【计算机视觉】在计算机视觉里,传统卷积已经彻底输给Transformer了吗?
文章目录
- 一、传统卷积 & Transformer
-
- 1.1 传统卷积
- 1.2 Transformer
- 二、知乎高赞回答
-
- 2.1 作者:知乎用户
- 2.2 作者:王云鹤
- 2.3 作者:知乎用户
一、传统卷积 & Transformer
1.1 传统卷积
传统卷积(Traditional Convolution)是指在数字信号处理和图像处理领域中常用的一种运算方法,用于从输入信号中提取特征或进行滤波操作。它是卷积神经网络(Convolutional Neural Networks,CNN)中的核心操作之一。
传统卷积基于滑动窗口的思想,通过将一个小的窗口(通常称为卷积核或滤波器)在输入信号上进行滑动,并将窗口中的元素与输入信号对应位置的元素相乘,然后将结果求和得到输出。这个过程可以看作是一种特征提取的操作,通过滤波器与输入信号的卷积运算,可以突出输入信号中的某些特征,例如边缘、纹理等。
在图像处理中,传统卷积通常采用二维卷积操作,即在图像的每个位置上,将卷积核与图像中对应位置的像素进行逐元素相乘,并将结果相加得到输出图像的对应位置的像素值。这种操作可以应用于图像平滑、边缘检测、特征提取等任务。
传统卷积的一个限制是需要手动设计卷积核的参数,这对于复杂的任务来说可能并不容易。而在卷积神经网络中,卷积核的参数是通过反向传播算法自动学习得到的,这使得网络可以更好地适应不同的任务和数据。
传统卷积在计算效率上也存在一些挑战,特别是对于大规模图像和复杂卷积核的情况。为了提高计算效率,研究人员提出了一些优化方法,例如快速卷积算法(如快速傅里叶变换、快速卷积网络)和基于硬件的加速器(如图形处理器、专用的卷积芯片)等。
传统卷积(Traditional Convolution)是指在数字信号处理和图像处理领域中常用的一种运算方法,用于从输入信号中提取特征或进行滤波操作。它是卷积神经网络(Convolutional Neural Networks,CNN)中的核心操作之一。
传统卷积基于滑动窗口的思想,通过将一个小的窗口(通常称为卷积核或滤波器)在输入信号上进行滑动,并将窗口中的元素与输入信号对应位置的元素相乘,然后将结果求和得到输出。这个过程可以看作是一种特征提取的操作,通过滤波器与输入信号的卷积运算,可以突出输入信号中的某些特征,例如边缘、纹理等。
在图像处理中,传统卷积通常采用二维卷积操作,即在图像的每个位置上,将卷积核与图像中对应位置的像素进行逐元素相乘,并将结果相加得到输出图像的对应位置的像素值。这种操作可以应用于图像平滑、边缘检测、特征提取等任务。
传统卷积的一个限制是需要手动设计卷积核的参数,这对于复杂的任务来说可能并不容易。而在卷积神经网络中,卷积核的参数是通过反向传播算法自动学习得到的,这使得网络可以更好地适应不同的任务和数据。
传统卷积在计算效率上也存在一些挑战,特别是对于大规模图像和复杂卷积核的情况。为了提高计算效率,研究人员提出了一些优化方法,例如快速卷积算法(如快速傅里叶变换、快速卷积网络)和基于硬件的加速器(如图形处理器、专用的卷积芯片)等。
1.2 Transformer
Transformer是一种用于自然语言处理(Natural Language Processing,NLP)和其他序列到序列(sequence-to-sequence)任务的神经网络架构。它于2017年由Vaswani等人在论文"Attention Is All You Need"中提出,并在机器翻译任务中取得了显著的成果。
相较于传统的循环神经网络(Recurrent Neural Networks,RNNs),Transformer采用了全新的结构,主要由两个关键组件构成:自注意力机制(Self-Attention)和前馈神经网络(Feed-Forward Neural Network)。
自注意力机制是Transformer的核心部分。它允许模型在处理序列时直接关注输入序列中的其他位置,并在计算注意力权重时考虑到序列中所有位置的信息。这种机制使得模型能够有效地捕捉输入序列中的长距离依赖关系,从而更好地理解上下文。
前馈神经网络是自注意力机制之后的一层全连接前馈网络。它通过多层感知机(Multi-Layer Perceptron,MLP)对自注意力机制的输出进行非线性变换,增加模型的表达能力。
Transformer还使用了层归一化(Layer Normalization)和残差连接(Residual Connections)等技术来加速训练和提高模型的性能。此外,为了实现序列到序列任务(如机器翻译),Transformer还引入了编码器-解码器结构,其中编码器用于处理输入序列,解码器用于生成输出序列。
相较于传统的循环神经网络,Transformer具有以下几个优势:
- 并行计算:Transformer可以同时处理整个输入序列,因此可以并行计算,加快了训练和推理的速度。
- 并行计算:Transformer可以同时处理整个输入序列,因此可以并行计算,加快了训练和推理的速度。
- 编码器-解码器结构:Transformer的编码器-解码器结构适用于序列到序列任务,如机器翻译。它通过将输入序列编码成固定长度的向量表示,并使用解码器逐步生成输出序列。
编码器-解码器结构:Transformer的编码器-解码器结构适用于序列到序列任务,如机器翻译。它通过将输入序列编码成固定长度的向量表示,并使用解码器逐步生成输出序列。
二、知乎高赞回答
2.1 作者:知乎用户
https://www.zhihu.com/question/531529633/answer/2473781572
是,输得很惨,我现在一看到面试者对Transformer一脸热情过度的样子都有点PTSD了
前面波尔德已经讲得很好了,Transformer冲击SOTA有用,但工业界不可能去用SOTA。既然是工业界,做什么都得考虑个成本,Transformer一上,就意味着推理时间,训练时间,调试时间成倍的增加。
推理时间翻倍,意味着硬件成本翻倍,也意味着同样的硬件能同时跑的模型变少。大部分硬件不支持意味着高效率硬件用不上,只能使用少数厂商的硬件,这就意味着硬件被人卡脖子。功耗成本增加也是问题。
训练时间翻倍,意味着迭代次数减少,迭代次数减少意味着你开发进度慢,意味着被市场淘汰。要跟上步子也可以,那么训练集群和电费都是成倍增加。
Transfomer难训练,意味着调试时间成倍增加,以前随便调调就有,现在得反复调试。训练时间使用的是GPU时间,还能忍,调试时间是是什么?员工的时间。IT企业最大的成本支出是什么?人力成本。
最后,你一个好好的企业,用上了Transformer,导致推理硬件成本翻倍,能耗翻倍,训练集群成本翻倍,耗电翻倍,迭代时间翻倍,员工成本翻倍,然后被市场淘汰。所有这一切的付出,居然只是为了涨那几个点。。。
如果你把Transformer用在刀刃上,比如波尔德说的处理高阶特征,那还行。比如特斯拉用Transformer搞tracking就是不错的思路。
2.2 作者:王云鹤
https://www.zhihu.com/question/531529633/answer/3047230939
一年多以前我也以为输了,但其实还有机会。我们6层的VanillaNet可以超过ResNet-34,13层的VanillaNet在ImageNet达到83%的top1精度,超过几百层网络的性能,并展现了非凡的硬件效率优势。顺道一提,VanillaNet的中文名字为朴素网络。
王云鹤:卷积的尽头不是Transformer,极简架构潜力无限:
https://zhuanlan.zhihu.com/p/632685158
在过去几年时间,一直都在找关于神经网络架构创新的灵感。在视觉Backbone这个方向上,端侧我们有了GhostNet这种轻量的模型架构和系列算法。但是面对现在大算力,还没有什么特别好的思路,虽然在Vision Transformer的路上跟着大家也一起做了一点工作,但一直想利用最简单的卷积网络,尝试做出更强的效率和性能,在实际应用中也可以有更大的价值。
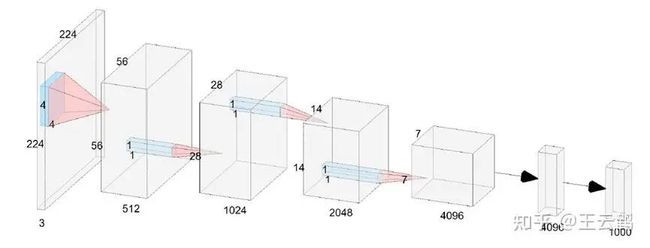
6层的VanillaNet结构图,没有Shortcut,致敬LeNet、AlexNet和VGGNet这个工作的核心就是,如何让一个浅层网络在没有复杂链接和attention的情况下,尽可能地提升精度,实际上我们面临的非线性大幅下降的技术难题。现代深度神经网络强大的拟合能力,甚至在不考虑复杂度的情况下具有逼近任意函数的潜力,很大一部分是复杂的非线性层不断堆叠带来的。
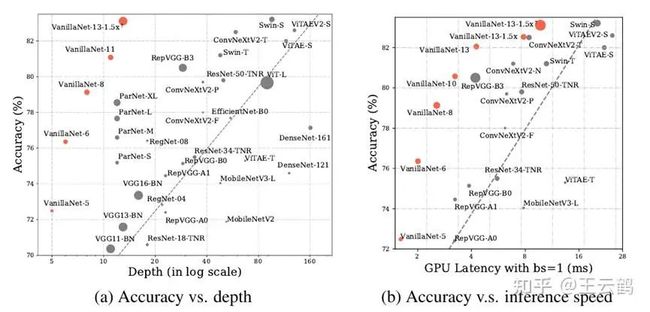
VanillaNet与SOTA架构在深度、精度、速度上的对比VanillaNet是我们的一个开端,让我们重新思考了很多,到底什么对深度神经网络性能提升是最重要的,是深度,是感受野,是attention,还是参数量?目前这个版本的VanillaNet我们优化了接近一年,已经在很多实际业务中都用了起来。但它也还有很多提升空间,比如没有加任何的预训练和蒸馏,也没有进一步系统性尝试与其它网络架构的融合,还没有更进一步进行结构的优化。AI的浪潮一波三折,距离AlexNet提出已经有11年过去了,而今迈步从头越,期待未来的新架构和新应用。
2.3 作者:知乎用户
https://www.zhihu.com/question/531529633/answer/2473798585
首先明确反对斗兽。反对“a完爆b”式引战。
CNN相比ViT至少有下列优点:
- CNN在数据较少时效果更好,收敛也更快。本质是因为cnn包含的inductive bias于图像数据的性质吻合,而ViT只能靠海量数据学习这些性质。现实业务中数据很可能没那么多,ViT吃不饱不好好干活。而且训练ViT动不动就300、500甚至1000个epoch真的遭不住。用CNN可能100个epoch就完事了。
- CNN容易训练。只要用上residual和BN这两个技术,CNN的效果基本就不会差到哪里去。训练ViT你需要各种正则化和trick。比如gradient clip,weight decay,random depth,large batch,warm up,各种数据增强……超参数过多意味着换个数据集就重新来过,慢慢调去吧。我听过很多人抱怨ViT迁移到自己的数据上效果不好,我怀疑多半是没调出来。
- CNN跑得快。卷积已经经历过多年优化,比自注意力的运算效率高。relu也比gelu快的多。
- CNN的开销与像素点的数目是线性关系。而ViT是平方关系。这意味着ViT难以处理高分辨率图像。
- CNN天然可以处理任意分辨率的图像。而ViT由于位置编码的限制,一般需要固定分辨率。
- CNN对硬件更友好。naive的卷积只需要im2col,matmul和reshape。BN和relu还可以融合进卷积核。硬件实现比自注意力简单。
- 因为运算简单,CNN的int8量化也容易做。想要量化ViT,首先必须搞一个int8的softmax…….怎么看都不是个容易的事情。目前的推理芯片绝大部分只能跑CNN。
最后是一些胡言乱语。
卷积和自注意力不是水火不容的。小孩子才斗兽。大人选择我全都要。例如Swin,吸收了CNN的局部性和层级结构,效果就比原版ViT好很多。反过来ConvNeXT从ViT里获得了灵感,给CNN来了一波文艺复兴。LeCun说过,他理想中的网络应该是用卷积抓底层的特征,transformer处理高阶的信息。类似于DETR那样。ViT这个领域现在还是大水漫灌,而我乐观地相信真正的好东西还在后面。
另外一个问题是,CNN到底还有多少潜力可挖。缝合了大量trick之后,老不死的(褒义)ResNet50也能在ImageNet上达到80%以上的准确度。说不定哪天又蹦出来个新技术,给全体CNN再补补身子(就像曾经的BN)。