机器学习评价指标
accuracy,precision,recall,F1-score
ROC曲线下面积:ROC-AUC(area under curve)
PR曲线下面积:PR-AUC
1.accuracy,precision,recall
accuracy
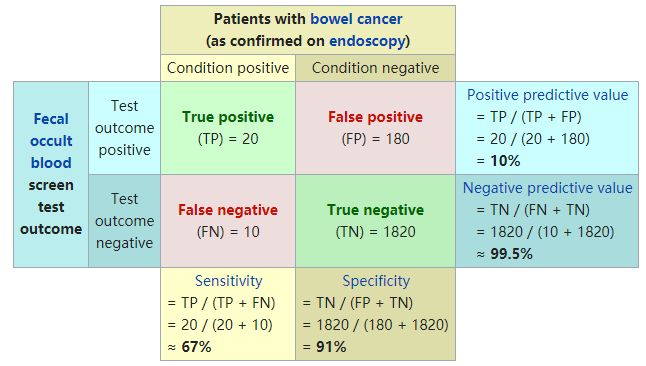
ACC:classification accuracy,描述分类器的分类准确率
ACC=(TP+TN)/(TP+FP+FN+TN)
准确率,二分类问题,98个1,2个0,预测全都是1,accuracy也是98%,但没意义。
精确率precision
“预测为正例的那些数据里预测正确的数据个数”。
precision= TP / ( TP + FP )
召回率recall
“真实为正例的那些数据里预测正确的数据个数”。
recall = TP / ( TP + FN ) = TPR (TP rate)
2.F1,F-beta
F1-score ——综合考虑precision和recall的metric
F1=2*P*R/(P+R)
F-beta
宏平均和微平均
为了综合多个类别的分类情况,评测系统整体性能,经常采用的还有微平均F1(micro-averaging)和宏平均F1(macro-averaging )两种指标。宏平均F1与微平均F1是以两种不同的平均方式求的全局的F1指标。其中宏平均F1的计算方法先对每个类别单独计算F1值,再取这些F1值的算术平均值作为全局指标。而微平均F1的计算方法是先累加计算各个类别的a、b、c、d的值,再由这些值求出F1值。由两种平均F1的计算方式不难看出,宏平均F1平等对待每一个类别,所以它的值主要受到稀有类别的影响,而微平均F1平等考虑文档集中的每一个文档,所以它的值受到常见类别的影响比较大。
3.AUC
其中TPR即为敏感度(sensitivity),TNR即为特异度(specificity)。
TPR:true positive rate,描述识别出的正例占所有正例的比例
计算公式为:TPR = TP / (TP+ FN)
TNR:true negative rate,描述识别出的负例占所有负例的比例
计算公式为:TNR = TN / (TN + FP)
TPR = recall = TP / (TP + FN)
TNR = TN / (TN + FP) = 1 - FPR
维基百科:
AUC 理解与计算
AUC 的全称是 AreaUnderRoc 即 Roc 曲线与坐标轴形成的面积,取值范围 [0, 1].
Roc (Receiver operating characteristic) 曲线是一种二元分类模型分类效果的分析工具。
Roc 空间将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。
//TPR: 在所有实际为阳性的样本中,被正确地判断为阳性之比率
TPR = TP/P = TP/(TP+FN)
//FPR: 在所有实际为阴性的样本中,被错误地判定为阳性之比率
FPR = FP/N = FP/(FP + TN)
AUC 最普遍的定义是 ROC 曲线下的面积。但其实另一种定义更常用,分别随机从正负样本集中抽取一个正样本,一个负样本,正样本的预测值大于负样本的概率。
后一个定义可以从前一个定义推导出来,有兴趣的可以看下 Wilcoxon-Mann-Witney Test。
ROC曲线 和 AUC 直白详解
https://www.jianshu.com/p/11be7ff89d8f
机器学习评估指标AUC与Precision、Recall、F1之间的关系,代码展示
https://blog.csdn.net/yftadyz/article/details/107789574
理解 ROC 和 AUC, 推导过程
http://vividfree.github.io/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/2015/11/20/understanding-ROC-and-AUC
AUC是反映ROC曲线下面的面积,面积越大,模型质量越好。而这个面积是由ROC曲线决定的。而组成ROC曲线的每一个点,是由TPR和FPR来决定。
AUC和F1的区别是什么?
- AUC关注的是混淆矩阵里左右两边的关系,即放到正类答卷里的数据多,还是放到负类卷子里的数据多.
- 而F1关注的是正类被误判的多还是漏判的多.
AUC里为什么正类答卷和负类答卷的数据是变化的呢?
因为AUC是在并不假设阈值是固定的前提下判断模型质量。这里的阈值是指,模型判断一行数据是正类还是负类时,是概率大于50%判断为正类?还是大于60%判断为正类?在这个阈值不固定的情况下,AUC仍可以判断模型质量,并且可以使用KS(Kolmogorov-Smirnov)来帮助查找最优阈值:KS=max(TPR-FPR)。
可以说ROC曲线是由多个阈值形成的多个混淆矩阵的结果组合成的。而F1是指在阈值已经固定的前提下,判断模型质量。因而AUC更公正和合理一些。
至于最终正确的阈值是什么,要考虑用户更关注TPR还是FPR,才能取舍。
还有一点,样本确定后,TPR、FPR分母就固定下来了,所以会随TP、FP增长单调递增。但Precision的变化情况会随着阈值调整而变化,且不可预测,或者说不稳定,而AUC会稳定很多。
总结一下,正确的做法是用AUC评价模型能力,选取好的模型之后根据实际需求确定阈值,再用Macro F1计算性能指标。
在很好的记忆训练数据中的正样本的基础下:
auc希望训练一个尽量不误报的模型,也就是知识外推的时候倾向保守估计,而f1希望训练一个不放过任何可能的模型,即知识外推的时候倾向激进,这就是这两个指标的核心区别。
所以在实际中,选择这两个指标中的哪一个,取决于一个trade-off。如果我们犯检验误报错误的成本很高,那么我们选择auc是更合适的指标。如果我们犯有漏网之鱼错误的成本很高,那么我们倾向于选择f1score。
放到实际中,对于检测传染病,相比于放过一个可能的感染者,我们愿意多隔离几个疑似病人,所以优选选择F1score作为评价指标。而对于推荐这种场景,由于现在公司的视频或者新闻库的物料总量是很大的,潜在的用户感兴趣的item有很多,所以我们更担心的是给用户推荐了他不喜欢的视频,导致用户体验下降,而不是担心漏掉用户可能感兴趣的视频。所以推荐场景下选择auc是更合适的。
https://blog.csdn.net/Jerry_Lu_ruc/article/details/107912462
python sklearn计算准确率、精确率、召回率、F1 score
https://blog.csdn.net/hfutdog/article/details/88085878
混淆矩阵
准确率
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
print(accuracy_score(y_true, y_pred)) # 0.5
print(accuracy_score(y_true, y_pred, normalize=False)) # 2
# 在具有二元标签指示符的多标签分类案例中
print(accuracy_score(np.array([[0, 1], [1, 1]]), np.ones((2, 2)))) # 0.5
准确度分类得分
在多标签分类中,此函数计算子集精度:为样本预测的标签集必须完全匹配y_true(实际标签)中相应的标签集。
参数
y_true : 一维数组,或标签指示符 / 稀疏矩阵,实际(正确的)标签.
y_pred : 一维数组,或标签指示符 / 稀疏矩阵,分类器返回的预测标签.
normalize : 布尔值, 可选的(默认为True). 如果为False,返回分类正确的样本数量,否则,返回正 确分类的得分.
sample_weight : 形状为[样本数量]的数组,可选. 样本权重.
返回值
score : 浮点型
如果normalize为True,返回正确分类的得分(浮点型),否则返回分类正确的样本数量(整型).
当normalize为True时,最好的表现是score为1,当normalize为False时,最好的表现是score未样本数量.
精确率
精确率指模型预测为正的样本中实际也为正的样本占被预测为正的样本的比例。
from sklearn.metrics import precision_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
print(precision_score(y_true, y_pred, average='macro')) # 0.2222222222222222
print(precision_score(y_true, y_pred, average='micro')) # 0.3333333333333333
print(precision_score(y_true, y_pred, average='weighted')) # 0.2222222222222222
print(precision_score(y_true, y_pred, average=None)) # [0.66666667 0.
召回率
from sklearn.metrics import recall_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
print(recall_score(y_true, y_pred, average='macro')) # 0.3333333333333333
print(recall_score(y_true, y_pred, average='micro')) # 0.3333333333333333
print(recall_score(y_true, y_pred, average='weighted')) # 0.3333333333333333
print(recall_score(y_true, y_pred, average=None)) # [1. 0. 0.]
F1 score
F1 score是精确率和召回率的调和平均值,计算公式为:
from sklearn.metrics import f1_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
print(f1_score(y_true, y_pred, average='macro')) # 0.26666666666666666
print(f1_score(y_true, y_pred, average='micro')) # 0.3333333333333333
print(f1_score(y_true, y_pred, average='weighted')) # 0.26666666666666666
print(f1_score(y_true, y_pred, average=None)) # [0.8 0. 0. ]