Beautifulsoup 库 -- 01 -- 安装及使用
文章目录
- 1. 安装
- 2. 快速使用
- 3. 对象的种类
-
- 3.1 Tag
-
- 3.1.1 Name 属性
- 3.1.2 Attributes
- 3.1.3 多值属性
- 3.2 可以遍历的字符串 NavigableString
- 3.3 BeautifulSoup
- 3.4 注释及特殊字符串 Comment
Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库.
1. 安装
- 安装 Beautiful Soup
- pip 安装:
pip install beautifulsoup4
- pip 安装:
- 安装解析器:
lxml 解析器:pip install lxmlhtml5lib 解析器:pip install html5lib
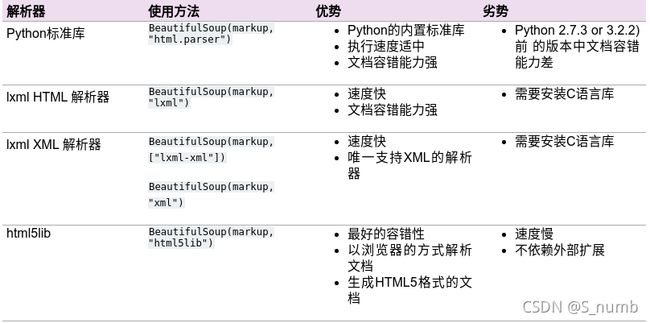
- 解析器的优缺点:
2. 快速使用
- 将一段文档传入BeautifulSoup 的构造方法,就能得到一个文档的对象, 可以传入一段字符串或一个文件句柄.
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("index.html"))
soup = BeautifulSoup("data")
-
首先,文档被转换成 Unicode,并且 HTML 的实例都被转换成 Unicode 编码;
-
然后,Beautiful Soup 选择最合适的解析器来解析这段文档,如果手动指定解析器那么 Beautiful Soup 会选择指定的解析器来解析文档;
-
栗子:
from bs4 import BeautifulSoup
soup = BeautifulSoup("data")
print(soup.prettify()) # 标准的缩进格式的结构输出
- 结果:
<html>
<body>
<p>
data
</p>
</body>
</html>
3. 对象的种类
- Beautiful Soup 将复杂 HTML 文档转换成一个复杂的树形结构,每个节点都是 Python 对象,所有对象可以归纳为 4 种:
- Tag ;
- NavigableString ;
- BeautifulSoup ;
- Comment;
3.1 Tag
生成的 Beautifulsoup 对象,转换为 tag 对象,后边的
.是根据标签来确定的,如果是 b 就是.b,是 p 就是.p;
Tag对象与 XML 或 HTML 原生文档中的 Tag 相同:- 栗子:
from bs4 import BeautifulSoup
soup = BeautifulSoup('Extremely bold')
tag = soup.b
print(type(tag))
--- 输出 ---
<class 'bs4.element.Tag'>
3.1.1 Name 属性
- 每个 tag 都有自己的名字,通过
.name来获取:
from bs4 import BeautifulSoup
soup = BeautifulSoup('Extremely bold')
tag = soup.b
print(tag.name)
输出
b
- 如果改变了 tag 的 name,那将影响所有通过当前 Beautiful Soup 对象生成的 HTML 文档:
from bs4 import BeautifulSoup
soup = BeautifulSoup('Extremely bold')
tag = soup.b
tag.name = "blockquote"
print(tag)
结果:
<blockquote class="boldest">Extremely bold</blockquote>
3.1.2 Attributes
- 一个 tag 可能有很多个属性;
tag有一个 “class” 的属性,值为 “boldest”;- tag 的属性的操作方法与字典相同:
tag['class'] - 也可以直接”点”取属性, 比如:
.attrs - tag的属性可以被添加,删除或修改。
- 栗子:
from bs4 import BeautifulSoup
soup = BeautifulSoup('Extremely bold')
tag = soup.b
tag.name = "blockquote"
print(tag.attrs) # 访问 tag 的属性
print(tag)
tag['class'] = 'verybold' # 修改属性
tag['id'] = 123 # 添加属性
print(tag)
del tag['class'] # 删除属性
print(tag)
- 结果:
{'class': ['boldest']}
<blockquote class="boldest">Extremely bold</blockquote>
<blockquote class="verybold" id="123">Extremely bold</blockquote>
<blockquote id="123">Extremely bold</blockquote>
3.1.3 多值属性
- HTML 4 定义了一系列可以包含多个值的属性;
- 在 HTML5 中移除了一些,却增加更多;
- 最常见的多值的属性是 class (一个 tag 可以有多个 CSS 的 class);
- 还有一些属性 rel , rev , accept-charset , headers , accesskey ;
- 在 Beautiful Soup 中多值属性的返回类型是
list;
from bs4 import BeautifulSoup
css_soup = BeautifulSoup('')
tag = css_soup.p
print(tag['class'])
- 输出:
['body', 'strikeout']
- 如果某个属性看起来好像有多个值,但在任何版本的 HTML 定义中都没有被定义为多值属性,那么Beautiful Soup 会将这个属性作为字符串返回:
- 栗子:(id 在 html 中并未被定义为多值属性)
from bs4 import BeautifulSoup
css_soup = BeautifulSoup('')
tag = css_soup.p
print(tag['id'])
输出:
body strikeout
- 将 tag 转换成字符串时,多值属性会合并为一个值:
- 栗子:
from bs4 import BeautifulSoup
css_soup = BeautifulSoup('')
tag = css_soup.p
print(tag['rel'])
tag['rel'] = ['body', 'strikeout']
print(tag['rel'])
print(tag)
输出:
body
['body', 'strikeout']
<p rel="body strikeout"></p>
- 如果转换的文档是 XML 格式,那么 tag 中不包含多值属性:
from bs4 import BeautifulSoup
css_soup = BeautifulSoup('', 'xml')
tag = css_soup.p
print(tag['rel'])
- 输出:
body strikeout
3.2 可以遍历的字符串 NavigableString
- 字符串常被包含在 tag 内;
- Beautiful Soup 用
NavigableString 类来包装 tag 中的字符串;
from bs4 import BeautifulSoup
soup = BeautifulSoup('Extremely bold')
tag = soup.b
print(tag.string)
print(type(tag.string))
输出:
Extremely bold
<class 'bs4.element.NavigableString'>
- 一个 NavigableString 字符串与 Python 中的 Unicode 字符串相同;
- 并且还支持包含在遍历文档树和搜索文档树中的一些特性;
- 通过
unicode()方法可以直接将 NavigableString 对象转换成 Unicode 字符串; - 在 Python 3中,unicode 已重命名为 str。
- python2 栗子:
from bs4 import BeautifulSoup
soup = BeautifulSoup('Extremely bold')
tag = soup.b
print(tag.string)
print(type(tag.string))
unicode_string = unicode(tag.string)
print(unicode_string)
print(type(unicode_string))
--- 输出 ---
Extremely bold
Extremely bold
- python3 栗子:
from bs4 import BeautifulSoup
soup = BeautifulSoup('Extremely bold')
tag = soup.b
print(tag.string)
print(type(tag.string))
unicode_string = str(tag.string)
print(unicode_string)
print(type(unicode_string))
--- 输出 ---
Extremely bold
<class 'bs4.element.NavigableString'>
Extremely bold
<class 'str'>
- tag 中包含的字符串不能编辑,但是可以被替换成其它的字符串,用
replace_with()方法:
from bs4 import BeautifulSoup
soup = BeautifulSoup('Extremely bold')
tag = soup.b
print(tag)
tag.string.replace_with("change string")
print(tag)
输出:
<b class="boldest">Extremely bold</b>
<b class="boldest">change string</b>
- 如果想在 Beautiful Soup 之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的 Unicode 字符串,,否则就算 Beautiful Soup 已方法已经执行结束,该对象的输出也会带有对象的引用地址,这样会浪费内存。
3.3 BeautifulSoup
- BeautifulSoup 对象表示的是一个文档的全部内容。
- 大部分时候,可以把它当做
Tag对象,它支持遍历文档树和搜索文档树中描述的大部分方法; - 因为 BeautifulSoup 对象并不是真正的 HTML 或 XML 的 tag,所以它没有 name 和 attribute 属性;
- 但有时查看它的
.name属性是很方便的,所以 BeautifulSoup 对象包含了一个值为 “[document]” 的特殊属性.name。
from bs4 import BeautifulSoup
soup = BeautifulSoup('Extremely bold')
print(soup.name)
输出:
[document]
3.4 注释及特殊字符串 Comment
- Tag , NavigableString , BeautifulSoup 几乎覆盖了 html 和 xml 中的所有内容,但是还有一些特殊对象:
- 文档的注释部分
- 栗子:
from bs4 import BeautifulSoup
annotate = "" #内容是注释
text = "This is text"
soup_annotate = BeautifulSoup(annotate)
soup_text = BeautifulSoup(text)
comment_annotate = soup_annotate.b.string
comment_text = soup_text.b.string
print(type(comment_annotate))
print(type(comment_text))
结果:
<class 'bs4.element.Comment'>
<class 'bs4.element.NavigableString'>
- Comment 对象是一个特殊类型的 NavigableString 对象。