使用python读取autogluon模型报错
主要代码:
#!D:/workplace/python
# -*- coding: utf-8 -*-
# @File : performance_predict.py
# @Author:Romulushe
# @Time : 2023/7/5 10:39
# @Software: PyCharm
# @Use: PyCharm
#读取数据
import numpy as np
import pandas as pd
#加载模型
import joblib
model_best=joblib.load('./data/worker5_best_0705.pkl')
# 读取数据
data=pd.read_csv("./data/t2_raw_0705.csv")
del data['Unnamed: 0']
# print(data)
#预测数据
try:
p1=model_best.predict(data)
print(p1)
except Exception as e:
print(e)
报错详情:
"D:\Program Files (x86)\anaconda\envs\ag\python.exe" E:/文档/Projects/Pycharm/HR_system/0705_new_pro/v1/performance_predict.py
[Errno 2] No such file or directory: '../data/AUO-train/model/AM/worker5/worker5.pkl\\models\\ExtraTreesMSE_BAG_L1\\model.pkl'
Process finished with exit code 0
问题分析:
The error message you encountered suggests that there is a missing file or directory. Specifically, the file '../data/AUO-train/model/AM/worker5/worker5.pkl\\models\\ExtraTreesMSE_BAG_L1\\model.pkl' could not be found.
Here are a few things you can try to resolve this issue:
-
Verify the file path: Double-check if the file
'model.pkl'exists in the specified location:'../data/AUO-train/model/AM/worker5/worker5.pkl/models/ExtraTreesMSE_BAG_L1'. Make sure the file name, case sensitivity, and directory structure are correct. -
Check for typos: Ensure that the file path specified in your code is accurate and there are no typographical errors.
-
Check the file permissions: Make sure you have appropriate read permissions for the file and its parent directories.
-
Confirm the working directory: Verify that the script is being executed from the correct working directory. The relative path
'../data/AUO-train/model/AM/worker5/worker5.pkl/models/ExtraTreesMSE_BAG_L1/model.pkl'should be relative to the current working directory. -
Confirm the file availability: If you are working on a shared system or network, check if the file is accessible to you or if it has been moved or deleted.
By addressing these points, you should be able to troubleshoot the issue and resolve the “No such file or directory” error.
中文翻译
你遇到的错误信息表明缺少文件或目录。具体来说,文件'../data/AUO-train/model/AM/worker5/worker5.pkl/models/ExtraTreesMSE_BAG_L1/model.pkl'无法找到。
以下是几个可能解决这个问题的步骤:
-
验证文件路径:仔细检查指定位置
'../data/AUO-train/model/AM/worker5/worker5.pkl/models/ExtraTreesMSE_BAG_L1'中是否存在文件'model.pkl'。确保文件名、大小写和目录结构都是正确的。 -
检查拼写错误:确保代码中指定的文件路径准确无误,没有拼写错误。
-
检查文件权限:确保你对该文件及其父目录具有适当的读取权限。
-
确认工作目录:验证脚本是否从正确的工作目录执行。相对路径
'../data/AUO-train/model/AM/worker5/worker5.pkl/models/ExtraTreesMSE_BAG_L1/model.pkl'应该相对于当前工作目录。 -
确认文件的可用性:如果你是在共享系统或网络上工作,请检查文件是否对你可访问,或者是否已被移动或删除。
通过解决上述问题,你应该能够解决“找不到文件或目录”的错误。
建模过程
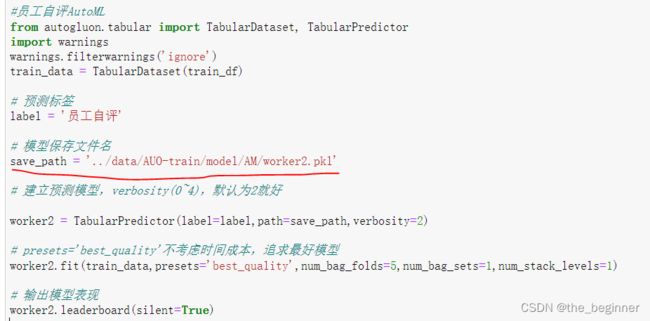
优化建模过程,重新建模
#!D:/workplace/python
# -*- coding: utf-8 -*-
# @File : train0705_new.py
# @Author:Romulushe
# @Time : 2023/7/5 11:15
# @Software: PyCharm
# @Use: PyCharm
#读取数据
import numpy as np
import pandas as pd
#准备数据
t2=pd.read_csv("./t2_raw_0705.csv")
del t2['Unnamed: 0']
# print(t2)
# 这里是直接进来一个.csv格式的表单,我这里粗略处理下,得到训练集和测试集
train_df2 = t2.sample(frac=0.8, axis=0, random_state=2022)
test_df2 = t2[~t2.index.isin(train_df2.index)]
#
# #保存数据
t2.to_csv("./raw_0705.csv")
train_df2.to_csv("./train_0705.csv")
test_df2.to_csv("./test_0705.csv")
#
# # #员工自评AutoML
import os,sys
base_path = os.path.dirname(os.path.realpath(sys.argv[0]))
# print('base_path:',base_path)
# new_path=os.path.join(base_path, 'data')
# print('new path:',new_path)
from autogluon.tabular import TabularDataset, TabularPredictor
import warnings
warnings.filterwarnings('ignore')
train_data = TabularDataset(train_df2)
# 预测标签
label = '员工自评'
# 模型保存文件名
save_path = base_path+'\worker0705.pkl'
# 建立预测模型,verbosity(0~4),默认为2就好
worker0705 = TabularPredictor(label=label,path=save_path,verbosity=2)
# presets='best_quality'不考虑时间成本,追求最好模型
worker0705.fit(train_data,presets='best_quality',num_bag_folds=5,num_bag_sets=1,num_stack_levels=1)
# 输出模型表现
worker0705.leaderboard(silent=True)
# 删除其余模型(减少内存开销)
worker0705.delete_models(models_to_keep='best')
# 输出最优模型
worker0705.get_model_best()
#保存
import sklearn.externals
import joblib
#保存模型
joblib.dump(worker0705, './worker0705_best.pkl')
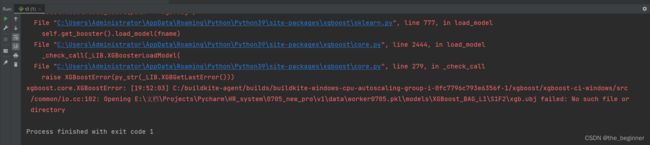
一样的报错信息
"D:\Program Files (x86)\anaconda\envs\ag\python.exe" E:/文档/Projects/Pycharm/HR_system/0705_new_pro/v1/performance_predict.py
base_path: E:\文档\Projects\Pycharm\HR_system\0705_new_pro\v1
new_path: E:\文档\Projects\Pycharm\HR_system\0705_new_pro\v1\data
model_path: E:\文档\Projects\Pycharm\HR_system\0705_new_pro\v1\data\worker0705_best.pkl
data_path: E:\文档\Projects\Pycharm\HR_system\0705_new_pro\v1\data\raw_0705.csv
[13:33:20] C:/buildkite-agent/builds/buildkite-windows-cpu-autoscaling-group-i-0fc7796c793e6356f-1/xgboost/xgboost-ci-windows/src/common/io.cc:102: Opening E:\文档\Projects\Pycharm\HR_system\0705_new_pro\v1\data\worker0705.pkl\models\XGBoost_BAG_L1\S1F5\xgb.ubj failed: No such file or directory
Process finished with exit code 0
调用代码
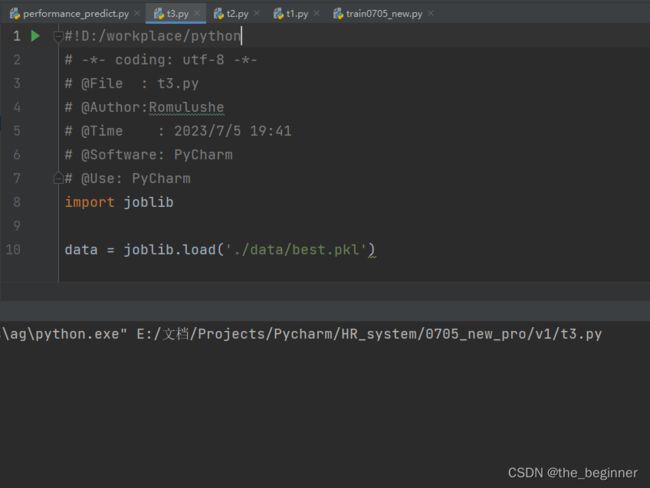
#!D:/workplace/python
# -*- coding: utf-8 -*-
# @File : performance_predict.py
# @Author:Romulushe
# @Time : 2023/7/5 10:39
# @Software: PyCharm
# @Use: PyCharm
import os,sys
base_path = os.path.dirname(os.path.realpath(sys.argv[0]))
print("base_path:",base_path)
new_path=os.path.join(base_path, 'data')
print("new_path:",new_path)
#读取数据
import numpy as np
import pandas as pd
#加载模型
import joblib
# model_best=joblib.load('./data/worker0705_best.pkl')
model_path=new_path+'\\worker0705_best.pkl'
print('model_path:',model_path)
model_best=joblib.load(model_path)
# 读取数据
data_path=new_path+"\\raw_0705.csv"
print('data_path:',data_path)
data=pd.read_csv(data_path)
del data['Unnamed: 0']
# print(data)
#预测数据
try:
p1=model_best.predict(data)
print(p1)
except Exception as e:
print(e)
问题分析
如果你已经确认了文件确实存在,但仍然遇到该错误,那么可以尝试以下方法来进一步解决问题:
-
检查文件路径中的转义字符:在文件路径中,反斜杠(\)通常被用作转义字符。确保在路径字符串中使用了正确的转义字符,或者可以尝试使用原始字符串(在字符串前面加上
r)来避免转义字符的影响。 -
检查文件路径中的斜杠方向:在文件路径中使用的斜杠方向应该与操作系统相匹配。在Windows系统中,使用反斜杠(\),而在类Unix系统(如Linux)中,使用正斜杠(/)。确保路径中的斜杠方向正确。
-
尝试使用绝对路径:尝试使用文件的绝对路径,而不是相对路径。将完整的文件路径直接指定到代码中,以确保准确性。
-
检查代码中的其他可能错误:检查代码中是否存在其他可能导致该错误的问题,如文件名大小写不匹配、文件名扩展名错误等。
如果以上方法仍然无法解决问题,可能需要进一步检查代码逻辑或提供更多的上下文信息,以便更准确地定位问题所在。
问题分析
根据你提供的代码,我注意到你在最后一行使用了joblib.dump(worker0705, './worker0705_best.pkl')来保存模型。然而,由于你的错误信息中提到无法找到文件'E:\文档\Projects\Pycharm\HR_system\0705_new_pro\v1\data\worker0705.pkl\models\XGBoost_BAG_L1\S1F5\xgb.ubj',我怀疑可能是路径问题导致的。
你可以尝试修改最后一行的代码,将保存模型的文件路径指定为绝对路径,而不是相对路径。例如,使用以下代码:
joblib.dump(worker0705, 'E:/文档/Projects/Pycharm/HR_system/0705_new_pro/v1/data/worker0705_best.pkl')
确保指定的路径是存在的,并且具有写入权限。这样做可以避免相对路径的问题,确保模型文件被正确保存。
请尝试修改代码并再次运行,看看是否能够成功保存模型文件。如果问题仍然存在,请提供更多的错误信息以便我能够更准确地帮助你解决问题。
其他方法
#!D:/workplace/python
# -*- coding: utf-8 -*-
# @File : t2.py
# @Author:Romulushe
# @Time : 2023/7/5 18:58
# @Software: PyCharm
# @Use: PyCharm
import pickle
# 打开.pkl文件
with open('worker0705_best.pkl', 'rb') as file:
# 使用pickle模块加载文件中的数据
data = pickle.load(file)
# 现在,您可以使用变量"data"来访问.pkl文件中的对象或数据
# 进行其他处理或操作
报错信息
"D:\Program Files (x86)\anaconda\envs\ag\python.exe" E:/文档/Projects/Pycharm/HR_system/0705_new_pro/v1/data/t2.py
Traceback (most recent call last):
File "E:\文档\Projects\Pycharm\HR_system\0705_new_pro\v1\data\t2.py", line 13, in <module>
data = pickle.load(file)
_pickle.UnpicklingError: invalid load key, '\x04'.
Process finished with exit code 1
调试方法
这个错误可能是由于.pkl文件损坏或不兼容的pickle版本导致的。下面有几种可能的解决方案:
-
检查文件路径和名称:请确保您提供的.pkl文件路径和名称是正确的,包括正确的大小写和文件扩展名。如果路径包含空格或特殊字符,请将其放在引号中,例如
'filename.pkl'。 -
检查文件是否损坏:您可以尝试打开.pkl文件并检查其内容是否完整。如果文件已损坏或截断,您需要找到正确的副本或重新生成.pkl文件。
-
检查pickle版本:如果您使用的pickle版本与创建.pkl文件时使用的版本不兼容,可能会导致加载错误。您可以尝试使用与创建.pkl文件时相同的pickle版本进行加载。另外,确保您的Python环境没有发生变化,以防止pickle版本不匹配。
-
尝试使用
pickle.Unpickler:有时,pickle.load()函数无法正确处理某些.pkl文件。您可以尝试使用pickle.Unpickler类手动进行反序列化。下面是一个示例:
import pickle
with open('filename.pkl', 'rb') as file:
unpickler = pickle.Unpickler(file)
data = unpickler.load()
这种方法使用pickle.Unpickler类从文件中加载数据,而不是使用pickle.load()函数。
如果您仍然遇到问题,请确保.pkl文件的完整性,并尝试使用其他工具或方法来加载和处理该文件。
继续调试
该错误表明.pkl文件的反序列化过程中发生了错误,并且无法正确加载数据。错误消息中的invalid load key, '\x04'指示加载过程中遇到了无效的键值。
这种情况通常发生在以下情况下:
-
文件格式不匹配:如果.pkl文件是使用不同的pickle协议或pickle版本创建的,它可能无法与当前的pickle版本兼容。您可以尝试使用较低版本的pickle或与创建.pkl文件的环境相同的pickle版本。
-
数据损坏:如果.pkl文件已经损坏或被篡改,它可能无法正确加载。请确保.pkl文件完整且没有被修改。
尝试以下解决方法:
-
更改pickle协议版本:尝试使用不同的pickle协议版本来加载.pkl文件。在
pickle.load()或unpickler.load()之前,设置pickle.HIGHEST_PROTOCOL为较低的协议版本,如下所示:import pickle with open('filename.pkl', 'rb') as file: unpickler = pickle.Unpickler(file) unpickler.proto = 2 # 设置较低的协议版本 data = unpickler.load()通过将
unpickler.proto设置为适当的协议版本(如2),可以尝试加载.pkl文件。 -
尝试其他反序列化库:如果使用pickle无法成功加载.pkl文件,可以尝试使用其他的反序列化库,如
joblib或dill。这些库提供了与pickle类似的功能,但可能更具容错性。您可以使用pip命令安装这些库,然后尝试加载.pkl文件。例如:import joblib data = joblib.load('filename.pkl')或者
import dill with open('filename.pkl', 'rb') as file: data = dill.load(file)这些库可以处理某些pickle无法处理的对象类型或数据结构。
如果以上方法仍然无法解决问题,可能需要检查.pkl文件的来源和生成代码,并确保它们之间的兼容性和一致性。
正确调用方式
import joblib
data = joblib.load('worker0705_best.pkl')
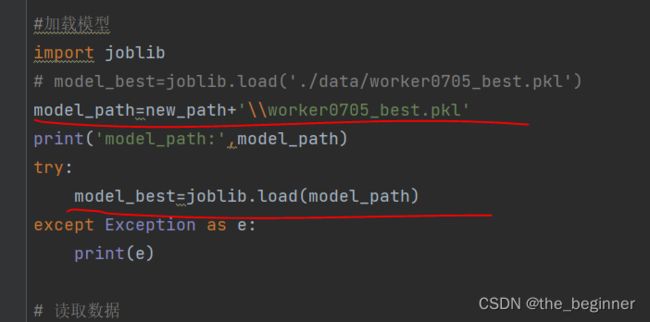
这个错误是由于在文件路径字符串中的反斜杠\之前没有额外的转义反斜杠\导致的。在Python字符串中,反斜杠\是一个特殊字符,用于转义其他字符。为了在字符串中包含一个反斜杠\,您需要在其前面添加另一个反斜杠\进行转义。
在您提供的错误消息中,数据文件路径E:\文档\Projects\Pycharm\HR_system\0705_new_pro\v1\data\raw_0705.csv中的反斜杠\之前缺少转义反斜杠\。要解决这个问题,您可以将路径字符串中的单个反斜杠\替换为双反斜杠\\,或者在路径字符串前面添加一个r前缀来表示原始字符串。
下面是两种可能的解决方法:
-
使用双反斜杠
\\进行路径字符串的转义:data_path = 'E:\\文档\\Projects\\Pycharm\\HR_system\\0705_new_pro\\v1\\data\\raw_0705.csv' data = pd.read_csv(data_path) -
使用原始字符串(在字符串前面添加
r前缀):data_path = r'E:\文档\Projects\Pycharm\HR_system\0705_new_pro\v1\data\raw_0705.csv' data = pd.read_csv(data_path)
无论选择哪种方法,都会确保在字符串中正确表示反斜杠\,从而解决OSError: [Errno 22] Invalid argument错误。
结论
模型pkl必须与调用模型文件在同一目录
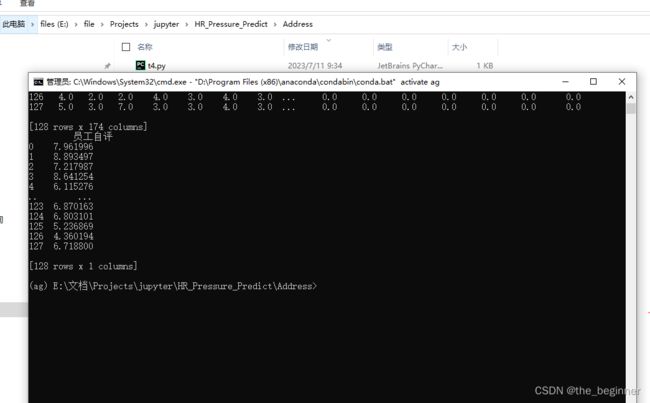
打脸(这样也没有报错)
报错根本原因
模型预测报错 与 读取路劲无关
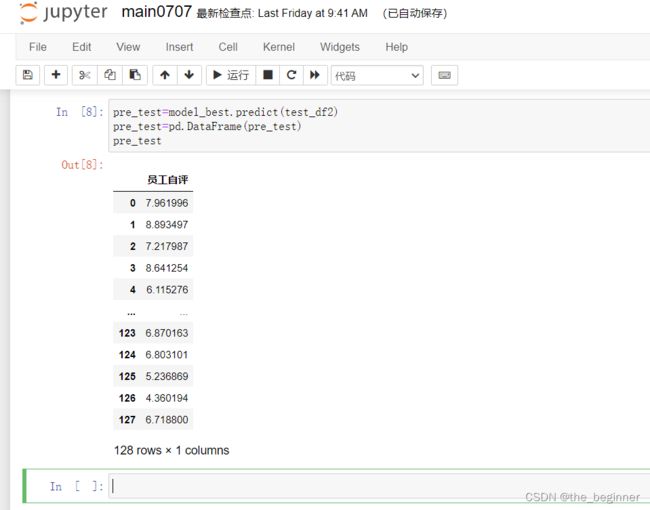
Jupyter
Pycharm
#读取数据
import numpy as np
import pandas as pd
#加载模型
import joblib
model_best=joblib.load('E:/文档/Projects/jupyter/HR_Pressure_Predict/data/AUO-train/model/AM/worker5/best.pkl')
test_df2=pd.read_csv('E:/文档/Projects/Pycharm/HR_system/0705_new_pro/v1/data/test_df2_0705.csv')
del test_df2['Unnamed: 0']
print(test_df2)
pre_test=model_best.predict(test_df2)
pre_test=pd.DataFrame(pre_test)
pre_test
依旧报错
"D:\Program Files (x86)\anaconda\envs\ag\python.exe"
0 8.0 5.0 6.0 7.0 3.0 ... 0.0 0.0 0.0 0.0 0.0
1 9.0 2.0 4.0 1.0 4.0 ... 0.0 0.0 0.0 0.0 0.0
2 6.0 2.0 4.0 1.0 4.0 ... 0.0 0.0 0.0 0.0 0.0
3 9.0 10.0 4.0 8.0 4.0 ... 0.0 0.0 0.0 0.0 0.0
4 6.0 2.0 4.0 1.0 4.0 ... 0.0 0.0 0.0 0.0 0.0
.. ... ... ... ... ... ... ... ... ... ... ...
123 7.0 3.0 7.0 3.0 3.0 ... 0.0 0.0 0.0 0.0 0.0
124 7.0 5.0 5.0 5.0 3.0 ... 0.0 0.0 0.0 0.0 0.0
125 5.0 5.0 4.0 5.0 3.0 ... 0.0 0.0 0.0 0.0 0.0
126 4.0 2.0 2.0 4.0 3.0 ... 0.0 0.0 0.0 0.0 0.0
127 5.0 3.0 7.0 3.0 3.0 ... 0.0 0.0 0.0 0.0 0.0
[128 rows x 174 columns]
Traceback (most recent call last):
File "E:\文档\Projects\Pycharm\HR_system\0705_new_pro\v1\data\t4.py", line 18, in <module>
pre_test=model_best.predict(test_df2)
File "C:\Users\Administrator\AppData\Roaming\Python\Python39\site-packages\autogluon\tabular\predictor\predictor.py", line 1371, in predict
return self._learner.predict(X=data, model=model, as_pandas=as_pandas, transform_features=transform_features)
File "C:\Users\Administrator\AppData\Roaming\Python\Python39\site-packages\autogluon\tabular\learner\abstract_learner.py", line 160, in predict
y_pred_proba = self.predict_proba(X=X, model=model, as_pandas=False, as_multiclass=False, inverse_transform=False, transform_features=transform_features)
File "C:\Users\Administrator\AppData\Roaming\Python\Python39\site-packages\autogluon\tabular\learner\abstract_learner.py", line 141, in predict_proba
y_pred_proba = self.load_trainer().predict_proba(X, model=model)
File "C:\Users\Administrator\AppData\Roaming\Python\Python39\site-packages\autogluon\core\trainer\abstract_trainer.py", line 555, in predict_proba
return self._predict_proba_model(X, model, cascade=cascade)
File "C:\Users\Administrator\AppData\Roaming\Python\Python39\site-packages\autogluon\core\trainer\abstract_trainer.py", line 1975, in _predict_proba_model
return self.get_pred_proba_from_model(model=model, X=X, model_pred_proba_dict=model_pred_proba_dict, cascade=cascade)
File "C:\Users\Administrator\AppData\Roaming\Python\Python39\site-packages\autogluon\core\trainer\abstract_trainer.py", line 569, in get_pred_proba_from_model
model_pred_proba_dict = self.get_model_pred_proba_dict(X=X, models=models, model_pred_proba_dict=model_pred_proba_dict, cascade=cascade)
File "C:\Users\Administrator\AppData\Roaming\Python\Python39\site-packages\autogluon\core\trainer\abstract_trainer.py", line 795, in get_model_pred_proba_dict
model = self.load_model(model_name=model_name)
File "C:\Users\Administrator\AppData\Roaming\Python\Python39\site-packages\autogluon\core\trainer\abstract_trainer.py", line 1272, in load_model
return model_type.load(path=path, reset_paths=self.reset_paths)
File "C:\Users\Administrator\AppData\Roaming\Python\Python39\site-packages\autogluon\core\models\ensemble\bagged_ensemble_model.py", line 888, in load
model = super().load(path=path, reset_paths=reset_paths, verbose=verbose)
File "C:\Users\Administrator\AppData\Roaming\Python\Python39\site-packages\autogluon\core\models\abstract\abstract_model.py", line 926, in load
model = load_pkl.load(path=file_path, verbose=verbose)
File "C:\Users\Administrator\AppData\Roaming\Python\Python39\site-packages\autogluon\common\loaders\load_pkl.py", line 42, in load
with compression_fn_map[compression_fn]['open'](validated_path, 'rb', **compression_fn_kwargs) as fin:
FileNotFoundError: [Errno 2] No such file or directory: '../data/AUO-train/model/AM/worker5/worker5.pkl\\models\\ExtraTreesMSE_BAG_L1\\model.pkl'
Process finished with exit code 1
Jupyter
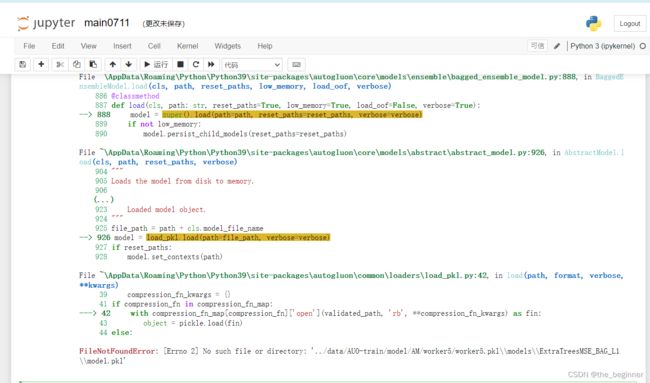
暂时无解:必须在建模的目录下,去读取模型,才不会报错!!!!