来去访问栈帧数据:mov
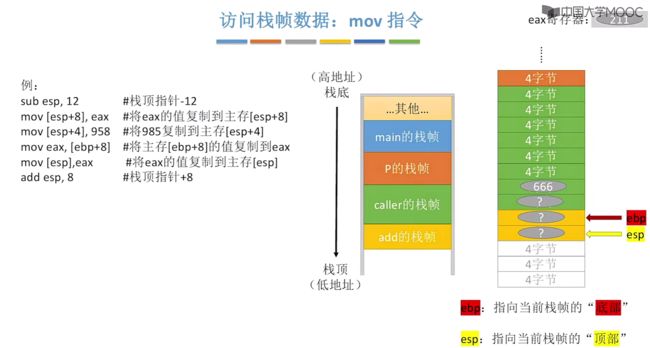
通过加减法来修改栈顶指针esp的值,接着使用mov来进行快速的复制值。
对应上图中mov以及sub、add指令图示:
总结:如何访问栈帧?
截止目前之前提出的问题解决了两个,还有两个:
- 如何调用参数、返回值?对于call、ret两条指令并不可以带参数以及返回值。
- 如何访问栈帧中的数据? √
- 每个栈帧中包含哪些内容?
- 为什么函数调用栈会倒过来画? √
3.6.3、如何切换栈帧?(进入函数时执行enter,结束前执行leave)
①认识栈帧的切换
如下是执行add栈帧后调用结束返回执行caller的流程,你可以看到:当进入到某个函数A中,ebp与esp会默认去指向到该栈帧中,若是函数A结束,此时回到函数B时同样ebp、esp也会重新换位置指向到到函数B中的栈帧中
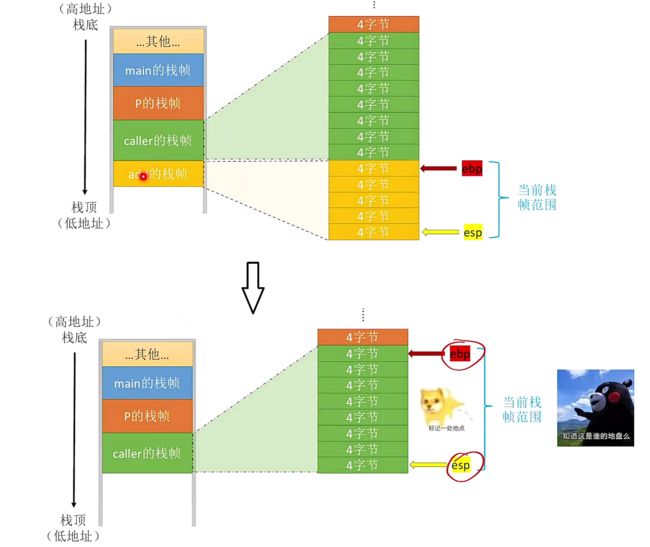
我们来进行一探究竟!
②使用enter指令来实现栈帧信息的保存
此时状态为读取call add指令结束,此时IP+1(这里实际上就是PC),接下来即将执行call命令:
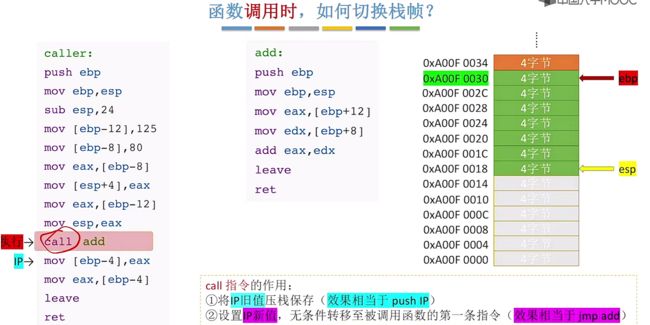
执行call命令分为两步:
1、首先第一步会将当前IP旧值(实际是目前将要执行的指令地址,这里称为旧值)压栈保存,此时会移动esp,接着将ip旧值入栈:
可以看到esp移动完后压入了IP旧值:
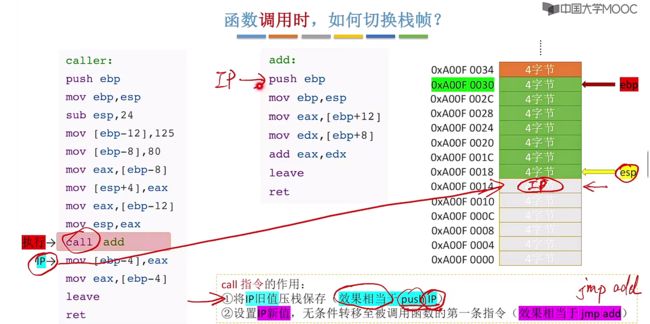
2、接着设置IP新值,也就是指向被调用函数的第一条指令(效果可以看作是jmp add)

此时IP指向到了add函数的第一条指令,接下来的两条就是用来实现保存上一个函数的栈帧信息关键命令:
- 在进入到每一个函数开头都会执行对应的两条指令用于保存上一个函数的栈帧地址也就是PC的旧值,接着修改PC的新值。
push ebp # 将ebp地址直接压入到esp中 此时esp会先进行移动,接着将ebp入栈
mov ebp esp # 改变ebp的指向,这里是将esp指向的地址移动给ebp,此时ebp就同样也指向esp所指的位置
对于上述两条指令可以使用enter来进行替代。
我们来对这两条命令进行拆解:
第一个命令:就是将原本的ebp地址进行了保存
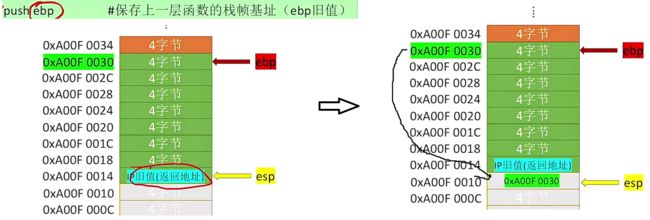
第二个命令:修改ebp的指向位置
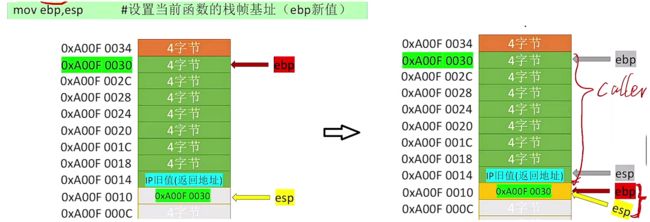
最终我们就将两个关键信息进行了保存,一个是原本ebp指向的地址,另一个是上一个函数在调用函数执行完成之后将要执行的指令代码。
在执行该add函数之后,我们的栈帧进行了扩大:
实际在每一个进入函数的第一第二条指令都会执行这两个操作,用于保存之前的被调用信息!

③使用leave指令来实现栈帧信息的回退(或称切换)
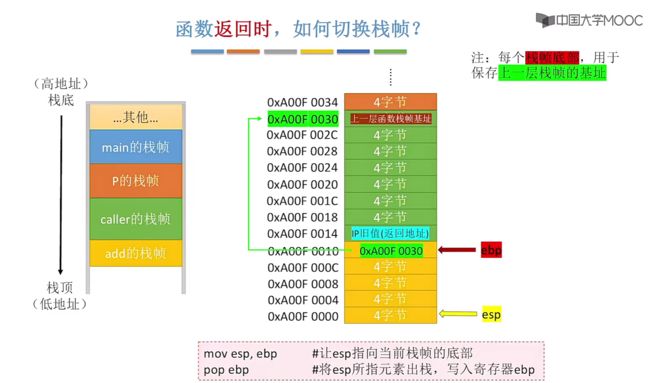
接下来我们回到add函数中,继续向下执行快进到leave指令:

实际对于leave指令就包含下面两条指令语句:
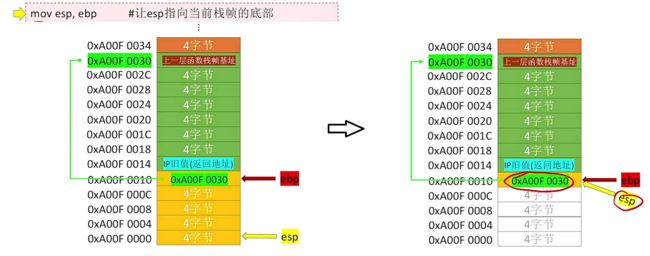
mov esb, ebp # 让esp指向当前栈帧的底部
pop ebp # 将esp所指元素出栈,写入到寄存器ebp中,这一步实际上就是对应上面enter的push,让ebp重新指向到原先保存的旧值,此时就完成了回退!
此时我们就来解析leave指令分解的这两条指令:
第一条指令:让esp指向当前栈帧的底部
第二条指令:将esp出栈,让ebp重新取指向出栈的地址值,也就是让ebp回到原先上一次函数时所指向的位置
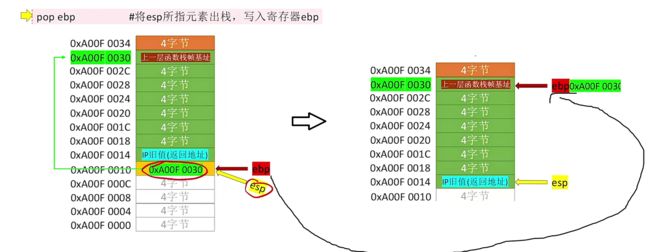
此时leave指令就执行完成了,接着还会执行ret指令,会从对应的栈帧顶部找到IP旧值,将其出栈并恢复到IP寄存器(这里实际上指的就是PC):

总结:函数调用的机器级表示
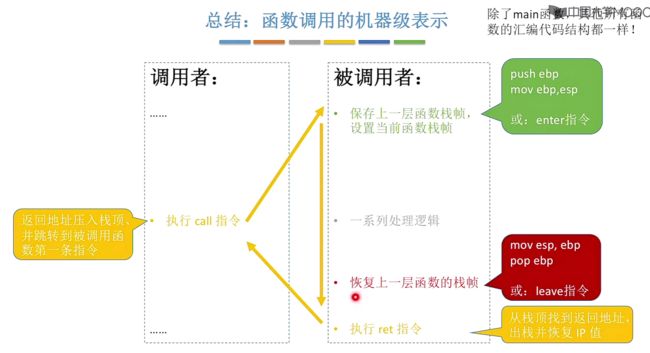
在本章节中学习了何时保存上一层函数栈帧以及恢复原始的状态指向,在函数调用执行时以及执行结束前分别执行保存以及恢复操作。
3.6.4、如何传递参数和返回值(栈帧内包含哪些内容,参数、返回值传递)
3.6.4.1、一个栈帧中可能包含的内容
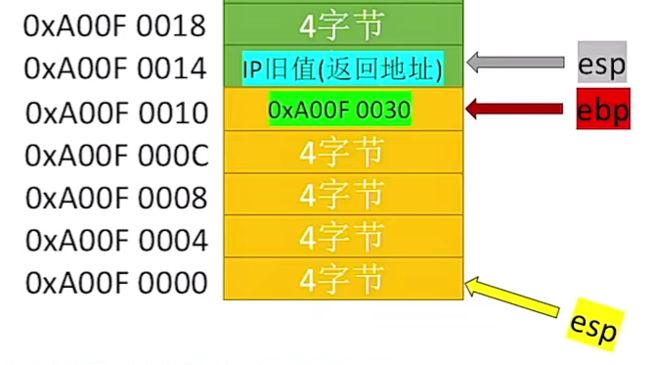
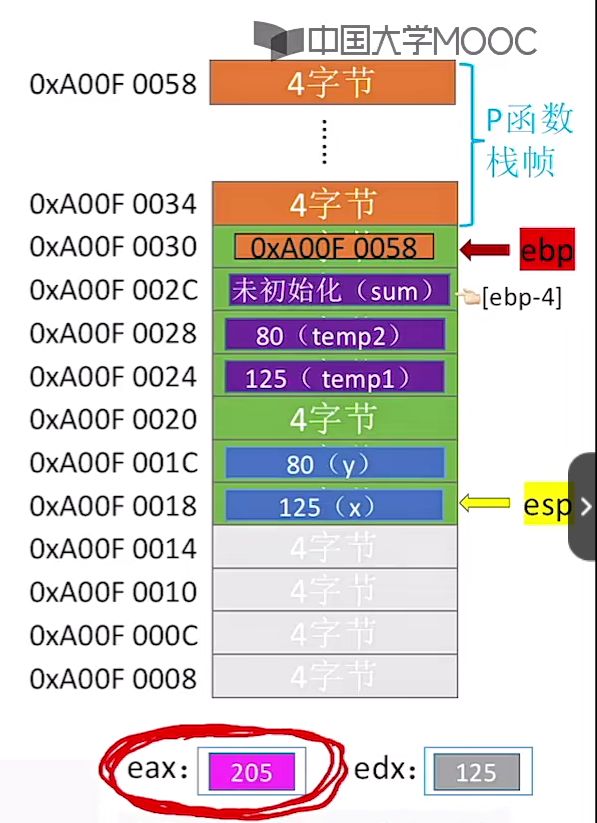
我们看下上面3.6.3章节里第③部分,当函数执行完leave以及ret回退后,当前栈帧中的状态如下:
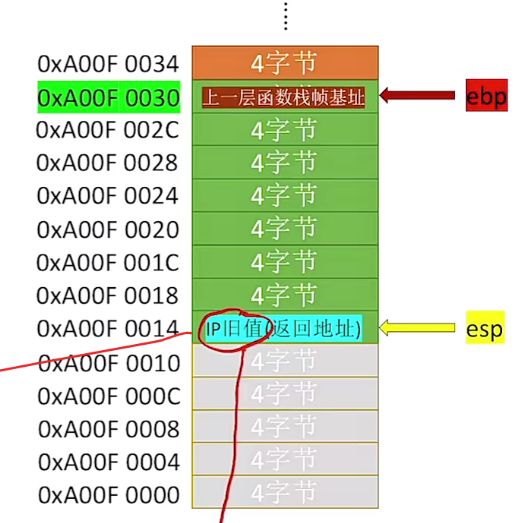
可以看到对应的ebp指着上一层函数栈帧基址,esp指着IP旧值返回地址。
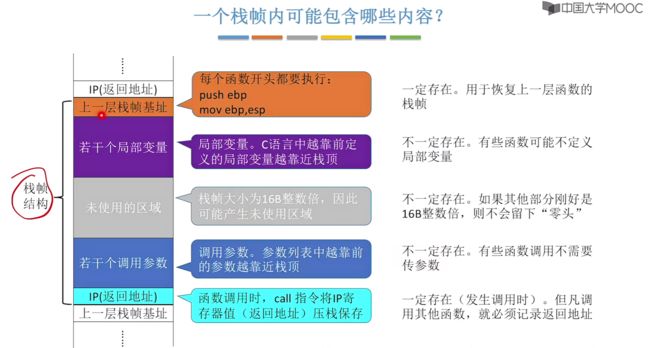
栈帧内可能包含的内容:
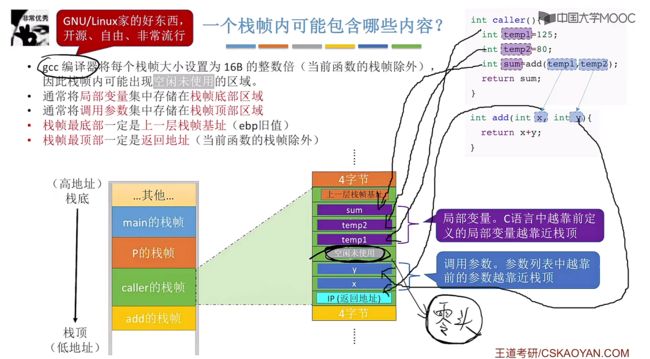
我们对比下看下c语言以及真实栈帧中的存储空间位置,可以看到调用函数传入的参数x,参数y分别在[esp+4]、[esp+8]位置,而对于在caller函数中的局部变量则依次是越靠前越靠近栈顶。
①gcc编译器会将每个栈帧大小设置为16B的整数倍(当前函数的栈帧除外)。
- 若是当前运算的函数中没有需要调用的函数,此时当前的栈帧可以是4B、8B。若是当前的栈帧中有需要调用的函数,那么此时栈帧的大小需要设置为16B的整数倍。
- 由于开源大部分的教材中的c语言都会使用gcc编译器来将其编译为汇编语言。
栈帧中可能会出现空闲未使用的区域。
②对于函数中的局部变量,C语言中越靠前定义的局部变量也就越靠近栈底(也就是上面)。
- 若是在汇编中看到了类似于[ebp-4]、[ebp-8]就基本都是访问函数中的定义的变量。
③对于调用函数传递的参数集中存储在栈帧顶部区域(也就是下面)。
④栈帧最底部一定是上一层的栈帧基址(ebp旧值)。
⑤栈帧最顶部一定是返回地址(当前函数的栈帧除外)。
详细大图如下:
3.6.4.2、汇编代码实战
接下来我们执行caller以及add函数来看在实际主存中的流程:
 caller汇编指令:
caller汇编指令:
caller:
push ebp # 保存上一个函数的栈帧基址 首先esp-4向下移动一格,接着将ebp地址值存入到esp指向位置
mov ebp,esp # 让ebp同样指向esp的位置
sub esp,24 # 移动esp栈顶指针,表示这是当前函数栈帧要使用到的空间
mov [ebp-12],125 # 将125存储在[ebp-12]也就是ebp距离三个区间位置 => int temp1 = 125
mov [ebp-8],80 # 将80存储在[ebp-8]也就是ebp距离二个区间位置 => int temp2 = 80
mov eax, [ebp-8]
mov [esp+4], eax # 上面两条指令实际上就是在传递函数参数x,放置在靠近栈顶的前一个位置
mov eax,[ebp-12]
mov esp, eax # 上面两条指令实际上就是在传递函数参数y,放置在靠近栈顶位置
call add # 调用add函数
mov [ebp-4], eax # 将eax寄存器中的值保存到[ebx-4]位置中,用来存放sum值,对应eax寄存器中的值是add函数的返回值
mov eax, [ebp-4] # 由于我们返回的是sum,所以这里需要将sum的值([ebp-4])放置到eax寄存器中(表示该函数返回的值)
leave
ret
针对上面的caller代码里对于一个主存中的值复制到另一个主存中的位置,不能够直接使用:mov [esp + 4], [ebp - 8],主要是x86作这样的限制防止速度过慢,两个主存,所以采用如下汇编命令:
-
mov eax, [ebp-8] # 先从主存[ebp-8]复制到寄存器 mov [esp+4], [eax] # 接着从寄存器再复制到主存[esp+4]
add汇编指令:
add:
push ebp # 保存上一个函数的栈帧基址 首先esp-4向下移动一格,接着将ebp地址值存入到esp指向位置
mov ebp,esp # 让ebp同样指向esp的位置
mov eax, [ebp+12] # 将栈底距离三个位置的值复制到寄存器eax中,本质就是x = 125
mov edx, [ebp+8] # 将栈底距离两个位置的值复制到寄存器eax中,本质就是y = 80
add eax,edx # 执行相加 x+y 最终将加到的值存回到eax寄存器中,实际就是x
leave # 回退
ret # 再返回到上一个函数的基准地址
下面是执行caller函数以及add函数的流程结果图:建议对照着相应上面的代码注释来进行理解
①执行caller函数前:

②目前pc指向call add语句,但是并没有执行该call语句:
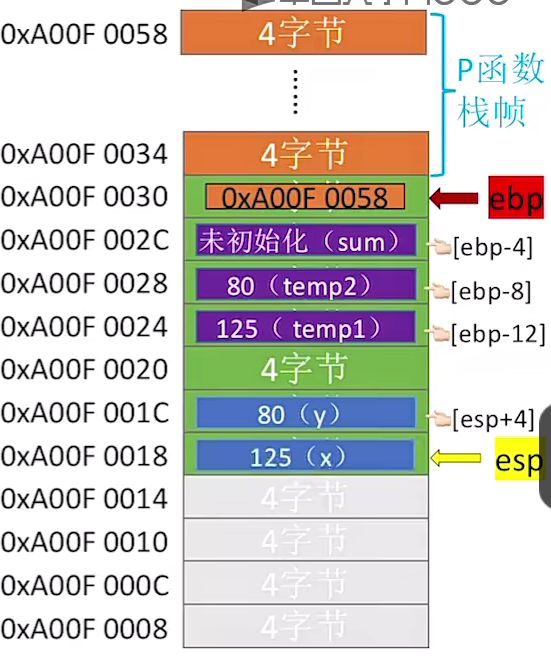
③执行call语句完成跳转,并且执行add函数的第一第二条语句之后:

④执行完add函数中的add eax,edx指令,暂未执行leave以及ret指令:
- 可以看到此时加法得到的值已经存储在eax中。
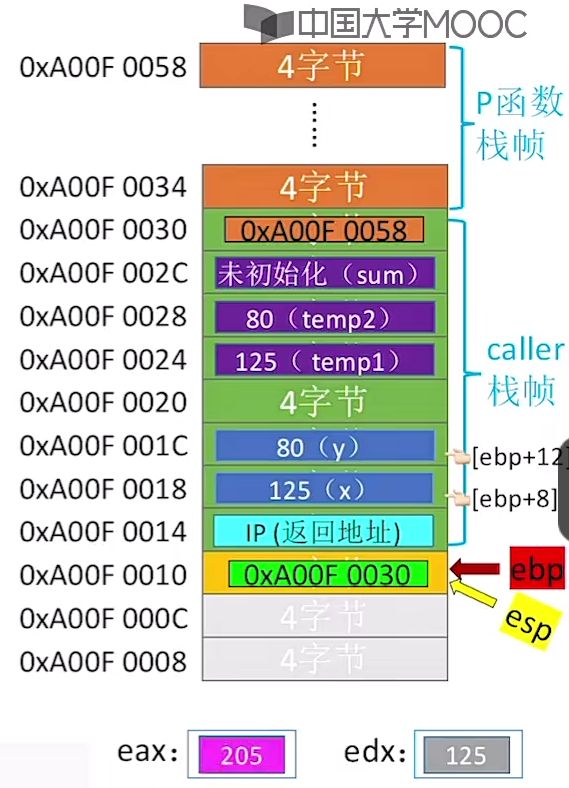
⑤执行完add函数中的leave、ret语句:
总结:函数调用的机器级表示
总结
四、CISC和RISC的基本概念
4.1、认识CISC与RISC
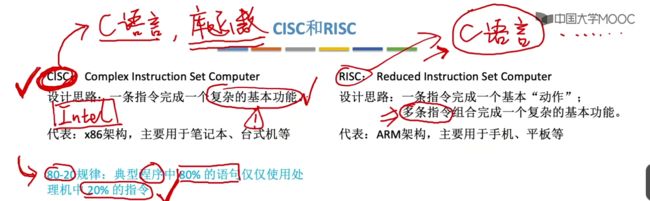
CISC与RISC是两种设计方向。
CISC:复杂指令集系统,一条指令完成一个复杂的基本功能。可类比是C语言+库函数。
代表:x86架构,用于笔记本、台式机等。
RISC:精简指令集系统,一条指令完成一个基本动作,多条指令组合完成一个复杂的基本功能。可类比C语言中只有基本的循环、判断语句。
代表:ARM架构,主要用于手机、平板等。
4.2、CISC与RISC的设计思路
有一些复杂指令用纯硬件实现十分困难,采用"存储程序"的设计思想,由一个比较通用的电路配合存储部件完成一条指令。
CISC的设计思路

RISC的设计思路

4.3、CISC与RISC的特性差异
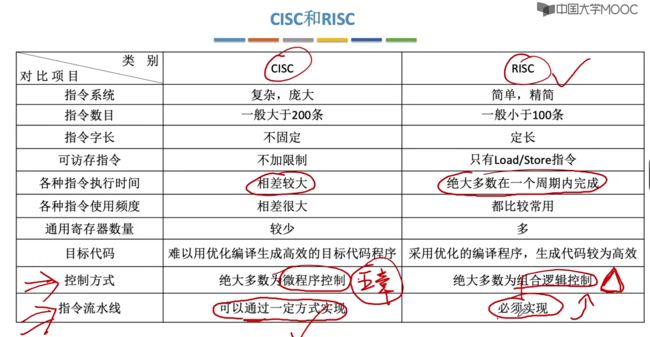
可访存指令:对于之前的乘法语句实现采用的是CISC实现。
通用寄存器数量:使用RISC时每个程序基本都是需要使用Load/Store,每个操作都会使用到寄存器,所以需要准备较多的寄存器。
控制方式:CISC效率低;RISC效率高。
整理者:长路 整理时间:2023.6.16-23