站在2023的起点,目前自动驾驶技术发展到了什么水平?
作者 | 洪泽鑫 编辑 | 汽车人
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群


按:汽车行业这年经历了众多跌宕起伏,既遭遇了新冠疫情、芯片短缺、L4自动驾驶寒潮等冲击,也收获了城市领航辅助驾驶落地、国产大算力芯片/激光雷达上车等亮眼战绩。
站在年终岁末的节点,HiEV编辑们将和业内人士一同总结当下、探索未来,为大家梳理行业发展的关键脉络。在2022年终盘点这个系列中,我们将共同记录下这年关于公司、技术和人的那些闪闪发光的时刻。
2022年,科技日/Tech Day/AI Day成为汽车行业一种新的潮流,其中既有特斯拉、小鹏这样的车企,也有毫末智行、百度、华为、轻舟智航、福瑞泰克等从L4/L2技术出发推动前装量产的科技公司。
硬核科技日,意味着面对自动驾驶这样的尖端话题,头部公司希望通过开放一部分的思考,来加速整个行业的进步;另一方面,公众对整车产品背后的技术,也逐渐显露出浓厚的兴趣。
车企和科技公司们,从不同的背景和业务定位出发,技术路线也各有差异,我们可以从中管窥自动驾驶领域不少前沿的突破和技术趋势。
目录


Robotaxi公司篇

Waymo
作为全球自动驾驶的鼻祖和领导者,Waymo在公布技术进展、研究成果时,有很强的推动行业的意味。比如,它的成果发布常常带着数据集的公开或者更新,以期影响更多开发者。
Waymo官网的技术博客理解门槛较低,很好地体现了Waymo ONE直面用户To C的定位,主要目的是让乘客更信任自动驾驶。但同时,Waymo又附上了具体论文信息,对技术人员了解新的技术趋势很友好。
感知
下面几篇小论文可以看到Waymo在感知领域的一些新进展:
SWFormer:点云3D目标检测的稀疏窗口Transformer
LidarAugment:搜索可扩展的3D LiDAR数据增强
PseudoAugment:学习使用未标记的数据在点云中进行数据增强
Surprise-based framework
关键概念
基于“惊讶度”对真实道路环境下的司机反应时间进行测量和建模。
亮点/指标
在决策规划上,Waymo一直在找判断智驾好坏的基准线。
在反应时间上,智驾系统延迟多少算是达标?目前并没有很好的答案,这篇论文就是为了解答这个问题。
Waymo发现,在交通事故发生时,人类司机的反应时间可以作为一个很好的参考,所以把“惊讶度”作为衡量标准,对真实道路环境下的司机反应时间进行测量和建模。
借助这个框架和模型,Waymo给自己的智驾系统的碰撞避免行为创建了一个内部基准,用于验证智驾系统的智能化程度。
劣势/不足
这是Waymo对于如何利用人类行为数据作为智驾表现好坏评价基准的尝试之一,并没有引起太多关注。
NIEON
关键概念
这个模型是基于人类司机事故数据训练出来的,意思是一个“理想型”人类司机,并把这个“司机”作为评价Waymo智驾系统的基准线。
亮点/指标
今年论文公开的NIEON模型,相比人类司机,能防止62.5%的碰撞,并降低84%的严重伤害风险。
当Waymo智驾被置于撞人角色时,完全避免或减轻了100%的碰撞。
当Waymo智驾被置于被撞角色时,完全避免了82%的事故。
在另外10%的场景中,当Waymo智驾是被撞角色时——当另一辆车转向其路径时,都在十字路口——它采取了减轻碰撞严重性的行动。
只有8%的被撞状态模拟没有变化,几乎都是被追尾的情况。
Waymo的智驾系统比NIEON模型更安全,能避免75%的碰撞,并降低93%的严重伤害风险。这说明,自动驾驶比人类驾驶更安全的客观依据,同时再次科普了自动驾驶并非0事故,只是更安全,为政策制定提供依据。
Block-NeRF
关键概念
基于相机图像的大规模场景重建的新方法。
亮点/指标
将场景分解为单独训练的NeRF,使渲染能够扩展到任意大的环境,并允许对环境进行每个块更新。
使用这项技术从280万张图像中重建了旧金山的整个社区——这是迄今为止最大的基于NeRF的3D重建。
细节展示了基于旧金山阿拉莫光场和使命湾合成的3D场景,阿拉莫广场面积960米 x 570米,数据分别捕捉于6月、7月和8月,共由35个Block-NeRF组成,经过了38到48次数据收集训练,训练每个Block-NeRF分别使用了6.5万到10.8万张图像数据,累计采集时间为13.4小时(1330次数据采集)。
发布了Waymo Block-NeRF数据集,由12个摄像头记录的100秒驾驶组成,包含1.08公里车程,总共约12,000张图像。
劣势/不足
没有公布给旧金山“建模”用了多长时间,但从描述来看,花费的总时长应该不短。
Waymo Open Dataset
关键概念
是2019年推出,最大、最多样化的自动驾驶数据集之一。
亮点/指标
Perception dataset,有2030个场景,目前最新版为2022年6月升级的v1.4,分训练和评估两部分,主要在凤凰城、山景城和旧金山采集,大部分为白天和晴天。
Motion dataset,有目标轨迹追踪和3D同步地图,有103354个场景,目前最新版为2021年8月升级的v1.1版。
发布以来,支撑了500多篇业界论文成果。
2022年3月增加了关键点和姿势估计、3D分割标签、2D到3D边界框对应标签。
2022年Waymo开放数据集挑战赛,连办多届,多家公司响应。

百度
文心大模型自动驾驶感知
关键概念
前代的感知更多是后融合,把激光雷达、摄像头、毫米波雷达三种传感器的感知结果融合在一起。
新一代感知2.0基于前融合方案,多模态前融合端到端;利用了文心大模型图像弱监督预训练的模型来挖掘长尾数据。
亮点/指标
这是一套覆盖近距离、中等距离和远距离的感知方案。
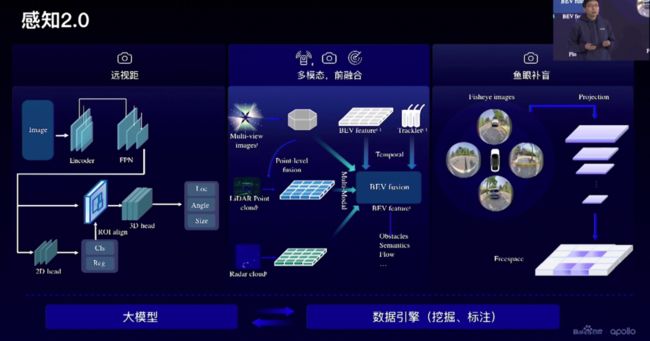
通过半监督的方法,利用2D的标注和没有3D标注的数据,在既有2D又有3D的训练数据上面,去训练一个感知大模型,然后给3D数据打上3D伪标注。

在编码器、2D检测Head、3D检测Head三个地方使用了蒸馏。
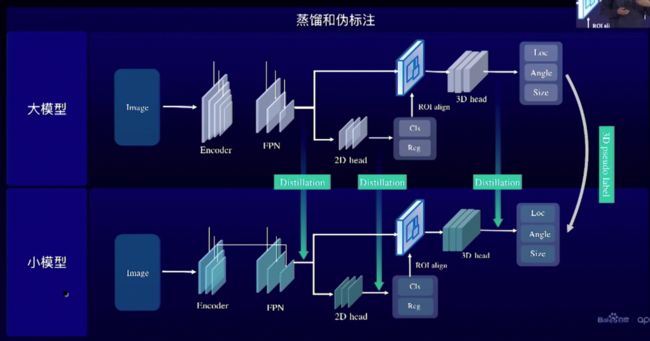
把大模型的Detection head,包括2D、3D里面的参数,直接作为小模型的初始化,提升训练的效率和效果。
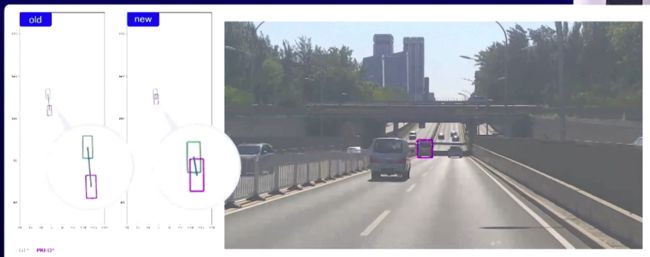
用了几个例子表示新模型的准确度,左边绿色的框是对应真值,红色的是预测的结果。
Apollo自动驾驶地图
关键概念
主要应用于L4自动驾驶。
亮点/指标
自动化数据融合:按照数据空间分布划分,构建多层级的图结构,确保全图的精度一致,在统一的坐标系下进行融合。
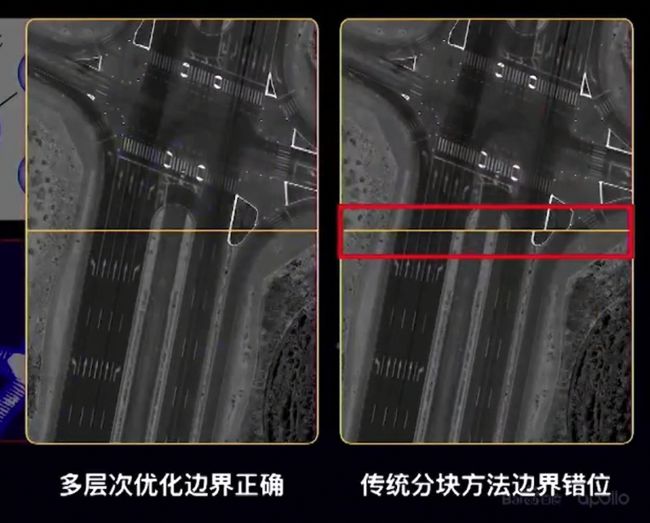
地图自动化标注:多层级的点云识别,结果优于一次识别的结果,基于车道级的拓扑模板进行了矢量要素的匹配,提高了拓扑的生成以及车道线串接的准确性。
在线地图:使用车辆的摄像头和激光雷达,基于Transformer生成BEV的Feature Map,生成车端的实时地图,最终将车端的实时地图和高精地图以及众源地图进行有效的融合,生成在线地图。

驾驶知识图谱:基于百度地图超过1200万公里的路网覆盖、日均20亿公里的轨迹里程,包含了多维度,且丰富的驾驶知识,例如经验速度、变道的时机、变道的轨迹等等,这跟轻舟提到的人类驾驶行为数据使用类似。
Apollo自动驾驶地图总共分三层:静态层、动态层、知识层、驾驶层,跟Momenta2019年的说法有点像。

数据提纯+数据消化
关键概念
百度理解整个数据闭环是由数据提纯以及数据消化这两个部分构成。

亮点/指标
数据挖掘与标注都是提高数据纯度的手段。
基于图文弱监督预训练的模型帮助做长尾数据的挖掘,大模型可以用来通过推理引擎获取对应数据的特征和标签,可以用作定向挖掘。

车上的小模型可以进行数据的初步筛选,通过推理的方式获取小模型的标签,实现重要的数据回传,多个小模型还可以获得模型对数据的不确定性,从而实现不确定性挖掘。

数据消化:自动化、联合优化以及数据分布。

自动化:
使用异步的推理引擎对模型进行评测,最终的训练的输出是一个候选模型的集合,而不是单一的模型,以下图小狗为例,当出现误检之后,可以利用特征检索的一些方式,挖掘出小狗的数据,然后将新数据与旧数据同时传入到训练引擎进行自动化训练,最终实现指标的提升。

联合优化:
假如预测指标与仿真指标的目标不一致,预测模型的指标提升不一定对仿真指标提升有帮助,但在训练的同时,将产生的预测模型实时地与下游规划模块进行打包,同步地进行仿真评测。最终的训练引擎同时优化的是离线的预测指标以及仿真的端到端指标。


数据分布:
首先对数据分布的先验进行统一的管理,这里的先验可以是人为设定的,也可以是通过学习来获得。当这个先验进入到训练引擎之后,训练引擎其实可以把这个先验或者这个数据分布当作超参数,做一定程度的探索或搜索。当发现更好的分布之后,可以通过一个反馈的机制修正数据分布的先验。


昆仑芯
关键概念
亮点/指标:
第一代14纳米的人工智能芯片,HBM内存,2.5D封装,已经在百度数据中心里面部署了超过2万片。
第二代AI芯片,7纳米的工艺,XPU第二代架构,第一颗采用GDDR6内存技术的AI芯片。



Cruise
Cruise背靠车企,其L4无人车Origin集合了改装车成本低、前装车可定制的优点。
其分享会的最后用一个具体的女性用户案例,来描述无人出租能带来的便利和安全,并且展示远程监控工具,还能确认有没有遗落物品。

感知
用了很多demo示例来呈现不同模块的表现效果,但具体技术实现讲得少。
在面对遮挡区域时,也有类似特斯拉ghost object的应用。
预测神经网络架构
关键概念
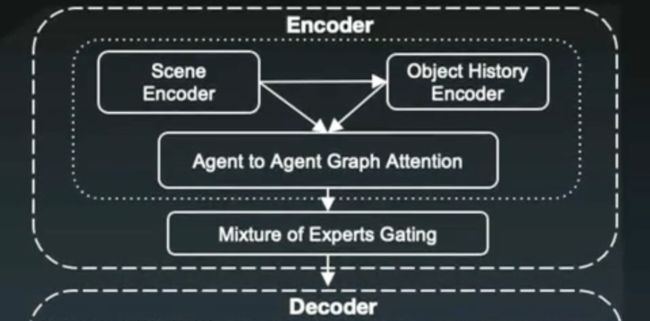
基于众多数据,用自监督的方法构建了一个端到端的预测神经网络架构,由Encoder和Decoder两部分组成。
Encoder以每个物体的历史状态和所处场景为输入,通过一个Graph Attention Network学习整个场景的潜在含义,包括不同物体间的交互。
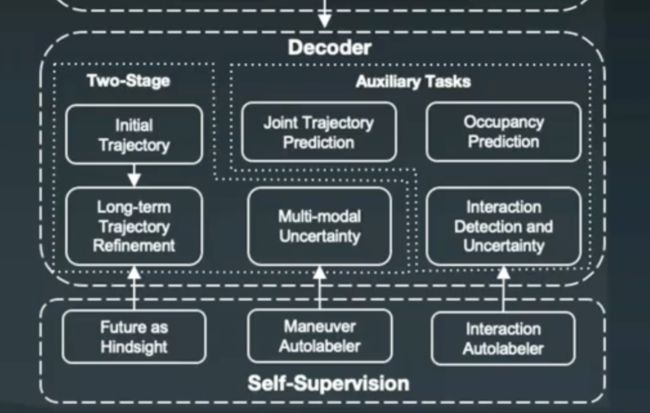
Decoder则是由Two-Stage和辅助任务两个子集构成,见下图,特别强调运用了自监督学习实现自动标注。

亮点/指标
能同时预测超过20人的行走状态。
在旧金山需要处理的交互场景的复杂度比凤凰城高32倍。
Cruise Decision Engine
关键概念
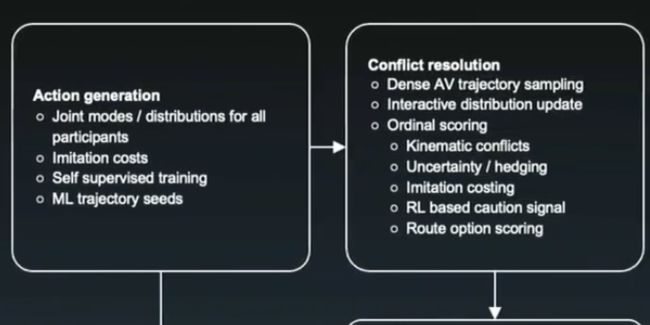
公开了决策模型的架构图,并简要介绍了含义。



亮点/指标
针对达到的效果(outcomes),尤其是不确定性(运动状态、存在与否、3D空间的不确定性),放了许多demo视频作为例子,但没有太详细解释具体技术方法。
其中existence uncertainty有被遮挡区域的ghost object例子,以及鬼探头的例子。
3D uncertainty是找了一个十字路口,其中一个路口是坡道的例子。
360 interaction是一个用逆向车道绕过路障的例子。
在计算速度上,通过其深度学习网络加速,大部分的时候决策只需要14ms,最坏的情况延迟是80ms。

用一个曲线图表示如何在控制层面达到的平顺效果,但没有细讲做法。
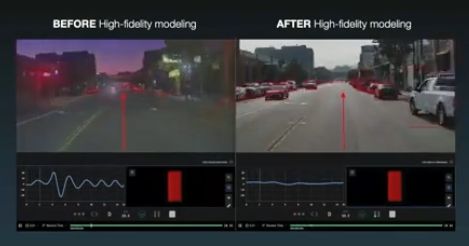
Cruise仿真
关键概念
包括morpheus、Road to Sim、NPC AI三个基础模块。
morpheus:通过简单代码便能模拟行驶轨迹,结合地图数据生成众多轨迹。

Road to Sim:从收集到的真实场景图像数据中学习,生成仿真场景。

NPC AI:smart agent,用到了预测模型来让NPC做出反应
亮点/指标
展示了阿拉莫广场的自动仿真重建结果(没说耗时多久),强调没有人工的参与。
可仿真光照和天气,还可以模拟多普勒效应。
仿真可以帮助收集特殊数据,比如被遮挡的警车、救护车等,效率比实际道路收集高180倍。
Webviz
关键概念
最初只是可视化工具,现在已经是一个开源的、供大规模开发团队一同协作的开发平台。
亮点/指标
在旧金山的日常道路测试里,有用的数据占比不到1%,所以数据的管理筛选很重要。
展示了内部的Event管理页面,可以很简单地查找case,或者智能化地提取跟某个event相关的其他类似event。

超过95%的Cruise员工在使用。
展示了工程师如何修改代码、自动构建和执行系列测试、分析结果并比较的过程,下面是某个场景在仿真测试中的比较结果。
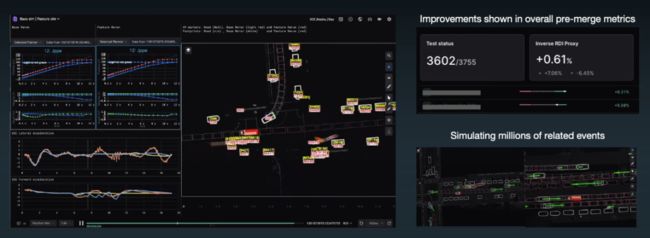
简单提到了车道线生成,应用在了地图的自动更新中。

仿真的运行效率数据:每天收集PB量级真实数据,合成PB量级的仿真数据,每天仿真的数据相当于17年的驾驶经验积累,计算资源的每个月的使用价值达到770年(这个我也没有太理解),每个月执行2千万次场景测试,累积收集已有4 EB的数据。

Origin
关键概念
基于通用对“造车”的洞察,可以保障硬件冗余,同时控制成本。
亮点/指标
目前正在正向研发的激光雷达可以更好地保障FOV的冗余。
考虑到了空气动力学,减少风阻和风噪。
考虑到了传感器的清洁,但没有细讲怎么做的。
计算平台,在四代芯片的迭代过程中,成本下降了十倍。

主要是两类平台,一类用于传感器的边缘计算平台,一个作为主计算平台。
芯片INT8算力1500 TOPS,带宽400GB/Sec,运行内存RAM 1G,DDR达800GB/Sec。


计划推出的新一代传感器,已经看不到机械式激光雷达的身影,可见Cruise在2021年11月就已经在准备应用半固态/固态激光雷达了,领先于国内。

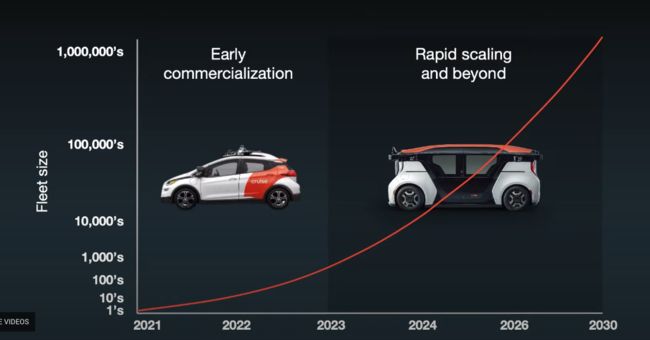
预计2023年Origin投入使用,车队规模达数百辆,2024年车队规模超过一千辆。

车企篇

特斯拉
特斯拉的AI DAY更多分享的是方法论上的创新,以及在最终结果上跟自身过往方法相比的优势。
对比国内公司,特斯拉敢于把较多的技术细节分享出来,从而会引发更多工程师的关注和分析,相反国内的技术分享总是让人云里雾里的。
大部分工程师会细细研究Demo视频,了解细节及原理。没有官方中文解读,所以国内工程师都是连蒙带猜,在语言理解上有点各持一言。
过去一年训练了75000个神经网络,每8分钟就要出一个新的模型,共有281个模型用到了特斯拉的车上。
Occupancy Network
关键概念
Occupancy表示空间中每个3D体素是否被占据,可以更好地处理长尾问题——类别不明的障碍物。
亮点/指标
以多个场景demo展示了对物体形状以及运动状态的感知。

不同颜色含义:
蓝色表示运动物体,红色表示车辆,绿色表示路沿...
3D分割输出时长只需要10ms。
从Demo中估算的感知范围:前向40m,后向20m,左右15m,单个体素约为40cm的立方体。


公开了模型结构:

直接输出道路信息(Surface Outputs),包括海拔和语义信息。
基于queryable MLP decoder,避免了分辨率对模型的限制。
劣势/不足
Occupacy network的真值监督用到了特斯拉4D标注中的线下三维重建场景,但重建场景也存在不准确性。
Tesla bot也用了相同的技术栈,但从demo来看,Occupancy Network在室内的体素体积更小,准确度一般。
首次亮相是2021年FSD Beta的Release Note中,后来在CVPR 2022 WAD WORKSHOP介绍了更多细节。
NeRF
关键概念
Neural Radiance Fields,用深度学习完成3D渲染,完成三维场景的重建。
亮点/指标
以demo呈现利用车队数据离线构建的三维场景效果。
每次重建可能会遇到图像模糊、雨、雾等,但多辆车的数据可以相互补充,在全世界范围内不同天气和光照条件下都能用上。
NeRF和Occupancy的相互结合:Occupancy network产生 3D volume后,将其于3D-reconstruction volume(Nerf离线训练得到)进行比较,起到监督作用。
劣势/不足
相比追求渲染颜色效果,更应该追求准确的位置信息,但官方表示这部分还在努力。
NeRF在Occupancy中的应用类似于“高精地图”,未来如果特斯拉的车队能做到对街景的细节重建,中国测绘政策就形同虚设了。
Interaction Search
关键概念
基于神经网络的轨迹规划,基于特斯拉车队的人类驾驶行为轨迹以及离线优化算法得出轨迹。
亮点/指标
讲解时,先基于无保护左转讲了传统方法的轨迹生成和优化的劣势,再抛出Interaction Search。
基于神经网络可形成数据驱动,减少对工程师的依赖。
基于神经网络的轨迹生成比传统方法时延下降了许多,从1-5ms per action到100us per action
在计算上,从CPU迁移到了GPU。
分享了一个Occlusion的案例:在摄像头被遮挡的区域里,会假设有一个ghost object从远处开过来,这样做类似于人类的习惯。
劣势/不足
特斯拉的Joint Planning指的是自车和他车的联合规划,主要分享的是轨迹的优化方法,没有谈到速度和方向的联合优化方法(国内吉大郭洪艳教授提出过横纵向一体化决策,轻舟提出过时空联合优化)。
Lanes Network
关键概念
Lanes Network
在线矢量地图构建模型,参考了自然语言模型中的Transformer decoder,以序列的方式自回归地输出结果。
分割得到的像素级别的车道不足够用于轨迹规划,而通过Lanes Network可以得到车道线的拓扑结构。
亮点/指标
展示了传统车道线识别的方法只能应用于高速,在城市这种有更多路口的环境下,难以应用。
由于Map信息的稀疏性,向量化表示比栅格化表示更佳。
详细介绍了如何加速Lane Network这类模型。

Autolabeling
关键概念
去年AI DAY详解了Autolabeling,今年主要讲解Lanes Network的自动标注。
通过车队收集上来的多轨迹,重建道路环境,在新的轨迹上便可以重建的道路环境作为真值,自动标注出车道线,自动标注一段新轨迹的时间约为30分钟,支持并发。
亮点/指标
在车道线标注上的各类指标提升情况,原本一万个trips需要5百万个小时的人工标注,现在只需要机器运转12个小时便能完成。

展示了在黑暗、雾气、遮挡、雨天情况下的自动标注效果。

劣势/不足
测绘法再次敲起警钟。
Simulation world creator
关键概念
依赖自动标注的真实世界道路信息和丰富的图形素材库,生成大量场景。
亮点/指标
要想创建一个路口的仿真场景,需要艺术家花2周时间,但特斯拉只需要5分钟。
创建旧金山的仿真城市只需要2周时间。
劣势/不足
特斯拉直到2021年才全面对外展示了自研的渲染引擎、场景库、目标库和对抗学习场景,对旧金山的虚拟城市重建工作Waymo和Cruise早就做过了。
Data Engine
关键概念
以一个路口右前方的停止车辆案例讲解数据闭环,并且展示了手动标注系统的友好度。
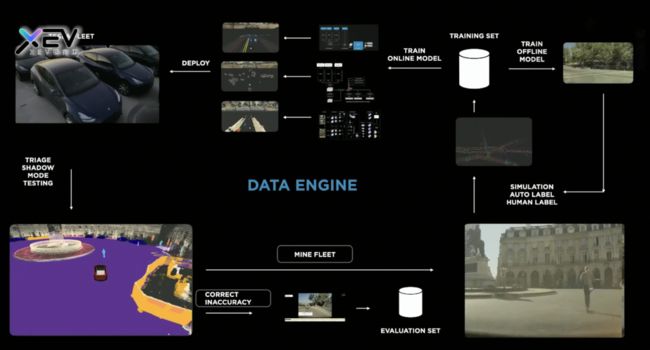
FSD芯片+DOJO
基础设施/计算平台
亮点/指标
车载计算平台上,多模型在两个SoC上跑时,通过优化,可以最大限度地利用100TOPS算力

超算中心拥有14,000个GPU,共30PB的数据缓存,每天都有500,000个新的视频流入这些超级计算机

专门开发了加速的视频解码库,以及加速读写中间特征的文件格式.smol file format。
使用24个GPU集群的服务器在计算一个Batch Normalization时候延迟是150us,在25个D1组成的DOJO训练服务器上,同样的Batch Normalization只需要5us就可以完成,效率提高了30倍。
在加速器使用效率(也就是公式中Accelerator Occupancy部分)上的优化,Tesla给出训练中占用负载最高的AutoLabeler和Occupancy Network部分优化前后的性能分析对比,优化前DOJO加速器占用率只有4%,大量时间消耗在数据读取装载上,而优化后,极速器利用率达到了97%,保证了DOJO高效的使用。
4个DOJO集群箱子就可以带来等效目前72个GPU集群的性能。
预计2023年Q1将会开始交付用以进行AutoLabeler训练的DOJO服务器。

小鹏
内容更偏C端车主端,主要被包装为功能、场景的宣传语言。
缺少技术细节,不像Waymo附有具体论文,鲜有工程师讨论。
自9月17日在广州试点开放以来,截止10月17日,城市NGP周用户渗透率达到84%,里程渗透率达到63%,同时通行效率可接近人类司机的90%,平均每百公里被动接管仅0.6次。
发布XNGP智能辅助驾驶系统,包括无图区域能力大幅升级、XNet 深度视觉神经网络、拟人化的决策系统、人机共驾体系。
相比高速NGP,城市NGP的代码量提升至6倍,感知模型数量提升至4倍,预测/规划/控制相关代码量提升至88倍(潜台词是研发干了很多活)。
XNet
关键概念
将多个摄像头采集的数据,进行多帧时序前融合,输出BEV视角下的动态目标物的4D信息(如车辆,二轮车等的大小、距离、位置及速度、行为预测等),以及静态目标物的3D信息(如车道线和马路边缘的位置)
亮点/指标
Transformer 部署,原本需122%的Orin-X 算力,优化后仅需 9%。
小鹏数据闭环
关键概念
由采集、标注、训练、部署四大核心能力组成。
亮点/指标
引入了黄金骨干网络架构(Golden backbone),首次应用自监督技术。
解藕了骨干模型和发布模型的训练,让多任务的网络训练效率更高。
通过定向采集和仿真结合,一年内累计解决1000个以上Corner case(极限场景),高速NGP事故率降低95%。
5 千万公里的仿真里程,5000+ 个核心模拟场景,挑战 17000+ 个专项模拟场景。
全自动标注系统
关键概念
亮点/指标
标注效率是人工标注的近45000倍,以50万段训练数据Clip,10亿个物体为例,现在仅需16.7天可以完成,而全人工标注需2000人年。
峰值日产 30000 clips,相当于 15个NuScene数据集。
扶摇
关键概念
自动驾驶智算中心
亮点/指标
在乌兰察布建成中国最大的自动驾驶智算中心“扶摇”,算力可达600PFLOPS(每秒浮点运算60亿亿次),模型训练效率提升602倍。
与2400TFLOPS算力的服务器进行单机训练相比,80机并行训练可将训练时长由276天缩短至11小时。
劣势/不足
只抛出数据结果,没有具体怎么做的分享。
全场景语音2.0
关键概念
亮点/指标
唤醒到界面反馈245ms、到语音反馈小于700ms。
并行指令:支持2-4个指令连在一起说,一般竞品只能支持任意2个命令组合。
端云一体:端4路+云4路结果仲裁。
回声消除:支持30dB。
错误率大幅下降:识别准确率达到97%,标准安静场景降低7.7%、中英文混合场景降低7.16%、噪声环境场景降低36.79%、带地域口音场景降低33.84%。
综合唤醒率98%、高噪唤醒率97%。到UI响应低至245ms(提升3倍),到语音回应小于700ms(提升60%);误唤醒率:低于2次/24h。
语音的CPU使用率降低65.9%,内存使用降低42.3%。
通过实车模拟生成车型适配数据,单车型数据采集成本大幅降低,仅为录制音频数据方式成本的5%。

科技公司篇

华为
八爪鱼
关键概念
工具链分为数据、训练、仿真、监管四部分。
可解耦、可定制化。
亮点/指标
华为的预标注算法精度已经达到领先水平,在nuScenes、COCO、KITTI等多个自动驾驶国际公开数据集测试挑战中获得第一。
可提供50多类、120多万张、超过2000多万对象的标注数据集,而且这个数据集是持续迭代、持续扩充的。
对场景进行智能化打标签:开发人员可以上传需要车辆获取的图片,通过云端下发指令,车端会采取类似‘以图搜图’的方式,遇到类似的场景就会自动截取下来,形成特定场景的难例数据集,减少90%的上云数据,并节省70%的数据集构建时间。
一键将真实路测场景转化为仿真场景,可实现95%以上的场景还原能力,能有效帮助开发者快速模拟周边车辆,实现分钟级的场景构建。
从安全性、舒适性、可靠性、人机交互体验、可用性、合规性、能耗性和通行效率等维度,共开放了200项评价指标。
虚拟仿真测试:将规控算法评测周期从原来的天级缩短到了小时级,整个算法的迭代周期也从周级缩短到了天级。
提供超过20万个仿真场景实例;系统每日虚拟测试里程可超过1000万公里,支持3000个实例并发测试。
提供给客户一套参考算法,客户可以在此基础上调试优化。
和VTD战略合作,并嵌入了CarMaker的车辆动力学模型。
车企间的数据共享:有一个叫 Club 的模式,车厂可以选择加入或不加入,如果加入的话所有是共享的。如果不加入,那你自己就是一个 Pool,别人也不会和你共享。
高精地图
智驾方案可根据对高精度地图的依赖程度,分成ICA、ICA+、NCA三类模式。
ICA 模式:车在第一次开的地方实现自动驾驶
ICA+ 模式:没有高精度地图,但是车会根据自车或者是他车开过的环境自动学习地图
NCA 模式:车内有预置的高精地图
整个地图系统叫 Roadcode,Roadcode 里面有两部分组成,一个叫 Roadcode HD,一个叫 Roadcode RT。
Roadcode HD可以理解为传统的高精度地图,有专门的地图制作团队做的,是离线的;
Roadcode RT 是车子的自学习地图,用于NCA和ICA+ 。
这两个东西是两位一体的,Roadcode RT 本身会不断地自学习后去更新 HD,把数据沉淀下来。AVP 也是同样的实现原理。(类似于特斯拉3D场景重建的做法)

轻舟智航
OmniNet
关键概念
时序多模态特征融合,应用于前中融合阶段、实现数据/特征融合的全任务大模型。
亮点/指标
将视觉、毫米波雷达、激光雷达等数据通过前融合和BEV空间特征融合,让本来独立的各个计算任务通过共享主干网络(backbone)和记忆网络(memory network)进行高效多任务统一计算,最终同时在图像空间和BEV空间中输出不同感知任务的结果。
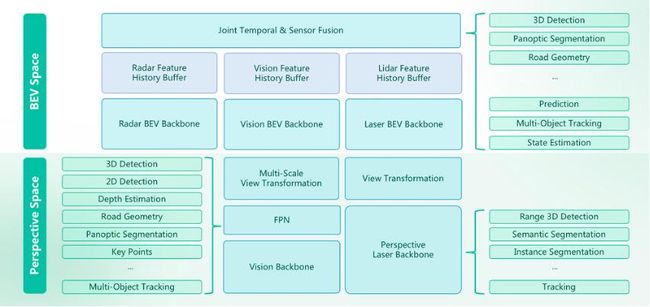
情调通用障碍物识别:在前向lidar视野内,OmniNet可输出每一个占据栅格的语义、实例、运动状态等信息,不仅能有效识别车辆、人群、植被、护栏、锥桶、小动物、施工区域等常见的道路交通参与元素,各类陌生或长尾罕见的异形障碍物,即使不属于交通参与者也可以识别并快速做出反应。
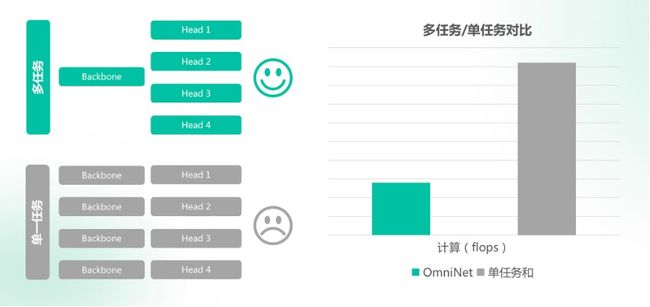
让本来独立的各个计算任务通过共享主干网络(backbone)和记忆网络(memory network)进行高效多任务统一计算,在完成相同数量任务的基础上,OmniNet可以节省2/3的算力。
前向120度的激光雷达看不到后方,但通过时序和空间融合算法,在车行驶过程中,前向激光雷达扫过的区域会在系统时刻进行记忆,并在车往前行进后将记忆区域的点云数据,与侧向后向的纯视觉信息进行补充和融合,从而保证对前后向区域的充分认知。
时空联合规划
关键概念
业界更多采用的是「时空分离规划」——把「对轨迹的规划」拆分成两个子问题,即路径规划(path planning)和速度规划(speed planning),路径规划对应于横向控制,即方向盘;速度规划对应于纵向控制,即刹车或油门,这种决策机制也就是通常所谓的「横纵分离」。
「时空分离规划」相当于先为车辆「铺好」一段铁轨,再在铁轨上计算速度。这种方式非常依赖手写规则调整车辆行为,也非常依赖大量路测来验证算法。
轻舟智航自研「时空联合规划算法」,同时考虑空间和时间来规划轨迹,能直接在x-y-t(即平面和时间)三个维度的空间中直接求解最优轨迹。

亮点/指标
用了一个案例来说明两种规划算法的区别。
规划控制技术架构设计灵活,可以适用高低性能的计算平台,当算力足够的时候,会计算出较多轨迹,选取最优轨迹,充分利用多核做并行计算;算力有限的情况下,生成的轨迹会相应减少,但也可以保证行车的安全性与稳定性。
将传统机器人技术和机器学习技术结合,通过深度学习来优化决策和规划,在大规模智能仿真系统中,模型算法每天可以抽取数百万帧有效数据,完成训练、测试验证和迭代优化,说明两个场景——“判断跟车距离”和“选择变道时机”都是可以基于人类驾驶行为数据训练得出的。
特斯拉讲的联合优化是指自车和障碍物之间的优化,跟轻舟的时空联合优化不是一回事,自车和障碍物的博弈并非轻舟强调的点。
Prophnet
关键概念
轻舟的预测模块分为车端和训练平台端两大重要部分:
① 车端的预测模块
主要目的是预测障碍物未来可能的行进轨迹,该模块又分成预测Context、预测Scheduler、后处理这三个主要的子模块。
· 预测Context(预测的上下文),主要用于记录各种各样的信息,比如自动驾驶车的历史的驾驶信息,障碍物的历史信息、包括历史的位置姿态,它的转向灯的历史序列,还有当前障碍物的信息。还有地图和红绿灯,因为障碍物的很多运动是跟地图以及红绿灯的状态强相关的,所以预测也需要考虑地图和红绿灯。
· 预测Scheduler,使用预测Context提供的信息来预测障碍物未来的行为和轨迹。
首先对障碍物进行优先级分析:把障碍物分成高优的——即距离自车较近的、有潜在交互风险的障碍物,和低优先级的----跟自车交互可能比较低的障碍物,比如远处的。这么做的主要目的是把有限的车载的算力去集中到比较重要的障碍物上。
其次是场景分析,主要分析障碍物当前所处的场景:比如正处于路口,还是正常道路;是在高速,还是在匝道上等等。
经过分析之后,会有相应的预测分发逻辑。根据不同的优先级、不同的场景,分发到不同的预测器去做大量的预测(预测器可以理解为预测算法的「容器」,不同的预测器包含不同的预测算法)。
· 后处理,解决预测轨迹之间的冲突:比如两个预测如果互相矛盾,那么会由冲突解决模块去仲裁。
裁剪低概率预测轨迹:如果有预测的轨迹概率较低,则可以裁剪掉不给下游。
交互后处理:主要处理障碍物,预测未来的轨迹,预测和自车的潜在的交互。
② 训练平台端
拥有预测样本生成模块——从海量的路测数据里提取感兴趣的预测样本,再将这些样本存到样本库中,在样本库中,预测模型的训练模块会从中选取所需的样本,进行深度学习模型的训练和优化。
亮点/指标
提供10秒的意图加轨迹预测,主模型预测有至少三条带概率的轨迹,同时最大概率轨迹和真值的平均误差是 3.73 米,即10 秒整体轨迹的平均误差3.73 米(没有提及在什么场景下)。
主模型可同时支持预测 256 个目标,推理整体耗时小于 20 毫秒,可以满足实时运算的需求。
除主模型外还包括副模型,包括Cutin模型,其平均可以提前一秒预测到和自车平行的障碍物的切入行为。准确率达95%,误报率小于10%,路口出口的选择模型的准确率也能高达90%以上。
Prophnet模型在Argoverse 2021年和2022年的比赛里分别拿到是冠军和季军,号称可在车端以10Hz的频率运行。
轻舟矩阵
关键概念
轻舟自动驾驶研发的工具链。
亮点/指标
建立了驾驶数据仓库,可自动化地对实际驾驶数据和影子模式下的人工驾驶数据打上标签。这些标签的内容非常丰富,数量多达成百上千个,包括道路信息(道路级别、种类、车道类别等)、坐标环境信息(周围障碍物、车流密度、行人、其他车辆是否cut in等)、自车信息(自车的速度、位置)、从影子模式中获得的人类司机的开车数据,由此就可以得知人类司机在哪个时间点刹车变道、什么时候打了转向灯。
可以更便捷地针对发现的问题建立场景库:比如,如果自车无法很好地处理有大车cut in的情况,就可以将大车在自车前突然起步的类似情况全挖掘出来,做成场景库进行仿真测试。
线上事件挖掘机制:当发现有行人检测不稳定的情况时,便会将相关时段的信息保存上传;在案例分析阶段,找到大量相似场景,确认相关场景的共性和算法处理的不足,在此基础上进一步挖掘出充分的数据用于标注训练,最终解决好这一类场景的问题。
生成红绿灯数据:通过对抗式生成网络,在有大量红绿灯数据积累的情况下,进一步增强其多样性;生成的数据可以在许多维度上更加多样化,在模型训练中加以使用,可以大幅提升模型算法的泛化能力。

毫末智行
解决了大部分高速场景后,今年自动驾驶很大一部分研发重心开始转向城市场景。
城市场景的复杂性较高速倍增:比如,城市道路经常不定时的养护;有的路段大型车辆密集,遮挡和截断严重;周围车辆的行为导致自车变道空间狭窄,变道困难;还经常遇到打开的车门等等。

毫末数据训练
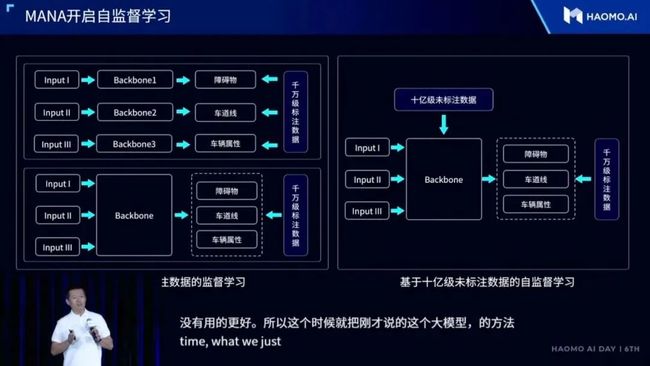
关键概念
将所有感知任务backbone进行统一,然后利用无标注数据对统一backbone进行预训练,模型剩余的部分再用标注样本进行训练。
做Backbone的预训练这种方式比只用标注样本做训练,效率可以提升3倍以上,同时精度也有显著的提升。
在数据规模增加后,需要继续保持巨量数据规模下对自然界数据分布遵循长尾分布形态。
简单来说,就是在处理好头部场景数据的基础上,兼顾腰尾部场景数据。
业界常用的方式是用全量数据再次精细的训练模型,但是这种做法的成本高而且效率低。
毫末的做法是,构造一个增量式的学习训练平台。训练过程中不再无差别地去优化所有参数,而是选择“有偏见”的参数进行定点优化,并动态观察模型的拟合能力,适时扩充模型参数规模。
亮点/指标
据称,相比常规做法,这一方式达到同样的精度可以节省 80% 以上的算力,收敛时间也可以提升 6 倍以上。
重感知+轻地图
关键概念
采用了重感知的技术路线。
亮点/指标
使用 Transformer 建立强感知的时空理解能力,用时序的transformer 模型在 BEV 空间上进行虚拟实时建图,通过这种方式让感知车道线的输出更加准确和稳定,在这个时空下对障碍物的判断也会变得更加准确。
目前,在实时感知能力下,毫末已经可以不需要地图辅助就能解决过去比较麻烦的复杂路口、环岛等问题。
拟人的驾驶策略
关键概念
过去业界常用的分场景、微模型方法,会存在由于太机械导致的舒适感不足问题。
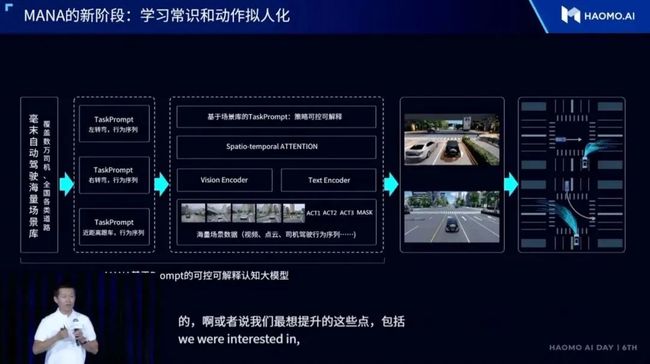
毫末正在借鉴多模态大模型的方法来解决认知问题,让系统的动作更加拟人。
大致做法是,对覆盖全国的海量人驾数据进行深度理解,构建毫末自动驾驶场景库,并基于典型场景挖掘海量司机的实际驾驶行为,构建 taskpromt,训练一个基于时空 Attention 的驾驶决策预训练大模型,使得自动驾驶决策更像人类实际驾驶行为。

福瑞泰克
福瑞泰克的技术中台——ODIN数智底座,其大致可以分为:传感器、域控制器、算法、数据闭环。
传感器
以前视感知为主的1V或者1V1R是当前量产的主力。第一代前视摄像头产品FVC1.0 2018年量产;第二代产品FVC2.0/FVC2.1已经量产,第三代产品FVC3即将量产。
FVC1.0、FVC2.0/FVC2.1 单V或者融合前雷达,支持L2辅助驾驶全功能的量产。向下,FVC2可以支持10万元级车型的量产,向上FVC3可以支持到25万元级的车型。
自研的摄像头模组,配合自研的标定算法,对图像进行高度拟合还原,可以提升识别精度;模组在设计时,充分考虑了温度对材料的影响,确保定焦时有较高的清晰度;在滤光片上,利用旋涂工艺,消除鬼影、优化光斑。
FCV3集成800万像素摄像头,FOV开角更大,可以在高时速下更好的识别到近距离的Cut-in,可以在较长距离车道线缺失的情况下优化LCC的体验,通过大弯道时也会更稳;800万像素前视对AEB功能也会有大幅提升。
涉足4D毫米波雷达的研发,除了成本更低,获取更丰富的原始数据外,传感器依据智驾的场景和软件需求进行针对性定义和优化。
相比激光雷达,福瑞泰克在传感器的路线选择上,更倾向深挖视觉和毫米波雷达的能力。
域控制器
ADC20,AI算力 13 TOPS,接入5V6R,支持高速NOA功能;
ADC25,AI算力37 TOPS,可接入10V5R,可以实现部分城区辅助驾驶功能;
ADC28,264 TOPS,支持城区NOA的L2.9方案;
ADC30,448 TOPS,可接入11V5R3L,支持L3级自动驾驶方案。

福瑞泰克 ADC30
数据闭环
基于FVC以及ADC20的量产,福瑞泰克在数十个ADAS项目上积累实车测试数据,尤其从ADC20开始,系统支持影子模式,内部保守估计未来一年内将获得千万公里级别的高价值数据回传。
在NOA开启时系统发现驾驶员接管,原因可能是超车时机不对、或者下匝道时机不对,接管的动作会触发相关数据上传到云端,云端训练后算法的策略会迅速优化迭代。

搭建分层的数据湖,支撑海量数据的生命周期管理:
对有缺陷的数据,快速发现并且尽快反馈给前方调整采集策略;
对高价值的数据,通过轻度挖掘,基于分层标签策略存储,方便研发人员访问洞察。
已建立了超过4000+高价值场景的场景库,用于算法测试、验证和质量管理;通过影子模式,与OEM厂商共建数据合作模式,发掘数据的商业价值方向。

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称