python基础学习7【聚合apply()、透视表pivot_table()、concat()、主键合并merge()、join()、combine_first()】
使用apply方法聚合数据
apply()方法类似agg方法能够将函数应用于每一列。


使用transform方法聚合数据
transform方法能够对整个dataframe的所有元素进行操作。且transform方法只有一个参数func,表示对dataframe操作的函数;
同时transform方法还能够对dataframe分组后的对象groupby进行操作,可以实现组内离差标准化等操作。

创建透视表与交叉表
pivot_table函数:
可以更改margins参数,查看汇总数据;
当某些数据不存在时,会自动填充NaN,因此可以指定fill_value参数。
实操:


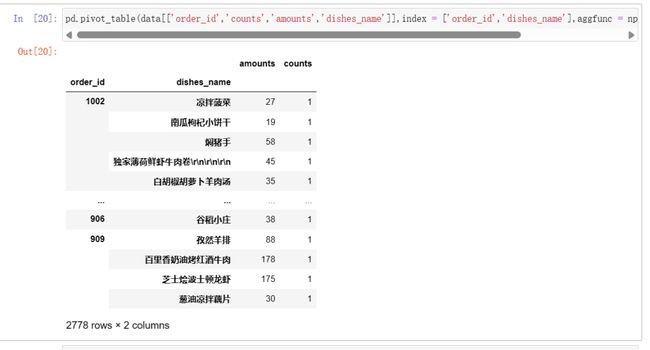
指定行和列绘制透视表情况:

margins=True:

汇总求和:aggfun=np.sum

这一期的错误请看上一期的解答2,不是很想改正了。(水一波)
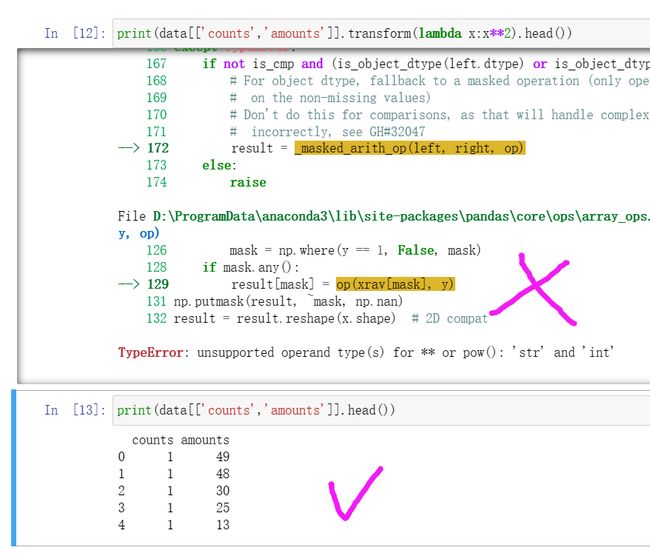
改完了就能看到正常的数据。
使用pandas进行数据预处理【合并数据、清洗数据、标准化数据、转换数据】
合并数据【横向、纵向】
横向表堆叠
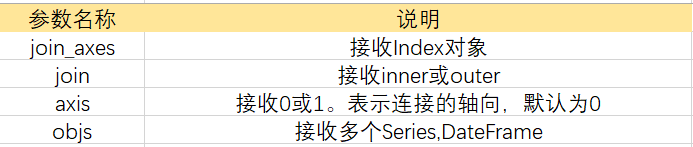
当axis=1时,concat做行对齐,然后将不同列名称的两张或多张表合并。当两个表索引不完全一样时,可以使用join参数选择是内连接还是外连接。在内连接的情况下,仅仅返回索引重叠部分。在外连接的情况下,则显示索引的并集部分数据,不足的地方则使用空值填补。
当两张表完全一样时,不论join参数取值。
实操:
import pandas as pdfrom sqlalchemy import create_engineengin = create_engine('mysql+pymysql://root:123456root@58.0.20.242:3306/test?charset=utf8')#这一句最好记到,写不对就会报错))

pd.read_sql('meal_order_detail1',con=engin)
![]()
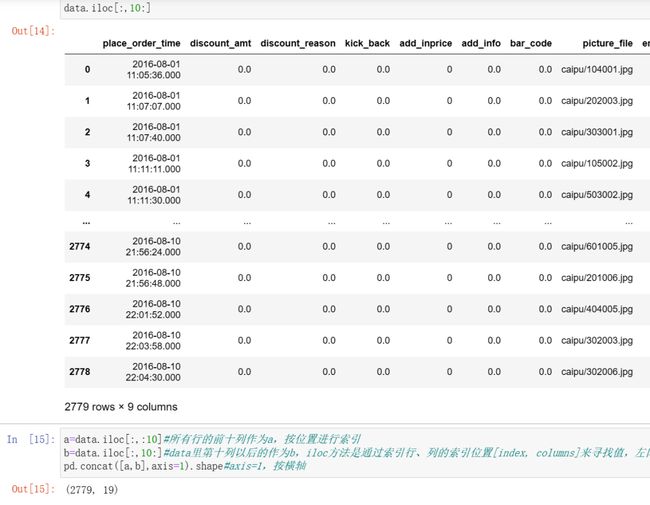
a=data.iloc[:,:10]#所有行的前十列作为a,按位置进行索引b=data.iloc[:,10:]#data里第十列以后的作为b,iloc方法是通过索引行、列的索引位置[index, columns]来寻找值,左闭右开pd.concat([a,b],axis=1,join='inner').shape#axis=1,按横轴;INNER JOIN(此处join的连接方式不影响,只是介绍一下):内连接,也可以只写JOIN。只有进行连接的两个表中,都存在与连接标准相匹配的数据才会被保留下来,相当于两个表的交集。如果前后连接同一张表,也叫自连接。
纵向堆叠----concat函数
使用concat函数时,在默认情况下,即axis=0时,concat做列对齐,将不同行索引的两张或多张表纵向合并。
实操:
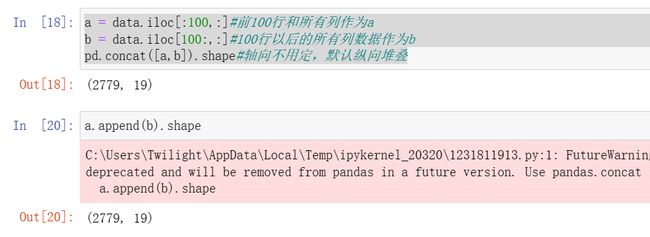
a = data.iloc[:100,:]#前100行和所有列作为ab = data.iloc[100:,:]#100行以后的所有列数据作为bpd.concat([a,b]).shape#轴向不用定,默认纵向堆叠
主键合并【merge、join】
通过一个或多个键将两个数据集的行连接起来,类似于sql中的join。
merge()函数:
和数据库的join一样,merge函数也有左连接、右连接、内连接和外连接,除此之外,在合并过程中可以对数据集进行排序。
可根据merge函数中的参数说明,并按照需求修改相关参数,就可以多种方法实现主键合并。
order = pd.read_csv('./609/meal_order_info.csv',encoding='gbk')order.head()

合并:

pd.merge(order,data,left_on = 'info_id',right_on='order_id')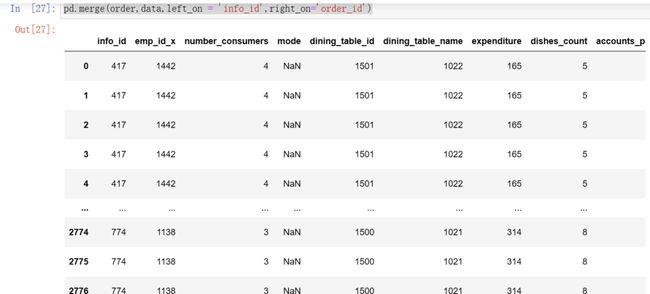
join()
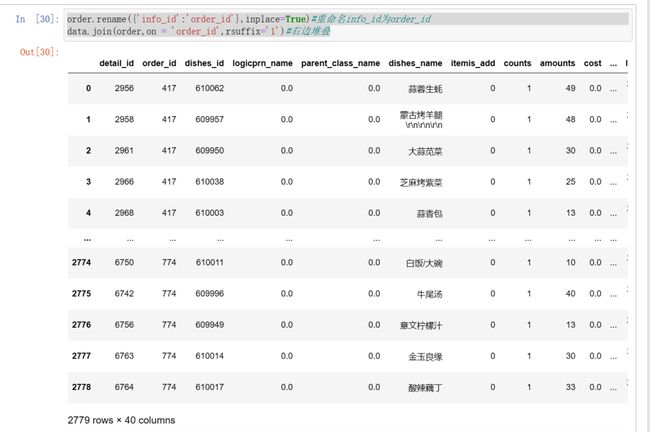
order.rename({'info_id':'order_id'},inplace=True)#重命名info_id为order_iddata.join(order,on = 'order_id',rsuffix='1')#右边堆叠
combine_first方法
数据分析和处理过程中若出现两份数据的内容几乎一致的情况,但是某些特征在其中一张表上是完整的,而在另外一张表上的数据则是缺失的时候,可以用combine_first进行重叠合并。
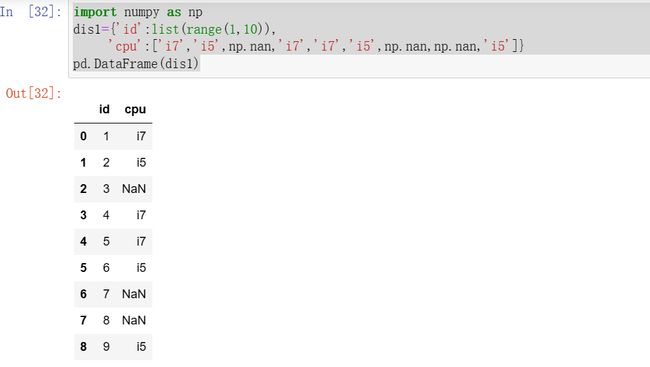
import numpy as npdis1={'id':list(range(1,10)),'cpu':['i7','i5',np.nan,'i7','i7','i5',np.nan,np.nan,'i5']}pd.DataFrame(dis1)
a=pd.DataFrame(dis1)dis2={'id':list(range(1,10)),'cpu':['i7','i5','i5',np.nan,'i7','i5','i5',np.nan,'i5']}pd.DataFrame(dis2)
a.combine_first(b)