手把手教学构建证券知识图谱/知识库(含码源):网页获取信息、设计图谱、Cypher查询、Neo4j关系可视化展示

项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实战掌握技能,助力用户更好利用 CSDN 平台,自主完成项目设计升级,提升自身的硬实力。

-
专栏订阅:项目大全提升自身的硬实力
-
[专栏详细介绍:项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域)
手把手教学构建证券知识图谱/知识库(含码源):网页获取信息、设计图谱、Cypher查询、Neo4j关系可视化展示
demo展示:

- 代码结构
stock-knowledge-graph/
├── __init__.py
├── extract.py # extract html pages for executives information
├── stock.py # get stock industry and concept information
├── build_csv.py # build csv files that can import neo4j
├── import.sh
├── data
│ ├── stockpage.zip
│ ├── executive_prep.csv
│ ├── stock_industry_prep.csv
│ ├── stock_concept_prep.csv
│ └── import # import directory
│ ├── concept.csv
│ ├── executive.csv
│ ├── executive_stock.csv
│ ├── industry.csv
│ ├── stock.csv
│ ├── stock_concept.csv
│ └── stock_industry.csv
├── design.png
├── result.txt
├── img
│ ├── executive.png
│ └── executive_detail.png
├── import.report
├── README.md
└── requirements.txt
1.数据源
本项目需要用到两种数据源:一种是公司董事信息,另一种是股票的行业以及概念信息。
-
公司董事信息
这部分数据包含在
data目录下的stockpage压缩文件中,⾥面的每一个文件是以XXXXXX.html命名,其中XXXXXX是股票代码。这部分数据是由同花顺个股的⽹页爬取而来的,执行解压缩命令unzip stockpage.zip即可获取。比如对于600007.html,这部分内容来自于http://stockpage.10jqka.com.cn/600007/company/#manager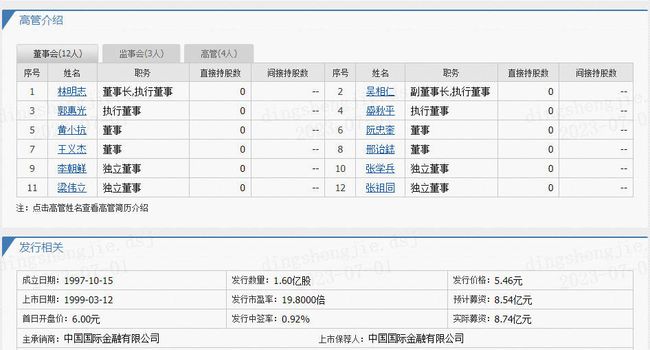
-
股票行业以及概念信息
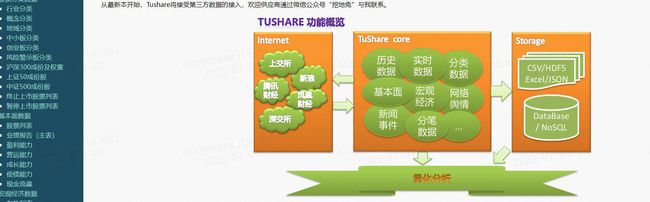
这部分信息也可以通过⽹上公开的信息得到。在这里,我们使用Tushare工具来获得,详细细节见之后具体的任务部分。
2.从⽹页中抽取董事会的信息
在我们给定的html文件中,需要对每一个股票/公司抽取董事会成员的信息,这部分信息包括董事会成员“姓名”、“职务”、“性别”、“年龄”共四个字段。首先,姓名和职务的字段来自于:
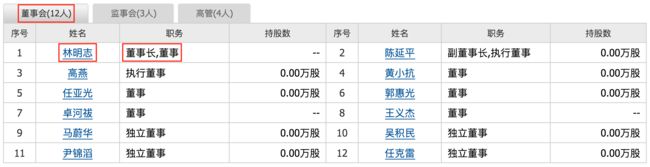
在这里总共有12位董事成员的信息,都需要抽取出来。另外,性别和年龄字段也可以从下附图里抽取出来:
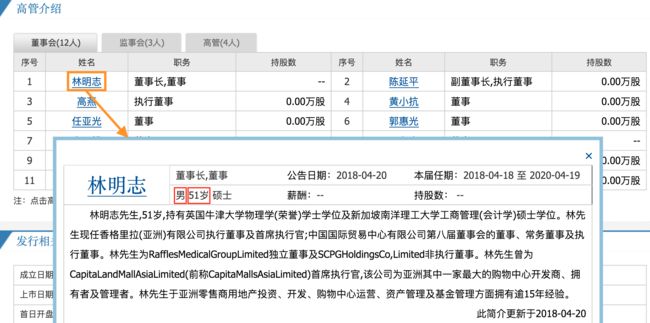
最后,生成一个 executive_prep.csv文件,格式如下:
| 高管姓名 | 性别 | 年龄 | 股票代码 | 职位 |
|---|---|---|---|---|
| 朴明志 | 男 | 51 | 600007 | 董事⻓/董事 |
| 高燕 | 女 | 60 | 600007 | 执⾏董事 |
| 刘永政 | 男 | 50 | 600008 | 董事⻓/董事 |
| ··· | ··· | ··· | ··· | ··· |
注:建议表头最好用相应的英文表示。
3.获取股票行业和概念的信息
分类数据_提供股票的分类信息数据,从股票类型的不同角度进行数据分类,在一些统计套利方法的应用中,时常会以股票的分类来做切入,比如对某些行业或概念进行阶段统计来决定近期的交易策略等。TuShare 提供的分类数据主要包括以下类别:
-
行业分类
-
概念分类
-
地域分类
-
中小板分类
-
创业板分类
-
风险警示板分类
-
沪深 300 成份股及权重
-
上证 50 成份股
-
中证 500 成份股
-
终止上市股票列表
-
暂停上市股票列表
-
行业分类
在现实交易中,经常会按行业统计股票的涨跌幅或资金进出,本接口按照 sina 财经对沪深股票进行的行业分类,返回所有股票所属行业的信息。考虑到是一次性在线获取数据,调用接口时会有一定的延时,请在数据返回后自行将数据进行及时存储。sina 财经提供的行业分类信息大致如下图所示:

返回值说明:
- code:股票代码
- name:股票名称
- c_name:行业名称
对于这部分信息,我们可以利⽤工具Tushare来获取,官网为http://tushare.org/ ,使用pip命令进行安装即可。下载完之后,在python里即可调用股票行业和概念信息。参考链接:http://tushare.org/classifying.html#id2
通过以下的代码即可获得股票行业信息,并把返回的信息直接存储在stock_industry_prep.csv文件里。
import tushare as ts
df = ts.get_industry_classified()
# TODO 保存到"stock_industry_prep.csv"
类似的,可以通过以下代码即可获得股票概念信息,并把它们存储在stock_concept_prep.csv文件里。
df = ts.get_concept_classified()
# TODO 保存到“stock_concept_prep.csv”
4.设计知识图谱
设计一个这样的图谱:
-
创建“人”实体,这个人拥有姓名、性别、年龄
-
创建“公司”实体,除了股票代码,还有股票名称
-
创建“概念”实体,每个概念都有概念名
-
创建“行业”实体,每个行业都有⾏业名
-
给“公司”实体添加“ST”的标记,这个由LABEL来实现
-
创建“人”和“公司”的关系,这个关系有董事长、执行董事等等
-
创建“公司”和“概念”的关系
-
创建“公司”和“行业”的关系
设计结果如下:

注:实体名字和关系名字需要易懂,对于上述的要求,并不一定存在唯一的设计,只要能够覆盖上面这些要求即可。“ST”标记是⽤用来刻画⼀个股票严重亏损的状态,这个可以从给定的股票名字前缀来判断,背景知识可参考百科ST股票,“ST”股票对应列表为[‘*ST’, ‘ST’, ‘S*ST’, ‘SST’]。
ST 股票,意即“特别处理”的股票。该政策针对的对象是出现财务状况或其他状况异常的。1998年4月22日,沪深交易所宣布,将对财务状况或其它状况出现异常的上市公司股票交易进行特别处理(Special Treatment),由于“特别处理”,在简称前冠以 ST,因此这类股票称为 ST 股。
5.创建可以导⼊Neo4j的csv文件
在前两个任务里,我们已经分别生成了 executive_prep.csv, stock_industry_prep.csv, stock_concept_prep.csv,但这些文件不能直接导入到Neo4j数据库。所以需要做⼀些处理,并生成能够直接导入Neo4j的csv格式。
我们需要生成这⼏个文件:executive.csv, stock.csv, concept.csv, industry.csv, executive_stock.csv,
stock_industry.csv, stock_concept.csv。对于格式的要求,请参考:https://neo4j.com/docs/operations-manual/current/tutorial/import-tool/
6.利用上面的csv文件生成数据库
neo4j_home$ bin/neo4j-admin import --id-type=STRING --nodes executive.csv --nodes stock.csv --nodes concept.csv --nodes industry.csv --relationships executive_stock.csv --relationships stock_industry.csv --relationships stock_concept.csv
这个命令会把所有的数据导入到Neo4j中,数据默认存放在 graph.db 文件夹里。如果graph.db文件夹之前已经有数据存在,则可以选择先删除再执行命令。
把Neo4j服务重启之后,就可以通过localhost:7474观察到知识图谱了。
注意:这些csv要放到~/.config/Neo4j Desktop/Application/neo4jDatabases/database-xxxx/installation-4.0.4下,即与bin文件夹同级,否则需要绝对路径
简单查询命令
# 查询node
MATCH (n:Concept) RETURN n LIMIT 25
# 查询relationship
MATCH p=()-[r:industry_of]->() RETURN p LIMIT 100
7.基于构建好的知识图谱,通过编写Cypher语句回答如下问题
(1) 有多少个公司目前是属于 “ST”类型的?
match (n:ST) return count(distinct(n))
104
(2) “600519”公司的所有独立董事人员中,有多少人同时也担任别的公司的独立董事职位?
MATCH (m:Company{code:‘600519’})<-[:employ_of{jobs:‘独立董事’}]-(n:Person)-[:employ_of{jobs:‘独立董事’}]->(q:Company)
RETURN count(distinct(n))
3
(3) 有多少公司既属于环保行业,又有外资背景?
MATCH (:Concept{name:‘外资背景’})<-[:concept_of]-(m:Company)-[:industry_of]-(:Industry{name:‘环保行业’})
RETURN count(distinct(m))
0
(4) 对于有锂电池概念的所有公司,独立董事中女性人员比例是多少?
MATCH (m:Concept{name:‘锂电池’})<-[:concept_of]-(n:Company)<-[:employ_of{jobs:‘独立董事’}]-(p:Person{gender:‘女’})
MATCH (m:Concept{name:‘锂电池’})<-[:concept_of]-(n:Company)<-[:employ_of{jobs:‘独立董事’}]-(p2:Person)
RETURN count(distinct§)*1.0/count(distinct(p2))
0.3541666666666667
8.构建人的实体时,重名问题具体怎么解决?
(1) 最好的方式是用身份证或者其他唯一能确定人的方式去关联。
(2) 在本例中,我用 姓名、年龄、性别3个字段做唯一的,将这3个字段做md5。
资料下载见文章顶部或者文末链接
https://download.csdn.net/download/sinat_39620217/87981257