hive数据的导入导出
一、hive 的数据导入
Linux本地文件以及数据格式:

在hive中创建表:
create table t_user(
id int
,name string
)
row format delimited
fields terminated by ","
lines terminated by '\n'
stored as textfile;
stored as常见的几种格式
1. TextFile:使用TextFile格式存储的表将数据以文本文件的形式进行存储。这是最常用的默认存储格式。
2. SequenceFile:使用SequenceFile格式存储的表将数据以键-值对的形式存储,适用于数据压缩和高效读取。
3. ORC(Optimized Row Columnar):ORC是Hive的一种高性能列式存储格式,它以列的方式组织数据,提供了更高的压缩率和查询性能。
4. Parquet:Parquet是一种列式存储格式,也是Hive的一个常用选项。它支持高度压缩和谓词下推等优化,适用于大规模数据分析。
5. Avro:Avro是一种跨语言的数据序列化系统,Hive可以使用Avro格式存储数据!
加载本地数据
load data local inpath '/home/hivedata/user.txt' into table t_user ;
-- 如果在into前面加了overwrite就是覆盖之前的数据重新导入数据
加载hdfs上的数据
*注意:hdfs上需要有数据
从本地上传文件到hdfs上

// 追加添加
load data inpath '/yan/hivedata/user.txt' into table t_user;
//覆盖添加
load data inpath '/yan/hivedata/user.txt' into table t_user;
把别的表中的数据插入目标表
create table u1(
id int,
name string
);
insert into u1
(select id ,name from t_user);
# 查询一次插入多个表 ,把from写在前面
from t_user
insert into u2 select *
insert into u3 select id ,name;
克隆表
-- 把表结构和数据一起复制
create table u4 as select * from t_user;
-- 只复制表结构,只需要使用like 表名即可,不用select
create table u5 like t_user;
本地数据导入和hdfs数据导入的区别:
本地:将数据copy到hdfs的表目录下
hdfs:将数据剪切到hdfs的表目录下
二、hive中数据的导出
导出到本地文件系统的目录下
# 必须加overwrite
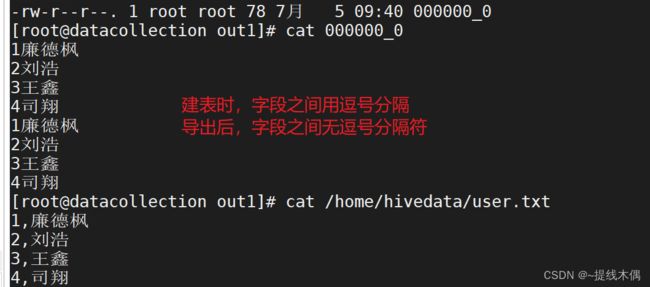
insert overwrite local directory '/home/hivedata/out/out1' select * from t_user;
# 在本地Linux系统中,最后一级的out1也是目录

导出到hdfs的目录下
-- 比本地少了local
insert overwrite directory '/yan/hivedata/out/out1' select * from t_user;
导出的数据文件中,默认字段不分割,其中的方括号是hdfs默认的分隔,之前的逗号分隔符没有了
把hdfs上的数据导入到Linux本地:
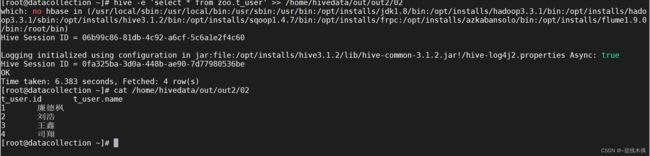
hive -e 'select * from zoo.t_user' >> /home/hivedata/out/out2/02
# 02是我建的空文件
# 导出的文件中字段分隔符默认是\t